Writing Systems of Sindhi
Scripts, Orthographies, Sociolinguistics
Arvind Iyengar

Cover illustration: Ajrak, a traditional handmade fabric from Sindh known for its characteristic block-printed geometric motifs.
| फुड़ीअ फुड़ीअ तलाउ | ڦُڙِيءَ ڦُڙِيءَ تَلاءُ |
| 𑋓𑋣𑋊𑋢𑊰 𑋓𑋣𑋊𑋢𑊰 𑋍𑋚𑋠𑊴 | ਫੁੜੀਅ ਫੁੜੀਅ ਤਲਾਉ |
| 𑈠𑈖𑈮𑈀 𑈠𑈖𑈮𑈀 𑈙𑈧𑈬𑈃 | |
| ⠖⠥⠻⠑⠊⠄⠂ ⠖⠥⠻⠑⠊⠄⠂ ⠞⠂⠇⠁⠄⠥ | |
| ⠖⠥⠻⠔⠁ ⠖⠥⠻⠔⠁ ⠞⠇⠜⠥ | |
| [ pʰʊɽiᵊ pʰʊɽiᵊ t̪əlaᶷ ] | |
| Little drops of water make a mighty ocean | |
Acknowledgements
This book has been in the works for a while, and has been made possible by the contributions of numerous individuals and institutions.
First off, I am grateful to Yannis Haralambous for releasing this work as a monograph under the Grapholinguistics and its Applications banner. Yannis’ pioneering initiatives — which include the aforementioned book series and the biennial /ɡʁafematik/ conference series — serve as niche, dedicated platforms for disseminating state-of-the-art research in grapholinguistics, and have played a key role in promoting this budding discipline. As author, I was reassured to have the backing of such an immensely patient and typographically zen publisher. Γιάννη, σ᾿ εὐχαριστῶ πολύ!
The seeds for this book were sown during my doctoral research at the University of New England (UNE) in Australia — a place I have been associated with since 2010, first as a student and subsequently as an academic. Over these years, several colleagues have assisted me in innumerable ways. Fellow linguists Liz Ellis, Inés Antón-Mendéz, Diana Eades, Helen Fraser, Mark Post and the late Jeff Siegel offered timely help and sage advice at various times during my initial years. Special thanks are due to Nick Reid for his enduring mentorship and friendship. Above all, I am deeply indebted to Finex Ndhlovu and Cindy Schneider for their expertise, wisdom and insights, first as my doctoral supervisors and now as colleagues. They, along with Sally Dixon and Sarah Lawrence, have extended unflinching support and encouragement when most needed. The patient ear and dry wit of geek-in-arms Piers Kelly have offered welcome respite in a world yet to fully appreciate the subtleties of grapholinguistics. I have, however, had the good fortune of meeting some extremely talented and motivated grapholinguists-in-the-making in my Writing Systems of the World course at UNE, which gives me confidence our ilk is well on its way to greater conspicuousness.
Outside of UNE, I extend my sincerest thanks to Keren Rice and Sali Tagliamonte of the University of Toronto’s (UoT) Department of Linguistics for hosting me as a Visiting Scholar in 2019. Their kind invitation allowed me to carry out research that helped set up Writing Systems of the World at UNE and informed central concepts in this book, among other things. My connection to UoT Linguistics continues thanks to the dynamism of Yoonjung Kang, whose sustained collaboration I am grateful for. Deserving special appreciation is Shafique Virani of UoT’s Department of History for generously and cheerfully offering me his time, expertise and endorsement throughout the drafting of this book, and unhesitatingly sharing his encyclopedic knowledge with me. His generous contributions have been indispensable in shaping Chapter 10.
In the world of grapholinguistics, I wish to acknowledge Amalia Gnanadesikan, Dimitrios Meletis, Sven Osterkamp and Gordian Schreiber for their cutting-edge research and for our enlightening conversations, all of which have offered much food for thought in the context of this book. I look forward to continuing my association with them and navigating new grapholinguistic frontiers together. I am also obliged to several scholars in the field of Sindhi language studies for their help over the years. The late Lachman Khubchandani offered me much-needed guidance during my initial foray into linguistics, which encouraged me to pursue my interests further. His passing has left a conspicuous void in the field. I remain indebted to Kanhaiyalal Lekhwani and Lachman Hardwani for sharing with me their deep knowledge of Sindhi graphematics and providing me with copies of their publications. Sundri Parchani has been a mentor and well-wisher for more than a decade now, and it has been particularly satisfying to draw on our co-authored scholarly work in compiling this book. Paroo Nihalani and Maya Khemlani-David have played quiet but key roles in my research endeavours over the years, for which I express my deep appreciation. Matthew Cook and Michel Boivin have forged new pathways for the dissemination of Sindhi language scholarship, and I cherish my collaboration with them. I am especially beholden to the Sindhi interviewees featured in Chapter 13 of this book for so generously sharing with me their time, stories and, often, food. The sombre realisation that several of them have now passed on makes me all the more appreciative of what I learnt from them.
Of course, none of this would have been possible without my parents, who, despite being thousands of kilometres away, have been indispensable in keeping me going. Their undying concern for my wellbeing and their pampering during my visits home have always provided a much-needed psychological boost. Their championing of my work has never been dampened by the fact that they remain somewhat unsure of what exactly linguistics is. Among my Sindhi family, I am grateful to Ashok, Giri, Usha and Vivek Sakhrani for the ongoing opportunity to speak, hear and appreciate the nuances of the Shikarpuri variety of Sindhi. I owe a debt of gratitude to Asha Sakhrani for acting as my on-call native speaker consultant for several years now.
Ultimately, this book was made possible by Malini. My Sindhi-speaking better half has been the greatest reward and incentive for my interest in the language. Her unwavering support through thick and thin is what keeps me going. To Malini — [ɡʱəɾᶷ t̪ɪt̪e t̪ũ d͡ʑɪt̪e]. Home is wherever you are.
PART ONE | Introduction
1 Aims, objectives and scope
1.1 What this book is about
If a writing system is understood as a particular language written down in a particular script subject to certain rules, this book is on the various writing systems of the Sindhi language. Native to the South Asian region of Sindh — today a province of Pakistan — Sindhi is an Indo-Aryan language spoken by around 33 million people, the vast majority of whom reside in Pakistan and India. Over the last millennium, Sindhi has appeared in various writing systems, some better known than others. This monograph is the first to analyse the various past and present writing systems of Sindhi, both individually and comparatively, using contemporary grapholinguistic research methods.
This monograph forms part of the series Grapholinguistics and its Applications. A previous volume from this series concluded with the following message:
[A] comprehensive evaluation of an entire [writing] system would be an important test for the theory as it likely highlights gaps in the theory or where it requires revision. Such case studies of the naturalness of different […] writing systems that are carried out in the same theoretical framework could, in a further step, also be straightforwardly compared, which would allow attaining a deeper understanding of universal, typological, and system-specific aspects of writing.
This is where the present work comes in. Harnessing and building on the theoretical approaches outlined in Meletis (2020), this book will describe, analyse and theorise the various writing systems used for the Sindhi language. In doing so, the book will also scrutinise the theoretical approaches themselves, and suggest practicable refinements.
In terms of scope, Meletis’ (2020) work was self-admittedly not “a minute description of any specific writing system, nor a detailed comparison of any two writing systems” (p. 10). Rather, it aimed to be a broad-based ‘horizontal’ treatment of writing systems in general. The present book is something of the opposite in featuring in-depth or ‘vertical’ analyses of specific writing systems and their salient features, followed by explanations or hypotheses for the existence of these features. More importantly, since the present volume describes several writing systems of various types using a common theoretical approach and terminology, robust comparisons of features from two or more of these writing systems will become possible in future analyses. To adopt Meletis’ (2020, p. 391) terms, the holistic approach of this volume will facilitate atomistic approaches towards the same subject matter in future. In this regard, the present monograph is comparable to another from the Grapholinguistics and its Applications series — Honda’s (forthcoming) monograph on Japanese writing systems.
1.2 What this book is not about
Being the first monograph dedicated to multiple writing systems of the Sindhi language, this work necessarily deals with linguistics and related domains. At the same time, there are certain areas of investigation that lie outside the purview of this book. Below is a list of salient domains and subject areas that readers may suspect this book covers, but which actually lie outside its scope.
Sindhi language, literature and society
This book is on the writing systems of the Sindhi language, and not on the Sindhi language itself. To this end, the book’s primary focus is not the phonology, morphology, syntax, lexicon, semantics or pragmatics of Sindhi. Nor does it treat in any detail issues of Sindhi-language education, government policy or politics. While these topics are briefly mentioned in Chapter 4, it is only with the aim of providing a foundation to facilitate a deeper understanding of Sindhi’s writing systems. Similarly, this book does not analyse or critique Sindhi-language literature, nor does it focus on Sindhi society per se. Just as Chapter 4 provides an overview of the language to orient the reader, Chapter 3 provides a brief historical and sociological background of Sindhi society. That said, certain sections of the book, particularly Chapters 5, 13 and 15, have an explicit sociolinguistic bent to them, albeit within the overarching domain of grapholinguistics.
Some readers may instinctively associate the concept of Sindhi’s writing systems with the symbols found on archaeological artefacts excavated from sites of the Indus Valley Civilisation (3300–1100 BC). These symbols have received considerable academic and popular attention since their discovery in the early twentieth century. However, there is as yet no consensus on what the symbols represent, let alone whether they represent the Sindhi language. For this reason, and aside from brief allusions in Sections 3.1 and 5.1, the book does not investigate in any detail the purported meaning and significance of the Indus Valley symbols.
Script pedagogy or advocacy
This book is situated in the domain of grapholinguistics, and is not directly associated with the subject areas of literacy and pedagogy. It describes and analyses various past and present writing systems used for the Sindhi language. It is not a reader, primer or self-instructional guide on ‘How to Read Sindhi’. Rather, what the book does is make clear how the idea of ‘reading Sindhi’ only makes sense when a particular writing system is also specified.
The book also does not advocate for one writing system or the other. Viewed against the ideologically charged and contested debate on Sindhi-language writing systems in post-Partition India (§5.3), it is emphasised that this book only describes the various writing systems (and others) in question. It does not prescribe. That said, the book cannot be understood as ideologically ‘neutral’, since a scholarly work situated in an ideological vacuum may well be an epistemological impossibility. What can be asserted, though, is the absence of an ideological stance favouring one writing system over another.
Typography and calligraphy
Although concerned with the writing systems of the Sindhi language, matters of typography and calligraphy are not central to the focus of this book. Consequently, the graphical and design aspects of the scripts in question are examined only to the extent necessary for a holistic analysis of a particular writing system. Thus, the book analyses the visual differences between unstandardised and standardised Sindhi-in-Khudawadi (Chapter 8), but does not concentrate on the visual differences between the Khudawadi, Khojki and Gurmukhi scripts. The latter type of analysis leans towards the typographical end of the grapholinguistic spectrum, which falls outside the scope of the book.
1.3 Limitations
Content and focus
This book is the first scholarly monograph to focus at once on multiple writing systems of the Sindhi language. Understandably, the reader may be sceptical about the intrinsic coherence of the book’s content, and whether the various themes in this work ‘go together’ in an intuitive manner. The content of the book may also be critiqued as skewing towards description rather than explanation. However, the seemingly eclectic nature of the content, and the surfeit of description, are natural and unavoidable outcomes of the book being a first mover in its discipline. As Meletis (2020, p. 178) puts it, the descriptive ‘what’ or ‘how’ needs to precede the explanatory ‘why’. Moreover, we still lack comprehensive and widely accepted terminology to accurately describe various grapholinguistic phenomena, let alone having at our disposal unambiguous metrics to measure and compare these phenomena. While recent scholarship in grapholinguistics (Gnanadesikan, 2017a; Meletis, 2020; Sproat & Gutkin, 2021) has made great strides in plugging the terminological gap, much conceptual and terminological development remains pending. This gap is acutely felt when having to consistently describing cross-linguistic grapholinguistic phenomena across typologically distinct writing systems, not to mention writing systems that straddle typological boundaries, such as unstandardised Sindhi-in-Khudawadi (Chapter 8). This means that the very task of description has required terminological innovation in order to enable subsequent analysis and explanation.
Nevertheless, and as mentioned in Section 1.1, an initial description of a phenomenon is likely to be broad-based and holistic. Atomistic analyses, whether individualised or comparative, can only be reasonably attempted once the initial groundwork has been laid — which is what this book aims to do. Consequently, the book contains a greater proportion of descriptive content than analytical. That said, acting as a counterweight to the description in Parts One and Two is the analysis in Part Three, which is dedicated solely to explanations and theory based on the descriptions preceding. I hope this book serves as the impetus and inspiration for deeper, more sophisticated graphematic and sociolinguistic analyses of Sindhi’s writing systems, and of writing systems in general.
The focus on Sindhi has also necessitated excluding writing systems where the language might be considered distinct from Sindhi proper. It is for this reason that writing systems of Kutchi — which is grammatically related to Sindhi but sociolinguistically seen as a separate variety — have not been analysed in any detail in this book. The exception to this rule is Kutchi written in the Khojki script (Chapter 10), justified based on historical-sociolinguistic factors.
Epistemological and logistical
The book’s first mover status meant that it was written in an epistemological silo of sorts, especially since works comprising a holistic treatment of a single writing system, such as Honda (forthcoming), were unavailable for comparison and ideation at the time of writing. Due to the epistemological vacuum this book was faced with, it may be critiqued as providing a “fragmentary picture” (Meletis, 2020, p. 403). As described in the previous section, the descriptive and analytical tools required for the job at hand are still a work in progress. Yet, imperfect as this book may be, it should still prove useful.
In terms of focus, my greater first-hand familiarity with the Indian and diasporic Sindhisphere, and my inability thus far to visit Pakistan and engage further with the Pakistani Sindhisphere, may have caused me to unwittingly foreground the Indian dimension of the language and its writing systems. This should not count as a critical shortcoming, though, since the smaller Indian Sindhisphere has been far less researched than the larger Pakistani one. In any event, since the geopolitical boundary between Pakistan and India only came into being in 1947, older data from the nineteenth and early twentieth century remains unaffected.
Further limitations of the book may arise from my own proficiency — or lack thereof — in certain subject areas, and the physical or material inaccessibility of specific sources of information. For instance, I was able to obtain and consult scholarly literature and data on the subject in certain languages and writing systems, including Sindhi, English, Hindi-Urdu, Marathi, Gujarati, German and French. However, my inability in Russian prevented me from taking advantage of the body of Russian-language scholarship on Sindhi. Besides, certain sources of information were not accessible at all, whether in print or digital format. To top it all, much of this book was written during the COVID-19 pandemic, rendering in-person travel to physical archives and data sources onerous or even impossible. I remain an optimist, though, and view the omissions and gaps in this book as a serendipitous reminder that there remains much work to be done, and many more grapholinguistic treasures to be unearthed.
1.4 Structure of the book
The book contains fifteen Chapters organised into three Parts. Part One, comprising the first four Chapters, lays down the conceptual and epistemological foundations for the reminder of the book. Chapter 2 explains the theoretical approaches and establishes the terminology used in the book. Chapters 3 and 4 provide an overview of the Sindh region, the Sindhi people and their history, and the Sindhi language, thereby setting the stage for the remainder of the book. Part Two constitutes the descriptive core of the book, starting off with a chronology of written Sindhi and its various forms in Chapter 5. This is followed by descriptions and evaluations of seven individual writing systems of Sindhi, concluding with a sociolinguistic investigation of attitudes towards the three most prominent systems in present times. In Part Three, Chapters 14 and 15 encapsulate the findings of this book and explore how the lessons offered by Sindhi’s writing systems can help advance the state of the grapholinguistic art.
2 Theoretical foundations and terminology
Unpacking the core subject matter of Sindhi writing systems requires fit-for-purpose terminology that allows us to describe and analyse the grapholinguistic phenomena in focus. Since grapholinguistics remains an emerging discipline, it is still grappling with conflicting, vague or even a complete lack of terminology to describe certain phenomena. Establishing and setting out the requisite terminology or meta-language to enable clear and unambiguous discussion necessarily entails a slight departure from the Sindhisphere, which is what this Chapter will do.
The terms and definitions described in this chapter are sourced from a variety of academic and industry publications. The industry publications consulted primarily comprise specifications issued by the Unicode Consortium, which is behind the eponymous “standard for digital representation of the characters used in writing all of the world’s languages” (Unicode, 2025a). Also consulted are sources intended for a popular audience but compiled by qualified linguists, such as the ScriptSource website (ScriptSource, 2022a) created and maintained by the Christian missionary organisation SIL International.
2.1 Writing
Probably the most elusive and hard-to-define concept in the present context is that of writing itself. Early monographs on the subject offered up terse, laconic definitions of the term. Diringer (1948, p. 20) conceived of writing as “the graphic counterpart of speech”, in which every graphic element corresponded to one or more specific speech elements. Inherent in this definition were the fundamental assumptions of writing directly representing spoken human language, while also being secondary to it. Gelb (1963, p. 7) repackaged these fundamental assumptions and portrayed writing as “signs [that] become ultimately secondary symbols for notions of linguistic value”. In so saying, Gelb drew a distinction between semasiography or ‘meaning writing’ and phonography or ‘speech writing’ (p. 11), emphasising that only the latter is considered “full writing” (p. 191). Recent scholarship has reiterated Gelb’s notion of writing as ‘speech writing’ (but see Brokaw (2022)), while also refining it further. Coulmas (1991, p. 17) identifies writing in terms of three basic characteristics:
- consisting of artificial graphical marks on a durable surface;
- intending to communicate something;
- achieving its purpose of communication thanks to the marks’ conventional relation to human language.
Subsequently, Coulmas (1996a, p. 555) combines these characteristics and portrays writing as “a system of recording language by means of visible or tactile marks which relate in a systematic way to units of speech”. In the now-classic reference work The World’s Writing Systems, Daniels (1996a, p. 3) echoes Coulmas’ sentiment in defining writing as “a system of more or less permanent marks used to represent an utterance in such a way that it can be recovered more or less exactly without the intervention of the utterer”. By explicitly stating that “writing is bound up with language” and that “pictography is not writing”, Daniels reiterates the notion of writing essentially being ‘speech writing’ and not ‘meaning writing’. Sampson (2015, p. 21 ff.) retains Gelb’s term of semasiography but eschews Gelb’s problematic term of phonography, replacing it with the more justifiable glottography or ‘language writing’.1 This book will adopt the now-established definition of writing as glottography, and restrict itself only to writing systems whose elements correspond more or less to identifiable linguistic units in spoken Sindhi. Such an epistemological position further justifies the preclusion of the Indus Valley signs from this book, whose glottographic status remains unclear (§5.1).
Gelb also classified human communication — both linguistic and non-linguistic — into categories based on how such communication is received or decoded: through the visual, auditory or tactile route (1963, p. 8). Even if restricted to linguistic communication, Gelb’s categorisation proves insightful and has been built upon by subsequent scholarship. Joyce (2011, p. 69) encapsulates the essence of such views as language being conceptualised as “an abstract entity, where speech and writing, as well as sign, are different mediums for expressing language”. Joyce’s statement may be expanded into a useful paradigm of the various modalities used in human linguistic communication, shown in Table 2.1.
| Modality | Basic unit | Encoding mode | Decoding mode | Example | |
|---|---|---|---|---|---|
| Primary & Temporary modalities | speech | phone | oral | auditory | all spoken languages |
| visual | lip-reading | ||||
| tactile | Tadoma | ||||
| signing | (manual) sign2 | manual | visual | all signed languages | |
| tactile | tactile signing | ||||
| Secondary & Durable modalities | writing | graph | graphical | visual | all glottography |
| textured-graphical | tactile (also visual) | Braille, Moon type |
In Table 2.1, the modalities of human linguistic communication are first classified by their relative permanence, and subsequently by their modes of encoding and decoding.3 Speech and signing, which are considered primary modalities (O'Connor, 1996, p. 793), are temporary in nature. Writing, on the other hand, is expected to be, and often is, relatively longer-lasting.4 In terms of encoding, speech, comprising sound units or phones, is produced in the human vocal tract. Manual signing, comprising gestures or physical movements, are produced using the hands and, to a lesser extent, the face and upper body. In terms of decoding, speech is most often decoded by the human ear, although it may, in principle, be decoded via the human eye or touch. Manual signing can only be decoded through the eye or touch. Writing, comprising units called graphs (§2.2), is most often encoded with the aim of visual decoding — namely by sight. However, if the graphs are encoded in a tactually perceptible manner — say, by embossing — such writing may also be decoded using human touch. This is the route used most often by Blind and visually impaired persons to read text composed in Braille. In theory, writing intended to be decoded tactually may also be decoded visually, as in a text composed in Braille being decoded visually by a sighted person. By this measure, Braille-based texts meet the definition of writing outlined earlier. This idea was succinctly expressed by Sir Clutha Mackenzie, a Blind activist and administrator who played a leading role in the harmonisation of Braille-based writing systems worldwide (§11.1):
Apart from the facts that seeing [i.e., sighted] people have many scripts and the blind but one, and that the former read by sight and the latter by touch, there is no fundamental difference between a written and an embossed script.5
Since most Braille-based writing is intended to be decoded tactually, and targeted primarily at the Blind community, it may be justifiably understood as a distinct sociolinguistic subtype of writing (Bunčić, 2016e, pp. 100–101). Graphematically, however, there is little justification for treating Braille-based writing any differently from prototypical writing intended to be decoded visually. As Meletis (2020, p. 32 footnote 35) asserts, Braille-based writing “is a graphic representation of language and it should be counted as writing”. This justifies the inclusion in this book of Braille-based writing systems for Sindhi.
Building on the above, the subfield of linguistics dealing with “the scientific study of all aspects of written language” (Neef, 2015, p. 711), or, alternatively, “the study of the written modality of language” (Haralambous, 2020, p. 12) is known as grapholinguistics. In English-language scholarship, this discipline has been variously known in the past as grammatology, graphonomy, graphemics and graphematics (Meletis, 2020, pp. 3–8). In German-language academia, though, the field has been known as Schriftlingiustik and Grapholinguistik since at least 1988 (Dürscheid, 2016, p. 2 footnote). The latter term, in the form of grapholinguistics, has found increasing use in English-language academia since the early 2010s, and is slowly but steadily becoming established as the designation for the subfield (Honda, 2021, p. 622 footnote). In this book, grapholinguistics will be understood as encompassing two broad subdomains, graphematics (§2.4) and the sociolinguistics of writing (Bunčić, 2016b). For compactness, the latter domain will be referred to as graphosociolinguistics.
2.2 Graph
Within the paradigm on the modalities of human linguistic communication (Table 2.1), the basic unit of the written modality was termed a graph, and that of the manually-signed modality a sign. However, such usage is by no means universal and well-established. For instance, Daniels and Bright (1996, p. xliv) define sign as “a unit in a communicative system comprising a signifier (what carries the meaning) and a signified (what is meant)”. Unless explicitly clarified, it follows that “communicative system” is susceptible to broad interpretations or misunderstandings. Another term for the basic unit of written language, frequently used in both academic and lay contexts, is symbol. According to Rogers (2005, p. 10), this is “a general term for a graphic mark used in writing”. In the context of written English, the basic unit of writing is popularly known as a letter. As evident, these terms have the potential to be imprecise or even misleading. Meletis (2020, p. 78) opines that terms like sign, symbol and letter “lead double lives as lay terms and quasi-technical terms, and their use is problematic”. These fuzzy terms may have their place in lay discourse, thanks to their familiarity to nonspecialists. In a scholarly grapholinguistic context, though, precise terminology is desirable. Hence, this book will adhere to the paradigm in Table 2.1 and use the terms graph and SIGN to refer to the basic units of the written and manually-signed modalities of human language, respectively. Furthermore, labelling the basic unit of writing as the graph creates a foundation for deriving vocabulary that is harmonious with corresponding vocabulary in other linguistic subdisciplines. With graph as the point of departure, we arrive at grapheme, allograph and graphetics, analogous to phone, phoneme, allophone and phonetics (Haralambous & Dürst, 2019b, p. 129). Terminology derived from graph will be dealt with in the sections that follow.
If multiple individual graphs are used to denote one particular linguistic value, especially a phoneme, the set of graphs may be referred to as a polygraph (Sproat, 2000, p. 136 footnote 2; Osterkamp & Schreiber, 2021) or multigraph (Honda, 2019, p. 203). In the context of writing systems based on the Roman (or Latin) script, the most commonly encountered subcategory of multigraphs are digraphs and trigraphs, exemplified by English-in-Roman ⟨ch⟩ and ⟨tch⟩ for the English phoneme /t͡ʃ/. Less frequently seen are tetragraphs, such as the German-in-Roman ⟨tsch⟩ for the German phoneme /t͡ʃ/. An implied characteristic of multigraphs is that their component graphs remain individually identifiable and segmentable. That is, a multigraph is generally compositionally transparent (Meletis, 2020, p. 254 ff.). If the individual graphs in a sequence are merged such that they become harder to visually segment and lose their individual identities somewhat, the resultant form may well be considered a distinct graph. That said, it is not always clear-cut whether a particular written entity constitutes a distinct and independent graph in its own right, or is actually a multigraph featuring some visual merger between its individual constituent graphs (§2.7).
2.3 Script and Writing System
Despite the potential ambiguity of the term sign as described in Section 2.2, it has been used by several authors to refer to the basic unit of writing. For instance, Coulmas (1996a) defines writing system as:
[a] set of visible or tactile signs used to represent units of language in a systematic way, with the purpose of recording messages which can be retrieved by everyone who knows the language in question and the rules by virtue of which its units are encoded in the writing system.
Notwithstanding its labelling of the basic unit of writing as ‘sign’, Coulmas’ definition reiterates the fundamental idea that written units may be decoded visually or tactually, assuming they are encoded appropriately. That said, the above definition does not mention the term script. Similar to the term writing, the term script, too, has been interpreted variously in the literature (Wang, 2019). Daniels and Bright’s (1996) base their definition of script on the terms signary, writing system and orthography:
- signary
- a general term for a determined collection of characters (or signs)
- orthography
- conventional spelling of texts, and the principles therefor6
- writing system
- a signary together with an associated orthography
- script
- in this book, equivalent to writing system
This position is also adopted by Rogers (2005, p. 11). However, Daniels (2018) reinterprets the term script as follows:
- script
- a particular collection of characters (or signs)
- orthography
- conventional spelling of texts, and the principles therefor
- writing system
- a script together with an associated orthography
That is, Daniels’ (2018) definition of script is identical to what Daniels and Bright (1996) term signary. The equating of script with signary, while decoupling it from writing system, is an epistemological stance adopted by other scholars, including Coulmas (1996a; 2003) and Sproat (2000).7 This is also the position of Unicode, whose glossary defines the terms in question as follows:
- script
- A collection of […] written signs used to represent textual information in one or more writing systems. For example, Russian is written with a subset of the Cyrillic script; Ukrainian is written with a different subset. The Japanese writing system uses several scripts.
- writing system
- A set of rules for using one or more scripts to write a particular language. Examples include the American English writing system, the British English writing system, the French writing system, and the Japanese writing system.
Unicode’s definitions of script and writing system cited above also succinctly allude to an important distinction. For a writing system to qualify as one, it must comprise a script together with a language (Neef, 2015; Weingarten, 2011). As alluded to at the start of this section, writing as in glottography inherently involves a set of graphs that represent language. Put simply, a writing system requires not just a script, but also a language as an indispensable component. Accordingly, this book will follow Unicode’s definitions of script and writing system as distinct concepts, where the former is a component of the latter. The term signary will be avoided, to avoid confusion stemming from the meaning of sign. Where reference needs to be made to a set of graphs, be it the superset of all graphs in a particular script, or the subset of graphs employed within a particular writing system, the term graph inventory will be used.8
Despite the above, there remains the question of how much one can vary the constituent script or language of a writing system without fundamentally changing the identity of the writing system. Consider the examples in (1):
(1)
| a. English in the Roman script | ⟨English⟩ | |
| b. English in the Shavian script | ⟨𐑦𐑙𐑜𐑤𐑦𐑖⟩ | ‘English’ |
| c. English in the Deseret script | ⟨𐐆𐑍𐑀𐑊𐐮𐑇⟩ | ‘English’ |
|---|
In (1), the language portrayed is the same throughout, namely English. However, the script in each instance is distinct — Roman, Shavian and Deseret, respectively. Compare them with the examples in (2):
(2)
| a. English in the Braille script | ⟨⠑⠝⠛⠇⠊⠎⠓⟩ | ‘English’ |
| b. Tamil in the Tamil script | ⟨⠞⠍⠊⠈⠷⟩9 | ‘Tamil’ |
In (2), the examples are the inverse of (1) in that the languages are distinct in each case, while the script is the same – Braille. The question is, are examples (1)a, (1)b, (1)c and (2)a each an instance of a different writing system? Or are they collectively representative of an overall ‘English writing system’? It appears scholarly consensus on this issue is yet to emerge. Weingarten (2011, p. 17) considers a writing system to be “an ordered pair of a single language and a single script”. More recently, though, Meletis (2020) opines that:
two different scripts can also materialize one and the same writing system if only the [graphs] are switched out while the linguistic units [e.g., phonemes] they correspond with remain stable (this is more or less the case for biscriptual Serbian, which is written in either Roman or Cyrillic script).
Meletis’ statement above implies that the Serbian language written in the Roman script, and the Serbian language written in the Cyrillic script, both “materialize one and the same writing system”. Along similar lines, Honda (2021) suggests that written Japanese is one writing system made up of four different scripts — hiragana, katakana, kanji and rōmaji. While such a position seems reasonable, it also engenders at least two counterarguments. The first is the theoretical consideration that, if the ontogenesis of a writing system lies in a language component and a script component coming together, varying just one of these components should be a necessary and sufficient condition for the writing system to change identity. Such a position also affirms the equal status of language and script in constituting a writing system. While language is an essential component of a writing system, it is not the primary component of a writing system. Put differently, glottography need not, and should not, imply glottocentricity, for this would be a rather self-defeating stance for a grapholinguist to adopt. The second, practical counterargument is that of potential terminological ambiguity. If ‘Serbian writing system’ were understood as comprising both Serbian-in-Cyrillic as well as Serbian-in-Roman, fully specifying which script a Serbian-language text is written in (Bunčić, 2016h) would require additional periphrastic terminology.10
Consequently, this book adopts the position that every unique combination of language-and-script — that is, every unique language-in-script instantiation — should be understood as constituting a distinct writing system. On this basis, each example in (1) and (2) represents a distinct writing system. This book will also refer to a particular writing system in terms of both its principal constituents. Accordingly, the writing systems in (1) may be termed English-Roman, English-Shavian and English-Deseret, respectively, while those in (2) may be called English-Braille and Tamil-Braille, respectively. Such double-barrelled nomenclature has the advantage of being visually transparent, and has precedent in the works of Weingarten (2011) and Neef (2015). The format has also been adopted by ScriptSource (2022a) for specifying writing systems, albeit with a slight modification. ScriptSource designates writing systems using the format adopted by the Internet Engineering Task Force (IETF) and the Internet Assigned Numbers Authority (IANA). Such a format for depicting a writing system is called a language tag, and is officially defined as follows:
A language tag is composed from a sequence of one or more “subtags”, each of which refines or narrows the range of language identified by the overall tag. Subtags, in turn, are a sequence of [Roman-script] alphanumeric characters (letters and digits), distinguished and separated from other subtags in a tag by a hyphen ("-", [Unicode] U+002D).
Per this convention, a language tag for a writing system comprises at least:
- a two or three-letter language subtag in lowercase based on the ISO 639 standard, such as 𝚓𝚊 for the Japanese language;
- a four-letter script subtag in title case based on the ISO 15924 standard, such as 𝙻𝚊𝚝𝚗 for the Latin or Roman script.
Subtags are separated from each other by hyphens. Accordingly, the writing systems seen in (1) and (2) would be 𝚎𝚗-𝙻𝚊𝚝𝚗, 𝚎𝚗-𝚂𝚑𝚊𝚠, 𝚎𝚗-𝙳𝚜𝚛𝚝, 𝚎𝚗-𝙱𝚛𝚊𝚒 and 𝚝𝚊-𝙱𝚛𝚊𝚒, respectively (ScriptSource, 2022a). Optional subtags may be added for greater specificity, such as country codes in uppercase based on ISO 3166-1, or custom subtags in lowercase for particular language varieties or orthographies. For instance, the Serbian language as written in the Roman script in the Republic of Serbia would be specified as 𝚜𝚛-𝙻𝚊𝚝𝚗-𝚁𝚂 (Phillips & Davis, 2009, p. 14) Similarly, English as written in Great Britain in the Roman script and in ‘Oxford spelling’ (Bunčić, Lippert, & Rabus, 2016) may be specified as 𝚎𝚗-𝙻𝚊𝚝𝚗-𝙶𝙱-𝚘𝚡𝚎𝚗𝚍𝚒𝚌𝚝. Evidently, such a granular nomenclature offers clarity and, when presented as a language tag, compactness. Nevertheless, the format may also be seen as redundant when used in the context of languages customarily written in just one script, as in ‘Tamil-Tamil writing system’. Also, one subtag may imply another; the 𝚘𝚡𝚎𝚗𝚍𝚒𝚌𝚝 orthography subtag implies that the script in question is Roman. In such instances, where there is little room for ambiguity, the seemingly redundant component may be dropped, as in ‘Tamil writing system’ or 𝚎𝚗-𝙶𝙱-𝚘𝚡𝚎𝚗𝚍𝚒𝚌𝚝.12 Accordingly, in this book, these language subtags will be harnessed in various combinations depending on context and need:
- 𝚜𝚍 refers to the Sindhi language, with no mention of script;
- 𝙰𝚛𝚊𝚋 refers only to the Arabic script, independent of language;
- 𝚜𝚍-𝙰𝚛𝚊𝚋 refers specifically to the Sindhi-Arabic writing system;
- 𝚖𝚞𝚕-𝙰𝚛𝚊𝚋 refers to multiple languages written in the Arabic script.
In the context of the Roman script, the fifty-two characters below specified in the ISO 646 standard will be referred to as the basic Roman or basic Latin script:
- ABCDEFGHIJKLMNOPQRSTUVWXYZ
- abcdefghijklmnopqrstuvwxyz
Categorically specifying the constituents of a writing system using a multi-part nomenclature also has another, somewhat inconspicuous, advantage. The format lays bare the somewhat arbitrary and circumstantial nature of the language and script combination comprising the writing system in question. Indeed, (1) and (2) tacitly reveal how English can be reasonably written in various scripts. Thus, a double-barrelled nomenclature for writing systems subconsciously reinforces the absence of any intrinsic link between a language and the script it may be written in. In doing so, it brings to the fore the long-held grapholinguistic maxim that any language may be written in any script (Coulmas, 1996b, p. 1380). Admittedly, academic grapholinguists might find this idea to be a banal truism. To laypersons, however, such an insinuation may well prove dissonant or even offensive from a sociolinguistic perspective, especially to people who view a particular script as being an indispensable part of their language. If conflicting views on this issue exist within the same language community, the result may be pedagogically and sociolinguistically detrimental to the community. In the context of the Sindhi community, this sociolinguistic aspect will be examined further in Chapter 13.
Building on the basic principle of a writing system comprising two equipollent components — a language and a script — it may be possible to further categorise writing systems into homolingual and homoscriptal ones. Homolingual writing systems share a constituent language but differ in terms of their constituent scripts, as seen with 𝚎𝚗-𝙻𝚊𝚝𝚗, 𝚎𝚗-𝚂𝚑𝚊𝚠, 𝚎𝚗-𝙳𝚜𝚛𝚝 and 𝚎𝚗-𝙱𝚛𝚊𝚒 in (1) and (2). Conversely, homoscriptal writing systems differ in their constituent languages but share a constituent script, as in 𝚎𝚗-𝙱𝚛𝚊𝚒 and 𝚝𝚊-𝙱𝚛𝚊𝚒 in (2). To clarify, homolingual or homoscriptal writing systems need not be typologically similar, and two writing systems with a common language or script component might well belong to two different typological categories (§2.10). This book will demonstrate how a set of homolingual writing systems — with Sindhi as their common language — can be typologically quite distinct from one another.
At this juncture, it is worth emphasising that, when designating a writing system in terms of its constituent language and script, there apply the usual caveats of ‘language’ having fuzzy boundaries that may be difficult to determine. By analogy, the boundaries of ‘script’, too, are fuzzy, making the allocation of graphic variants into one or another ‘script’ potentially contentious. For instance, in (1), it seems uncontroversial to state that Roman, Shavian and Deseret are distinct scripts. However, not all instances are as straightforward, as seen in (3):
(3)
| English in the Roman script | ⟨English⟩ |
|---|---|
| English in Unifon | ⟨iNGliS⟩ |
| English in the Initial Teaching Alphabet (ITA) | ⟨Iñgliš⟩ |
Based on (3), do Unifon and the Initial Teaching Alphabet constitute distinct scripts? Accordingly, are English-Unifon and English-ITA distinct writing systems? Or should Unifon and ITA simply be considered distinct stylistic variants of the Roman script that just happen to possess certain graphs absent from the conventional Roman-script graph inventory for English? To some extent, the latter proposition has a parallel in spoken language. For instance, individual varieties of spoken English sound different, as they effectively comprise distinct phonological subinventories of the overall English inventory. However, the fact that these varieties are still considered ‘English’, and not distinct languages, suggests that the differences in phonological inventory are not significant enough. As evident, there is an element of subjectivity in such determinations, making them contentious. In the context of this book, the difficulty in deciding how much individual graphs — and, by extension, the scripts they constitute — can vary in visual form before they lose their initial identity and gain a distinct one is aptly illustrated in the context of the Landa inventories used to write Sindhi (Chapter 8).
The emergence of the Unicode standard over the last three decades has provided a useful heuristic for determining whether a particular graph inventory constitutes an independent script. Before a particular set of graphs can be encoded in Unicode as a distinct ‘script’, it usually goes through several rounds of proposals, refinements and deliberation (Unicode, 2025b). Consequently, the outcome may be considered, if not definitive, at least a reasoned one. Despite the rigorous process, the fuzziness involved in such decision-making is aptly illustrated by a proposal to encode Unifon graphs in Unicode, in which the author leaves open the question of whether the graphs should be designated a distinct ‘script’, or simply be included as part of the larger Roman-script inventory (Everson, 2012).13
It should be emphasised that the use of a particular writing system is often determined by sociolinguistic factors, and it is not difficult to find instances of full-fledged writing systems going unused, being used only in restricted domains. For instance, the Mandarin language written in the Roman script, known as Hànyǔ Pīnyīn, ticks the boxes for qualifying as a standalone writing system in theory (𝚌𝚖𝚗-𝙻𝚊𝚝𝚗-𝚙𝚒𝚗𝚢𝚒𝚗). In practice, though, Hànyǔ Pīnyīn is typically used as an auxiliary writing system restricted to specific contexts, such as teaching Mandarin to learners or entering Mandarin-language text on electronic devices (Mair, 1996, pp. 204–205; Wiedenhof, 2005). The reasons for the restricted use of 𝚌𝚖𝚗-𝙻𝚊𝚝𝚗-𝚙𝚒𝚗𝚢𝚒𝚗 are primarily sociolinguistic and political, as deployment of the Roman-script-based Hànyǔ Pīnyīn as a primary writing system, on par with or in place of Chinese-origin characters or Hànzì, might be seen as symbolic of Western cultural imperialism. Hence, despite being widely used as an auxiliary writing system, Hànyǔ Pīnyīn has never been officially promoted, nor gained popular acceptance, as a standalone primary writing system (DeFrancis, 2006). The secondary status of 𝚌𝚖𝚗-𝙻𝚊𝚝𝚗-𝚙𝚒𝚗𝚢𝚒𝚗 for writing Mandarin is betrayed by its common description, both in lay and scholarly spheres, as an ‘auxiliary’ writing system or ‘transliteration’ (§2.10).
2.4 Graphematics
In what is termed the Modular Theory (MT) of Writing Systems, Neef (2015) conceives of writing systems being composed of three distinct modules, two mandatory and one optional. The first mandatory module is a script, or, more granularly, a graph inventory, paired with a language. The second module, also mandatory, is graphematics or the graphematic system, defined as the “relation of letters to phonological units” (Neef, 2015, p. 714).14 This definition has since been extended to mean the correlation of the written units of the graph inventory with the spoken units of the language (Meletis, 2020, p. 26). Here, ‘spoken units’ may refer to phonemes, morphemes, lexemes, suprasegmentals or other orally manifesting linguistic elements. The third and optional module is orthography, taken up in Section 2.9.
Graphematics, thus, constitutes the correspondences between units of the written and spoken modalities of language, the study of which includes (a) what graphical and linguistic units are correlated, and (b) how the units are correlated. Under the what of graphematics, one would describe that, in the 𝚎𝚗-𝙻𝚊𝚝𝚗 writing system, the digraph ⟨sh⟩ typically denotes a voiceless alveolo-palatal fricative /ʃ/. In contrast, the how of graphematics would focus on the fact that ⟨sh⟩ maps onto a phoneme, and not onto a syllable or morpheme. Depending on whether the ‘linguistic unit’ is a phonological or morphological unit, the corresponding graph(s) may be known as phonograms and logograms, respectively.15 The former category may also encompass syllabograms, and the latter morphograms (Sampson, 2015, p. 24; Sproat & Gutkin, 2021). Section 2.8 deals with these categories in further detail.
Closer scrutiny reveals that the term graphematics may be prone to polysemous use, to denote not only the correlation between graphs and linguistic values, but also the study thereof. Such polysemy is reminiscent of the ambiguity with graphematics’ spoken counterpart, phonology, in that the latter term may denote the sound system of a language, or the study of sound systems of languages. When greater precision and disambiguation is desired, especially in the context of phonograms, the term graph-phone correspondences (or relations or mappings) may be used to denote the typical correlations between written and spoken units in a given writing system.16
Also provided for in the MT is the concept of graphematic solution space. According to Neef (2015):
[…] graphematics defines what a possible spelling of a word is. […] in natural writing systems, there may be more than one, actually considerably more than one. The set of possible spellings for a word with a specific phonological representation is what I call the ‘graphematic solution space’.
It follows from the above that strict one-to-one correspondences between phones and graphs would result in fewer and more predictable spelling options for a spoken word or utterance. That is, the more transparent and biunique the graph-phone correspondences, the smaller the resultant graphematic solution space. Conversely, if the correspondences between phones and graphs are many-to-one or opaque, the number of possible spellings would be greater, and the size of the graphematic solution space larger (Meletis, 2020, p. 133). In such an instance, an optional orthographic module might be required to constrain the possible spellings of words and utterances (§2.9).
Although Neef defines the graphematic solution space with reference to phonographic writing systems, the concept lends itself to being extended and applied to a variety of writing system types (Honda, 2021). In any event, since the writing systems dealt with in this book are largely phonographic in nature, Neef’s concept may be harnessed without significant modification. The interplay of the graphematic module with the orthographic module will be analysed further in Section 2.9.
The concept of graphematic system allows us to neatly articulate an elusive but crucial sociolinguistic phenomenon. When a script used to write a particular language is adopted to write another language, the process is often termed script adoption. However, as Meletis (2020, p. 341) points out, the process often involves adopting not just the script — that is, the graph inventory — but also the graphematic values associated with the graphs. Accordingly, the process in question may be more accurately characterised as adoption of a graphematic system. The graphematic system may subsequently be modified to suit the target language’s phonology, which may be analysed as adding an orthographic module (§2.9). That said, most scripts used to write multiple languages — that is, used in multiple writing systems — tend to have certain graphs that retain an archetypal linguistic value across writing systems. Thus, the Roman-script graph |a| usually denotes a low vowel (Meletis, 2020, p. 24), while |k| typically denotes a velar consonant. These archetypal linguistic values have been termed prototypical or canonical values (Gnanadesikan, 2017a; 2021; Weingarten, 2011). Besides being useful in analysing graphematic phenomena, the concept of canonical values also permits us to explain why, in an adopted graphematic system, ‘recycling’ a graph and assigning it a linguistic value vastly different from its canonical value may be met with sociolinguistic resistance (Meletis, 2020, pp. 356–357).
2.5 Grapheme
In writing-related contexts, the term grapheme is often defined by analogy to its counterparts in spoken language, such as the phoneme or morpheme (Daniels, 2018, p. 164 ff.). According to an early definition by British linguist Daniel Jones:
[…] phonemes are abstract sounds which one aims at producing, but which emerge in actual speech as a number of differing concrete sounds depending upon the phonetic environment. [Thus,] a phoneme is a family of sounds [called allophones], each of which is appropriate to one or more phonetic contexts […]
Broadly, the defining principles of a phoneme as outlined by Jones also hold true for a grapheme. A grapheme may justifiably be considered an abstract written symbol that one aims at producing, but which emerges in actual writing as a number of differing concrete symbols depending upon the context of writing. Simultaneously, a grapheme may also be considered a family of symbols — called allographs (§2.6) — each of which is appropriate to one or more writing contexts. Thus, a grapheme may be understood as the smallest contrastive unit, namely a graph in a writing system that is also linguistically significant.
Despite consensus on the broad concept of a grapheme, a narrow definition of the term has proved elusive. Unlike the concepts of phoneme or morpheme, which are defined based on a single modality of language, the concept of grapheme necessarily involves two modalities, written and spoken. Unsurprisingly, the bimodal implications of a grapheme has led to different authors arriving at slightly different interpretations and definitions of the term, resulting in ambiguity. As a result, scholars have questioned the usefulness of the term (Meletis, 2020, p. 78 ff.), and Unicode avoids using the term in its glossary (Haralambous & Dürst, 2019b, p. 141). Daniels (2018, p. 169) goes so far as to assert that “[t]he term “grapheme” should not be used in the study of writing systems”.
The counterargument to eschewing the term grapheme altogether is that it may amount to throwing the baby out with the bathwater. An alternative pragmatic approach is to salvage the term by refining its meaning and scope. One such attempt at re(de)fining the grapheme is that of Meletis (2020, pp. 94–96), who states that, for a particular graph to qualify as a grapheme within a given writing system, it must be interpreted as being:
- minimal, in that the graph must not be further divisible into graphic units that are themselves graphemes;
- contrastive or distinctive within a specific graphematic environment, in that, within a given writing system, substituting the graph in question for another graph of the same status should result in a distinct word or lexeme;
- linguistically significant, in that the graph in question should have a prototypical or ‘default’ relation to one or more linguistic units, such as phonemes or morphemes.
To qualify as a grapheme within a given writing system, a graph must meet all of the above criteria. That said, a grapheme need not always be unattached to other written units and necessarily occupy its own graphosegmental space; a bound graph or ‘diacritic’ that is graphosubsegmental may well act as a grapheme in a particular writing system. Conversely, within a writing system, a particular multigraph may meet the minimality criterion and qualify as a grapheme, but other multigraphs in the same system may not (Meletis, 2020, pp. 94–96). As evident, such analysis is hardly straightforward. The fraught nature of deciding whether a graph in a writing system qualifies as a grapheme will become evident in Part Two of this book.
Granular qualifying criteria aside, the fact remains that a grapheme is defined at the level of the writing system. That is, a particular graph qualifies as a grapheme of a writing system than of a script. This is evident in the discussion on allographs in the following section. A grapheme or a sequence of graphemes is conventionally enclosed in angular brackets ⟨ ⟩.
2.6 Allograph
Despite rejecting the term grapheme, Daniels (2018, p. 169) concedes that “[t]he one piece of grapheme theory that remains useful is the term allograph”. Within a given writing system, an allograph is understood as a variant form or shape of a grapheme, and is perceived by fluent literates in the language as such. It follows that, regardless of graphemic association, all allographs are necessarily graphs. The adjective graphetic may be used to describe allographic variation in a given context, much like how the adjective phonetic is used to describe allophonic variation. Allographs — and graphs in general — are shown enclosed in pipes | |.
From the definition above, it follows that the existence of allographs in a writing system is ontologically secondary, being predicated on the prior identification of graphemes. Simply put, one can talk about allographs of a particular grapheme only after one has already identified the set of graphemes in that writing system. Accordingly, graphs that belong to the same grapheme in one writing system may be understood as belonging to distinct graphemes in another system. That is, graphs that are considered allographs in complementary distribution or free variation in one writing system, may be considered contrastive graphemes in another writing system. For instance in the 𝚎𝚗-𝙻𝚊𝚝𝚗 writing system, the graphs |e ɛ E Ɛ|, whether printed or handwritten, are normally considered variants of the same grapheme, as seen in (4):
(4)
| Free variation | e | ɛ |
|---|---|---|
| E | Ɛ | |
| Complementary distribution | e | E |
| ɛ | Ɛ | |
| e | Ɛ | |
| ɛ | E |
However, in the writing system of the Ewe language in the Roman script (𝚎𝚎-𝙻𝚊𝚝𝚗), |e| and |ɛ| are considered representative of distinct graphemes – namely as ⟨e⟩ and ⟨ɛ⟩. Accordingly, the distribution of the graphs |e ɛ E Ɛ| in the Ewe-Roman writing system would be:
(5)
| Contrastive distribution | e | ɛ |
|---|---|---|
| E | Ɛ | |
| Complementary distribution | e | E |
| ɛ | Ɛ |
Similarly, in 𝚎𝚗-𝙻𝚊𝚝𝚗, |z| and |ʒ| would be considered allographs in (relatively) free variation.17 However, in the writing system of the Skolt Sami language in the Roman script (𝚜𝚖𝚜-𝙻𝚊𝚝𝚗), |z| and |ʒ| would be considered representative of distinct graphemes, as ⟨z⟩ and ⟨ʒ⟩, respectively. Similar considerations are seen in the context of graphs shared by the inventories employed by the Arabic-Arabic (𝚊𝚛-𝙰𝚛𝚊𝚋) and Sindhi-Arabic (𝚜𝚍-𝙰𝚛𝚊𝚋) writing systems, in which the shared graphs differ in graphemic status depending on the writing system (Chapter 6).
Broadly speaking, allographic variants of a particular grapheme include graphetic variants. That is, allography may be understood to include not just graphs differing in visual shape, as in |g| and |ɡ|, but also graphs differing in typographic parameters such as line weight (|𝗀| vs. |𝗴|) or calligraphic hand (|ℊ| and |𝖌|). As already outlined, classifying graphs as allographs of a particular grapheme or as representing distinct graphemes may involve grey areas. For instance, if the graphs of a script as used within a given writing system are customarily written in a particular calligraphic or visual style, the visual style may be considered indispensable to the identity of the writing system. This is illustrated by the popular perception of the Fraktur or blackletter style traditionally used to write German in the Roman script (𝖆𝖇𝖈𝖉…𝖝𝖞𝖟), or the Gaelic type used for Irish Gaelic in the Roman script (abcd…xyz). These calligraphic hands have come to be so closely associated with their respective writing systems that each of them is often considered to constitute a distinct script, independent from Roman. This is borne out by the fact that the Fraktur and Gaelic types, despite arguably being calligraphic or stylistic variants of the Roman script, have been allocated their own IETF subtags — 𝙻𝚊𝚝𝚏 and 𝙻𝚊𝚝𝚐, respectively (Phillips & Davis, 2009). Similar is the case with the Nastaliq hand of the Arabic script, which is customarily used to write the Urdu language and, consequently, has gained a status quasi-independent of the Arabic script. As a result, the Nastaliq variant of the Arabic script, too, has been assigned its own subtag — 𝙰𝚛𝚊𝚗 (Phillips & Davis, 2009). Along similar lines, the Sindhi-Arabic writing system (𝚜𝚍-𝙰𝚛𝚊𝚋) almost always appears in the Naskh calligraphic style, whether handwritten or typeset. Written Sindhi appearing in any other calligraphic style, such as Nastaliq, would be seen as typographically and aesthetically anomalous (§6.5). The phenomenon of graphetic variants being popularly perceived as constituting distinct scripts is a good reminder of how sociolinguistic factors may influence graphematic analysis and theory, and how it may well be impossible to mutually insulate graphematic factors from graphosociolinguistic ones.
Despite the fuzzy boundaries separating the graphematic and sociolinguistic dimensions, it is usually possible to distinguish between allographs that are visually distinct variants of a particular grapheme, as in |g| and |ɡ|, and those that are merely stylistic variants or different concrete instantiations of a particular graph(eme), such as |𝗀| and |𝗴|. Meletis (2020, p. 109 ff.) terms the former graphem(at)ic allographs and the latter graphetic allographs. In the context of the latter, Meletis (2020) also states that:
visual resources that are superimposed upon scripts (and thus often considered ‘suprasegmental’), including bold print, italics, etc., […]
According to Meletis, variation in the line weight or inclination of graphs may be considered the written counterpart to spoken suprasegmentals. By extension, the “visual resources” of line weight and inclination that are imposed upon graphs may be termed supragraphicals. Most often, supragraphicals such as bold and italic type serve only a graphetic function, and may influence the perception of type design or typographical aesthetics. Occasionally, they may also have a paralinguistic function, in that text printed in bold type may indicate emphasis, while italic text may suggest ‘foreignness’. However, there exist instances where a visual alternation or supragraphical feature in a given writing system may have consistent and identifiable linguistic significance by itself, raising the question of whether such a supragraphical feature is contrastive.18
Allographs need not be mutually singular, and a single allograph may alternate with a sequence of graphs or graphemes, which is seen in the case of so-called ligatures (§2.7). Finally, and like graphemes, allographs need not always occupy a separate graphosegmental space, and may be graphematically free or bound. As will be seen, several Sindhi writing systems feature free and bound allographs for vowel phones in complementary distribution. In turn, this graphematic feature significantly influences the typology of the writing systems in question (§14.1).
2.7 Additional graphetic concepts
It is noteworthy that the assumption of the graph as the basic unit of writing may not always align with Unicode’s terminology in this regard. Since 1991, the Unicode Consortium has done much of the heavy lifting in coining a technical grapholinguistic vocabulary (Haralambous & Dürst, 2019b, p. 128). However, Unicode’s mandate is to act as a standard for the digital representation of writing, which inevitably gives its terminology a computational bent. In Unicode, the basic or atomic unit (Haralambous & Dürst, 2019b, p. 139) is the character, defined as “[t]he smallest component of written language that has semantic value” (Unicode, 2025a). Significant here is the fact that a particular character is “distinguished from others by its [underlying] meaning, not its specific [superficial] shape” (ScriptSource, 2022a). The latter concept is termed glyph, understood as the “actual, concrete image” depicting a particular character (Unicode, 2025a), or the “shape that is the visual representation of a character” (ScriptSource, 2022a). Thus, the terms character and glyph refer to two sides of the same graphical coin, with the former denoting the underlying, abstract side, and the latter the surface, concrete side. The mapping of glyphs to characters is determined by the writing system and, consequently, the graphosocial context. As Haralambous and Dürst (2019b, p. 145) state, “graphs are defined as units in a graphetic system, while glyphs are defined as socially recognizable renderings of a given character”. For a detailed critique of the terms glyph and character and their homology with graph and grapheme, see Haralambous and Dürst (2019b).
Since this book is oriented towards writing systems per se, and not so much towards their digital representation, it will prefer the term graph and its derivatives, and relegate the terms character and glyph to restricted contexts, such as East Asian writing systems or the sociolinguistic framework of Biscriptality (§2.10).
Related to the concept of glyph is that of basic shape (Haralambous & Dürst, 2019b, p. 129; Meletis, 2020, p. 41), translated from the German original Grundform (Rezec, 2009). In this book, a basic shape will be taken to mean an individual shape, outline, skeleton or template that forms the graphetic basis of one or more graphs in a writing system. For instance, in the context of the Roman script’s graph superset, |A|, |C|, |a| and |ɑ| are graphs that also qualify as basic shapes. In contrast, the graphs |á| and |ç| are not basic shapes; rather, they comprise graphetic enhancements of the basic shapes |a| and |c|, respectively. Thus, a graph in a writing system may comprise just a basic shape, or a basic shape augmented by graphetically distinctive features such as dots or lines. Besides, the graph inventories of homoscriptal writing systems may comprise distinct subsets of basic shapes and their derivatives. Thus, the Roman-script basic shapes |þ ð| are present in the graph inventory of the Icelandic-Roman (𝚒𝚜-𝙻𝚊𝚝𝚗) writing system, but not in the homoscriptal 𝚎𝚗-𝙻𝚊𝚝𝚗 writing system. Furthermore, since basic shapes are graphetic entities (Meletis, 2020, p. 23), their phonological or linguistic values across writing systems are not directly relevant to their analysis. In 𝚎𝚗-𝙻𝚊𝚝𝚗, the basic shapes |a| and |ɑ| would, in most contexts, be considered allographs and, therefore, homophonous. In contrast, |a| and |ɑ| are considered contrastive and heterophonous in the Roman-script-based writing system of the Fe’efe’e language of Cameroon (Priest & Constable, 2005, p. 8). The basic shapes |a| and |ɑ| are also contrastive and heterophonous in transcriptions based on the International Phonetic Alphabet (Haralambous & Dürst, 2019b, p. 129; Neef, 2015). Yet, regardless of context and phonological values, |a| and |ɑ| remain graphetically distinct basic shapes.
Some of the most revealing and illustrative examples of basic shapes and their derivatives are found in Arabic-script-based writing systems. In the graph superset of the Arabic script, |ح| constitutes a basic shape, as well as a standalone graph in the subinventories of the Arabic-Arabic (𝚊𝚛-𝙰𝚛𝚊𝚋), Persian-Arabic (𝚏𝚊-𝙰𝚛𝚊𝚋) and Sindhi-Arabic (𝚜𝚍-𝙰𝚛𝚊𝚋) writing systems. The graph |ج|, formed by adding a dot at a specific location within the graphetic skeleton of |ح|, also acts as a standalone graph in all three writing systems. In contrast, the derivative graph |چ| occurs in 𝚏𝚊-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙰𝚛𝚊𝚋 but not in 𝚊𝚛-𝙰𝚛𝚊𝚋. Another derivative graph, |ڄ|, is exclusive to 𝚜𝚍-𝙰𝚛𝚊𝚋. In the context of Arabic-script graphetics, a basic shape such as |ح| is known as a rasm.19 Originally, the term rasm denoted the entire inventory of basic shapes used in writing Quranic Arabic (Daniels, 2013, pp. 412–413; Gacek, 2009, p. 141). Of late, though, scholars have begun to use rasm to denote an individual basic shape in the Arabic script inventory (Kurzon, 2013), which I adopt in this book. If necessary to distinguish between the two uses of the term, an individual basic shape may be termed a rasmic form. Accordingly, |ح| is a rasm (or rasmic form) that acts as the graphetic skeleton for the derivatives |ج چ ڄ|. That said, the actual occurrence of these derivatives in the graph inventories of various writing systems is a graphematic decision that is somewhat unpredictable and not directly related to their mutual graphetic similarity. Furthermore, in the context of Arabic-script-based writing, each so-called ‘positional variant’ of a graph may also be considered a rasm in itself (Bauer, 1996; see also §6.1).20 That is, each of the graphs |ح ﺣ ﺤ ﺢ| is also a rasm, although the distinctness of |ﺣ| and |ﺤ| is debatable. It follows that considering the rasms |ح ﺣ ﺤ ﺢ| to be allographs is, again, a graphematic decision rather than a graphetic one.
Given the precision and potential utility of the term rasm, this book will extend the term beyond its traditional Arabic-script contexts. In this book, rasm will be considered synonymous with basic shape and used to denote graphetic skeletons or templates in any graph inventory, regardless of graphetic origin. Thus, in the graph superset of the Roman script, |a| and |c| are rasms or rasmic forms, while |á| and |ç| are derived or augmented forms.
Despite the usefulness of the concept, identifying the graphetic boundaries of a rasm is not always straightforward. For instance, in the Roman-script graph |i|, the dot or tittle has traditionally been considered an intrinsic part of the body of the graph, and not a diacritic. According to this view, |i| as a whole may be viewed as a rasm. However, in 1928, a Roman-script-based writing system was introduced for the Turkish language (𝚝𝚛-𝙻𝚊𝚝𝚗), whose graph inventory featured a dotless |ı| distinct from dotted |i|. Graphetically, the introduction of dotless |ı| effectively made dotted |i| into a derivative, in the process depriving the latter of rasmic status. Furthermore, since a rasm is a graphetic entity that exists at the level of script, the creation of dotless |ı| may be argued to impact the Roman-script graph inventory as a whole, irrespective of writing system. As a result, the derived form of dotless |ı| effectively emerges as the rasmic form, and dotted |i| as the derived one. This suggests that graphetic primacy is independent of ontogenetic primacy. Consequently, it may be possible for a rasm to lose rasmic status if a graphetic element were to be hived off from it and spun off into an independent graph. This process may, in turn, affect the graphematic status of graphs within a particular writing system.
A corollary of the above observation is the difficulty in pinpointing what may be called the graphetic baseline — or, more precisely, the graphosegmental baseline — of a rasm. For instance, the Devanagari-script graph inventory features the graphs |ज| and |ज्◌|. On purely graphetic grounds, |ज्◌| may be considered the rasmic form, and |ज| the derived form. In comparison, when faced with the Devanagari-script graphs |ट| and |ट्ट|, it is much harder to say whether |ट्ट| is simply a derivative of |ट|, or should be considered graphetically rasmic in its own right. Such rasmic fuzziness also exists within the Roman script inventory. Historically, the rasm |C| acted as the graphetic foundation for |G|, as did |V| for |W| (Gnanadesikan, 2009, pp. 231, 248). Hence, should |G| and |W| be considered derivatives of rasmic |C| and |V|, respectively? Or have |G| and |W| undergone sufficient graphetic evolution to be considered rasmic in themselves?
The graph |W| is also described in the literature as a ligature of |V| (Gnanadesikan, 2009, p. 259). A ligature is commonly understood as a graph formed by merging two independent graphs (Haralambous & Dürst, 2019b, p. 151). Yet, the concept of ligature encompasses certain graphetic and phonological presuppositions, which require unpacking. Graphetically, ligatures exist on a spectrum of transparency. For instance, the graph superset of Devanagari contains the graphs |ष्◌| and |ट|, which may be graphetically merged or ligated as |ष्ट|. However, they may also be represented as |ष्ट|, with a greater degree of graphetic coalescence compared to |ष्ट|. Accordingly, at what point does a graphetic merger result in an identifiably independent graph? As expected, this is difficult, if not impossible, to pinpoint. Conversely, within a particular writing system, a particular graph may be considered a ‘ligature’ of two other graphs. Thus, in the Hindi-Devanagari (𝚑𝚒-𝙳𝚎𝚟𝚊) writing system, |क्ष| is considered a ligature of the graph sequence |क्ष|, while |क्त| is considered a ligature of the graph sequence |क्त|. In the Arabic-Arabic (𝚊𝚛-𝙰𝚛𝚊𝚋) writing system, |لا| is considered a ligature of the right-to-left graph sequence |لا| (Haralambous & Dürst, 2019b, pp. 151–152). Graphetically, there appears to be little similarity between |क्ष|, |क्त| and |لا| on the one hand, and |क्ष|, |क्त| and |لا| on the other. In fact, |क्ष|, |क्त| and |لا| may well qualify as rasms within their respective graph inventories. Yet, |क्ष|, |क्त| and |لا| are commonly considered ‘ligatures’ of |क्ष|, |क्त| and |لا|, respectively, based on the fact that they are homophonous. That is, the writing system of 𝚑𝚒-𝙳𝚎𝚟𝚊 assigns both |क्ष| and |क्ष| the phonological value of [kɕ(ə)], making them homophonous and, hence, allographs of each other. Likewise, 𝚑𝚒-𝙳𝚎𝚟𝚊 considers |क्त| and |क्त| to be allographs representing [kt̪(ə)]. Along similar lines, the writing system of 𝚊𝚛-𝙰𝚛𝚊𝚋 considers |لا| to be homophonous and allographic with |لا|, with both denoting /laː/.21 Taken together, it emerges that, within a particular writing system, a rasm or graphetically distinct form within a graph inventory may be considered a ‘ligature’ of other graphs in that inventory based primarily on mutual homophony and allography. The phonological basis of the label ‘ligature’ is further revealed by the fact that, depending on the writing system, certain ligatures may be considered mandatory and others optional (Haralambous & Dürst, 2019b, pp. 151–152). This corresponds to allographs in complementary distribution and free variation, respectively. For instance, the writing system of 𝚊𝚛-𝙰𝚛𝚊𝚋 requires all instances of |لا| to be mandatorily substituted with |لا|, making them allographs in complementary distribution. Along similar lines, the writing system of 𝚑𝚒-𝙳𝚎𝚟𝚊 considers |क्ष| a mandatory ‘ligature’ or allograph of |क्ष|, putting the two forms in complementary distribution. In contrast, 𝚑𝚒-𝙳𝚎𝚟𝚊 licenses |क्त| as well as |क्त|, making them free variants of each other. These examples suggest that the mandatory or optional nature of a so-called ligature — that is, whether it is in complementary distribution or free variation with its allographs — is decided at the level of writing system, particularly its orthography (§2.9), and not at the level of graph inventory. As seen, written elements commonly described as ligatures may justifiably be considered rasms in their respective graph inventories.
Thus, it emerges that the use of the term ligature to refer to graphetic fusion as well as phonological equivalence renders it polysemous. Consequently, the term will be judiciously used in this book, primarily to denote graphetically transparent forms like |ष्ट| that lie on the boundary between qualifying as a sequence of a graphs or as an independent graph by itself. Although the term conjunct may be suggested as an alternative, this term may denote either a sequence of graphs or a sequence of phones (Unicode, 2025a). Since conjunct may refer either to a graphical entity or to a phonological one, it, too, has the potential to prove ambiguous and will also be avoided to the extent possible in this book.
In the context of Indic writing systems, a concept closely related to those of ligature and conjunct is that of akshara. This term has been variously understood and depicted in the academic literature, due to which an unambiguous definition of this term is lacking. Consequently, the term is avoided in this book. For a discussion on the concept of akshara and a proposed definition, see Iyengar (2024).
Finally, when it comes to digital encoding, an individual character or glyph in Unicode may represent graphs that are rasmic, graphetically augmented or of graphetically ambiguous status (Unicode, 2025a). Where Unicode assumes greater importance is in the availability of graphetic forms for enabling electronic text. Since grapholinguistic publishing in the digital era presupposes the availability of necessary graphs or glyphs — by way of fonts containing such glyphs — it follows that the lack of suitable glyphs and fonts represents a significant hurdle for authors in the field. As Haralambous & Dürst (2019b, p. 144 & footnote) observe, typographers and font designers effectively become the “gatekeeper[s]” of glyphs, especially in rare or understudied scripts and writing systems. As a result, authors without the necessary design competencies to design the requisite glyphs and fonts themselves may be forced to use suboptimal existing glyphs, in the process potentially undermining the perceived authenticity and credibility of their work. While much care has been taken to custom-design any necessary glyphs and fonts for this book, certain typographical and aesthetic shortcomings may well remain.
2.8 Phonography and Logography
Most writing systems tend to contain a mix of phonographic and logographic elements (Sampson, 2015, p. 24; Sproat & Gutkin, 2021). For instance, the graph inventory of the predominantly phonographic English-Roman (𝚎𝚗-𝙻𝚊𝚝𝚗) writing system also includes the ampersand, currency symbols and numerals, the last of which are also termed digits or ciphers (Honda, 2021). Logography in a writing system may also manifest at a broader level, with various functions. According to Gnanadesikan (2017a, p. 15), the distinction between the English-language homophones spelt ⟨deer⟩ and ⟨dear⟩ in 𝚎𝚗-𝙻𝚊𝚝𝚗 is essentially logographic in nature. A more illustrative example from French is that of the utterance /aʁive/ corresponding to at least four distinct forms in the French-Roman (𝚏𝚛-𝙻𝚊𝚝𝚗) writing system: ⟨arrivé⟩, ⟨arrivée⟩, ⟨arrivés⟩, ⟨arrivées⟩, all of which mean ‘arrived’ but differ in the referent number and gender they denote. Logograms may also occur as allographs of phonograms, as attested by the Marathi-Devanagari (𝚖𝚛-𝙳𝚎𝚟𝚊) spellings ⟨ॐकार⟩ and ⟨ओमकार⟩. Both written forms reflect the pronunciation /omkaɾ/ and mean ‘the symbol Om’. Here, the benedictory logogram |ॐ| [om] occurs as an allograph in free variation with the homophonous phonogram sequence |ओम|. Whereas these examples illustrate how predominantly phonographic writing systems also comprise logographic elements, the converse is also true. In fact, Daniels (1996a, p. 4) states that writing that is purely logographic may not exist.
Just as the line between phonograms and logograms may be blurry, the line where logography crosses the line into semasiography may also be difficult to determine. Aptly exemplifying the fuzzy boundary in question is the status of punctuation marks across writing systems. On the one hand, punctuation marks may be interpreted as minimal, contrastive and linguistically significant and, hence, may even qualify as graphemes (§2.5). On the other hand, it may be argued that punctuation marks are not so much linguistically meaningful as paralinguistically, in that they graphically indicate pauses, emphasis or intonation patterns. On this basis, punctuation marks may be considered less glottographic and more semasiographic. Scholarly opinion on the status of punctuation marks is equivocal. Neef (2015, pp. 711–713) considers logograms, ciphers and punctuation marks as “belong[ing] to the script but not to the writing system”. Meletis (2020, p. 95) admits that the status of punctuation marks in a writing system is yet to be suitably resolved. In the absence of epistemological and terminological consensus, this book will tentatively categorise and analyse numerals, punctuation marks and certain benedictory symbols within a given writing system as logograms.
Also worth remembering is that a graph is a phonogram or logogram within the context of a particular writing system. Among homoscriptal writing systems, certain graphs used as logograms in one system may be used as phonograms in another, and vice versa. For instance, the Squamish language when written in the Roman script (𝚜𝚚𝚞-𝙻𝚊𝚝𝚗) uses the graph |7| to denote /ʔ/ (Dyck, 2004). The Roman-script writing systems of several Khoisan languages employ the graph |ǃ| to denote an alveolar click, coinciding with IPA usage (DOBES, 2017). A 1993 proposal for writing the Turkmen language in the Roman script (𝚝𝚔-𝙻𝚊𝚝𝚗) listed |$| and |¢| as uppercase and lowercase allographs for the phoneme /ʃ/ (Clement, 2008; Pedersen, 2003).
Graphematically, utilising a graph as a logogram in one context and as a logogram in another is completely plausible. Sociolinguistically, and especially within a writing community or graphosphere (§2.9) that is largely monoscriptal, the use of logograms in a phonographic function may be implicitly seen as transgressing established conventions and, consequently, viscerally resisted. At best, such usage may be looked upon as a grapholinguistic curiosity. At worst, they may cause heated debate, and have ramifications for the perceived violators of graphematic and graphosociolinguistic norms.22 Conversely, the absence of such debate in a writing community and a diversity of scribal practices may point to the lack of importance given to graphematic standardisation in that community. This, in turn, raises critical questions for our conception of standardisation, spelling and orthography.
2.9 Spelling and Orthography
Just as phonotactics is understood as the restrictions on how phonological elements within a language can combine with each other, graphotactics refers to the “restrictions on ways in which the elements of a writing system may combine with each other” (Meletis, 2020, p. 131). As with allography, two subtypes of graphotactic rules may be identified depending on their level of applicability. Rules that govern the combination and manifestation of concrete graph shapes fall under graphetic graphotactics, whereas those governing the co-occurrence of graphs are covered by graphematic graphotactics. As the names suggest, the former merges into the domains of calligraphy and typography, while the latter overlaps with rules and conventions regarding spelling and orthography. Evidently, a writing system comprising a graphetically simple inventory may not require a separate graphetic graphotactics, whereas one with a (nearly) biunique set of correspondences between spoken and written units may render a distinct graphematic graphotactics redundant (Meletis, 2020, p. 133). Consequently, and depending on the characteristics of the writing system being studied, it may be possible to subsume graphotactic considerations under other disciplines and dispense with a standalone category of graphotactics.
Most scholarly works on writing systems do not provide an explicit definition of the concept of spelling. An exception is Coulmas (1996a, p. 477), who defines spelling as the conventions for using the graphs of a writing system to write the language in question. In a sense, spelling bears similarities to pronunciation, as a popular if imprecise term for how smaller linguistic units — be they written or spoken — are generally combined and collectively realised. Coulmas considers orthography to be a codified set of spellings or spellings rules, which aligns with Daniels and Bright’s (1996) definition of the term (§2.3).23 According to Coulmas, the distinction between a spelling system and orthography lies in the presence of codification, be it implicitly by longstanding tradition or explicitly by official decree. In the absence of any discernible codification, it becomes problematic to assert that the writing system possesses an orthography (Coulmas, 1996b, p. 1380). Instead, such a writing system may be considered a ‘bare’ graphematic system with generally accepted graph-phone correspondences but an unconstrained graphematic solution space.
Coulmas’ characterisation of orthography as an optional add-on that codifies and constrains graphematic manifestations is reflected in the structure of the Modular Theory. The MT posits orthography as a third module superimposed over the graphematic module. Also, the orthographic module is considered optional, and a writing system may, in principle, comprise just a graph inventory and a graphematic system (but see Honda (2021)). As alluded to in Section 2.4, a graphematic system featuring biunique correspondences between spoken and written units and, consequently, a predictable set of licensed spellings, may have limited use for an orthographic module (Meletis, 2020, p. 28). However, if a graphematic system features nonbiunique correspondences between spoken and written forms, it may require an orthographic module to constrain its graphematic solution space. Thus, an overlaid orthographic module:
prescribes how to write correctly within the limits of the graphematic solution space. This module particularly aims at constant spellings of words.
As Neef’s statement implies, underpinning the concept of orthography is the notion of ‘correctness’ and, by extension, prescriptivism. Thus, the graphematic module simply generates a set of possible spellings without prejudice, so to speak. In contrast, the orthographic module restricts these possibilities, and effectively prescribes the ‘correct’ spellings of words.24 In terms of orthography subtypes, the MT aligns with Coulmas’ (1996a, p. 477) observations mentioned above. Thus, an orthography may develop implicitly from within the graphematic system as a set of practices emerging organically from the collective practice of reader-writers and stabilising over time. This is an internal, implicit or a bottom-up orthography. Alternatively, an orthography may comprise a set of rules decreed by a language body, typically one with governmental or official authority. This counts as an external, explicit or top-down orthography. Neef (2015) labels the former type a systematic orthography and the latter a conventional one.25 According to this model, the English-Roman writing system would be considered to have a systematic orthography codified not by a quasi-official linguistic authority but by multiple private lexicographic institutions worldwide. In contrast, the German-Roman (𝚍𝚎-𝙻𝚊𝚝𝚗) writing system possesses a conventional orthography, given the greater role played by official bodies in its codification (Meletis, 2020, p. 155 footnote 172). That said, distinguishing the two orthography types is not always straightforward. For instance, an externally-imposed orthography is not conjured ex nihilo; rather, it typically comprises a regularisation of existing system-internal practices. Similarly, an orthography that emerges from within the system becomes externally imposed when promulgated by a lexicographic institution. As a result, it may be difficult to definitively state what subtype of orthography a particular writing system possesses, or whether it possesses an orthography at all (Meletis, 2020, p. 155). As demonstrated in this book, this dilemma is frequently encountered across most, if not all, of Sindhi’s writing systems.
In the context of phonographic writing systems, a graphematic system with nonbiunique correspondences between phones and graphs may be of two types (Osterkamp & Schreiber, 2021, p. 193). If a particular phone may be represented by more than one graph — that is, if there is homophonous heterography — the number of spelling variants licensed by the graphematic solution space will increase. Conversely, if several phones map onto the same graph — namely in the event of heterophonous homography — the number of spelling variants may be fewer, but the difficulty of decoding spellings increases. Both situations may be addressed by an orthography. In cases of homophonous heterography, the orthography may pick a particular spelling for a particular lexico-semantic entity. As alluded to in Section 2.8, the English utterance /dɪə(ɹ)/ may be spelt ⟨deer⟩ or ⟨dear⟩ in 𝚎𝚗-𝙻𝚊𝚝𝚗, as both spellings are licensed by its graphematic solution space. It is the orthographic module that mandates the spelling ⟨deer⟩ or ⟨dear⟩ depending on the meaning of /dɪə(ɹ)/ in a given context. In cases of heterophonous homography, where the choice of written forms is limited, the orthography may prescribe — or seek to prescribe — spellings not licensed by the graphematic solution space (Meletis, 2020, p. 158). An orthography may also legitimise extrasystemic spellings for reasons of etymology or prevalence, as in 𝚎𝚗-𝙻𝚊𝚝𝚗 ⟨tsunami⟩ or 𝚍𝚎-𝙻𝚊𝚝𝚗 ⟨Computer⟩. Within Sindhi’s writing systems, both homophonous heterography and heterophonous homography are attested, and offer valuable insights to further our understanding of these phenomena.
Within the MT, the relation between the orthographic module and the graph inventory module remains underresearched. In particular, the influence orthography has on the graph inventory of a writing systems is worthy of further investigation. For instance, the German-Roman writing system as used in Germany (𝚍𝚎-𝙻𝚊𝚝𝚗-𝙳𝙴) makes use of the grapheme ⟨ß⟩ /s/, while the German-Roman writing system as used in Switzerland (𝚍𝚎-𝙻𝚊𝚝𝚗-𝙲𝙷) does not. Words featuring ⟨ß⟩ in 𝚍𝚎-𝙻𝚊𝚝𝚗-𝙳𝙴 are spelt in 𝚍𝚎-𝙻𝚊𝚝𝚗-𝙲𝙷 with ⟨ss⟩ instead. Thus, 𝚍𝚎-𝙻𝚊𝚝𝚗-𝙳𝙴 and 𝚍𝚎-𝙻𝚊𝚝𝚗-𝙲𝙷 differ in their graph inventories. Yet, scholarly and popular opinion generally describes this phenomenon as a difference in the orthographies of 𝚍𝚎-𝙻𝚊𝚝𝚗-𝙳𝙴 and 𝚍𝚎-𝙻𝚊𝚝𝚗-𝙲𝙷 (Bunčić, 2016c, p. 66; Meletis, 2020, p. 373). Similarly, the Russian-Cyrillic (𝚛𝚞-𝙲𝚢𝚛𝚕) writing system underwent significant modifications in 1708 and 1917, which impacted not just the spellings of words but also graph-phone correspondences, the graph inventory and the calligraphic style of the graphs (Coulmas, 1996b, pp. 107, 447). Despite affecting the size and composition of the 𝚛𝚞-𝙲𝚢𝚛𝚕 graph inventory, these reforms are commonly understood as orthographic reforms (Bunčić, Kislova, & Rabus, 2016). The distinct graph inventories used to write Mandarin, commonly known as Traditional and Simplified characters, have also been characterised as a distinction in orthography (Klöter & Bunčić, 2016). A particularly intriguing and illustrative case in this context is that of the Azeri language in the Roman script (𝚊𝚣-𝙻𝚊𝚝𝚗). Over the twentieth century, Azeri has been written in the Roman script but at least three distinct graph inventories and, consequently, with differing graph-phone correspondences. Again, this situation is commonly portrayed as Azeri having been written in different Roman-script orthographies (Coulmas, 1996b, pp. 29–30). In the context of scripts featured in this book, modifications to the Uyghur-Arabic (𝚞𝚐-𝙰𝚛𝚊𝚋) writing system in the late twentieth century (Coulmas, 1996b, p. 525), and to the Kashmiri-Devanagari (𝚔𝚜-𝙳𝚎𝚟𝚊) writing system in the early twenty-first century (Ishida, 2021) have been characterised in terms of orthographic reform, despite the modifications entailing the addition of new graphs and the recalibration of graph-phone correspondences.
Thus, in terms of the MT, it needs to be recognised that a change in the orthographic module may impact not just the graphematic module, but also the graph inventory. Such an approach also aligns somewhat with the format of IETF language tags. Within the language tag 𝚍𝚎-𝙻𝚊𝚝𝚗-𝙳𝙴, the subtag DE denotes the presence of the Germany-specific orthographic module and, by extension, the Germany-specific graph inventory that includes ⟨ß⟩. Likewise, the 1708 and 1917 subvariants of the Russian-Cyrillic writing system are assigned the IETF language tags 𝚛𝚞-𝙲𝚢𝚛𝚕-𝚙𝚎𝚝𝚛𝟷𝟽𝟶𝟾 and 𝚛𝚞-𝙲𝚢𝚛𝚕-𝚕𝚞𝚗𝚊𝟷𝟿𝟷𝟽, respectively. However, this is not always the case with IETF subtags. Although academics have described the Traditional and Simplified Hànzì graph inventories for Mandarin as distinct orthographies, the IETF considers them to be distinct scripts and assigns each of them a separate script subtag. Thus, Mandarin in Traditional and Simplified Hànzì bear the language tags 𝚌𝚖𝚗-𝙷𝚊𝚗𝚝 and 𝚌𝚖𝚗-𝙷𝚊𝚗𝚜, respectively. The vacillation in denoting distinct graph inventories, by using orthography subtags on the one hand and script subtags on the other, reiterates how writing system taxonomy remains a fraught area (§2.3).
Another grey area in this context is that of orthography-induced changes in graph inventory and correspondences between spoken and written units that may alter the writing system’s typological category. If an orthographic reform within a writing system introduces new graphs into its inventory, and/or reassigns the linguistic values of graphs, the result may be a writing system whose typological category is different from the original. This issue is taken up in detail in Section 2.10. Notwithstanding terminological vacillation, there appears to be considerable justification to recognise the mutual dependency of the graph inventory and orthography modules within a writing system. Doing so allows for a robust and transparent analysis of the variations observed within and across writing systems. Accordingly, the mutual interdependence of the various modules within a writing system may be schematically represented as shown in Figure 2.1 (see also Meletis, 2020; Neef, 2015).
Sources: Neef (2015, p. 718) and Meletis (2020, p. 21)
It follows from the above that most writing systems that are or have been in active use can be understood to possess an orthographic module. In Neef’s (2015, p. 719) words, the “ideal” writing system comprising just a bare graphematic system with biunique correspondences between spoken and written units is unlikely to exist in practice. Even if one did exist, asynchronous phonological and graphematic evolution would eventually disrupt the one-to-one mapping between its spoken and written units. Consequently, Neef considers the presence of an orthographic module to be the “normal case”.
The MT also has the potential to act as a graphematic mirror to certain (grapho)sociolinguistic phenomena. Analogous to a speech community that shares a common language, it is possible to conceive of a “writing community” (Coulmas, 1996a, p. 556) or graphosphere (Franklin, 2011). Depending on the strictness of interpretation, a graphosphere may indicate a group of people with a shared orthography (𝚎𝚗-𝙻𝚊𝚝𝚗-𝚄𝚂 versus 𝚎𝚗-𝙻𝚊𝚝𝚗-𝙶𝙱), a shared writing system (𝚎𝚗-𝙻𝚊𝚝𝚗) or simply a shared script without a shared language (𝙻𝚊𝚝𝚗). In Coulmas’ (1996a, p. 556) opinion, once writing systems or parts thereof become established, “they define cultural and religious spheres and thus communities”. This sociolinguistic interpretation may be neatly expressed in graphematic terms using the MT. The greater the number of shared modules (script, language, orthography…) among communities, the greater the emic and etic feeling that those communities belong to the same graphosphere.
Moving further into the graphosociolinguistic realm, the process of writing down a previously spoken-only language for the first time — sometimes unfortunately characterised as ‘reducing’ a language to writing — may be termed graphisation (Ferguson, 1996 [1968], p. 41). Here, ‘reduction to writing’ should be understood as “creation or adoption of a writing system” (Gold, 1982). With time, a pan-regional and pan-social norm may develop for the language in question, both in speech and in writing. The development of such norms usually amounts to standardisation (Ferguson, 1996 [1968], p. 41). Within the written domain, standardisation may include the development of a normative graph inventory and spelling rules, namely an orthography. The process of developing an orthography is orthographisation, by analogy with graphisation. Sometimes, the process of graphisation and orthographisation may coincide (Lüpke, 2011). However, in the context of Sindhi, the two are unarguably distinct. Hence, this book will maintain a strict distinction between these two concepts and terms, and use them accordingly.
Near-synonymous with graphisation is literisation, which Siegel (1981, p. 20) uses to mean “development, both planned and unplanned, of a previously unwritten language into a written one”. Evidently, the process of literisation would involve at least some degree of standardisation and orthographisation. Pollock (1998, p. 41) draws a further distinction between literisation and literarisation, where the former term indicates the act of committing a spoken-only language into writing, while the latter refers to the ongoing deployment of a now-literised or graphised language for literary purposes. In turn, these processes may overlap with those of transliteration and transcription (§2.10), but remain distinct from them.
In this book, where no official IETF language subtag exists for a specific orthographic module within a writing system, a private use subtag will be assigned. The term ‘private use’ indicates that the subtag is not approved or specified by the IETF, and is employed purely for nomenclatural expedience. All private-use subtags in this book will have a preceding 𝚡-, in line with the IETF-prescribed format.
2.10 Writing system typologies
Writing systems may be divided into subcategories based on their internal structure, or on their use in everyday settings. In simple terms, we can classify writing systems based on how they are, or what they are used for. The former may be considered a graphematic typology of writing systems, while the latter constitutes a sociolinguistic typology.
2.10.1 Graphematic or structural typology
A graphematic or structure-based typology of writing systems focuses on the nature of mapping or correspondence between a writing system’s graphs and their linguistic values. As outlined in Section 2.8, writing systems may be graphematically subcategorised into logographies and phonographies. In turn, phonographies — the focus of this book — may be further classified into syllabaries and segmentaries (Gnanadesikan, 2017a; Sampson, 2015). In a syllabary, an individual graph corresponds to a phonological syllable, whereas, in a segmentary, the individual graph corresponds to a phonological segment, namely a consonant or a vowel. Thus, syllabaries and segmentaries differ in terms of the basic grain size represented by their graphs — the phonological syllable in the former, and the phonological segment in the latter (Gnanadesikan, 2017a). Segmentaries themselves may be further divided into the kinds of segments they represents. One that comprises graphs for consonantal segments only, and leaves vowel segments unrepresented in writing, is termed a consonantary or abjad (Daniels & Bright, 1996, p. xxxix). In contrast, vowelled segmentaries that contain graphs for consonant as well as vowel segments may be of various subtypes. Figure 2.2 summarises the graphematic typology of writing systems described thus far.

Source: Sampson (2015, p. 24)
The prototypical vowelled segmentary is an alphabet, in which phonological consonants and vowels are denoted by distinct graphs, usually of graphetically comparable size (Daniels & Bright, 1996, p. xxxix). However, other recognised categories of writing systems, such as alphasyllabaries and abugidas, are also graphematically capable of denoting phonological consonants and vowels with distinct graphs. In an alphasyllabary, graphs denoting phonological vowels generally have two allographs, free and bound (Bright, 1999), whose distribution is determined by phonological and graphotactic-orthographic considerations. In general, if a phonological consonant is followed by a phonological vowel, the latter is shown with the appropriate bound allograph.26 The distinctive feature of an abugida is that a basic graph in the inventory corresponds to a sequence of a distinct phonological consonant and a common phonological vowel. The systematically common phonological vowel is known as the ‘inherent’ or ‘default’ vowel. Its quality depends on the language represented. Against the above, Daniels (1996a, p. 4) and Bright (1999) characterise the graphematic distinction among alphabets, alphasyllabaries and abugidas as a ‘formal’ versus ‘functional’ one. Gnanadesikan (2017a) refines this distinction into one of which vowel segments are overtly represented in the graphematic system, versus how they are graphematically realised. Yet, there remain areas of overlap among these definitions. For instance, in Hindi-Devanagari (𝚑𝚒-𝙳𝚎𝚟𝚊), postconsonantal vowels are shown using the appropriate bound allograph for the vowel, which makes the writing system an alphasyllabary. Concurrently, 𝚑𝚒-𝙳𝚎𝚟𝚊 denotes all phonological vowels overtly except one, with the vowel /ə/ considered ‘inherent’ to basic graphs denoting phonological consonants. This makes the writing system an abugida. Thus, it is possible for a particular writing system to simultaneously fall into multiple categories. On this basis, harnessing Gnanadesikan’s (2017a) dimensions of which and how along different axes, Iyengar (2023) argues that the key distinguishing factor among various types of vowelled segmentaries is the graphematic (γ) representation of a phonological (φ) vowel after a phonological consonant. Based on the graphematic and phonological manifestation of a postconsonantal vowel, Iyengar proposes a four-way classification of vowelled segmentaries, shown in Figure 2.3.

Adapted from Iyengar (2023)
As seen in Figure 2.3, Iyengar introduces the term plenary to denote a writing system in which all phonological vowels are overtly written, with none considered ‘inherent’ to a graph.27 This property distinguishes a plenary from an abugida, the latter of which requires one phonological vowel to be systematically ‘inherent’ in graphs representing consonants. Based on the paradigm outlined in Figure 2.3, Hindi-Devanagari (𝚑𝚒-𝙳𝚎𝚟𝚊) is an abugidic alphasyllabary, which is harmonious with its graphematic properties described earlier. In contrast, 𝚎𝚗-𝙻𝚊𝚝𝚗 is a plenar alphabet, since it represents phonological vowels using free allographs at all times, and represents them overtly. Sharing graphematic similarities with both 𝚑𝚒-𝙳𝚎𝚟𝚊 as well as 𝚎𝚗-𝙻𝚊𝚝𝚗 is the writing system for the Divehi or Maldivian language based on the Thaana script (𝚍𝚟-𝚃𝚑𝚊𝚊). In 𝚍𝚟-𝚃𝚑𝚊𝚊, postconsonantal vowel phones are shown as bound allographs, making it an alphasyllabary like 𝚑𝚒-𝙳𝚎𝚟𝚊. However, all vowel phones are represented overtly, making it a plenary like 𝚎𝚗-𝙻𝚊𝚝𝚗 (Gnanadesikan, 2017b). Finally, the Mongolian language written in the ’Phags-pa script (𝚖𝚗-𝙿𝚑𝚊𝚐) denotes vowel phones only as free allographs, making it an alphabet, but also assigns an inherent vowel phone to each of its consonant graphs, making it an alphasyllabary (Bright, 1999; Gnanadesikan, 2017a).
Coupled with the double-barrelled nomenclature of writing systems adopted in this book, the typological framework proposed in Figure 2.3 helps prevent conflating homoscriptal writing system types with each other. Thus, the Hebrew language written in the Hebrew script (𝚑𝚎-𝙷𝚎𝚋𝚛), with all vowels overtly represented, constitutes a plenar alphasyllabary (Bright, 1999, p. 50 footnote 2). In contrast, Yiddish in the Hebrew script (𝚢𝚒-𝙷𝚎𝚋𝚛) shares graphematic similarities with 𝚎𝚗-𝙻𝚊𝚝𝚗 in functioning as a plenar alphabet (Aronson H. I., 1996). This observation, in turn, reinforces the idea that writing system typology is actually graphematic typology (Meletis, 2020, p. 393) rather than script typology. In other words, writing systems fall into a particular category based on their graphematic makeup, and not because of some inherent property within the script itself. Additionally, and as alluded to in Section 2.9, the framework in Figure 2.3 is consistent with the notion that an orthography-induced modification to the graph inventory and/or graph-phone correspondences within a writing system may cause the system to deviate from its original type. Such a position also reaffirms the interdependent nature of a writing system’s modules.
Since this book deals only with segmentaries, speaking of ‘phonological vowels’ and ‘phonological consonants’ on the one hand, and ‘graphematic vowels’ and ‘graphematic consonants’ on the other, is theoretically justified and consistent. To allow for brevity and compactness, the Greek graphs φ and γ will be used as notations to indicate ‘phonological’ and ‘graphematic’, respectively (Haralambous, 2019a). Thus, a graphematic consonant — namely a consonant graph — will be represented as γ-consonant. Likewise, a phonological vowel or vowel sound will be denoted by φ-vowel. The notation also lends itself well to denoting non-segmental grapholinguistic units, such as φ-syllable for ‘phonological syllable’.
The study of written Sindhi’s graphematic and sociolinguistic history reveals how certain graphematic labels used to describe the language’s writing systems — such as abjad or alphasyllabary — were actually based on sociolinguistic practices. The following section sheds more light on the issue.
2.10.2 Sociolinguistic or contextual typology
In contrast to a graphematic typology, a sociolinguistic or context-based typology of writing systems derives from the employment of a writing system in a particular context or for a particular purpose. According to Mountford (1996, p. 627), a sociolinguistic typology of writing system seeks to answer the question “who uses which writing system to whom, in what context, and for what purpose”.28 Broadly speaking, Mountford distinguishes between general-purpose and special-purpose writing systems. The former comprises what Sampson (2015, p. 146) describes as “the ordinary writing system of a society” used for everyday purposes. The latter encompasses writing systems employed in specialised situations or for special purposes. Such specialised writing systems include shorthand, cryptic codes and systems used primarily in pedagogical or professional settings, regardless of their graphematic type. The use of a writing system in a restricted situation or context may influence its popular perception, and prevent the system from being used for everyday purposes, regardless of its graphematic properties. This explains why Hànyǔ Pīnyīn (𝚌𝚖𝚗-𝙻𝚊𝚝𝚗-𝚙𝚒𝚗𝚢𝚒𝚗; §2.3), English in the Initial Teaching Alphabet (see (3)) or English transcribed in the IPA (𝚎𝚗-𝙻𝚊𝚝𝚗-𝚏𝚘𝚗𝚒𝚙𝚊) are not used in quotidian settings, despite being graphematically comprehensive systems. Hence, the use of a writing system for a specific purpose or by a specific user group may well create a semiotic association between the system and its use or users. If such a semiotic association becomes entrenched over time, attempting to use the writing system outside of its perceived domain of use may be sociolinguistically resisted. Such semiotic associations, and resistance to modify them, are especially evident in the context of written Sindhi in contemporary India (§13.3).
Transliteration, Transcription and Shorthand
Within the context of a particular language — that is, in a homolingual context — three noteworthy special-purpose types of writing system are transliteration, transcription and shorthand. According to Daniels (2018, p. 15), transliteration involves replacing one script with another, ensuring that (nearly) every graph in the source inventory has an equivalent in the target inventory. If the target script is Roman or Latin, the transliteration is called a romanisation or latinisation.29 In contrast, a transcription involves equating the phones of a language with the graphs of a particular script (Daniels, 2018, p. 15). Graphematically, the phenomena differ in terms of focus and point of departure. Transliteration focuses on graph-graph correspondence between two different scripts or inventories, while transcription focuses on phone-graph correspondences between a language and a script. Also, transliteration in the strict sense presupposes that the language in question already has a writing system, thereby being applicable only to graphised languages. Transcription, on the other hand, can apply to any language irrespective of graphisation status. Both processes, however, lead to the establishment of a new language-script pair, thereby resulting in a new writing system. Consequently, the terms are often used interchangeably. Besides, they are also used as near-synonyms for a writing system perceived as secondary or auxiliary in nature. Such a characterisation, however, derives from the sociolinguistic use and perception of the writing system in question, and not from its graphematic properties per se. As described earlier in this section, Hànyǔ Pīnyīn (𝚌𝚖𝚗-𝙻𝚊𝚝𝚗-𝚙𝚒𝚗𝚢𝚒𝚗) is sociolinguistically perceived as a secondary or auxiliary system, despite being a graphematically full-fledged writing system in its own right. Hànyǔ Pīnyīn does, however, meet the definition of transliteration — specifically, romanisation — as outlined above, since there exists a consistent correspondence between the graphs of 𝚌𝚖𝚗-𝙻𝚊𝚝𝚗-𝚙𝚒𝚗𝚢𝚒𝚗 and those of Mandarin in Simplified Hànzì (𝚌𝚖𝚗-𝙷𝚊𝚗𝚜).
In the context of this book, there arise two questions regarding transliteration. First, since a transliteration is intended to serve as an auxiliary writing system, should one be used in this book, especially given the large number of writing systems in focus? Second, if a transliteration is essentially a full-fledged writing system, should this book also include past and present transliterations of Sindhi in its purview? As defined above, a transliteration reflects graph-graph correspondences between two homolingual writing systems. This implies that, for a transliteration to be effective, the number of pre-existing writing systems should be as few as possible — ideally just one. In this book, however, no less than seven distinct writing systems are described and analysed, with each of them having numerous subvariants featuring distinct graph inventories, graph-phone correspondences and orthographies. In such a scenario, an effective transliteration would, on the one hand, need to accurately capture and portray a vast amount of graphemic, graphetic, phonemic, phonetic and orthographic information. On the other hand, it would also need to be as economical and legible as possible. Clearly, these criteria involving simultaneous comprehensiveness and compactness are difficult to reconcile. For this reason, this book will not employ a transliteration to depict Sindhi’s writing systems. Instead, it will make use of transcriptions of Sindhi words into the IPA, both phonemic and phonetic, as needed. In the absence of a specific transliteration, Sindhi and South Asian names and terms will be spelt according to their generally accepted 𝚎𝚗-𝙻𝚊𝚝𝚗 spellings, as in ⟨Sindh⟩, ⟨Hyderabad⟩ and ⟨Kutch⟩. If a word has more than one commonly attested 𝚎𝚗-𝙻𝚊𝚝𝚗 spelling — as in ⟨Devanagari⟩ and ⟨Devnagri⟩ — one of them will be adopted on a discretionary basis and, if required, be accompanied by an IPA transcription. In terms of transliterations as objects of study, the book will make one borderline exception — the Sindhi-Roman writing system as used in the Linguistic Survey of India (𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒; §12.2). Despite being explicitly designed and used as a transliteration for auxiliary purposes, 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 is included as a subvariant of Sindhi-Roman due to its graphematic insights and historical-sociolinguistic significance. The question of sociolinguistically classifying Sindhi-Braille (𝚜𝚍-𝙱𝚛𝚊𝚒) is taken up in detail in Chapter 11.
Aside from transliteration and transcription, a third type of sociolinguistically defined homolingual writing system is shorthand. According to Daniels (1996b, p. 807), shorthand is a “notation system” for recording words quickly, and designed to prioritise speed over phonological accuracy. The sociolinguistic aim and graphematic design of a shorthand system result in two distinctive characteristics. First, since a text written in shorthand may gloss over certain phonological aspects of the spoken utterance it records, it usually needs to be rewritten in another, more widely-known homolingual writing system — or orthography — for the recorded phonological information to be made transparent. Else, deciphering the shorthand text may prove difficult, if not impossible, for anyone other than the writer. Second, since shorthand notations are usually known to and utilised by specialised user groups, a shorthand system may serendipitously serve as a ‘secret’ writing system restricted to its user base.
Despite these properties, there remains a third requirement for a writing system to be termed shorthand — the existence of a homolingual ‘full’ writing system, or longhand. Hence, a shorthand can only be considered to exist when there also exists a corresponding graphematic longhand. Sociolinguistically, the longhand serves as the general-purpose writing system, while the shorthand acts as a special-purpose system restricted to specific uses or users.
As alluded to at the end of the previous section, Sindhi’s writing systems have been classified in academic and popular discourse under a variety of descriptors. Just as the graphematic labels abjad and alphasyllabary were applied based on sociolinguistic practices, so too were labels like auxiliary system and shorthand. In the absence of grapholinguistic tools in the past, terminological equivocation was understandable. However, in view of recent scholarly advancements and the introduction of sophisticated grapholinguistic models, a fresh approach to analysing Sindhi’s writing systems from graphematic and sociolinguistic perspectives is now necessary. Such an endeavour includes reclassifying Sindhi’s writing systems under appropriate graphematic and sociolinguistic labels, based on their synchronic use.
Biscriptality and multiscriptality
The specific phenomenon investigated in this book is that of a particular language being written in multiple ways, be it in more than one script, orthography or graphetic style. This phenomenon has been recognised in the literature for some time now, typically under the label digraphia (Grivelet, 2001) and characterised as the written counterpart to spoken-language diglossia (Ferguson, 1959). It has also been referred to by a variety of other appellations, including biscriptalism and multialphabetism, among others (Bunčić, 2016a, p. 16). Inconsistent terminology, coupled with a lack of robust methodologies, have hindered rigorous analyses — especially comparative analyses — of such sociolinguistic situations. Aiming to plug this epistemological gap, Bunčić, Lippert and Rabus (2016) propose a typological framework for analysing what they term biscriptality. According to the authors, biscriptality is the simultaneous use of more than one script, orthography or graphetic style in writing a given language (Bunčić, 2016c, pp. 51, 54). It follows that all instances of biscriptality are, by definition, homolingual in nature. The proposed analytical framework categorises biscriptal writing along two principal dimensions of variation – graphematic and sociolinguistic.30 The graphematic dimension or axis further distinguishes among biscriptal writing in three ways, depending on whether they differ in the scripts, graphetic styles or orthographies they employ. Along the sociolinguistic axis, biscriptal writing is again categorised into three subtypes, based on the conditioning factors at play — the situation of use, the user group, or none. When the choice of biscriptal variant is decided by the purpose of writing, the result is complementary distribution between the variants, often accompanied by an implied difference in status. One may say the variants exist in ‘vertical’ opposition. When the choice of variant depends less on what the writing is about and more on who the writers (and intended readers) are, the outcome is complementary distribution based on user group – a ‘horizontal’ opposition. When there is no evident conditioning factor behind the choice of biscriptal variant, the choice may be considered ‘free’ in principle — although this is rarely the case in practice. The resultant 3 × 3 matrix allows for precisely and transparently situating attested instances of biscriptality based on their characteristics, as shown in a simplified format in Table 2.2.31Additionally, some of the nine categories of biscriptality may feature further subcategories, not shown here for brevity.
Sources: Bunčić, Lippert, & Rabus (2015) and Bunčić (2016c, p. 67)
| Graphematic dimension | ||||
|---|---|---|---|---|
| script | graphetic style | orthography | ||
| Sociolinguistic dimension | ‘vertical’ | digraphia | diglyphia | diorthographia |
| ‘horizontal’ | scriptal pluricentricity | glyphic pluricentricity | orthographic pluricentricity | |
| ‘free’ | bigraphism | biglyphism | biorthographism | |
Despite the name, the Biscriptality framework also overs homolingual writing practices that differ in not just in the script used, but also the graphetic style or orthography employed. Consequently, going by the definitions and approaches used in this book, only those biscriptal variants that differ in their script component would be considered distinct writing systems (§2.3). Biscriptal variants that differ only in graphetic style or in orthography are usually considered subvariants of the same writing system. Also, graphetic style here refers to the specific typeface or calligraphic hand in use, exemplified by German in the Roman script appearing in the Fraktur style (𝖆𝖇𝖈𝖉…𝖝𝖞𝖟) on the one hand, and in the Roman or ‘Antiqua’ style (abcd…xyz) on the other (Spitzmüller & Bunčić, 2016). As alluded to in Section 2.2, the Biscriptality framework uses the term glyph to describe the surface typographic or calligraphic allograph of an underlying graph.
With regard to scope, the authors intend the term biscriptality as a cover term for a language written in multiple ways, although they make a provision for the term multiscriptality to be used where warranted:
[We] treat biscriptality as a cover term encompassing multiscriptality as a special case where more than two [scripts, graphetic styles or orthographies] are involved. Mathematically one might of course argue that multi ‘many’ means more than one, so that biscriptality should be a special case of multiscriptality. However, the analysis of concrete examples of multiscriptality with three (or even more) [biscriptal variants] shows that these are often complex cases of double (or triple) biscriptality nested into each other. […] Therefore biscriptality seems to be the term with the greater analytic power (although multiscriptality can of course be used to describe a situation of complex biscriptality).
Given that the case of Sindhi seems to qualify as “complex biscriptality”, the term multiscriptality will be preferred in this book.
A cornerstone of the Biscriptality framework is its restriction to instances of simultaneous, concurrent or synchronic biscriptality (Bunčić, 2016c, p. 54). In simple terms, a language must be written in two different ways during the same time period or era. The framework does not intend to analyse diachronic changeovers in script, graphetic style or orthography. That said, it is capable of analysing multiple instances of (synchronic) biscriptality within the same language but at different points in time. A language that undeniably fits this description is Sindhi, which not only features multiple instances of biscriptality across the centuries, but also exemplifies different biscriptal subtypes in different eras. This makes written Sindhi a particularly rich sociolinguistic site for harnessing the full potential of the Biscriptality paradigm.
In terms of its relation with graphematic typologies of writing systems, the Biscriptality framework appears, especially at first glance, to align somewhat with the concept of writing system modules as envisaged by the Modular Theory (MT). Despite superficial similarities, the overlap in scope is limited. The neatest overlap of the sociolinguistically oriented Biscriptality framework with the graphematically oriented MT is in terms of script, which, in both frameworks, refers to a graph superset underspecified for typographical or calligraphic style. When it comes to orthography, the Biscriptality framework aligns with the MT in certain cases such as American English and British English. Here, the sociolinguistic instance of orthographic pluricentricity represents the graphematic phenomenon of different orthographic modules being superimposed on a shared graph inventory and graphematic system. These sociolinguistic and graphematic interpretations are also conveniently captured by the IETF language tags applicable in this case — 𝚎𝚗-𝙻𝚊𝚝𝚗-𝚄𝚂 and 𝚎𝚗-𝙻𝚊𝚝𝚗-𝙶𝙱, which share a common language and script subtag but differ in their country subtags. In contrast, the Biscriptality framework analyses the Traditional and Simplified characters used in writing Mandarin as a difference in orthography (Klöter & Bunčić, 2016). However, the Traditional and Simplified characters may also be interpreted as different graph subsets of the same script. Yet another interpretation is that the two inventories represent two distinct scripts, suggested by the IETF language tags 𝚌𝚖𝚗-𝙷𝚊𝚗𝚝 and 𝚌𝚖𝚗-𝙷𝚊𝚗𝚜, respectively (§2.9). Finally, graphetic or glyph style as envisaged by the Biscriptality framework is not explicitly provided for under the MT, although it may be argued that a particular graphetic style may well be instituted by an orthographic module. Muddying the waters yet again is the fact that the IETF assigns script subtags to certain stylistic or glyph variants of the same script (§2.6). As a result, German-Roman printed in Antiqua and Fraktur styles may be indicated with the language subtags 𝚍𝚎-𝙻𝚊𝚝𝚗 and 𝚍𝚎-𝙻𝚊𝚝𝚏, respectively.
Even so, the limited concurrency between the Biscriptality framework and the MT should not impact on the perceived versatility and utility of each. Both frameworks carry potential for plausible and revealing analyses in their respective domains of specialisation, while also allowing for modifications and ameliorations as needed. For this reason, the MT and the Biscriptality framework will form the foundation for analysing and interpreting the graphematic and sociolinguistic properties exhibited by Sindhi’s writing systems, past and present.
3 Sindh and the Sindhi people
This chapter provides a brief history of Sindh and its inhabitants, from prehistoric times to the modern day. In doing so, it recounts the twentieth-century split of Sindhi society into its present-day Pakistani, Indian and diasporic communities. This sociohistorical overview will contextualise the chapters that follow on the Sindhi language and its writing systems.
3.1 Ancient and pre-Islamic times
The Sindh region is located in the north-west of South Asia. Geopolitically, contemporary Sindh is a province of Pakistan. Geographically, it is flanked by the Pakistani provinces of Balochistan and Punjab to the west and north, respectively, and by the Indian states of Rajasthan and Gujarat to the east and south, respectively. To the south-west of the Sindh province lies the Arabian Sea and the delta of the Indus, an economically, culturally and historically significant river for much of South Asia.
Historically, the Sindh region finds mention as sindhu in the Mahabharata, an epic poem in Sanskrit about events supposed to have taken place around 3102 BC (Buck, 2000, p. xiv; Winternitz, 1981, p. 453).32 Up until the early twentieth century, these mythological allusions were the earliest recorded references to the region. In fact, the history of South Asia as a whole had until then been attested with some certainty only up to 326 BC, the year Alexander of Macedonia had invaded the north-west of the Subcontinent (Possehl, 2002, p. 3). However, the 1920s represented a watershed moment for our knowledge of Sindh’s history. Following the discovery of numerous large mounds along the valley of the Indus river, the Archaeological Survey of India (ASI) carried out a series of excavations at these mounds. Buried beneath were hitherto unknown sites of human settlement dating back to the Bronze Age (3300–1100 BC) (Habib, 2002; McIntosh, 2008). The discovery of these settlements pushed back South Asia’s recorded history to at least 2500 BC. Since the first settlement discovered was near the village of Harappa (in present-day Punjab province, Pakistan), the civilisation was termed the Harappan Civilisation (McIntosh, 2008, pp. 3–4).33 Eventually, the sites as a whole became commonly known as the Indus Valley Civilisation (Marshall, 2004 [1931]). The civilisation reached its pinnacle between 2600 and 1900 BC (‘Mature Harappan Phase’; see Figure 3.1), and was highly advanced for its time.

Source: Wikimedia Commons (http://commons.wikimedia.org/wiki/File:Indus_Valley_Civilization,_Mature_Phase_(2600-1900_BCE).png). Copyright 2014 by Avantiputra7. Used under CC BY-SA 3.0.
After Harappa, another well-known site of the Indus Valley Civilisation was unearthed under a mound near the town of Larkano, in the north-west of present-day Sindh province. Estimates suggested that this settlement was one of the largest cities in the world for its time (Petrie, 2013, p. 88). Also found at the site were several skeletal remains of human bodies in unusual positions, apparently abandoned on the city’s streets. Theories have been put forward to explain the presence and positions of these skeletons (Wheeler, 1953, pp. 91–93), but none has been widely accepted (Habib, 2002, p. 64). Nevertheless, the skeletons have likely served as the inspiration for the Sindhi name of the site — [mʊənᶦ d͡ʑo d̪əɽo], meaning ‘mound of the dead’. The name has conventionally been spelt Mohenjo-daro in 𝚎𝚗-𝙻𝚊𝚝𝚗 since the publication of Marshall’s (2004 [1931]) work, with the alternative Moenjo-daro appearing occasionally (Kenoyer, 2016; Possehl, 2002, p. 3). Both spellings may also occur unhyphenated (Encyclopedia Britannica, 2021). Of late, Mohenjo-daro has been increasingly harnessed by Sindhi intellectuals as a symbol of the supposed antiquity of Sindhi culture (Falzon, 2004, p. 78; Kothari, 2009, pp. 1–2). This is notwithstanding a dearth of substantiated facts on the culture, religion or language of the Indus Valley civilisation.
The Indus Valley Civilisation started declining with the abandonment of its cities from 1900 BC onwards, the reasons for which are again not clearly known. Prominent hypotheses that have been advanced include a decline in trade, a change in course of the river Indus and destruction by invaders (Habib, 2002, pp. 61–66; Possehl, 2002, pp. 237–246). Albeit yet unproven, the last of these hypotheses has received some attention, for Sindh’s geographical location on the north-western border of South Asia has historically rendered it vulnerable to invasions from Central and Western Asia. The area was conquered by the Persian Achaemenid Empire in the sixth century BC, and by the Macedonian-Greek army of Alexander in 326 BC (Kulke & Rothermund, 2004, pp. 60–61). Subsequently, the Sindh region came under the rule of the Mauryans, Graeco-Bactrians, Scythians, Kushans, Sassanids and Huns, who brought with them and pursued various cultural and religious practices including Greek, Vedic and Buddhist (Bowersock, Brown, & Grabar, 1999).
3.2 711 to 1843: Arab and Islamic influence
In 711 AD, the seventeen-year old Arab general Muhammad bin Qasim invaded Sindh and defeated the local king Dahir.34 This made Sindh the easternmost province of the Umayyad Caliphate (Campo, 2009). In 1025 AD, Sindh was seized from the Arabs by the Afghan king Mahmud of Ghazni. From 1050 AD onwards, Sindh was ruled by the native Sumro and Samo warrior clans, and then by the Turco-Mongol Arghun dynasty, all of whom had adopted Islam (Qalichbeg, 1902).35 In 1593, Sindh was taken over by the emperor Akbar (Richards, 1995, p. 51) and annexed to the Mughal empire, which ruled much of the Subcontinent until British colonisation. From the seventeenth century onwards, Sindh was ruled by the local Kalhoro clan and then the Talpur clan as vassals of the Mughals (Qalichbeg, 1902).36 Thus, despite not remaining under direct Arab rule for long, Sindh did remain under local Muslim rulers, predominantly Sunni, for more than a millennium. This rule left a profound Islamic influence on Sindh’s culture and language.
Yet, throughout the period of Muslim rule, Sindh continued to have significant communities of minority faiths (Boivin, 2008a; Boivin & Cook, 2010). Prominent among them were Shia Muslims of the Nizari Ismaili community (§5.1.4; Chapter 10), whose faith traditions incorporated numerous Indic elements (Asani, 1991; Gillani, 2004; Khakee, 1972). The non-Muslim minority of Sindh’s population — commonly, if anachronistically, labelled ‘Hindu’ — historically worshipped the water deity Jhulelal (Parwani, 2010). Later, they also began following the teachings of Guru Nanak (1469–1539), the founder of the Sikh faith (Khan, 2008).37 Consequently, the belief system of non-Muslims in Sindh came to be “an easy blend of Sikhism and Hinduism” (Daswani & Parchani, 1978, p. 21). Major life events were marked by rites and rituals at Sikh temples, alongside Vedic and folk practices on an everyday level. Pending the emergence of a widely accepted umbrella term for Sindhis who observed a mélange of Sikh, Vedic and folk traditions, this socioreligious group will be referred to in this book as Hindu-Sikh. Contributing to the syncretism of Sindhi faith practices was a significant Sufi mystic influence (Ramey, 2008, p. 178). The influence of Sufism on Sindhi spiritual life persisted even after the British conquest of Sindh, leading Boivin (2020, p. 298) to claim that, up until the early twentieth century, adherence to the Sufi paradigm was “the best way to claim to be Sindhi, whatever the religion at hand”.
The intertwined and nonsegregated nature of belief systems meant that, in pre-British Sindh, “religious distinctions were not particularly important political categories of identification” (Boivin, Cook, & Levesque, 2017, p. 3). However, these fluid traditions were sometimes met with disapproval by orthodox observers, leading to discrimination. Despite negative reception in some quarters, the syncretic nature of Sindhi expressions of faith significantly contributed to sociocultural harmony in pre-British Sindh. It also left a lasting impact on the language’s writing systems (Chapter 5).
3.3 1843 to 1947: British rule
In 1843, the ruling Talpur chieftain of Sindh was defeated by the forces of Charles James Napier, a British general in the private army of the London-based East India Company (Cook M. A., 2016a). In 1857, the British government dissolved the East India Company and took over its possessions in South Asia, including Sindh. Subsequently, Sindh was amalgamated into the neighbouring Bombay Presidency. In 1936, it was made a separate province with its own Assembly (Boivin, Cook, & Levesque, 2017).
The early twentieth century saw the struggle for independence gaining momentum in British-ruled South Asia, or British India as it was then known. This period also saw a rise in Hindu-Muslim tensions, as the Muslim elite in certain parts of British India began to fear being dominated by the majority Hindus in an independent India. In 1940, the All-India Muslim League passed the Lahore Resolution — today known as the Pakistan Resolution (Swaab, 1973). The Resolution called for the creation of “independent states” for Muslims in British India, and stated, among other things, that:
no constitutional plan would be workable in this country or acceptable to the Muslims unless it is designed on the following basic principle, viz., that geographically contiguous units are demarcated into regions which should be so constituted with such territorial adjustments as may be necessary that the areas in which the Muslims are numerically in a majority as in the North-Western and Eastern zones of India should be grouped to constitute “Independent States” in which the constituent units shall be autonomous and sovereign.
This Resolution was passed in the Sindh Assembly in June 1947 (Jalal, 1994, p. 290), which meant that Sindh would become part of the new nation of Pakistan. Pakistan and independent India, comprising the Muslim and Hindu-majority areas of British India, respectively, came into being simultaneously at midnight between 14 and 15 August 1947. The port city of Karachi, which was the capital of Sindh and now Pakistan’s largest city, was designated the country’s interim capital (Khan Y. , 2017).
The Partition of British India triggered massive bloodshed and resulted in one of the largest mass migrations in recorded history. Between twelve and seventeen million people were displaced (Butalia, 1998, p. 3; Jalal, 1994, p. 1), and between two hundred thousand and two million were left dead (Butalia, 1998, p. 3). On both sides of the border, religious minorities began to fear for their lives. Most Hindus and Sikhs in what was now Pakistan, as well as a large number of Muslims from independent India, fled their ancestral homes and sought refuge on the other side of the border (Khan Y. , 2017). Initially, Sindh initially remained relatively calm, especially when compared to the level of violence seen in neighbouring Punjab. Hence, in the immediate aftermath of Partition, much of Sindh’s non-Muslim population stayed in place, albeit tentatively. However, in the months that followed, Karachi began to receive a large influx of Muslim refugees from independent India. By January 1948, religious riots began erupting in Sindh, resulting in an exodus of the province’s non-Muslim population (Zamindar, 2010). Although a section of non-Muslims of socioeconomically disadvantaged background remained in Sindh (Boivin, Cook, & Levesque, 2017, p. 7), most Sindhis of Hindu and Sikh background left their homeland to make a new beginning in independent India and elsewhere around the world.
3.4 Present-day
Pakistan
In terms of ethnolinguistic identity, the Pakistani census only reports figures based on self-reported ‘mother tongue’. Consequently, these figures need to be used as a statistical proxy for gauging ethnolinguistic self-identification. According to the 2017 Pakistani census, Sindh (Figure 3.2) had a population of 47.8 million (Pakistan Bureau of Statistics, 2017a), of whom 29.4 million were reported Sindhi as their mother tongue. Fewer than a million native Sindhi speakers were based in other parts of Pakistan, with the total number of Sindhi speakers in the country numbering 30.2 million (Pakistan Bureau of Statistics, 2017b; 2017c). While data on speakers of Sindhi as a second language are absent from the census figures, the number of such speakers would likely be statistically insignificant.

Source: Google Maps (http://maps.google.com). Copyright 2013 by Google.
The ethnolinguistic composition of Sindh today represents a significant transformation from pre-Partition times, when native Sindhi speakers were in a much greater majority. In 1941, Sindh had a population of just over 4.5 million (Census of India, 1941), of whom the overwhelming majority were native Sindhi speakers. Partition led to around 800,000 Sindhi speakers fleeing Sindh, whose place was taken up primarily by Urdu speakers arriving from what was now independent India (Boivin, Cook, & Levesque, 2017, p. 6). These refugees came to be known as muhajir, Arabic for ‘refugee’ (Platts, 1884, p. 1098).38 Although disliked by some in-group members due to its connotations of nonindigeneity, the label muhajir has today come to be somewhat coterminous with ‘Urdu speaker’ in Pakistan (Ayres, 2009; Siddiqi, 2012). Many Muhajirs settled in Karachi, while others ended up in regional cities of Sindh such as Hyderabad and Shikarpur.39 As a result, the populations of these cities have gone from majority Sindhi-speaking before Partition to majority Urdu-speaking in present times (Khubchandani, 1998, p. 12; Rahman, 1995, p. 1008).
Today, Sindhi remains the official language of Sindh and is used in education and mass media in the province. In rural areas of Sindh, where the population numbers 23 million, the overwhelming majority — 21 million — are native speakers of Sindhi. In urban Sindh, however, the language has been reduced to a minority. Of an urban population of 24.8 million, only 8.3 million speak Sindhi as a mother tongue, compared to almost 8.5 million Urdu speakers. The linguistic divide is particularly stark in Karachi, where the population of 14.9 million people comprises only 1.2 million native Sindhi speakers but 6.7 million Urdu speakers. (Pakistan Bureau of Statistics, 2017b; 2017c). Thus, in the capital city of Sindh, Sindhi speakers are outnumbered by Urdu speakers by more than five-to-one. Consequently, Sindh has seen several instances of Sindhi-Muhajir tensions erupting into violence, not least over the issue of language (Shackle, 2014a). For an overview of ethnolinguistic conflicts in the recent past in Sindh and Pakistan, see Rahman (1995; 1999), Ayres (2009) and Siddiqi (2012).
Present-day Sindh also has a minority of just over 3.3 million Hindus, although it is unclear how many of them are native speakers of Sindhi (Pakistan Bureau of Statistics, 1998c). At any rate, since Hindus comprise less than one per cent of Sindh’s 47.8 million residents, they do not significantly impact the province’s language demographics.
India
Sindhis in India are dispersed all over the country, although the vast majority are settled in the western states of Maharashtra and Gujarat. Of the Hindu-Sikh Sindhis that migrated to independent India following Partition, most settled in metropolitan areas such as Bombay (now Mumbai), Poona (now Pune), Delhi and Ahmedabad. Since Hindu-Sikh Sindhis have historically been a mercantile community, Bombay as the commercial capital of India was a natural destination for them (Anand, 1996, p. 52; Tan & Kudaisya, 2000, p. 233). Hence, Bombay received the main wave of migration. Cities further away from Sindh, such as Bangalore (now Bengaluru) and Madras (now Chennai), and smaller towns such as Jaipur and Bhopal, received a smaller influx of Sindhi settlers. Those unable to find shelter in the cities proper ended up in refugee camps on their outskirts, often in abandoned British military barracks. Although the Indian government provided some help, the refugees in these camps were faced with lack of housing and the travails of starting life anew in a foreign land (Falzon, 2004, p. 41). Over time, several of these refugee camps grew into towns in their own right, prominent among them being Ulhasnagar and Pimpri in present-day Maharashtra state, Kubernagar and Gandhidham in Gujarat state, and Bairagarh in Madhya Pradesh state.
The total number of Sindhi refugees in India just after Partition was estimated at 800,000 (Daswani & Parchani, 1978, p. 7). According to the 1951 Indian census, 337,000 Sindhi refugees arrived in western India, of whom almost 88 percent had settled in urban districts due to their mercantile pursuits (Barnouw, 1966). Consequently, the number of Sindhis listed as tradespersons was 41 percent, compared to only eight percent for the overall Indian population. More significantly, the Sindhis had a relatively high literacy rate of 53 percent, compared to 24 percent for the overall population at the time (Falzon, 2004, p. 41).
As with the Pakistani census, the Indian census, too, only collects data on self-reported ‘mother tongue’ and not on ethnicity per se. This effectively makes the terms ‘Sindhi’ and ‘Sindhi speaker’ synonymous. According to the 2011 Indian census, (Iyengar & Parchani, 2021, p. 4), there were slightly fewer than 2.8 million Sindhi speakers in India, although this figure includes a million speakers of the Kutchi variety (Census of India, 2011a). In direct contrast to the Pakistani situation, the bulk of Indian Sindhis are based in urban areas of the country. Those who arrived from large urban centres of Sindh such as Karachi, Hyderabad and Shikarpur are often settled in correspondingly large Indian cities such as Mumbai, Pune, Delhi and Ahmedabad. On the other hand, persons hailing from the villages and smaller towns of Sindh typically reside in smaller Indian towns such as Ulhasnagar (Falzon, 2004, pp. 41–42), Pimpri, Bhopal and Adipur-Gandhidham. Currently, the largest concentration of Sindhi speakers in India is at Ulhasnagar, at an estimated 400,000 (Tare, 2010).
Sindhi diaspora
Although receiving a significant numerical boost thanks to the post-Partition exodus of non-Muslim Sindhis, the Sindhi diaspora around the world had been in existence for at least one hundred years prior. In fact, Falzon (2004, pp. 5–6) characterises the emergence of the worldwide Sindhi diaspora in terms of three distinct waves of emigration from Sindh. The first occurred with the British annexation of Sindh in 1843. Faced with uncertain business prospects following the takeover, Sindhi traders, primarily from Hyderabad and Shikarpur, started venturing into new lands to try their luck (Markovits, 2008). The second migration was an outcome of Partition, with those fleeing Sindh heading to independent India or to other parts of the world where they had family or business links. For some, India served only as a temporary post-Partition base before they moved on to other countries, both in the East and West. The third migration according to Falzon (2004) coincides with modern-day emigration from India for economic reasons. These waves of migrations have resulted in a present-day Sindhi diaspora spread across more than a hundred countries worldwide, from Japan to Malta to Panama.
3.5 Summary
This chapter has traced the rich and diverse history of Sindh and its inhabitants through the ages. More than a millennium of Islamic influence, coupled with frequent changes in rulers, have left a lasting impression on the people, culture and language of Sindh. In particular, it has made the people accustomed to uncertainty, and instilled in them an ethos of adaptability and pragmatism (Anand, 1996; Falzon, 2004). How these historical events have impacted the Sindhi language and its writing systems over the centuries and into the present day is explored and analysed in detail in the remainder of this book.
4 The Sindhi language
The Sindhi language is an Indo-Aryan language (Khubchandani, 2007) native to Sindh. Varieties of the language are also indigenous to regions bordering Sindh (see Figure 4.2). As outlined in Section 3.4, Sindhi is spoken by around 30.2 million people in Pakistan, 2.8 million in India, and an unknown, albeit small, number in the 500,000-strong Sindhi diaspora worldwide (Falzon, 2004, p. 6), a speaker base of 2.8 million amounts to only 0.2% of India’s population, which, as of 2022, stood at 1.41 billion (World Bank, 2022). Consequently, the Sindhi community in India is, in Khubchandani’s words, a “microscopic minority” in the country (1995, p. 309).
This chapter describes the key elements of the language, including its phonology and morphosyntax, and concludes with a sketch of the language’s sociolinguistic development in modern times. In doing so, this chapter acts as a foundation for Part Two, which forms the descriptive core of this book.
4.1 Linguistic affiliation
The Sindhi language is grouped under the north-western branch of the Indo-Aryan subfamily of the Indo-European language family (see Figure 4.1). However, this classification has occasionally been contested. In the popular literature, one frequently encounters unproven assertions that the language of Mohenjo-daro, or of the Indus Valley Civilisation in general, was an ancient form of Sindhi. Less frequently, such assertions may surface in academic works (Allana, 1991, p. 1; Asani, 2003, p. 613). Khubchandani summarises prominent claims linking the modern Sindhi language to the yet-unknown language of the Indus Valley Civilisation, and characterises them as made “[u]nder the spell of language chauvinism” (Khubchandani, 2007, p. 687). There also exists scholarly conjecture that Sindhi might well contain a non-Aryan substratum. The author of one of the first major Sindhi grammars, Ernest Trumpp (1872), states on the one hand that “Sindhi is a pure Sanskritical language, more free from foreign elements than any other of the North Indian vernaculars” (p. i).40 On the other hand, he also claims that Sindhi possesses “a certain residuum of vocables, which we must allot to an old aboriginal language, of which neither name nor extent is now known to us” (p. iii). Sindhi lexicographer George Shirt (1878) asserts that this underlying language is Dravidian in nature, and attempts to demonstrate the link between Sindhi and Dravidian languages by means of lexical-etymological comparison. In making his claim, Shirt alludes to the modern-day existence of a Dravidian language called Brahui in parts of Sindh and its environs. Shirt’s argument is reasserted by Sindhi pedagogue Parso Gidwani (2007) in his revised and enlarged comparative list of phonologically similar lexical roots in Sindhi and Dravidian languages. To bolster his argument, Gidwani reiterates the presence of Brahui in Sindh. The speculation of Sindhi having a Dravidian substratum is in a mutually reinforcing relationship with the hypothesis that the yet-unknown language of the Indus Valley Civilisation was of Dravidian stock (Habib, 2002, pp. 50–51; Mahadevan, 1977; Parpola, 1996; 2009). Still others have attempted to present a Semitic origin for Sindhi (Baloch, 1962). Nonetheless, based on available linguistic evidence, the majority of contemporary scholarly works classify Sindhi as Indo-Aryan (Cole, 2006).

Source: Wikimedia Commons (http://commons.wikimedia.org/wiki/File:IndoEuropeanTreeDielli1.svg). Copyright 2015 by Zoti Zeu. Used under CC BY-SA 3.0.
To be precise, Sindhi is considered to have descended from a certain form of Prakrit, a group of Middle Indo-Aryan vernaculars (Bubenik, 2007), spoken in what is today Sindh (Grierson, 1919, p. 4; Jetley, 2000; Khubchandani, 2007, pp. 686–687). However, due to the region having been under Islamic influence for more than eleven hundred years, Arabic and Persian lexical items, phonemes and, to a lesser extent, morphosyntactic constructions have found their way into the Sindhi language (Cole, 2006; Jetley, 2000). Cole (2006, p. 384) states that Sindhi “undeniably reveals the impact of its long history of contact with speakers of other languages”. George Stack, a pioneering British author of Sindhi dictionaries and a grammar, has succinctly summed up the syncretic nature of modern Sindhi in stating that “[t]he Sindhi […] borrows from the Arabic, the Persian, and the Sanscrit [sic], to an extent only limited by the learning and fancy of the writer” (1849a, p. iii). Despite these influences, Jetley (2000, p. 40) claims that the basic Indo-Aryan structure of the language has “remained mostly unchanged”.
4.2 Spoken varieties
Standard Sindhi is based on the Vicholi variety (Khubchandani, 2007, p. 683; Nihalani, 1999, p. 131) spoken in Vicholo, central Sindh. Since the main city in the region is Hyderabad, the variety is occasionally referred to as Hyderabadi (Covernton, 1906, p. 10). In Sindh, the Vicholi variety is considered the standard for administration, literature and education. Other principal dialects of Sindhi listed by Grierson (1919) and Khubchandani (2007) include:
- Siroli, spoken in Siro, upper Sindh;
- Lari, in Lar, lower Sindh;
- Lasi, in western Sindh and the Lasbelo region of neighbouring Balochistan province in Pakistan;
- Thari or Thareli, in the Thar region of south-east Sindh.41
The Siroli dialect is also cited in the literature as Siraiki (Nihalani, 1978, p. 8). However, this is also the name given to a variety of southern Punjabi (Grierson, 1919, p. 140), and is being increasingly used in this sense (Masica, 1991, p. 18; Shackle, 2014b). Meanwhile, the northern Sindhi variety has come to be known as Siroli (Bughio, 2006; 2009) or Utaradi (Bughio, 2009, p. 30), meaning “of the north” (Mewaram, 1910, p. 3).42 Other speech varieties usually classified as Sindhi dialects include Kutchi (or Kachchhi) in the Kutch region of Gujarat state, and Jaisalmeri in the Jaisalmer region of Rajasthan state, both in present-day India.43 Although the Indian census figures on the number of Sindhi speakers in the country includes speakers of Kutchi and Jaisalmeri, native speakers of these varieties may consider their mother tongues to be distinct from Sindhi proper (Khubchandani, 2007, p. 683). Such self-distinction is particularly noticeable with Kutchi speakers. Over the last several centuries, Sindh and Kutch have developed as separate political entities (Mallison, 2008, p. 67). Since 1947, the two regions have also been separated by the international border between Pakistan and India. Hence, Kutchi speakers may prefer to identify with the neighbouring Gujarati-speaking population, or maintain a distinct sociocultural identity. For an overview of the phonological differences between the Kutchi and Vicholi varieties, see Khubchandani (2007, p. 690). Regarding Jaisalmeri, Grierson (1919, p. 143) considers it a subvariant of Thareli, opining that “all these specimens are the same mixed forms of speech”, between Sindhi on the one hand and the Marwari speech variety in Rajasthan on the other.

Source: Wikimedia Commons (http://commons.wikimedia.org/wiki/File:Location_map_Pakistan_Sindh.png). Copyright 2012 by Nomi887. Used under CC BY-SA 3.0.
Apart from Kutchi and Jaisalmeri, there are no Sindhi-related varieties native to present-day India. For a comprehensive treatment of Sindhi dialect features, see Grierson (1919). Grierson’s work is invaluable both for the wealth of information it contains, as well as for its historical significance.
4.3 Phonology
The phonemic inventory and phonological makeup of Sindhi is quite similar to that of most north-western and western Indo-Aryan languages. That said, scholars are not unanimous on the exact number and nature of phonemes in Sindhi. This section provides an overview of several areas of Sindhi phonology and highlights certain features that are significant from a grapholinguistic perspective. These features include implosive stops, consonant gemination, reduced vowels and age-based phonological variation. Scholarly disagreement in these areas is also discussed.
4.3.1 Consonants
Table 4.1 shows the phonemic inventory of consonants in standard Sindhi, based on Nihalani (1999), Cole (2006), Khubchandani (2007) and Iyengar and Parchani (2021). Phonemes of marginal or undecided status are shown in parentheses, while allophones are shown in square brackets.
| Labial | Dental | Alveolar | Retroflex | (Alveolo-) |
Velar | Glottal | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Plosive stop | p pʰ |
b bʱ |
t̪ t̪ʰ |
d̪ d̪ʱ |
ʈ ʈʰ |
ɖ ɖʱ |
k kʰ |
ɡ ɡʱ |
||||||
| Implosive stop | ɓ | ɗ | ʄ | ɠ | ||||||||||
| Nasal stop | m (mʱ) |
[n̪] | n (n̪ʱ) |
ɳ (ɳʱ) |
ɲ | ŋ | ||||||||
| Affricate | t͡ɕ t͡ɕʰ |
d͡ʑ d͡ʑʱ |
||||||||||||
| Fricative | f | s | z | ɕ | (x | ɣ) | ɦ | |||||||
| Approximant | ʋ (ʋʱ) |
j | [w] [wʱ] |
|||||||||||
| Tap/Flap | ɾ [ɾʱ] |
ɽ [ɽ̃] (ɽʱ) |
||||||||||||
| Lateral approximant | l (lʱ) |
|||||||||||||
Sindhi has the most comprehensive stop system of all Indo-Aryan languages (Nihalani, 1974). Traditionally, Sindhi consonants are classified into five places of articulation — labial, dental, retroflex, palatal and velar. Based on the Sanskritic model, phonetically alveolar oral stops are considered phonemically retroflex. Similarly, alveolar sibilants and liquids are classified as dental. Alveolo-palatal affricates are traditionally grouped under palatal stops (Masica, 1991, p. 94). Sindhi thus shares a large part of its consonantal inventory with neighbouring Indo-Aryan languages such as Punjabi, Hindi-Urdu and Gujarati. However, the Sindhi consonantal inventory transcends those of its neighbours in terms of two major features. First, Sindhi has a full set of five nasal consonants. This contrasts with the neighbouring Indo-Aryan languages, where velar [ŋ] and palatal [ɲ] do not for the most part manifest as independent phonemes. In fact, [ɲ] may be altogether absent in these languages, while [ŋ] may only appear as an allophone of /n/ when preceding a velar stop in a consonant cluster. That said, in Sindhi, only /n/ and /m/ among these five nasal phonemes appear word-initially. Second, Sindhi features a series of voiced implosive stops /ɠ ʄ ɗ ɓ/, which occur word-initially and medially (Table 4.2). Of these, /ʄ/ is traditionally considered palatal and /ɗ/ retroflex. This classification agrees with the etymological origin of the implosives from the gemination of the corresponding plosives /ɡ d͡ʑ ɖ b/, respectively (Trumpp, 1872, pp. 13–19). A dental implosive corresponding to the dental plosive /d̪/ is absent from the phonemic inventory. For a detailed articulatory analysis of implosives in Sindhi, see Nihalani (1986).
| Word-initially | Word-medially | |||
|---|---|---|---|---|
| ɠ | [ɠoʈʰᶷ] | ‘village’ | [d͡ʑʱəɠᶦɽo] | ‘quarrel’ |
| ʄ | [ʄaɳəɳᶷ] | ‘to know’ | [əʄᶷ] | ‘today’ |
| ɗ | [ɗaɖʱo] | ‘very’ | [ɡaɗi] | ‘cart, vehicle’ |
| ɓ | [ɓʊɗəɳᶷ] | ‘to drown, sink’ | [kəɓəʈᶷ] | ‘cupboard’ |
The realisation of the velar and palatal nasals, as well as of the implosives, becomes increasingly unstable as one moves away from the Vicholi region. In Thareli-Jaisalmeri towards the east and Kutchi towards the south, the implosives are reported to be poorly established and highly variable (Grierson, 1919, p. 147; Khubchandani, Sindhi, 2007, p. 690), or altogether absent (Grierson, 1919, p. 185). In recent years, the implosives have also been disappearing from standard Sindhi varieties in India, particularly in the speech of younger speakers who have limited exposure to spoken Sindhi. In the speech of such speakers, the implosives are typically realised as the corresponding plosives /ɡ d͡ʑ ɖ b/, respectively (Lekhwani, 2011, p. 34; Parchani, 1998, p. 18; Iyengar & Parchani, 2021).
Consonant allophony
Table 4.1 shows allophone symbols enclosed in square brackets. [n̪] is an allophone of /n/ preceding dental stops in consonant clusters, as in /ɗənd̪ʊ/ [ɗən̪d̪ᶷ] ‘tooth’. [ɽ̃] is an intervocalic allophone of /ɳ/, as in /maɳʱu/ [maɽ̃ʱu] ‘man’. This is reflected in the observation by early grammarians that /ɳ/ was occasionally interchangeable with /ɽ/ (Trumpp, 1872, p. 16). [w] and [wʱ] tend to be the realisations of /ʋ/ and /ʋʱ/ before back vowels, although this is subject to high idiolectal variation. In addition, [ɽ] and [ɽʱ] freely alternate with [ɾ] and [ɾʱ] in certain speakers’ idiolects (Nihalani, 1978, p. 103).
Aspirated sonorants
The symbols enclosed in parentheses in Table 4.1 are described by Nihalani (1999) as representing independent phonemes in Sindhi, but by Cole (2006) as phonologically indeterminate. Cole notes that it is difficult to assert independent phoneme status for [mʱ nʱ ɳʱ lʱ ɽʱ ʋʱ] in Sindhi, since they do not contrast with a phonological cluster of a sonorant and [ɦ] in the language. Khubchandani (2007), too, does not characterise the parenthesised symbols as representing independent phonemes in Sindhi. This perspective is graphematically reflected in the current Sindhi-Arabic (𝚜𝚍-𝙰𝚛𝚊𝚋) writing system (Chapter 6) in that each of [mʱ nʱ ɳʱ lʱ ɽʱ ʋʱ] is written as a multigraph.
Consonant clusters
Consensus is also lacking on the phonemic status of word-medial consonant clusters in Sindhi. Trumpp (1872, p. xxxiii) observes that there is great idiosyncratic variation in the pronunciation of a “compound consonant”, ranging from clear articulation as a cluster to phonetically rendering them as separate consonants with an intervening epenthetic [ᶦ]. He notes that this epenthetic vowel is “scarcely perceptible”. This phenomenon has been attested by several scholars over the years (Grierson, 1919, p. 23; Khubchandani, 2007, p. 691; Lekhwani, 1996, p. iv). As will be seen in Part Two of this book, idiosyncratic variation in the pronunciation of medial clusters results in corresponding variation in their graphematic representation, regardless of the writing system used. That said, certain varieties of Sindhi, especially Siroli in the north, feature the consonant clusters [ʈɾ] and [ɖɾ], including word-initially (Bughio, 2009). In the Vicholi variety of south-central Sindh, these clusters are realised as simple [ʈ] and [ɖ], respectively. Present-day 𝚜𝚍-𝙰𝚛𝚊𝚋 spelling (§6.5) reflects the Vicholi pronunciation (Grierson, 1919, p. 23). Thus, the graphematic representation may not be reflective of the pronunciations of speakers of northern varieties. Attempts have been made in the past to represent these phones with distinct graphs (Stack, 1849a, p. 9), but this practice has not caught on, presumably as it amounts to graphematic overrepresentation for the standard Vicholi variety. Cognates in southern varieties, especially Kutchi, are realised with [ʈɾ] replaced by [t̪ɾ]. Thus, the word for ‘three’ is realised in Siroli as [ʈɾe], Vicholi as [ʈe] and Kutchi as [t̪ɾe] (Grierson, 1919, pp. 140, 185).
Consonant gemination
Scholarly consensus is also lacking on whether consonant gemination in Sindhi is contrastive and, therefore, phonemic. Grierson characterises the Sindhi implosive stops as “double consonants”, but states that “[t]hese are really the only double letters [sic] in Sindhī” (1919, p. 22). Nihalani (1978; 1999) only states that intervocalic stops tend to be longer when they follow a lax vowel. Allana (1993 [1964], p. 151) states that phonological gemination does occur in Sindhi in certain cases, but does not elaborate further. Khubchandani (2007, p. 691) affirms that “doubling of consonants is not significant in Sindhi”, but then goes on to refer to the existence of a diacritic marker in the 𝚜𝚍-𝙰𝚛𝚊𝚋 graph inventory sometimes used to represent consonant gemination. He also offers the example of a geminate consonant in the word [ɪzzət̪] ‘respect’. In contrast, Mewaram’s (1910, p. 373) and Lekhwani’s (1996, p. 12) spelling for the same word reflects the pronunciation [ɪzət̪ᵊ]. Lekhwani is likely the most explicit on the issue of gemination. He states that phonemic gemination is not semantically significant in Sindhi, and on this basis, recommends against representing gemination in writing (Lekhwani, 1996, p. iii; 1997, p. xv).
Loan consonants and mergers
Due to a large number of lexical borrowings or loanwords from other languages, standard Sindhi has absorbed a number of nonindigenous φ-consonants. Among these, Khubchandani (2007, p. 689) considers the voiceless uvular stop [q] marginal, mentioning that it is only found in the “formal speech of Persian-oriented speakers”. Masica (1991, p. 105) echoes this sentiment in claiming that phonemic /q/ is either absent or not well established in Sindhi. Of late, Cole (2006) observes that Urdu influence is strengthening the phonemic status of [q] in urban Pakistani Sindhi. In contrast, Iyengar and Parchani (2021) note that [q] is essentially absent from modern Indian Sindhi. From a graphematic perspective, Varyani and Thakwani (2003, p. x) explicitly state that, 𝚜𝚍-𝙳𝚎𝚟𝚊 |क़्| is pronounced [k] in Indian Sindhi, making it homophonous with |क्| [k] (see Chapter 7). For a comparative overview of post-Partition phonological developments in Pakistani and Indian Sindhi, see Iyengar and Parchani (2021).
Historically, Sindhi phonology has absorbed [f z x ɣ] by way of loanwords. While [x ɣ] are found only in Arabic and Persian loans, [f z] occur in Arabic, Persian and English loans. Among Sindhis in India, [f z] seem to be relatively stable in the speech of younger speakers due to their proficiency in English and the reinforcing presence of [f z] in English. On the other hand, [x ɣ] are disappearing in the speech of younger Indian Sindhis, merging with [kʰ ɡ], respectively (Lekhwani, 2011, p. 34; Nihalani, 1978, pp. 2–3; Parchani, 1998, p. 19; Iyengar & Parchani, 2021). This merger is leading to the emergence of new homophones. For instance, both /səkʰi/ ‘female friend’ and /səxi/ ‘generous’ are realised as [səkʰi] in the speech of younger Indian Sindhis. An emerging phenomenon in Indian Sindhi is that of /pʰ f/ both collapsing into [f], even in native Sindhi words, again resulting in new homophones. An example is that of /pʰoʈo/ ‘cardamom’ merging with /foʈo/ ‘photograph’, with both being realised as [foʈo]. A similar phenomenon is attested in modern Hindi by Shapiro (2007, p. 286). Compared to standard Sindhi, Kutchi is reported as lacking not only phonemic /f z x ɣ/, but also /ɕ/, with the last one surfacing only as an allophone of /s/ (Acharya, 1966).
Other phones in the source forms of loanwords are usually approximated to the closest native Sindhi phoneme; for instance, the English alveolar stops /t d/ are usually realised in Sindhi as the corresponding retroflex stops /ʈ/ and /ɖ/, respectively, and represented as such in all its writing systems.
4.3.2 Vowels
Standard Sindhi has a system of ten phonemic vowels, namely /ə a ɪ i ʊ u e ɛ o ɔ/ (Khubchandani, 2007; Nihalani, 1999), shown in Table 4.3. Sindhi also features phonemic vowel nasalisation, with all ten oral vowels possessing nasalised counterparts.
| Front | Central | Back | |
|---|---|---|---|
| High & near-high | i ɪ |
u ʊ |
|
| Mid-high | e | o | |
| Mid | ə | ||
| Mid-low | ɛ ⁓ əɪ̯ | ɔ ⁓ əʊ̯ | |
| Low | a |
Based on the Sanskritic model, the vowels of modern Indo-Aryan languages, including that of Sindhi, have been conventionally grouped into short and long categories (Masica, 1991, p. 111). In Sindhi, the former comprises the monophthongs /ə ɪ ʊ/, while the latter includes the monophthongs /a i u e o/ and so-called diphthongs /ɛ ɔ/. Notwithstanding the Sanskritic model, vowel length is not phonemically significant in modern Sindhi, and distinctions between phonological vowels are primarily qualitative (Nihalani, 1978). Therefore, this book categorises standard Sindhi’s vowel phonemes as lax /ə ɪ ʊ/ and tense /a i u e o ɛ ɔ/, respectively. In general, lax vowels tend to be phonetically short, and tense vowels phonetically long (Keerio, Channa, Mitra, Young, & Chatwin, 2014), although this depends greatly on word environment (Nihalani, 1978). Hence, the terms lax and tense are used in this book primarily for nomenclatural convenience rather than as accurate descriptors of phonetic quality and quantity. The so-called diphthongs /ɛ ɔ/ show variable realisation, ranging from [əɪ̯ əʊ̯] to [e o], respectively.
The distribution of pronunciation is described variously by different authors. Nihalani (1999, p. 133) only states that /ɛ ɔ/ “tend to be diphthongized”. Khubchandani (2007, p. 693) claims that /ɛ ɔ/ occur mostly in loanwords, and are often replaced by /e o/. The most comprehensive sociolinguistic treatment of these vowels is likely that of Bughio (2001). Bughio attributes the varying realisation of /ɛ ɔ/ to a nominal diachronic and synchronic stratification in Sindhi pronunciation, albeit only in the context of Pakistan. First, he draws a distinction between the speech of older, rural Sindhi speakers and younger, urban Sindhi speakers. These are termed the Old Variety and New Variety, respectively. The New Variety is further divided into so-called Hindu and Muslim varieties. Sindhi sociolects are, thus, classified into religiolects and chronolects (Adamson, 1998; Frellesvig, 1996). According to Bughio, Hindu New Variety speakers tend to realise these vowels as the mid-low monophthongs [ɛ ɔ], while Muslim New Variety speakers usually featuring the diphthongs [əɪ̯ əʊ̯] in their phonologies. In contrast, Old Variety speakers, both Hindu and Muslim, tend to realise these vowels as [e o], respectively. Bughio’s characterisation of the Hindu New Variety of Pakistani Sindhi is reasonably applicable to Indian Sindhi pronunciation as well.
Notwithstanding Bughio’s classification, there remains significant idiolectal variation in the realisation of /ɛ ɔ/. Unsurprisingly, scholars disagree on the quality of not just these two phones, but on the very nature of diphthongs in Sindhi (Keerio, 2011, p. 62). Regardless, Bughio’s classification of Sindhi dialectal variation into religiolects and chronolects is a compact and convenient one.
Reduced vowels
An oft-cited feature of Sindhi phonology is its vowel-finality. Some authors assert that all Sindhi words are vowel-final (Bughio, 2006, p. 98; Grierson, 1919, p. 22; Hardwani, 1991, p. iii). Others state that indigenous Sindhi words are vowel-final, while certain consonant-final loanwords that have not yet been phonologically indigenised remain as they are (Khubchandani, 2007, pp. 691, 701). Conversely, if a loanword that is consonant-final in the source language is considered to have been assimilated into Sindhi, it may have a lax vowel suffixed. This word-final lax vowel manifests in a ‘reduced’ form (see Table 4.4).
| Source word | Source language | Sindhi realisation | Gloss |
|---|---|---|---|
| /ˈɔfɪs/ | English | [afisᵊ] | ‘office’ |
| /d͡ʒɒn/ | Persian | [d͡ʑanᶦ] | ‘life’ |
| /ɣariːb/ | Arabic | [ɣəɾibᶷ] | ‘poor’ |
The reduced vowels [ᵊ ᶦ ᶷ] are essentially unstressed phonetic realisations of the lax vowels /ə ɪ ʊ/, respectively, in morpheme-medial or morpheme-final positions in polysyllabic words (Addleton & Brown, 2010, p. 15).44 The distribution of reduced lax vowels in Sindhi aligns with the phenomenon known as the Indo-Aryan schwa syncope or schwa deletion rule (Bhatia, 1987; Choudhury, Basu, & Sarkar, 2004). Compared to their Sanskrit etyma, polysyllabic lexical items in modern Indo-Aryan languages often feature a deleted or elided oral schwa in certain phonological environments.45 The rule may also apply to non-Sanskritic lexical items, especially when a root and affix(es) combine to form a stem (Bhatia, 1987, pp. 39–40). However, the schwa deletion rule applies to different extents to different modern Indo-Aryan languages. The environments where schwa may be potentially deleted in polysyllabic words, and their applicability to various modern Indo-Aryan languages are detailed in Table 4.5.
| Environment | Phonological rule | Sanskrit etymon | Modern Indo-Aryan derivative |
|---|---|---|---|
| word-final in a disyllabic or polysyllabic word, subject to conditions | schwa → Ø / _____• | [akʂaɾa]‘syllable’ |
Hindi [əkɕəɾ]Marathi [ əkɕəɾ]Bengali [ ɔkkʰɔɾ]Sindhi [ |
[sʋaɾɡa]‘heaven’ |
Hindi [sʋəɾɡ]Marathi [ swəɾɡə]Bengali [ ʃɔɾɡo]Sindhi [ sʊɾɠᶷ] |
||
| word-medial in a [VC__CV] sequence | schwa → Ø / VC_____CV | [ɾacanaː]‘design’ |
Hindi [ɾət͡ɕna]Marathi [ ɾət͡ɕ(ə)na]Bengali [ ɾɔt͡ɕona]Sindhi [ ɾət͡ɕᵊna] |
As evident from Table 4.5, the schwa deletion rule is not universally applicable to modern Indo-Aryan languages. In general, the applicability of the rule gets weaker as one proceeds to the peripheries of the Indo-Aryan-speaking region (§4.1). Sinhala does not exhibit schwa deletion at all, while Bengali and Marathi feature word-final deletion with exceptions (Masica, 1991). In Sindhi, the rule involves vowel reduction, and applies to all the lax vowels /ə ɪ ʊ/. Thus, applying the rule of lax vowel reduction in Sindhi results in the reduced forms in [ᵊ ᶦ ᶷ] in certain word positions. Furthermore, the rules in Table 4.5 may apply multiple times within the same word. Thus, if a Sindhi word contains multiple /VCVCV/ sequences where the medial /V/ is any of lax /ə ɪ ʊ/, this may result in more than one theoretical surface realisation, as shown in Table 4.6:
| Sindhi word (Lekhwani, 1996) | /VCVCV/ sequences | Standard Sindhi pronunciation | Gloss |
|---|---|---|---|
| /nəməkəɦəɾamʊ/ | əməkə əkəɦə əɦəɾa |
[nəməkᵊɦəɾamᶷ] | ‘disloyal’ |
| /pəd̪ʱəɾənamo/ | əd̪ʱəɾə əɾəna |
[pəd̪ʱəɾᵊnamo] | ‘notification’ |
| /ɡʊzɪɾəɳʊ/ | ʊzɪɾə ɪɾəɳʊ |
[ɡʊzᶦɾəɳᶷ] | ‘to pass’ |
| /ɡʊmʊɕʊd̪a/ | ʊmʊɕʊ ʊɕʊd̪a |
[ɡʊmᶷɕʊd̪a] | ‘missing’ |
Arriving at the correct pronunciations for the examples in Table 4.6 requires applying the rules from Table 4.5 at the morpheme level before applying them at the lexical or word level. Clearly, this requires knowledge of morpheme boundaries and, consequently, a certain level of linguistic proficiency in Sindhi.
Reduced [ᵊ ᶦ ᶷ] in word-final position are grammatically significant in Sindhi, since the quality of the vowel often encodes person-number-gender (PNG) information (Grierson, 1919, p. 22). Compare, for instance, /kɪt̪abʊ/ [kɪt̪abᶷ] ‘book’ and /kɪt̪abə/ [kɪt̪abᵊ] ‘books’, or /masat̪ʊ/ [masat̪ᶷ] ‘mother’s sister’s son’ and /masat̪ɪ/ [masat̪ᶦ] ‘mother’s sister’s daughter’. Final [ᵊ ᶦ ᶷ] are also semantically significant, as illustrated by the words /bãsə/ [bãsᵊ] ‘smell’ and /bãsʊ/ [bãsᶷ] ‘bamboo’. Furthermore, the quality of a final phonological vowel is lexically conditioned, and not predictable from the phonological structure of the word. Also, consonant-final loanwords in Sindhi may be assigned a final reduced vowel in an arbitrary manner, much like the arbitrary assignment of grammatical gender in Sindhi to an inanimate loanword. That said, final vowels and grammatical gender often align; certain final vowels are characteristic of masculine words and others of feminine words. This is treated in further detail in Section 4.4.
The acoustic indistinctness of reduced [ᵊ ᶦ ᶷ] may lead to free variation among them in pronunciation, resulting in Sindhi [ɾət͡ɕᵊna] (see Table 4.5) also being realised as [ɾət͡ɕᶦna]. Besides being imperceptible to a nonfluent listener (Cole, 2001; Stack, 1849a, p. 10), reduced [ᵊ ᶦ ᶷ] are often dropped in rapid speech (Khubchandani, 2007, p. 692). Cole (2001) notes that reduced vowels in final position may also be devoiced following voiceless stops, adding to their imperceptibility. These reduced vowels are being lost in the speech of Sindhi youth who do not live in a comprehensive Sindhi-speaking environment. Remarkably, this has been attested not just in India, but also in Pakistan (Cole, 2006). More accurately, reduced [ᵊ ᶦ ᶷ] tend to feature only epenthetically in the New Variety phonologies, rather than contrastively. This has resulted in the emergence of new homophones, and consequently impinged upon the morphology of the language. For instance, both [kɪt̪abᶷ] and [kɪt̪abᵊ] may be pronounced [kɪt̪ab] by New Variety speakers. This is often frowned upon by older speakers (Iyengar & Parchani, 2021).
In Indian Sindhi, the merger or loss of various consonants and vowels as described above has shaped the New Variety of the language in India. In this chronolect, reduced vowels have largely been lost (Bughio, 2001), and implosives and velar fricatives have merged with their corresponding stops. The New Variety coexists with the Old Variety spoken by the older generation of Indian Sindhis, which remains phonologically more conservative, preserves reduced vowels, and also retains the distinctiveness of implosives and velar fricatives. The intergenerational difference in phonology has implications for Sindhi pedagogy and orthography design and forms a significant thread in Part Two of this book.
The phonologies of the old and new chronolects, therefore, form a spectrum. In such a scenario, speaking of a supposedly authentic Sindhi phonology becomes problematic. For this reason, using either extreme as the ‘standard’ phonology will be suboptimal as a reasonably accurate representation of the other. That is, both /kɪt̪abʊ/ and /kɪt̪abə/ on the one hand, and [kɪt̪ab] on the other, would be found awkward by speakers of the other chronolect. To overcome this dichotomy, IPA transcriptions of Sindhi in this book will depict a mid-point pronunciation that explicitly show lax vowels as reduced. In other words, phonemic /ə ɪ ʊ/ in unstressed or final position will always be shown as phonetic [ᵊ ᶦ ᶷ], respectively. This practice has some precedence in Sindhi grapholinguistics. In writing Sindhi in the Roman script (𝚜𝚍-𝙻𝚊𝚝𝚗) Grierson (1919) explicitly represented a reduced φ-vowel by a superscript version of the corresponding graph (see Chapter 12).
Reduced φ-vowels are also significant from a graphematic point of view. In present-day 𝚜𝚍-𝙰𝚛𝚊𝚋 writing, lax and reduced φ-vowels are conventionally unrepresented. In contrast, Sindhi-Devanagari (𝚜𝚍-𝙳𝚎𝚟𝚊) convention requires that all φ-vowels, whether tense, lax or reduced, be explicitly represented in writing. This results in disagreement on how to spell certain words in 𝚜𝚍-𝙳𝚎𝚟𝚊, since there is high intergenerational as well as idiosyncratic variation in the pronunciation of reduced φ-vowels. The fraught nature of representing reduced φ-vowels in contemporary written Sindhi is described and analysed in Sections 6.5, 7.5 and 13.2.
Speech varieties geographically distant from Vicholi, such as Thareli-Jaisalmeri and Kutchi, are generally understood as permitting φ-consonants to occur in clusters and in word-final position (Masica, 1991, p. 196). As a result, reduced φ-vowels in such varieties, to the extent they exist, may be considered epenthetic rather than phonemic (Grierson, 1919, pp. 147, 184–185). In the limited instances that such varieties are written, the above phonological features may be reflected in the graphematic practices adopted, with φ-consonant clusters written as such, and word-final reduced φ-vowels left unwritten.
Vowel allophony
In standard Sindhi, certain environments can cause φ-vowels to change their quality; for instance, the sequence /əɦɪ/ is realised allophonically as [ɛɦᵋ], (Grierson, 1919, p. 22; Trumpp, 1872, p. x). Similarly, /əɦʊ/ often surfaces as [ɔɦᵓ] in rapid speech. Thus, standard Sindhi /ɡəɗəɦɪ/ ‘female donkey’ is realised as [ɡəɗɛɦᵋ], while /ɡəɗəɦʊ/ ‘male donkey’ may be realised as [ɡəɗɔɦᵓ]. Metathesis may also be involved, resulting in [ɡəɗʱɛ] and [ɡəɗʱɔ], respectively. A similar — although not identical — phenomenon is attested in the neighbouring and phonologically similar Punjabi language (Gill, 1996, p. 397). An exception to this rule among Sindhi varieties occurs in Kutchi, in whose phonology surface [ɛ ɔ] tend to be analysed simply as underlying /ɛ ɔ/. This is reflected in the fact that, in written Kutchi, these φ-vowels are usually represented with distinct graphs of their own (Jobanpotra, 1922).
4.4 Morphology and syntax
This section provides a brief overview of Sindhi syntax and morphology for the uninitiated reader. Since sections of Part Two touch upon aspects of Sindhi noun and adjectival morphology, the scope of this section is restricted to these aspects. For comprehensive treatments of Sindhi verbal morphology, see Grierson (1919) and Cole (2001).
In terms of syntax, Sindhi has features similar to neighbouring Indo-Aryan languages. Sindhi is a head-final language; word order is nominally subject-object-verb (SOV), but is flexible to allow for topicalisation. In terms of morphology, Sindhi has a rich system of noun declensions and verb conjugations based on case, number and gender (Cole, 2001). Nouns usually end in one of [ᵊ a ᶦ i ᶷ u o], with those ending in [e ɛ ɔ] being uncommon. All nouns are classified into masculine or feminine genders, and are often distinguishable based on their final vowel. Nouns ending in [ᵊ a ᶦ i] are usually feminine, whereas those ending in [ᶷ u o] are usually masculine (see Table 4.7). Exceptions typically comprise animate nouns, such as [ɾad͡ʑa] ‘king’ and [maᶷ] ‘mother’. However, a few inanimate nouns are also irregular in this regard; [mot̪i] ‘pearl’ is masculine, and [kʰəɳɖᶷ] ‘sugar’ is feminine (Grierson, 1919, pp. 23–24; Shahaney, 1967 [1906], pp. 41–48).
Source: Shahaney (1967 [1906], p. 42)
| Masculine | Feminine | ||
|---|---|---|---|
| [ɡʱəɾᶷ] | ‘house’ | [zalᵊ] | ‘woman, wife’ |
| [t̪əmbu] | ‘tent’ | [ɦəʋa] | ‘air’ |
| [nalo] | ‘name’ | [bʱɪt̪ᶦ] | ‘wall’ |
| [ɡʱoɽi] | ‘mare’ | ||
Sindhi makes use of postpositions, which is typical of Indo-Aryan languages. Most grammatical cases in Sindhi are formed by a noun followed by a postposition, wherein the noun appears in a declined form known as the oblique (see Table 4.8).
Source: Shahaney (1967 [1906], p. 69)
| Nominative | Oblique | Dative | Comitative | |
|---|---|---|---|---|
| Masculine singular | [ɡʱoɽo]‘horse’ |
[ɡʱoɽe] |
[ɡʱoɽe kʰe]‘to the horse’ |
[ɡʱoɽe sã]‘with the horse’ |
| Masculine plural | [ɡʱoɽa]‘horses’ |
[ɡʱoɽənᶦ] |
[ɡʱoɽənᶦ kʰe]‘to the horses’ |
[ɡʱoɽənᶦ sã]‘with the horses’ |
| Feminine singular | [ɡʱoɽi]‘mare’ |
[ɡʱoɽiᵊ] |
[ɡʱoɽiᵊ kʰe]‘to the mare’ |
[ɡʱoɽiᵊ sã]‘with the mare’ |
| Feminine plural | [ɡʱoɽᶦjũ]‘mares’ |
[ɡʱoɽᶦjʊnᶦ] |
[ɡʱoɽᶦjʊnᶦ kʰe]‘to the mares’ |
[ɡʱoɽᶦjʊnᶦ sã]‘with the mares’ |
Verbs are marked for tense, aspect, mood and agreement, with agreement occurring in number and gender with the head noun (Cole, 2001; Grierson, 1919). Adjectives in Sindhi are classified as declinable or indeclinable. Declinable adjectives agree in case, number and gender with the noun they qualify, whereas indeclinable adjectives are invariant (see Table 4.9).
Source: Shahaney (1967 [1906], pp. 68-69)
| Masculine | Feminine | ||
|---|---|---|---|
| Declinable | Singular | [t͡ɕəŋo ɡʱoɽo]‘(a) good horse’ |
[t͡ɕəŋi ɡʱoɽi]‘(a) good mare’ |
| Plural | [t͡ɕəŋa ɡʱoɽa]‘good horses’ |
[t͡ɕəŋᶦjũ ɡʱoɽᶦjũ]‘good mares’ |
|
| Indeclinable | Singular | [məzᶦbut̪ᶷ ɡʱoɽo]‘(a) strong horse’ |
[məzᶦbut̪ᶷ ɡʱoɽi]‘(a) strong mare’ |
| Plural | [məzᶦbut̪ᶷ ɡʱoɽa]‘strong horses’ |
[məzᶦbut̪ᶷ ɡʱoɽᶦjũ]‘strong mares’ |
Of late, a few morphological changes have emerged in Sindhi usage in India. In the literary variety, this primarily involves replacing vernacular Sindhi adjectival declensions with Sanskritic adjectival suffixes. Lekhwani (2011, p. 34) illustrates this phenomenon with the example of the Sindhi word [səmad͡ʑᶷ] ‘society, community’. While this word has traditionally been adjectivised as [səmad͡ʑi] ‘societal’, recent Indian practice is to use the Sanskritised adjectival form [səmad͡ʑɪkᶷ]. In the spoken variety, morphological changes are most evident in the speech of the younger generation. For instance, Parchani (1998, p. 20) observes that the negative copula [naɦe] ‘is not’ may be realised by younger Sindhi speakers as [nə aɦe], where the negative particle [nə] ‘not’ is simply juxtaposed with the copula [aɦe] ‘is’, rather than phonologically merged with it. Such changes may be considered the morphological counterparts to the intergenerational phonological changes described in Section 4.3. For a deeper examination of morphophonological and morpholexical changes in Indian Sindhi since Partition, see Iyengar and Parchani (2021).
4.5 Sociolinguistic overview
4.5.1 Linguistic status
Following Partition and the arrival of non-Sindhi Muslim refugees from independent India in Karachi, Sindhis became a minority in their province’s capital city (§3.4). Consequently, Urdu emerged as the lingua franca among Karachi’s multilingual population, which effectively eliminated the need for non-Sindhis in the city to learn the Sindhi language (Rahman, 1999, p. 27). A government proposal to have non-Sindhi children in Sindh’s schools learn both Urdu and Sindhi as part of the curriculum was never implemented (Bughio, 2006, p. 99). Instead, in 1954, Sindh and its neighbouring regions were assimilated into the territory of West Pakistan, as part of the government’s ‘One Unit’ policy (Rahman, 1995, p. 1010). As a result, Sindh ceased to exist as a distinct geopolitical entity. In 1958, Pakistan’s democratically elected government was overthrown in a military coup, resulting in further centralisation of language policy and the promotion of Urdu at the expense of the country’s regional languages (Bughio, 2006, p. 100). In 1970, the One Unit policy came to an end. With it, Sindh was restored as a province of Pakistan, and Sindhi was once again declared the province’s official language. However, this declaration was strongly opposed by the province’s now-sizable non-Sindhi population, who feared socioeconomic and political sidelining. Simmering linguistic tensions between Sindhis and non-Sindhis culminated in riots in several of the province’s cities (Bughio, 2006; Rahman, 1999). Although a compromise was negotiated, tensions between Sindhis and non-Sindhis persisted. Another period of military rule from 1977 to 1988 pushed the language controversy into the background, following which an uneasy linguistic status quo has prevailed in Sindh up to the present day. Recent qualitative research in Sindh reveals that, despite a high level of bi- and trilingualism and increasing use of Urdu and English in their daily lives, both Muslim and Hindu Sindhis in the province continue to retain a strong sense of ethnolinguistic identity (Abbasi, Khemlani David, & Ali, 2021; Khemlani David & Ali, 2021). For a history of language learning, teaching and policy in Sindh and Pakistan, see Rahman (1999; 2002).
In India, the post-Partition settlement of Sindhi refugees all across the country, primarily in large cities, resulted in a geographically scattered community. Consequently, the urban, cosmopolitan and multilingual environment that the Indian Sindhi community has found itself in since Partition has triggered linguistic changes. According to Lekhwani (2011, p. 33), Sindhi dialectal variation is disappearing in India, with dialects being levelled and the Vicholi variety tending to predominate. In contrast, Daswani (1989, p. 59) states that there is no accepted standard dialect of Sindhi in India, and that every speaker considers their own familial variety to be the reference. Khubchandani (2007, p. 684) notes that the Sindhi language has developed in different directions in Pakistan and in India in the post-Partition era. In Pakistan, the language is undergoing progressive Arabicisation and Urdu-isation, while in India, it is being infused with Sanskrit and Hindi elements, accompanied by a simultaneous purging of unassimilated Perso-Arabic elements. A common element, though, is that urban varieties of the language in both countries are also experiencing increasing Anglicisation. This is corroborated by Nihalani (1978, pp. 3–4) when he points out the reduction of Perso-Arabic elements in colloquial Indian Sindhi and an increase in Hindi and English influence. Sociolinguistically, Sindhi in India is typically used only in familial and cultural environments, with formal education in the language being minimal. Despite a steady increase in speaker numbers over the last seven decades, Sindhi in India has undergone a considerable reduction in functional load since Partition (Iyengar & Parchani, 2021). In large Indian cities where English, Hindi and one or more regional languages dominate, language shift away from Sindhi has also been attested (Iyengar, 2013). For analyses and critiques of phonological, morphological, lexical and sociolinguistic changes in Indian Sindhi since Partition, see Khubchandani (1963; 1998; 2007), Daswani (1979; 1985; 1989), Daswani and Parchani (1978), Lekhwani (2011, pp. 33–35) and Iyengar and Parchani (2021).
Outside of Pakistan and India, the Sindhi language continues to be spoken in the diaspora, albeit primarily by the older generation. Although reliable statistics are lacking, sociolinguistic studies carried out at regular intervals among sections of the worldwide Sindhi diaspora attest to language shift away from the language. For analyses of Sindhi-language proficiency and the sociolinguistics thereof in the worldwide diaspora, see Dewan (1989), Detaramani and Lock (2003), Khemlani David (1991; 1998; 2001) and Raina Thapan (2002).
4.5.2 Education and media
Although not compulsory anywhere in Pakistan or India, state-funded Sindhi-language education is available in both countries. In Sindh, education in the language exists at all levels, from primary to tertiary. Prominent public universities in the province offering doctoral research opportunities in Sindhi include the University of Sindh and University of Karachi.
In India, the initial years of the post-Partition era saw several Sindhi philanthropists endeavouring to set up Sindhi-language schools in areas where the community had settled in considerable numbers. Consequently, a number of schools providing instruction in Sindhi emerged in western Maharashtra and Kutch. However, Sindhis who had settled in other parts of India found it difficult to provide their children with education in their home language. In the first fifteen years after Partition, Khubchandani (1963, p. 29) notes that less than half of the total Sindhi population of India at the time had the opportunity of sending their children to Sindhi-medium schools. That said, he observes that a few such schools had introduced Sindhi instruction in 𝚜𝚍-𝙳𝚎𝚟𝚊, although the majority of them, especially in Maharashtra and Gujarat, taught in 𝚜𝚍-𝙰𝚛𝚊𝚋. While 𝚜𝚍-𝙳𝚎𝚟𝚊 has since become more widely available, the overall demand for Sindhi-language education has fallen drastically (Daswani, 1989, p. 59).
Since 1967, Sindhi has been listed in the Eighth Schedule of the Indian constitution, which makes it an official language of the country and eligible for government support (Daswani, 1979; Vaish, 2008). Apart from being the primary medium of instruction, Sindhi is also eligible to be taught as a language subject in schools under the Three-Language Formula mandated by the Indian government. This formula recommends that children be taught their “mother tongue”, Hindi and English in school, with one of the three languages being the primary medium of instruction. The choice of the “mother tongue” or third language is at the discretion of individual schools (Benedikter, 1999). However, elite schools in urban areas typically employ English as the primary medium of instruction and offer the state language as the third language. These are the schools often preferred by the Sindhi community (Daswani & Parchani, 1978, pp. 88–89). Such a schooling choice often precludes any presence of the Sindhi language in Sindhi children’s education.
As a result of diminishing community demand for education in the language, most Sindhi-medium schools in India have either closed down (Sharma, 2016; Vora, 2016; Wajihuddin, 2010), or are changing their medium of instruction to English, Hindi or a regional language (Sindhi Sangat, 2016). They retain Sindhi only as a language subject, if at all (Anand, 1996, pp. 114, 127). Unfortunately, reliable figures regarding the number and spread of Sindhi schools in India are scarce. The absence of up-to-date and openly accessible government figures means that statistics on Sindhi education in India need to be pieced together from independent academic sources. In western India, Anand (1996, p. 168) provides a figure of 28 schools in Ulhasnagar town that taught Sindhi at the time, at least as a subject. In the metropolises of Mumbai and Pune there are likely no Sindhi-medium schools remaining. A few schools and colleges in these cities offer the language as a subject (Jai Hind College, 2019; MUCC, 2016; St Mira’s, 2021). When taught as a subject, the written form is usually 𝚜𝚍-𝙳𝚎𝚟𝚊. In northern India, Lekhwani (2015) opines that opportunities for formal education in Sindhi are almost nil, save for Ajmer town. That said, language courses at certificate and diploma levels are run throughout the country with the help of central government funding (NCPSL, 2005; 2014; 2015). Options for further study in the language up to the doctorate level are also available at a few major universities, particularly the University of Mumbai.
In Pakistan, Sindhi enjoys a vibrant and vigorous literary output and media presence in its home province, with a significant number of books, magazines and television channels churning out Sindhi-language content in various genres. Lying in stark contrast to the situation in Pakistan is the minimal media presence of Sindhi in India. In terms of audio-visual content, the state-owned All India Radio (AIR) allocates 16 hours per week for Sindhi programmes, including news (Central Institute of Indian Languages, n.d.). Certain channels run by the Indian state-owned television broadcaster, Doordarshan, also have slots for Sindhi-language programming (SABSindhi, 2016). A private Sindhi television channel called ‘Sindhi Kutchi TV’, relaying from Adipur-Gandhidham in Kutch, was briefly available between 2013 and 2016 ("Encyclopedia of Sindhi", 2016). However, at the time of writing this book, there was no widely available Sindhi-language television channel, whether state-funded or private. A campaign has been underway to have the Indian government start a Sindhi-language channel (Live Law, 2015; Punjabi, n.d.), with prominent Indian Sindhi politicians lending their support to the cause (Sindhi Sangat, 2008).
In the meantime, technological advances the twenty-first century have enabled several Pakistan-based Sindhi-language media outlets, as well as smaller Indian ones, to make their audio-visual content available online on video-sharing websites. Being a fairly recent phenomenon, the rise and spread of online Sindhi-language content remains largely unexplored from a scholarly perspective. Although beyond the scope of this book, the linguistic and pedagogical impacts of online Sindhi-language content on the Sindhi community worldwide is a promising avenue for future research.
4.5.3 Literary development
While noting that Sindhi literature has often experienced interruptions due to social turmoil, Kloss and McConnell (1978, p. 466) reiterate that fresh literary activities in the Sindhi language have not been found wanting both in Pakistan and in India. Overall, post-Partition literary productions in Sindhi, both in Pakistan and India, encompass drama, essays, critical works, short stories and novels, biographies, folklore, translations and works in linguistics. A list of prominent post-Partition linguistic works on Sindhi can be found in Khubchandani (2007, pp. 685–686). An overview of lexicographic works in the language in modern times is given in Khubchandani (1988). For comprehensive overviews of Sindhi literature from medieval to post-Partition times, see Allana (1991; 2009), Jetley (1992), Jotwani (1992; 1996), Lekhwani (2011) and Schimmel (1963; 1974).
Following Partition and arrival in India, Sindhis in the country attempted to maintain their linguistic identity by publishing Sindhi-language newspapers, magazines and books, primarily in 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊. A variety of material, including poetry and prose, was thus produced. At the time of writing this book, the Registrar of Newspapers for India (2022) listed the number of active registered newspapers and periodicals in 𝚜𝚍-𝙰𝚛𝚊𝚋 at twenty-one and 𝚜𝚍-𝙳𝚎𝚟𝚊 at two. Most of these periodicals are published from areas of high Sindhi concentration such as Ajmer, Ahmedabad and Mumbai-Ulhasnagar. In terms of literary output, Khubchandani (personal communication, August 2, 2012) notes that Sindhi-language output and writers, although not thriving, are nevertheless on the rise. This can be attributed in part to government grants and recognition such as the annual awards by the Sahitya Akademi, or the National Academy of Letters in India. Similarly, Rohra (2015) highlights the positive impact that governmental and institutional aid and awards given to Sindhi writers have had in increasing the amount of Sindhi literature published. Rohra, however, characterises the situation of written Sindhi in India as “strange”, considering that the number of publications in the language is increasing despite the number of readers decreasing. In contrast, Daswani (1989, p. 59) opines that literary activity in the language is very limited, as is the number of emerging writers.
Both Pakistan and India have state-funded institutions to ensure the Sindhi language’s development and promotion. In Pakistan, the Hyderabad-based Sindhi Language Authority (SLA) has consistently produced a wealth of monographs and pedagogical resources since its establishment in 1990, while also maintaining a healthy output of Sindhi-language academic journals. In India, the state-aided Indian Institute of Sindhology (IIS) and the National Council for Promotion of Sindhi Language (NCPSL) were established contemporaneously with the SLA. The IIS, founded in 1989, claims to be:
[A] centre for advanced studies and research in the fields related to Sindhi Language, Literature, Education, Art and Culture. Its primary aim is to preserve and promote the Cultural heritage of [the] Sindhi Community and ensure its continuity by disseminating it in the younger generation.
The NCPSL, formed in 1994, has similar aims, undertaking:
action for making available in Sindhi language the knowledge of scientific and technological development as well as knowledge of ideas evolved in the modern context, […] [and undertaking] any other activity for the promotion of Sindhi language as may be deemed fit by the Council.
Like the SLA, the IIS and NCPSL are both engaged in publishing Sindhi literary and educational material, as well as conducting language courses. The IIS also runs a state-recognised Sindhi-language school in Adipur, Kutch.
4.6 Summary
This chapter has outlined the linguistic features of the Sindhi language relevant to this study, especially its phonology. It has also shown how the transplantation (Khubchandani, 1995) of the community in independent India has brought about significant changes in the language’s present-day status, role in education, and consequently, everyday use. Evidently, the changes in domains and patterns of language use have brought with them corresponding changes in writing system use.
Changes in use, however, are not new in the context of the Sindhi language, be it in its spoken or written forms. As evinced by the phonological, morphosyntactic and sociolinguistic descriptions in this chapter, the language has absorbed a variety of influence over the centuries. Accordingly, its spoken form has undergone several metamorphoses, as have its written forms. Part Two of this book is devoted to tracing and examining the evolution of Sindhi’s various written forms over the centuries, and to unearthing graphematic and sociolinguistic insights from them.
PART TWO | Writing systems of Sindhi: Descriptions and evaluations
5 Written Sindhi: A chronology
The history of Sindhi’s writing systems goes hand in hand with the history of written literature in the language. Yet, scholarly works focusing primarily on Sindhi writing systems per se are few and far between. Hence, works on Sindhi language and literature often serve as useful secondary sources for information on historical script trends. Harnessing these secondary sources to enrich and contextualise original research, this chapter presents a comprehensive chronology of the writing systems used for the Sindhi language, from the tenth century AD to the present day.46
5.1 Pre-1843
As described in Sections 3.1 and 4.1, neither do we have much substantiated information on the language of the Indus Valley Civilisation, nor have the graphical marks and symbols on the seals excavated at Indus Valley sites been convincingly deciphered. This is despite more than a hundred attempts at decipherment having been made since the 1920s (Robinson, 2015, p. 500). In terms of linguistic decipherment, two of the best-known recent attempts are those of Mahadevan (1977) and Parpola (1996; 2009), both of whom posit that the language of the Indus Valley Civilisation is of Dravidian stock. This hypothesis remains to be universally accepted (Possehl, 2002, pp. 127–140). Alternative claims are even more contested, such as that of the language being related to Vedic Sanskrit (Bright, 1990a; Mitchiner, 1978; Rao S. R., 1982; 1994). With regard to decoding the symbols on Indus Valley seals, researchers disagree on whether these symbols represent a linguistic writing system at all (Rao, et al., 2009; Sproat, 2010b). Yet, claims of graphematic decipherment are common. In his initial work on the Indus Valley Civilisation excavations, Marshall (2004 [1931], p. 423) claims that these symbols were the precursor to the Brahmi script of ancient South Asia. He concedes, though, that the language represented by these symbols is unknown. Certain scholars have attempted to draw a distinction between linguistic and graphematic decipherment, especially in the absence of any evident link between the Indus Valley symbols and subsequent glottography in South Asia. Notwithstanding his position of the Indus Valley language being of Dravidian origin, Parpola (1996, p. 165) emphasises that “[t]here is no connection whatsoever [of the symbols found on Indus Valley seals] with the earliest scripts of South Asia, Brahmi and Kharoshthi”. In this regard, Masica notes that:
[A] serious obstacle to any attempt to link the Brahmi script with the Harappan is the time-gap between the two, which may amount to 1,500 years. […] Despite these difficulties, it may be said that derivation of Brahmi from the Harappan script — somehow — remains the most popular view in India.
Reflecting Masica’s sentiment is a cohort largely if not entirely comprising Sindhi primordialists, whose membership cuts across national and religious lines. This cohort claims that the language of the Indus Valley represents an ancestor of modern Sindhi, predating other linguistic influences (Asani, 2003, p. 613). By extension, the Indus Valley symbols are depicted as a precursor to the present-day writing systems of Sindhi. The intention behind such claims is to confer antiquity to the Sindhi language and its written forms. Khubchandani (2007, p. 687) lists a few authors who have attempted to link the Indus Valley symbols with a proto-Sindhi language and writing system. For reasons evident, such claims remain popular among the Sindhi intelligentsia, whether in Pakistan, India or in the diaspora. These claims may also have adherents in the academy, although scholars of repute tend to express their stance in a measured and nuanced manner, as exemplified by Allana (1993 [1964]):
هت موهن جي دڙي واري لکت کي نظرانداز ڪيو ويو آهي، ڇاڪاڻ تہ جيستائين اها لکت پڙھي نہ ويئي آهي، ۽ اهي ثابت نہ ڪيو وئو آهي تہ اُن لکت واري ٻوليءَ جي ساخت ۽ سٽاءُ ڪھڙي آهي، تيستائين موهن جي دڙي واري ٻوليءَ کي ڊاڪٽر بلوچ صاحب جي لفظن ۾ ”قديم سنڌ جي ٻولي“ چئبو، ۽ موهن جي دڙي واريءَ لکت کي ”قديم سنڌ جي ٻوليءَ جي لکت“ چئبو، نہ ڪ موجوده سنڌي ٻوليءَ جي لکت […]
I have not taken into account here the writing found at Mohenjo-daro. Until this writing has been deciphered and its underlying system and structure established, the language of Mohenjo-daro, in the words of Dr [Nabi Bakhsh Khan] Baloch, should be termed “the language of ancient Sindh”, and its writing “the written form of the language of ancient Sindh”, and not that of the present-day Sindhi language […]
In this sense, the topic of the Indus Valley symbols is one that arises frequently in present-day intellectual opinion on Sindhi writing systems, particularly in India (§13.3).
In terms of attested folklore, oral poetry in what may be reasonably considered ‘Sindhi’ has been dated to the ninth century AD (Asani, 2003, p. 615). Over the years, a rich tradition of poetry, religious hymns and folk ballads emerged in the language. Indeed, Sindhi has been characterised as having one of the most extensive folkloric traditions among Indo-Aryan languages (Schimmel, 1974; Baloch, 1993). That said, several of these compositions were performative in nature, and tended to be propagated through oral means (Boivin, 2020). Therefore, early Sindhi ‘literature’ may be more accurately described as oral literature or orature. This was a trend common to folkloric traditions throughout South Asia, including in Sindh’s immediate vicinity. In the context of the Punjabi language, Grierson (1919) states that:
[i]t contains no prose literature, and the poetry written in it is of the nature of folk-poetry, stored in the memory, and seldom committed to writing.
Yet, for nineteenth-century British and European scholars and administrators, oral traditions, however rich, did not merit the same prestige as a written body of literature. As a result, Sindhi was often depicted by colonial-era writers as a language poor in literature (Grierson, 1919, pp. 12–13; Imperial Gazetteer of India, 1908), with the status of ‘literature’ being reserved mainly for written works composed under the aegis of the British (Aitken, 1907, pp. 481–485). Even those Europeans who devoted their lives to studying the Sindhi language often painted its associated folklore in unsympathetic tones, such as the German-born Christian missionary and Sindhologist Ernest Trumpp. In his pioneering publication of the verses of celebrated eighteenth-century Sindhi poet Shah Abdul Latif, Trumpp (1866) describes Sindhi folklore thus:
I endeavoured to collect, whatever I could, of the old literature of the country, consisting, as I soon found out, of an inexhaustible store of legends, ballads and songs, which had been handed down orally and committed to the memory of the travelling bards and singers; for written books are scarce in Sindh […] unfortunately I could hit upon no native work of any merit, prose being peculiarly disliked by the Sindhis, who have only an ear for jingling verses, like most semi-barbarous nations.
Trumpp’s unflattering portrayal of Sindhi orature and implicit preferencing of written literature is illustrative of colonial-era attitudes of the time. A pithy encapsulation of these colonial attitudes is provided by Boivin (2020, p. 26), who notes that “literacy and illiteracy were a primary cleavage for identifying a civilized and uncivilized people”.
In contrast to British-era perspectives, present-day scholarship tends to agree that written material in Sindhi existed as far back as the ninth century AD, making it more or less contemporaneous with the oldest attested orature in the language. Unfortunately, no specimens from this era have survived, partly due to the tropical climate of South Asia and the perishability of commonly-used manuscript materials such as palm leaf and birch bark (Salomon, 2007, p. 82). Consequently, the existence of the earliest written texts in Sindhi is inferable only through secondary references. Khubchandani (2007, p. 688) and Lekhwani (2011, pp. 26–27) state that the Quran was translated into Sindhi in the ninth century AD, presumably using an Arabic-based script. However, Schimmel (1963, p. 224) adds a layer of nuance to this claim, noting the lack of clarity on whether the translation was into an earlier stage of Sindhi or of a related north-western Indo-Aryan language. Chatterji (1958) refers to the supposed existence of a Sindhi version of the Sanskrit-language epic Mahabharata in the eleventh century AD, known only through its subsequent Arabic and Persian translations. The script used in the Sindhi composition, however, is not known. In discussing specimens of written Sindhi, Allana (1993 [1964]) lists several toponyms of Sindh mentioned in the Chachnama, a thirteenth-century Persian translation of a now-lost Arabic-language chronicle of the Arab conquest of Sindh (Qalichbeg, 1900).47 Strictly speaking, the Sindh-related toponyms in the Chachnama are transcribed in accordance with the Persian-Arabic (𝚏𝚊-𝙰𝚛𝚊𝚋) writing system. For Allana, though, they count as early written specimens of Sindhi.
Nevertheless, there exists evidence that earlier stages of what might be reasonably considered Sindhi were written using multiple scripts even a thousand years ago. The tenth-century Arab traveller Al-Nadim cites accounts of there being two hundred scripts being used in Sindh at the time (Dodge, 1970, p. 34). Al-Nadim’s contemporary, the Persian scholar Al-Biruni, reports a more plausible three scripts in vogue in the region at the time. He gives their names as Ardhanagari (half-Nagari), Malwari and Saindhava (Sachau, 1910, p. 173).48 Considering that Sindh was under Arab rule at the time (§3.2), there exists scholarly conjecture (Allana, 1993 [1964], p. 34; Baloch, 1962; Rahman, 1999, p. 22) that at least one of these scripts would have been an offshoot of the Arabic script. This speculation aligns with the evidence that, in pre-British times, the graph inventories used for writing Sindhi essentially fell into two broad categories — those of Semitic origin, namely the Arabic script, and those derived from the ancient Brahmi script of South Asia, known as Brahmic or Indic.
5.1.1 Unstandardised Landa
The Indic inventories used for Sindhi in pre-British times were part of a macrofamily of related but unstandardised inventories known collectively as Landa.49 Being an unstandardised macrofamily, there is no IETF script subtag for the Landa inventories. Their genealogical relationship to Brahmi is shown in Figure 5.1.

Source: Pandey (2010a, p. 2)
The Landa inventories were well established in north-western South Asia by the sixteenth century AD (Grierson, 1916, p. 624), and were prevalent from Kashmir in the north to Gujarat in the south.50 Besides sharing a common genealogy, these inventories were also visually similar. They existed along a graphetic continuum, varying gradually based on geographical location and user group (Stack, 1849a, p. 1; Trumpp, 1872, p. 1). Sociolinguistically, these unstandardised inventories were primarily used by traders for private bookkeeping purposes. Consequently, the Landa inventories came to be identified with their mercantile user group, and derived their local names accordingly. In Sindhi, the Landa inventories were known as Vanika (Asani, 2003, p. 623; Grierson, 1919, p. 14; Pandey, 2010a, p. 1) or Hatavanika (Lekhwani, 2011, p. 36), both being adjectival forms of vanio ‘trader’ (pl. vania). In later years, the synonymous Hindi-origin designation bania ‘trader’ was also applied to these inventories, particularly by European colonial authors.51 Graphematically, the unstandardised Landa inventories comprised a sufficient number of discrete graphs to permit distinct representation of most — although not all — phonological consonants present in north-western Indo-Aryan speech varieties (§4.3.1). Where they fell particularly short was in the available number of discrete graphs to distinctly represent φ-vowels. Typically, the Landa inventories possessed only three basic shapes or rasms for representing the ten or so φ-vowels typical of north-western Indo-Aryan speech varieties (§4.3.2). In the absence of graphetic or graphematic augmentation, the three available rasms were generally used to denote three underspecified vowel archiphonemes: low, high front and high back. Graphematically unencoded phonological information on vowel quality, including nasalisation, had to be mentally filled in by the reader from context. Also, the three rasms for vowel archiphonemes were typically restricted to word-initial or syllable-initial position, although they were occasionally, albeit unpredictably, used in final position in monosyllabic words. Unstandardised writing systems based on the Landa inventories were notable for having no generally accepted provision to represent word-medial φ-vowels (Shackle & Moir, 1992, pp. 34–35). It was up to individual writers to idiosyncratically insert one of the three rasms as matres lectionis if desired (Shackle & Skjærvø, 2006, p. 547). Unsurprisingly, graphematic practices commonplace today, such as word spacing and punctuation, were rarely observed consistently in the past (Pandey, 2010a, p. 1). It was the perceived graphematic deficiency inherent in such writing practices that resulted in the name Landa, meaning ‘clipped’ or ‘tailless’ (Grierson, 1904, p. 68; Pandey, 2010a, p. 1; Pandey, 2010d, p. 2).
Colonial-era British and European authors who encountered the unstandardised Landa-based systems in the nineteenth century were generally contemptuous of them. In his Sindhi grammar, Trumpp (1872, p. 1) dismisses the Landa-based systems as “utterly unfit for literary purposes”, claiming that “merchants themselves, after a lapse of time, are hardly able to reproduce with accuracy what they have entered in the ledgers”. Sharing Trumpp’s sentiment, Grierson (1919, p. 14 footnote) notes that:
[a]s regards the illegibility of this Wāṇikō character, there is a proverb, Wāṇikā akharᵃ bbuṭā, sukā paṛhaṇᵃ-khā̃ chhuṭā, the Wāṇikō letters are vowelless, (as soon as the ink is) dry, they are […] illegible.52
Grierson (1919, p. 14 footnote) also reports a story on the supposed perils of employing Landa-based systems in written communication. A merchant once wrote to his son in Sindhi-Landa, asking to send [nəɳɖʱ(ɾ)i ʋəɦi puʈʰe sud̪ʱi] ‘the small accounts book with the cover’. The son interpreted the message as being asked to send [nəɳɖʱ(ɾ)i ʋəɦu puʈ(ɾ)ə sud̪ʱi] ‘the younger daughter-in-law with (her) son’. Similar apocryphal tales on the supposed misinterpretations arising from quick-and-dirty Landa-based writing continue to be popular among Sindhis even today (Falzon, 2004, p. 272). In a similar anecdote related to me by a contemporary Sindhi litterateur (interviewee 26M; see Chapter 13), someone wrote the following message to an acquaintance in Sindhi-Landa: [ɦu əd͡ʑᶦmeɾᶦ ʋᶦjo] ‘He went to Ajmer town’. The recipient read it as [ɦu əʄᶷ məɾi ʋᶦjo] ‘He died today’. Whether the interpretations cited in these jokes are graphematically plausible is a matter of debate, and will be examined further in Section 8.1 (Example (20)). Regardless, the persistence of humorous tales arising from the supposed illegibility of Sindhi-Landa implicitly indexes a more sober reality — that present-day literacy in Sindhi-Landa is practically nil.
Despite the now-legendary ambiguity of Landa-based writing and its consequent exoticisation, the practices observed seem graphematically plausible and consistent with their sociolinguistic functions. Graphematically, representing nearly ten φ-vowels in word-initial position using just three rasms has been attributed to influence from Semitic writing practices (Masica, 1991, pp. 150–151; Salomon, 2007, p. 93; Shackle, 2007, p. 651). Lekhwani (personal communication, December 8, 2014) also surmises that the Arabic-Arabic (𝚊𝚛-𝙰𝚛𝚊𝚋) convention of leaving word-medial φ-vowels unmarked, especially in quotidian writing, may have influenced the avoidance of medial vowel graphs in Landa-based writing. In other words, the possibility of a spillover effect from 𝚊𝚛-𝙰𝚛𝚊𝚋 practices onto Sindhi-Landa cannot be ruled out. Lekhwani’s conjecture is echoed by a major nineteenth-century work on world scripts (Faulmann, 1880a, p. 121), which ascribes Sindhi-Landa’s focus on consonant graphs to Semitic abjadic practice. To illustrate the nature of such abjadic writing, Sproat (2010a) provides the following example based on 𝚎𝚗-𝙻𝚊𝚝𝚗:
f u cn rd ths u cn b trnd as a scrtry nd gt a gd jb
According to Sproat, a competent speaker-reader of English and 𝚎𝚗-𝙻𝚊𝚝𝚗 should be able to fill in the missing graphematic — and, in turn, phonological — information to accurately decode the message as ⟨if you can read this, you can be trained as a secretary and get a good job⟩. It is also evident that such writing, despite posing an increased cognitive load for the reader, is extremely convenient for the writer in terms of speed. Sproat’s example, thus, serves as a convenient demonstration of how, and why, the supposedly ‘deficient’ Landa-based systems managed to function effectively. For starters, the Landa-based systems were primarily used to maintain mercantile records and account books, which remained largely restricted to their authors and close associates. Consequently, readability by a wider audience was not a priority. Even when the intended reader was a third party, the writing did not pose insurmountable hurdles as long as the reader was reasonably proficient in the language represented. Moreover, as noted by Prinsep (1837, p. 352), “the inconvenience of this omission [of vowel graphs] is not much felt in the limited scope of mercantile correspondence, […] where the same sentences are constantly repeated”. Above all, the near-exclusion of vowel graphs allowed for quick writing and note-taking. Sociolinguistically, this proved to be a particularly valuable convenience to its primary user group of traders and merchants (Shackle & Moir, 1992, p. 35).
It is often mentioned in the literature that the unstandardised Landa inventories were a secret traders’ script (Anand, 1996, p. 8; Boivin, 2015; Falzon, 2004). Such depictions may be understood to imply that the graphematically opaque practices in question were deliberate, allowing traders to maintain their accounts in a cryptic form and conceal details of their dealings from the authorities. However, and as mentioned, it seems more plausible that these seemingly opaque practices arose simply from traders’ need for expedience and compactness rather than phonetic fidelity. Indeed, the two functions of Sindhi-Landa as an expedient writing system, as well as a secret code, go hand in hand. In other words, to the extent Sindhi-Landa was used as a secret code, it was likely a convenient extension of it being known only to a restricted user group (Falzon, 2004, p. 271). For these reasons, Landa-based writing systems remained in vogue for centuries across north-western South Asia, including in Sindh (Shackle & Skjærvø, 2006, p. 547).
Irrespective of their popularity for bookkeeping and private note-taking, the unstandardised Landa-based systems exhibited high levels of idiosyncratic variation and low levels of graphetic and graphematic normativity. These features prevented the systems as such from being extensively used for literary purposes (Hotchand & Bhojwani, 1982 [1915], p. 165 footnote). This was unsurprising, since literary writing is a genre intended to be read and understood by a wide audience, thereby necessitating consistency in graphetic form and graph-phone correspondences. Moreover, in pre-British Sindh, propagation by oral means remained the most common mode of transmitting folklore, with written compositions limited in number. Those Sindhi-language compositions that were written down were often intended for a specific audience, which, in turn, dictated the choice of script.
5.1.2 Arabic
In addition to the unstandardised Landa scripts, Sindhi in pre-British times was written in the Arabic script, not least because educated persons in Muslim-majority Sindh often acquired basic competence in 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 (Lekhwani, 2011, p. 38). As described earlier in this section, it is plausible that Sindhi was written in the Arabic script as far back as a thousand years ago, although first-hand evidence of such writing has not survived. Hence, the graph inventory and graph-phone correspondences of early Sindhi-Arabic (𝚜𝚍-𝙰𝚛𝚊𝚋) writing is not known with certainty. According to Jetley (1987b, pp. 196–197), a collection of Persian and Sindhi verses attributed to Sufi preacher Abdul Karim of Bulri (1537?–1622) were written down by his disciple Muhammad Shah in the year 1628. Jetley states that the Sindhi-language verses were written down in “Persian script”, although details of the graph inventory and graph-phone correspondences used are not stated. Also present in the same collection are Sindhi-language verses attributed to Qazi Qadan, whose work has also been found transcribed in Devanagari (§5.1.3).
In the seventeenth century, the 𝚜𝚍-𝙰𝚛𝚊𝚋 graph inventory and graph-phone correspondences were substantially refined by Abul Hasan, a theologian from the politically significant town of Thatta in south-central Sindh.53 The refinements primarily comprised adding dots to existing graphs or rasms in the inventory to create distinct graphs for Sindhi-specific phonemes absent in the Arabic or Persian languages. Graphematically noteworthy among these modifications was the tendency to depict of aspirate φ-stops using only one rasm, modified by dots as required. This was illustrative of the emic view that the aspirated φ-stops were single phonemes, and not clusters of a φ-stop and /h/ (Trumpp, 1872, p. 3). This augmented version of 𝚜𝚍-𝙰𝚛𝚊𝚋 came to be known as “Abul Hasan Sindhi” (§6.2). In spite of this attempt at standardisation, ambiguities persisted in the 𝚜𝚍-𝙰𝚛𝚊𝚋 graph inventory and graph-phone correspondences in pre-British times. These mainly concerned inconsistencies in the application of dots for creating new graphs, and the graphematic underdifferentiation of certain phonemes (Trumpp, 1872, pp. 2–3). These matters would not be addressed until after the British conquest of Sindh.
5.1.3 Devanagari
In addition to the unstandardised and proto-standardised inventories from the Landa macrofamily, a non-Landa Indic script said to be occasionally used for the Sindhi language in pre-British times was Devanagari. That said, the name of the script as used in the context of pre-British era Sindhi writing requires further qualification. Strictly speaking, Devanagari (from Sanskrit deva- ‘divine’ and -nagari ‘of the city, urban’) is a specific graph inventory from the Nagari macrofamily (Maurer, 1976; Salomon, 1998, pp. 40–41). However, the term is sometimes used by present-day authors to refer to any Brahmic or Indic graph inventory, including Landa-based ones. According to Taylor (1883), such broad-based use of the term ‘Devanagari’ likely became entrenched thanks to its use in British-authored works of the late eighteenth century:
The term Devanagari, which would mean the divine or sacred Nagari, is not used by the natives of India, and seems to have been invented by some ingenious Anglo-Indian [i.e., English person in India] about the end of the [eighteenth] century. It has, however, established itself in works on Indian Palæography, and may be conveniently retained to denote that particular type of the Nagari character employed in printed books for the sacred Sanskrit literature, while the generic term Nagari may serve as the designation of the whole class of vernacular alphabets of which the Devanagari is the literary type.
In line with Taylor’s observations, specimens of written Sindhi composed in a Landa inventory may be described by certain authors as ‘Sindhi in Devanagari’. It is with these provisos in mind that we need approach Sindhi-language works written in graph inventories collectively identified as ‘Devanagari’. Most works in this category comprise Sindhi-language poetry on Sufi, Vedantic and spiritual themes. Prominent among them are the Sufi verses of Qazi Qadan (d. 1551), hailed as one of the earliest Sindhi poets (Asani, 2003, p. 616 ff.; Lekhwani, 2011, p. 37; Schimmel, 1974, p. 11), as well as the Sindhi-language verses of sixteenth and seventeenth-century mystics Dadu Dayal and Pran Nath (Khubchandani, 2007, p. 693; Lekhwani, 2011, p. 37).54
As mentioned, the blanket characterisation of the graph inventories in question as ‘Devanagari’ may inadvertently gloss over underlying graphetic (and graphematic) differences among them. Moreover, the gradual variation in graphetic appearance among Indic-origin graph inventories used to write Sindhi has resulted in disparate interpretations and descriptions. That said, certain authors are particular about distinguishing between the graphetic forms used in the pre-British Sindhi manuscripts and in contemporary Devanagari. In analysing and interpreting these poems, Sindhi litterateur Hiro Thakur characterises the manuscript containing Qazi Qadan’s poems as being written in “پراڻي ديوناگري” [pʊɾaɳi d̪eʋᵊnaɡᵊɾi] ‘old Devanagari’ (Thakur, 1996, pp. 35–36). He also notes that several graphs in the inventory used were graphetically distinct from their present-day equivalents. Likewise, a Gujarati-language collection of Dadu Dayal’s works (Bhavnani, 2000) characterises their written form as follows:
એમનું સમગ્ર સર્જન એક જ લિપિમાં લખાયું છે. આજની દેવનાગરીના જેવી જ એ લિપિ છે.
His entire body of work has been written down in the same script, which is very similar to present-day Devanagari.
Along similar lines, the graphetic differences between modern Devanagari and the script in which Pran Nath’s poetry has been found written are evident in a facsimile on display at the Sindhi Language Authority in Hyderabad, Sindh (Hauze, 2016a; 2016e). Also relevant in this regard is the fact that some of these written specimens were discovered much after their contents were initially composed in oral form. For instance, a substantial portion of Qazi Qadan’s Devanagari-script works were discovered only in the 1970s, among a multilingual repository of manuscripts found in India’s Haryana state (Thakur, 1996).
Against this background, one needs to bear in mind at least two caveats when analysing works considered to be in Sindhi-Devanagari (𝚜𝚍-𝙳𝚎𝚟𝚊). First, the term ‘Devanagari’ may simply mean a graph inventory that is graphetically similar to present-day Devanagari, while also visually resembling other historical and contemporary scripts and inventories. Second, the 𝚜𝚍-𝙳𝚎𝚟𝚊 works in question may have been written down by other authors, sometimes much after they were initially composed. In such a case, 𝚜𝚍-𝙳𝚎𝚟𝚊 may simply represent a transcription of the original oral composition, with the choice of script being determined by the writer’s or intended audience’s proficiency. In other words, the choice of script may not have been the original composer’s choice, but decided based on user-oriented or use-oriented factors (§5.1.6).
Notwithstanding the above, there exists evidence of the Gospel of Matthew from the Bible being translated into Kutchi and printed in the Devanagari script in 1834. For specimens and an analysis of this text, see Section 7.2.
5.1.4 Khudawadi, Gurmukhi and Khojki
Although most Landa-based writing was unstandardised and idiosyncratic, there existed at least three inventories from the Landa macrofamily that exhibited evidence of proto-standardisation. During the eighteenth-century rule of the Kalhoro clan in Sindh (§3.2), the Landa inventory prevalent in the capital city at the time, Khudabad, underwent a modicum of graphetic standardisation. Consequently, the Landa-based graph inventory characteristic of Khudabad came to be known as Khudabadi or Khudawadi (Lekhwani, 2011, p. 36; Pandey, 2010a; 2010d).55 Despite basic emic standardisation, Khudawadi was not used for writing any substantial amounts of Sindhi-language literature. In contrast, two Landa-derived graph inventories that did go on to be used in literary contexts were Gurmukhi and Khojki. Given the organic standardisation they went through, both Gurmukhi and Khojki are commonly understood as full-fledged ‘scripts’. Despite being associated with different faith groups in the popular imagination, the two scripts bear striking similarities to each other in terms of the time period in which they emerged, and the sociolinguistic contexts in which they were used.
Gurmukhi is a script whose Landa-based graphetic predecessor was geographically located in Punjab, and not in Sindh (Figure 5.1).56 Its traditional inventory of thirty-five graphetic rasms led to the alternative appellation Paintih ‘the thirty-five’ (§9.1). According to legend, Gurmukhi in its present form was created, or least standardised, by the Sikh spiritual leader Guru Angad (1504–1552). The motivation behind the script’s standardisation was to accurately transcribe the Sikh community’s religious hymns, composed in Punjabi, Sindhi and other north-western Indo-Aryan varieties. Initially compiled in the early seventeenth century into a collection known as the Adi Granth (‘First Book’), the final, enlarged collection transcribed came to be known as the Guru Granth Sahib.57 Accordingly, the Sindhi-language hymns appearing in the Adi Granth in Gurmukhi script form the earliest known examples of the Sindhi-Gurmukhi writing system (𝚜𝚍-𝙶𝚞𝚛𝚞). As Sikhism spread to Sindh and gained popularity, a section of the faith’s adherents in the region learnt Gurmukhi to be able to read Sikh scriptures. Predominant among the Gurmukhi-literate Sindhi population were women, as they tended to devote more time to religious rituals than men (Falzon, 2004, p. 54; Khemlani David, 2001, p. 231).
Aside from Sikh scripture, probably the most noteworthy examples of written literature in 𝚜𝚍-𝙶𝚞𝚛𝚞 dated to the pre-British era are the couplets of Sindhi poet Sami (1743?–1850) (Hauze, 2016f). Overall, though, Gurmukhi remained restricted to Sikh temples and books, and did not find wide use as an everyday script for the Sindhi language (Lekhwani, 2011, pp. 37–38). An in-depth description and graphematic analysis of 𝚜𝚍-𝙶𝚞𝚛𝚞 follows in Section 8.3.
Besides Gurmukhi, another Landa-based graph inventory that underwent a degree of emic normativisation in pre-British times was Khojki. The script originated within the Nizari Ismaili branch of Shia Muslims in Sindh and Kutch, and was used to transcribe the community’s canon of ceremonial hymns or ginans composed in Sindhi, Kutchi and other north-western Indo-Aryan speech varieties (Asani, 1991, pp. 4–5).58 The name Khojki was first attested only in the mid-twentieth century (Virani, 2022), and is a neologised adjectival form of Khoja, a commonly used emic and etic ethnonym for the Nizari Ismaili community of South Asia (Chapter 10).59 The term Khojki has since gained some currency in scholarly circles, but remains far from ubiquitous within the lay community (Virani, 2022). Based on its traditional forty-graph inventory, Khojki was also known as chaliha akhari or chari akhari ‘forty-letter script’ (§10.2).
Much like Gurmukhi, the origins of Khojki are folklorically traced to a community spiritual figure. Legend has it that Khojki was created, or at least polished, by Pir Sadruddin (also spelt |Sadardin|; d. 1416?), a fifteenth-century Ismaili missionary or pir active in the Sindh region (Allana, 1993 [1964], p. 37; Asani, 1987, p. 439).60 Notwithstanding creation legends, the oldest extant Khojki-script manuscript is dated 1737 AD (Khakee, 1972). Yet, it is possible that some of the content of later Khojki-script texts was originally composed as far back as the fourteenth century (Shackle & Moir, 1992, p. 10). Given the potential presence of fourteenth-century elements, Schimmel (1963, p. 224) opines that the oldest surviving Khojki-script texts may well represent some of the earliest extant evidence of Sindhi religious literature. However, Allana (1993 [1964], pp. 32–34) posits a much older timeframe for the oldest surviving Khojki-script specimens. In the early 1960s, the Department of Archaeology of the Government of Pakistan excavated several potsherds around the town of Bhambhore in southern Sindh. The potsherds were dated to the eighth century AD and featured certain symbols on them. Allana argues that the symbols are glottographic in nature, and, based on graphetic comparison, equates individual symbols with specific graphs of the Khojki inventory. In so doing, he also attempts to reconstruct a Sindhi-language message encoded in the graphs, thereby implying that the inscriptions on the potsherds are an instance of the Sindhi-Khojki (𝚜𝚍-𝙺𝚑𝚘𝚓) writing system. Also, since the potsherds were dated to the pre-Islamic and early Islamic period in Sindh (§3.2), Allana contends that the symbols on them affirm that Sindhi was written in Khojki even in pre-Islamic times. In view of the unstandardised nature of the Landa inventories and the attested graphetic variation therein, Boivin (2015) notes that the symbols on the potsherds may well be compared with another proto-standardised daughter inventory of Landa, namely Khudawadi. Boivin does, however, concede that the symbols on the potsherds, if glottographic, may well be considered early graphetic variants of Landa-based writing. For a detailed graphematic analysis of the Sindhi-Khojki and Kutchi-Khojki (𝚔𝚏𝚛-𝙺𝚑𝚘𝚓) writing systems, see Chapter 10.
Khojki, Gurmukhi and, to a lesser extent, Khudawadi, represent the most significant and successful instances of proto-standardised Landa-based inventories emerging in pre-British times. Overall, the Landa inventories may be considered the indigenous scripts of north-western South Asia, particularly in Sindh and Punjab. Colonial-era authors who were often disdainful of the variable graphematics of Landa-based systems were nevertheless obliged to recognise their sociolinguistic significance. In the context of Punjab, Grierson (1916, p. 624) describes the regional Landa forms as the “true alphabet” of the region. Similarly, Stack (1849a) designates the local Landa inventories of Sindh — including Khojki and Khudawadi — simply as “Sindhi” to mirror community practice. Indeed, despite Khojki and Khudawadi undergoing considerable graphetic standardisation in British times, their respective user groups continued to refer to them homonymously as ‘Sindhi’ well into the twentieth century (Virani, 2022). An intriguing, if coincidental, outcome of this nomenclatural legacy is the four-letter IETF script subtag assigned to Khudawadi, which is 𝚂𝚒𝚗𝚍 (Pandey, 2010f).
5.1.5 Roman
By the early 1800s, the growth of British control over parts of South Asia resulted in increasing geopolitical focus on Sindh (Cook M. A., 2013; 2016a). Consequently, British and European interest in the people, culture and language of the region began to grow. The earliest European-authored works on Sindhi varieties were translations of the Bible in the 1820s and early 1830s, printed in the Arabic and Devanagari scripts (§6.2, §7.2). The choice of script was most often dictated by the availability of metal types.
European-authored works on Sindhi grammar and lexicography began to appear by the mid-1830s (Hoernle, 1885, p. 162). Significantly, most of these works featured Sindhi transcribed in Roman, resulting in a distinct writing system (𝚜𝚍-𝙻𝚊𝚝𝚗). Again, the choice of script was dictated primarily by typographical constraints, although the intended readership — people of European and British origin — also played a part. Probably the earliest such work is the 1836 Sindhi grammar of British colonial administrator and epigraphist William Henry Wathen, reviewed by famed Indologist James Prinsep in the Journal of the Asiatic Society (1837). Through Prinsep (1837, p. 351) and Stack (1849a, p. v), we know that Wathen’s work featured Sindhi transcribed in 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙻𝚊𝚝𝚗, although, in terms of function, the latter was intended only as a transliteration to the former. Unfortunately, I was unable to obtain a physical or electronic copy of Wathen’s work, because of which the details of the 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙻𝚊𝚝𝚗 graph-phone correspondences as used by Wathen remain unclear. Significantly, Wathen’s work contains a sample of the Khudawadi graph inventory, cited by Prinsep (1837) as “Sindhi”. This makes Wathen’s work likely the first instance of Sindhi-Khudawadi (𝚜𝚍-𝚂𝚒𝚗𝚍) appearing in print. This was followed by another instance of 𝚜𝚍-𝚂𝚒𝚗𝚍 in print, in the form of a lithographed handwritten English-Sindhi wordlist by British civil servant Edward Backhouse Eastwick (1843a). Eastwick’s work features Sindhi-language entries alongside their English glosses, with the Sindhi entries listed in both 𝚜𝚍-𝚂𝚒𝚗𝚍 and 𝚜𝚍-𝙻𝚊𝚝𝚗. The 𝚜𝚍-𝚂𝚒𝚗𝚍 writing featured in Eastwick’s work was illustrative of the graphematically unstandardised and phonologically underdifferentiated practice in vogue at the time. The 𝚜𝚍-𝙻𝚊𝚝𝚗 system essentially comprised applying 𝚎𝚗-𝙻𝚊𝚝𝚗 graphematic principles to transcribe Sindhi-language lexicon, augmented only by the inconsistent use of the graphs |á í ú| to denote the Sindhi φ-vowels [a i u]. Overall, neither the 𝚜𝚍-𝙻𝚊𝚝𝚗 nor the 𝚜𝚍-𝚂𝚒𝚗𝚍 systems seen in Eastwick’s work consistently distinguish between lax and tense φ-vowels, or between dental and retroflex φ-consonants.61 A subsequent version of this work (Eastwick, 1843b) was printed using movable type, albeit only featuring entries in 𝚜𝚍-𝙻𝚊𝚝𝚗 since Khudawadi-script types had not yet been developed at the time.
5.1.6 User-oriented and use-oriented writing
In the centuries immediately preceding British colonisation, Sindh remained under the sphere of influence of the Persianate Mughal dynasty (§3.2). Consequently, Persian served as the court and prestige language in Sindh for much of this period (Burton, 1851, pp. 63–69), and was used to maintain government records (UK Parliament, 1854). It followed that official scribes, regardless of socioreligious background, needed to acquire reasonable proficiency in 𝚏𝚊-𝙰𝚛𝚊𝚋. As it turned out, such Persian-literate scribes were often of Hindu-Sikh background, and came to be identified as a distinct social class called Amil (Burton, 1851).62 Significantly, even 𝚏𝚊-𝙰𝚛𝚊𝚋 writing existed in a complementary distribution similar to that observed in Sindhi-Landa. While official documents were written in ‘full’ 𝚏𝚊-𝙰𝚛𝚊𝚋, everyday or personal writing in 𝚏𝚊-𝙰𝚛𝚊𝚋 was often written using the shikasta or ‘broken’ calligraphic style — a handwriting style that enabled quick writing but was often difficult to read (Meidani, 2020).63 In this regard, the graphematic practice in 𝚏𝚊-𝙰𝚛𝚊𝚋 attested in Sindh was consistent with practice in other systems, particularly the Landa-based ones, and similarly criticised by British observers (Burton, 1851, p. 69; UK Parliament, 1854, p. 347).
In contrast to educational and writing practices for lay purposes, education and writing practices in religious contexts was primarily in liturgical languages, namely Arabic for Muslim clergy and Sanskrit for Hindu priests. This also necessitated becoming functionally literate in the corresponding writing systems — 𝚊𝚛-𝙰𝚛𝚊𝚋 and Sanskrit-Devanagari (𝚜𝚊-𝙳𝚎𝚟𝚊), with the label ‘Devanagari’ subject to the caveats outlined in Section 5.1.3.64 The mercantile classes, as already described, were literate in one of the various Landa inventories, the appearance of which was nominally conditioned by geography and socioreligious background. As a result, distinct graphetic styles of the Landa inventories became associated with specific areas of Sindh, as well as with socioreligious groups. Geographically identifiable graphetic styles were named after the principal city of the region, resulting in names like Khudawadi, Shikarpuri and Thattai. Styles typical of socioreligious groups took on the demonyms of those groups, such as those used by the Shia Ismailis and Sunni Memons (Stack, 1849a, pp. 3–8).64 Although reliable statistics are unavailable, it is conceivable that a minority of merchants would have been conversant in their group-specific Landa inventory as well as in the script used for their community’s liturgical language (Allana, 1993 [1964], p. 36). Moreover, as outlined in Section 5.1.4, certain Hindu-Sikh women acquired proficiency in Gurmukhi, to read Sikh scriptures. Notably, Sindhi was transcribed in Roman by European and British authors just prior to British colonisation, although such use stemmed primarily from typographical limitations. Overall, though, education and writing practices in Sindh prior to the British conquest of 1843 was stratified by “vocational relevance” (Khubchandani, 1977, p. 34), further categorisable into a user-oriented and use-oriented stratification. Such stratification of graphematic adoption based on vocation, socioreligious background and even gender meant that different user groups tended to be conversant with different scripts. Regardless, spoken Sindhi, in its regional varieties, remained common to all sections of society (Aitken, 1907, p. 473).
Despite Sindhi varieties being the predominant medium of oral communication in the region, none of these local varieties had any official status up until the mid-nineteenth century (Boivin, 2020). The lack of administrative or societal recognition for Sindhi led Stack (1849a) to write:
The study of [Sindhi] has been always despised — the most by those who had pretensions to education. Learned Musalmans read Arabic and Persian; Hindoos the latter, or Punjabi and Hindi. The speech they learnt at their mothers’ breasts, was thought only fit for clowns.
It is debatable whether Sindhi was “despised” and “thought only fit for clowns” by its speakers at the time. What is less debatable is that the language was subordinate in social prestige to Persian, Arabic and Sanskrit. In part, the lack of official status for Sindhi explains why, prior to the British era, the language was written primarily in informal contexts and in a plethora of graphetically unstandardised graph inventories (Asani, 2003, p. 622).
5.2 1843–1947
By 1843, Sindh had fallen into British hands. The new rulers had a policy of running lower-level administration in the local language (Khubchandani, 2007, p. 696). However, Bartle Frere, the British-appointed Commissioner in Sindh, noted that knowledge of the Sindhi language was low among British officers stationed in the region, with only two officers reported to be conversant as of the late 1840s (Martineau, 1895, p. 122). Sindhi scribes and interpreters employed in the administration spoke Sindhi natively, but read and wrote primarily in 𝚏𝚊-𝙰𝚛𝚊𝚋 based on practice in the pre-British era and the absence of a generally accepted writing system for their native language (Aitken, 1907, p. 474). Proceedings in British-instituted courts in Sindh were described by Frere’s biographer thus:
The usual process in all official proceedings before Europeans was that the Sindi [sic] parties and witnesses spoke Sindi, a Moonshee interpreted between them and the European officer in Hindustani [Hindi-Urdu], and all was written down in bastard Persian.66
For the colonisers, oral and grapholinguistic fluidity in official contexts evidently came across as aberrant practice, and needed to be replaced by a uniform spoken and written language. Consequently, Frere decided that any use of Persian in administrative contexts would be done away with, and would be replaced by Sindhi as the official language of the colonial administration of Sindh. In 1851, Frere decreed that administrative officers would need to pass an examination in spoken Sindhi (Aitken, 1907, p. 474). Additionally, he proposed a higher level of examination in which knowledge of spoken and written Sindhi would be tested, and recommended that the government bear the cost of printing Sindhi-language books in any script (Martineau, 1895, p. 123). However, employing written Sindhi in government records or in book printing necessitated a generally accepted writing system for it, comprising at least a standardised graph inventory and reasonably consistent graph-phone correspondences (Allana, 1993 [1964], p. 96). Under the chairmanship of Barrow Ellis, Assistant Commissioner in Sindh, a committee was established to choose a script and decide on the graph inventory and graphematic fundamentals of an official writing system for Sindhi. In addition to Ellis, the committee comprised eight local and two European members (Allana, 1993 [1964], p. 96; Jetley, 2007; Matlani, 2008). The local members of the committee were:
- Rai Bahadur Narayan Jagannath Vaidya, a Marathi Brahmin originally from Ratnagiri (today in Maharashtra state, India);
- Khan Bahadur Mirza Sadiq Ali Beg of Hyderabad;
- Diwan Pribhdas Anandram Ramchandani of Hyderabad;
- Diwan Udharam Thanvardas Mirchandani of Hyderabad;
- Diwan Nandiram Navani of Sehwan;
- Mian Mahomed Shah of Hyderabad;
- Qazi Ghulam Ali of Thatta;
- Mian Ghulam Husain of Thatta.
The two European members were George Stack and Richard Francis Burton, both civil servants with the colonial administration.
5.2.1 Arabic
Stack was the author of the first comprehensive dictionaries of Sindhi (Stack, 1849b; 1855) as well as a detailed grammar of the language (1849a). Despite favouring a standardised Landa-based inventory as the official script for Sindhi (Government of Bombay, 1857, p. 105), Stack used Devanagari to print Sindhi-language content in all his works. In the introduction to his grammar (1849a, pp. v–vi), he decides against any of the Landa inventories — which he collectively terms “Sindhi” — due to their supposed “scanty use of vowels”. He rejects Roman since its inventory would supposedly require considerable augmentation if a transparent writing system is desired. According to Stack, acquainting oneself with this augmented graph inventory would allegedly involve as much effort as learning a new script altogether. Yet, he acknowledges that the existing inventory of Devanagari, too, would require augmentation to align it with Sindhi phonology, albeit justifying such augmentation by claiming it would be minimal in nature. Notably, Stack admits that Gurmukhi had an advantage in “being […] more known to Hindoos in Sindh” than Devanagari, and concedes that the latter was largely unfamiliar to Sindhis themselves. Eventually, he selects Devanagari for his grammar and dictionaries on the grounds that it was better known to Europeans at the time (1849a, p. vi), since his works were primarily aimed at British officers in Sindh. For details of Stack’s version of 𝚜𝚍-𝙳𝚎𝚟𝚊, see Section 7.3. Regardless of his script preferences, Stack’s grammar remains invaluable for its comparative handwritten chart of the various graph inventories in vogue at the time for writing Sindhi (1849a, pp. 3–8).
Along similar lines, Burton (1851, pp. 152–157) outlines what he feels are the relative advantages and disadvantages of the various candidate scripts for an official writing system for Sindhi — proto-standardised Khudawadi, Gurmukhi, Devanagari and Arabic. Burton rejects both Khudawadi and Gurmukhi on the grounds of them being known only to small sections of the population. He considers Devanagari a strong candidate based on its familiarity to Europeans in the colonial administration but, like Stack, notes that the script was unfamiliar to most Sindhis themselves. Furthermore, he claims that the existing Devanagari inventory would need to be suitably augmented to create a 𝚜𝚍-𝙳𝚎𝚟𝚊 system that is suitably transparent and as biunique as possible. Ultimately, Burton advocates using Persian-Arabic (𝚏𝚊-𝙰𝚛𝚊𝚋) as the inventorial foundation for an official Sindhi writing system, since this inventory had already been employed in some 𝚜𝚍-𝙰𝚛𝚊𝚋 works by that time.67 Burton does admit, though, that the 𝚏𝚊-𝙰𝚛𝚊𝚋 inventory had been “carelessly adapted to the language of Sindh, and by the confusion of points and the multitude of different sounds expressed by one letter appears difficult and discouraging” (1851, p. 155). That said, he asserts that the script would be familiar to most educated Muslims and Persian-educated Amils (§5.1.6). He also hopes that mass education would result in further standardisation of the writing system and elimination of its shortcomings.
Both Stack (1849a) and Burton (1851) tend to wax eloquent about their preferred scripts and gloss over their flaws, and focus instead on the purported drawbacks of the other scripts in the fray. For instance, Burton (1851) ignores the fact that the 𝚏𝚊-𝙰𝚛𝚊𝚋 inventory comprises distinct graphs for φ-consonants present in Persian and Arabic but absent in Sindhi. In fact, Burton seems to suggest that such graphs are necessary in any 𝚜𝚍-𝙰𝚛𝚊𝚋 system simply because Sindhi lexicon comprises a much greater number of Persian and Arabic loanwords than do other South Asian languages (p. 400). In doing so, he glosses over the fact that these loanwords have been assimilated into Sindhi’s phonology. Burton claims that the Landa inventories are unsuitable due to their lack of distinct graphs for φ-vowels, but underplays the fact that, in 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋, there exists a similar — albeit sociolinguistically conditioned — practice of leaving word-medial lax φ-vowels unwritten (§6.1). On the other hand, Stack (1849a) shuns both Arabic and Roman due to the alleged inventorial augmentation involved, while simultaneously defending similar enhancement in Devanagari and Landa. Also noteworthy is Stack’s use of Devanagari in his publications for Europeans, while simultaneously advocating a Landa-based writing system for educational and popular use by Sindhis. Burton, too, cites the familiarity of the Arabic script to educated Muslims and Amils in Sindh as an argument in its favour. However, it is unclear whether he advanced this argument out of genuine interest in Sindh’s people, or as a red herring to detract from his subjective preference of the Arabic script (Boivin, 2020, pp. 44–47). Overall, both Stack and Burton considered familiarity to Europeans a significant factor in selecting an official script for Sindhi.
A widespread sentiment articulated in the writings of colonial officials at the time, including Burton, Frere and Ellis, was the apparent reluctance of Muslim and Hindu Sindhis to read and write Sindhi in a script semiotically associated with the other religion (Aitken, 1907, p. 474). That is, Muslim Sindhis were expected to reject any Landa-based writing system for Sindhi, just as Hindu Sindhis, especially the trading community, would stay away from any proposed 𝚜𝚍-𝙰𝚛𝚊𝚋 system. On this issue, Frere wrote that:
[A]fter the most careful and dispassionate consideration, Mr. Ellis […] agreed that it was as hopeless to teach the Hindoos generally to read their own language in an Arabic character, as it would be to induce the Mahomedans to adopt generally a system of writing which they would consider as more than savouring of rank idolatry.
Frere’s and Ellis’ position sits at odds with the reality that Brahmi-derived Landa-based inventories had been in longstanding use among Muslim communities in Sindh — particularly the Ismailis and Memons — not just for record-keeping but also for liturgical writing. The officials’ view is also dissonant with the fact that the Hindu-Sikh community of Amils formed a significant section, if not the majority, of Persian-educated munshis in Sindh at the time. What comes across as particularly curious is that Ellis’ script committee included three Persian-literate Amil members, all of whom would go on to author several 𝚜𝚍-𝙰𝚛𝚊𝚋 textbooks, grammars and dictionaries in the following decades (Boivin, 2020). Yet, Frere and Ellis appeared reasonably convinced of their notions of the semiotic connotations of scripts and mutual religious prejudices prevailing in Sindh at the time. However, given that a majority of Sindh’s population was Muslim, Frere and Ellis were inclined towards officially adopting the Arabic script for Sindhi. Eventually, Ellis’ committee assented and recommended that 𝚜𝚍-𝙰𝚛𝚊𝚋 be officially adopted. Existing proto-standardised graphematic practices (§5.1.2) were supplemented with graphetic innovations to produce an augmented graph inventory. Finalised in 1853, the new inventory was officially adopted in 1857 as the basis for written Sindhi for administrative and, subsequently, educational purposes (Asani, 2003, p. 625; Khubchandani, 2007, p. 696).
Despite finalising the graph inventory of 𝚜𝚍-𝙰𝚛𝚊𝚋, Ellis’ committee did not focus on finer orthographic matters, such as diacritic placement, spellings of individual words and collation order (Lekhwani, 2011, p. 38). Several questions on these aspects of the 𝚜𝚍-𝙰𝚛𝚊𝚋 writing system remain debated even in present times (§6.3, §6.5).
5.2.2 Devanagari
In 1850, Stack published a translation of the Biblical Gospel of Matthew into 𝚜𝚍-𝙳𝚎𝚟𝚊 (Grierson, 1919, p. 13; Hooper, 1938, pp. 131–132), printed as a lithograph. Stack’s use of 𝚜𝚍-𝙳𝚎𝚟𝚊 was consistent with his position of advocating a Landa-based writing system for educational purposes but using Devanagari in his own works. Even after 𝚜𝚍-𝙰𝚛𝚊𝚋 was decreed official, debate on the issue persisted and supporters of alternative writing systems for Sindhi continued to make their case. Most prominent among supporters of Devanagari for Sindhi was the German Christian missionary Ernest Trumpp (§4.1). Trumpp (1857, p. 685) criticises 𝚜𝚍-𝙰𝚛𝚊𝚋 as being loaded “with a confusing heap of dots and other diacritical marks”. In his now-classic grammar of Sindhi, Trumpp (1872) devotes an entire chapter (pp. 1–30) to the development, characteristics and a critique of 𝚜𝚍-𝙰𝚛𝚊𝚋. This is likely the most detailed work on the subject from that period. In this work, Trumpp criticises the 1853 version of 𝚜𝚍-𝙰𝚛𝚊𝚋 (𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹), claiming that it was as unsystematic and indiscriminate in its application of dots as was the previous unstandardised practice (§5.1.2). Instead, he maintains that a writing system based on Devanagari, which he calls the “Sanskrit alphabet” (p. 1), would be the best suited for Sindhi.
Notably, a constant thread across several of Trumpp’s works is the supposed existence of religious prejudices between the Muslims and Hindus of Sindh, which echoes the sentiments expressed by Burton, Frere and Ellis. Trumpp associates scripts with religious groups to the extent that he labels the Arabic and Devanagari scripts ‘Hindu’ and ‘Muslim’, respectively (Trumpp, 1872). Like the British officials in the colonial administration, Trumpp believes that prevailing prejudices meant that one group would not learn the script of the other:
As the population of Sindh consists of Hindûs and Muhammadans, two distinct alphabets will be required for them. In respect to the Muhammadans, all are agreed that only the Arabic character will do for them […] The national alphabet for the Hindûs is the Sanscrit [Devanagari] character, […]
Yet, despite considering Devanagari to be linguistically better aligned with Sindhi phonology, Trumpp concedes that its adoption would be impractical in view of Sindh’s Muslim majority and their purported preference for a 𝚜𝚍-𝙰𝚛𝚊𝚋 system. However, since he was opposed to 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹, he advocates for the graph inventory and graph-phone correspondences of Urdu-Arabic (𝚞𝚛-𝙰𝚛𝚊𝚋) to be adopted for Sindhi, with minor modifications as needed (Trumpp, 1857; 1872). In Trumpp’s opinion, the graph inventory of 𝚞𝚛-𝙰𝚛𝚊𝚋 — which he refers to by the then-prevalent name ‘Hindustani’ — is comprehensive enough to allow for lexical items of Sanskritic as well as Perso-Arabic origin to be accurately transcribed. Consistent with his position, Trumpp’s (1872) grammar features Sindhi words in a modified 𝚞𝚛-𝙰𝚛𝚊𝚋 system as well as in a Devanagari-based system. For an analysis of Trumpp’s 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 inventories, see Sections 6.4 and 7.4, respectively.
While aligning somewhat with Ellis’ views, Trumpp’s views on needing separate writing systems based on religious affiliation comes across as dissonant with the fact that communities in Sindh read and wrote in a variety of writing systems, the isographs for which did not coincide with religious boundaries. More importantly, Trumpp’s views sit uneasily with the statistic that, in the late nineteenth century, less than ten per cent of Sindh’s population was literate (Aitken, 1907, p. 480; Boivin, 2020, p. 14). Against this background, it was probably unsurprising that Trumpp’s renditions of 𝚜𝚍-𝙰𝚛𝚊𝚋 or 𝚜𝚍-𝙳𝚎𝚟𝚊 faded away in the decades that followed. Thanks to government backing, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 went on to be adopted and used by educated Sindhis of all backgrounds. Use of 𝚜𝚍-𝙳𝚎𝚟𝚊 remained restricted to certain genres and contexts, chiefly liturgical and scholarly. These included Sindhi translations of Biblical texts, and the Sindhi volumes of George Grierson’s Linguistic Survey of India (1919).
As alluded to in Section 5.1.3, it was common to see British and European works describing the unstandardised Landa forms, and sometimes even Khojki and Khudawadi, as derivatives or corruptions of ‘Devanagari’ (Lepsius, 1863, p. 105). Such usage could be attributed to the British’s greater familiarity with the graphetically distinct variant of Devanagari and to the greater sociolinguistic prestige of this variant stemming from its use in writing Sanskrit. It is plausible that such indiscriminate usage of the term ‘Devanagari’ in British and European-authored works sowed the seeds of confusion in some quarters, particularly in the minds of colonial administrators who may not have been entirely familiar with Sindh’s grapholinguistic reality. At the other end of the analytical spectrum were those who opined that Devanagari in the modern sense was historically unused in Sindh (Covernton, 1906, p. 10). Regardless of whether Devanagari in the modern graphetic sense was used to write Sindhi in pre-British times, there remains no doubt on 𝚜𝚍-𝙳𝚎𝚟𝚊’s existence and use in the British era.
5.2.3 Khudawadi
Notwithstanding the adoption of 𝚜𝚍-𝙰𝚛𝚊𝚋 for official purposes in Sindh, the British administration retained concerns about its use in public education in the province. Consequently, Frere and Ellis sought to standardise a Landa-based graph inventory for Sindhi as the basis for a second writing system for the language, to be used in educating Hindu-Sikh children. This Landa-based writing system came to be known as Hindu Sindhi (Government of Bombay, 1857, p. 106). An initial version of this system was prepared in 1856, but was put on the back burner. In 1862, there was a brief attempt to introduce the so-called Hindu Sindhi writing system in a handful of schools, which failed due to the lack of printed material in it (Education Commission, Bombay, 1884, p. 25). Throughout the 1860s, the low uptake of government-sponsored education by the Vania trader community — the chief users of unstandardised Landa — prompted some officials to revisit the matter. Prominent among them was Narayan Jagannath Vaidya, one of the members of Ellis’ script committee who had since become Deputy Educational Inspector in Sindh. Vaidya was reportedly of the opinion that the low turnout of Vania children in government-run schools was due to instruction being provided in 𝚜𝚍-𝙰𝚛𝚊𝚋, which was of little use to them in their customary occupation of trade (Government of Bombay, 1864, pp. 85–86). According to Vaidya, providing instruction in a Sindhi-Landa system would act as an incentive for Vania children to such schools, given the widespread use and practical value of Landa in their community (Government of Bombay, 1865, p. 89). Still, other government officials remained sceptical. The British-appointed Commissioner in Sindh at the time, Samuel Mansfield, wrote:
Sind labours under great difficulties in the language introduced by Government for education. The only persons disposed to allow their children to learn it are the Government servants and those who wish to obtain Government employment [i.e., Amils]. The agricultural population [Sunni Muslims], if they educate their children at all, have them taught Persian only; and the trading community, Bunnia-Sindee, which is quite a distinct language [i.e., writing system] from that taught in the Government schools.
A similar sentiment was echoed by Vaidya’s immediate superior, acting Educational Inspector JG Moore. Despite having high regard for Vaidya’s abilities, Moore felt that introducing a Sindhi-Landa system in schools would not solve the problem at hand. According to him, Vania children had traditionally acquired a working knowledge of their community-specific Landa inventory from their elders. Consequently, there was no need for these children to attend government-run schools, rendering moot the question of writing system to be used in education (Government of Bombay, 1865, pp. 89–90). Yet, by 1869, support had re-emerged for introducing a Landa-based writing system for Sindhi for use in government schools. In February 1869, incumbent Commissioner in Sindh, William Merewether, issued a notification stating:
Government have decided upon introducing a uniform Bunya-Sindhi or Hindu-Sindhi alphabet, in the hope that: —
- (1.) By its use in our Schools, it may be the means of very largely increasing the attendance.
- (2.) By the publication of books in the new character, the education of the children of Native merchants and shopkeepers may be facilitated and knowledge largely diffused among that class.
- (3.) By the gradual introduction of the new character, the difficulty generally experienced by our Law Courts, in deciphering documents drawn up in the present Bunya-Sindhi character may be avoided.
Also announced was the formation of a “Vernacular Literature Committee in Sind”, whose mandate, among other things, would include “fix[ing] a well-digested and uniform system of orthography both for the Arabic-Sindhi and Hindu-Sindhi characters” (Government of Bombay, 1869, p. 214). In finalising the ‘Hindu Sindhi’ or Sindhi-Landa system, the Committee adopted the existing proto-standardised Khudawadi graph inventory as the basis. The inventory was then supplemented with bound vowel graphs or vowel ‘diacritics’, whose graphetic shape was inspired by corresponding graphs in the Gurmukhi script (Boivin, 2020, p. 47). One graph, |𑋙| [ɾ(ə)], was taken from the Shikarpuri style of Landa (Grierson, 1919, p. 18). This new system came to be known as “improved Hindu Sindhi” (Grierson, 1919, p. 18). Compared to the previous proto-standardised 𝚜𝚍-𝚂𝚒𝚗𝚍, the new Sindhi-Khudawadi system featured additional graphs in its inventory, as well as a revamped and regularised set of graph-phone correspondences. Accordingly, the writing system hitherto referred to as proto-standardised Sindhi-Khudawadi will be assigned the language subtag 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, while the so-called ‘improved Hindu-Sindhi’ will be denoted by the subtag 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 (§2.9).
The first public school providing instruction in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 was set up in Karachi later in 1869 (Hughes, 1876, p. 373).68 Textbooks in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 were authored by government officials, primarily Amil (Chapter 8). After initially being lithographed, books in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 were printed using movable type by 1874 (Government of Bombay, 1874, p. 262). Despite government support and funding, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 did not receive the public uptake that administrative officials expected. Although the initial couple of years after its introduction saw an increase in school attendance, there was “still a considerable want of confidence on the part of the Baniá class in the permanency of the New Character” (Government of Bombay, 1872, p. 442). By 1875, it was reported that school attendance by Vania children had begun to decline (Government of Bombay, 1875, p. 87), with many pupils — almost all boys — leaving midway to join their family occupation (Baillie, 1890, p. 161). In the meantime, with the demise of Narayan Jagannath Vaidya in 1873 (Baillie, 1890, p. 161), 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 had lost its driving force. In 1881, Dayaram Gidumal Shahani, a civil servant of Amil background, recommended ending government support for 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿. Reiterating the observation of past civil servants, Shahani noted that Vania children had little use for the graphematically transparent 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 in their community’s trading affairs, preferring instead the graphematically opaque but quick-to-write 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍. Shahani’s recommendation was approved by the Commissioner in Sindh, and government support for 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 was eventually withdrawn (Dow, 1976, p. 55). By the early twentieth century, only a handful of schools continued to provide instruction in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, typically alongside 𝚜𝚍-𝙰𝚛𝚊𝚋 (Aitken, 1907, p. 479). Meanwhile, proto-standardised 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 continued to remain popular among the Vania community for personal use, at least until Partition (Boivin, 2015; Falzon, 2004). Among printed works, the majority of twentieth-century works in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 comprise Sindhi translations of sections of the Bible (Figure 8.3).
In the scholarly literature, the British administration’s instituting of two distinct writing systems — and, consequently, educational systems — geared towards Muslim and Hindu-Sikh Sindhis is sometimes portrayed as deliberate, intending to drive a wedge between the two communities. For instance, Anand (1996, pp. 17–18) opines that the instituting of separate schools providing instruction in 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 was consistent with the colonial-era British policy of divide et impera — Latin for ‘divide and conquer’. Similarly, Hugh Dow, a British civil servant who served as Governor of Sindh from 1941 to 1946, felt that the introduction of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 was “sectarian propaganda masquerading in the garb of educational enthusiasm” (Dow, 1976, p. 55). Such arguments may well have a considerable element of truth in them. However, there may also be a more mundane explanation for the grapholinguistic experimentation witnessed in early British-era Sindh. It emerges that the primary actors behind a standardised writing system for Sindhi were primarily non-Sindhis — Stack, Burton, Frere, Ellis, Trumpp and Vaidya, not to mention the various Educational Inspectors and Commissioners of British background. Notwithstanding the benevolence or malintent behind their actions, these non-Sindhi officials and intellectuals may have simply misunderstood the implicit-but-consistent patterns of writing system adoption prevalent among sections of the Sindhi community. For the Sindhis themselves, their preference for a particular writing system was dictated not by graphematic perfection or religious ideology, but by user-oriented and use-oriented pragmatism. This may explain why Frere’s and Ellis’ impression that Hindu-Sikh Sindhis would not learn 𝚜𝚍-𝙰𝚛𝚊𝚋, and Vaidya’s assumption that the same community would be drawn to an education in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, were both proven false.
5.2.4 Gurmukhi, Khojki and Roman
Despite official support for 𝚜𝚍-𝙰𝚛𝚊𝚋, and temporarily for 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, the British era saw a slight increase in the use of Sindhi-Gurmukhi. In the 1850s, European missionaries translated select Christian scriptures into Sindhi, printed in 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙶𝚞𝚛𝚞 (Grierson, 1919, p. 13; Hooper, 1938, pp. 131–132). New and revised Bible translations in 𝚜𝚍-𝙶𝚞𝚛𝚞 continued to appear until the early twentieth century (§8.3). The choice of 𝚜𝚍-𝙶𝚞𝚛𝚞 suggests a target readership of Hindu-Sikh women in Sindh (§5.1.4). In 1890, Hyderabad-based social reformer Navalrai Advani launched a monthly magazine in 𝚜𝚍-𝙶𝚞𝚛𝚞 dealing with women’s issues was launched (Jotwani, 1992, p. 368; Schimmel, 1964, p. 214). Titled Sudhar Patrika ‘Journal of Reform’, the choice of writing system for the magazine was determined by the literary competence of its intended audience (Gidumal, 1903, p. 354; Jetley, 1987a, p. 88).69 Alongside 𝚜𝚍-𝙰𝚛𝚊𝚋 as the primary medium of instruction, a few girls’ schools in urban areas in Sindh also provided instruction in the Gurmukhi script. However, rates of female school attendance were low, and most women acquired proficiency in Gurmukhi at home from older female family members (Aitken, 1907, p. 481). In this regard, the transmission of Gurmukhi among Hindu-Sikh Sindhi women in the home domain represented a continuation of a pre-British tradition.
The British era also saw an uptick in Khojki-script publications, albeit not necessarily in the Sindhi language. Historically, the spoken language of the Nizari Ismaili community ranged from Siraiki to Kutchi on a continuum (Shackle & Moir, 1992, pp. 15, 43). By the early nineteenth century, the Nizari Ismaili community had spread from the Kutch region further into what is now Gujarat state in India. Consequently, multilingualism and multidialectalism became common, particularly in the Kathiawadi variety of Gujarati (Akhtar, 2016). Following the consolidation of British power in South Asia by the mid-1800s and the subsequent development of Bombay and Karachi as port cities, large sections of Kutchi and Kathiawadi-speaking Nizari Ismailis settled in these cities (Shackle & Moir, 1992, p. 11), particularly in Bombay (Asani, 2011, p. 105). The British-driven emergence of ‘standard’ Gujarati and Sindhi in spoken and written forms, and the increasing socioeconomic prestige of these languages, led to the Nizari Ismailis adopting these languages for formal and written purposes (Ivanow, 1931, p. 533 footnote), although they often retained Kutchi and Kathiawadi as their spoken community languages. Several Ismailis also emigrated to British colonies in the Middle East and East Africa (Akhtar, 2016), where they took their speech and writing practices.
The first books in Khojki were printed in Bombay in the late nineteenth century, initially using lithographic techniques and subsequently with movable type. Printing of these books was authorised by the spiritual leader of the Nizari Ismailis at the time, Aga Khan III. These books comprised recensions of the ginans as well as some novel content, albeit remaining within the theological domain (Shackle & Moir, 1992, p. 16). The first Khojki-script press, the privately-run Ghulam-i Husain Printing Press, was set up in the 1880s by one Aladin Ghulamhusen (Asani, 1987, p. 444). Subsequently, an ‘official’ press authorised by Aga Khan III was set up by Laljibhai Devraj, initially named the Khoja Sindhi Printing Press and, eventually, the Ismaili Printing Press (Asani, 1991, pp. 55–57). Besides pioneering Khojki printing using movable type, Devraj also attempted to develop and further standardise the Khojki graph inventory. While the Ghulam-i Husain Printing Press closed down not long after its inception, the Ismaili Printing Press continued publication until the 1930s (Asani, 1987, p. 444). Aside from the ginans, these presses produced some content in the Kutchi language in the Khojki script, which may be denoted by the language subtag 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓. By the 1910s, however, most non-ginanic content issued from these presses began to appear in the Gujarati language, albeit in the Khojki script. In graphematic terms, the publications displayed a shift in manifestation from 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 to 𝚐𝚞-𝙺𝚑𝚘𝚓. The 1930s saw yet another metamorphosis in the written manifestation of Ismaili literature, with the Khojki script being increasingly replaced by the Gujarati script (Asani, 1991, p. 56; Moir, Shackle, & Mitha, n.d., p. 1). This meant that publications were now almost entirely in 𝚐𝚞-𝙶𝚞𝚓𝚛, with the presence of the Sindhi language or the Khojki script in modern non-ginanic Ismaili literature reduced to a minimum.
Various factors have been cited for the gradual shift from 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 to 𝚐𝚞-𝙺𝚑𝚘𝚓 and finally to 𝚐𝚞-𝙶𝚞𝚓𝚛. The first shift from 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 to 𝚐𝚞-𝙺𝚑𝚘𝚓 in the early twentieth century can be understood as reflecting the increasing socioeconomic prestige and use of the Gujarati language for the Ismaili community outside Sindh, including in the East African diaspora. Increased cost in procuring and maintaining Khojki-script types may also have played a part (Asani, 1991, p. 56). The second shift from 𝚐𝚞-𝙺𝚑𝚘𝚓 to 𝚐𝚞-𝙶𝚞𝚓𝚛 was likely an outcome of increasing community literacy in the Gujarati language and script, and a simultaneous decline in Khojki-script proficiency (Akhtar, 2016, p. 89). Moreover, despite Devraj’s efforts, there remained several gaps in his proposed systems for 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 and 𝚐𝚞-𝙺𝚑𝚘𝚓, leading to a gradual shift towards the established and graphematically more predictable 𝚐𝚞-𝙶𝚞𝚓𝚛. Additionally, a transliteration system for depicting Arabic-language Quranic text in the Gujarati script (𝚊𝚛-𝙶𝚞𝚓𝚛) had been developed by the early twentieth century (Akhtar, 2016, pp. 88–89; Pandey, 2009), which provided further impetus to adopt the Gujarati script for Ismaili liturgical publications. Partition dealt a decisive blow to printing in Khojki, since the Ismaili community, like the Sindhi community overall, was now split among Pakistan, independent India and the diaspora. For more on the timeline of Khojki-script publishing, see Asani (1991; 1992; 2011), Bruce (2015), Pandey (2009), Shackle and Moir (1992) and Virani (2022).
The most comprehensive attempt at using Roman to transcribe Sindhi is that of Grierson (1919, pp. ix–x), albeit only as an auxiliary system. In his monumental eight-volume Linguistic Survey of India (LSI; 1903–1928), Grierson depicts South Asian languages in a Roman-script writing system based on one initially proposed by the Welsh scholar William Jones in the late eighteenth century (Jones W. , 1799). Jones’ system loosely follows the principle of “vowels as in Italian, consonants as in English”, which was a concept popular among English missionaries at the time (Gleason, 1996, p. 778). Compared to Jones’ system, though, Grierson’s system is graphematically more sophisticated and transparent. It incorporates established conventions of distinguishing lax and tense γ-vowels with a macron (e.g., |a| and |ā|), and dental and retroflex γ-consonants with an underdot (e.g., |d| and |ḍ|). Grierson’s system also includes Sindhi-specific innovations, such as representing the language’s characteristic reduced vowels by superscript graphs (e.g., |a| and |ᵃ|). What makes the LSI invaluable in the present context is the presence of texts in various spoken varieties of Sindhi, transcribed in several writing systems. These include 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, 𝚜𝚍-𝙻𝚊𝚝𝚗 and even Kutchi in the Gujarati script, or 𝚔𝚏𝚛-𝙶𝚞𝚓𝚛. The LSI does not feature any instances of 𝚜𝚍-𝙶𝚞𝚛𝚞 or 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓, which may be considered indicative of the decline or diminished status of those systems by the early twentieth century.
5.2.5 Braille
Although the presence of Sindhi in Gurmukhi and Khojki began to diminish by the early twentieth century, the language also began to appear in a new script — Braille. In 1922, Parmanand Mewaram (PM) Advani, an educationist and principal of a school for Blind students in Karachi, designed a Braille-based system for encoding Sindhi (Ajwani, 1939, p. 94; Hall, 2013, pp. 90–91; Shaikh, 2017, p. 19).70 Advani observed that Braille-based systems for other South Asian languages were also in use across schools for the Blind across South Asia, most of which were distinct and incompatible in terms of their graph-phone correspondences. He then began to advocate for a common Braille-based system that could accurately yet consistently encode all major South Asian languages for the benefit of Blind learners and readers. However, Advani himself was sighted, due to which his proposals received some pushback from members of the Blind community. In the 1940s, disability activist Lal Advani (1923–2005) designed an alternative Braille-based system capable of encoding all major South Asian languages, including Sindhi (Chander, 2005; Khandeker, 2018).71 Although unrelated to each other, the two Advanis shared a common background in being Amil Sindhis. Unlike PM Advani, however, Lal Advani was Blind.
Throughout the 1940s, the two Advanis’ proposals for a pan-Indian Braille-based writing system continued to be debated at the government level. The matter would be resolved only after Partition in 1947.
5.3 After 1947
From the 1920s, 𝚜𝚍-𝙰𝚛𝚊𝚋 emerged as the dominant writing system for Sindhi in the public sphere. While 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝙶𝚞𝚛𝚞 continued to be used for personal records and private correspondence, they gradually disappeared from the educational system and public eye. As a result, debates on Sindhi’s scripts seem to have lain low until after independence and the concurrent Partition of British India in 1947. Partition resulted in Sindh becoming a province of Pakistan and the emigration of most Hindu-Sikh Sindhis to India (§3.4). Today, in Sindh, 𝚜𝚍-𝙰𝚛𝚊𝚋 continues to be the unchallenged official writing system for the Sindhi language. While the Hyderabad-based Sindhi Language Authority (SLA) has brought out a few pedagogical publications in 𝚜𝚍-𝙳𝚎𝚟𝚊 (Hussain, 2011), the writing system is not used in Sindh in any official or educational capacity.
In independent India, the scars of Partition and its religious overtones prompted some Hindu-Sikh Sindhis to back Devanagari as the official script for Sindhi. The first calls to this effect were made shortly after Partition by a Bombay-based group called the Sindhi Sahitya Sabha ‘Sindhi Literary Assembly’ (Asani, 2003, p. 625; Daswani, 1979, p. 61; Cook M. A., 2016a), also referred to as the Sindhi Sahitya Sammelan ‘Sindhi Literary Conference’.72 In January 1949, the Secretary of the group, AG Mamtora, sent a resolution to the Indian Ministry of Education in New Delhi asking that government-funded primary schools start teaching Sindhi, but using Devanagari. The stated justification was “facilitating integration of the Sindhis who have migrated from Sindh” and “having a scientific script for the [Sindhi] language” (National Archives of India, 2018b, p. 65). Backing the Sabha’s position was the New Delhi-based Trust for Sindhi Women and Children, chaired by Sindhi politicians Jairamdas Daulatram and Choithram Gidwani (National Archives of India, 2018a, p. 92). On 25th and 26th August 1949, Gidwani presided over an All-India Sindhis (Displaced People) Convention in Bombay. The Convention endorsed the Sabha’s call for ensuring 𝚜𝚍-𝙳𝚎𝚟𝚊 instruction in government-funded primary schools. It also called on the state governments of Bombay (then comprising parts of present-day western Maharashtra and Gujarat) and Rajasthan to recognise Sindhi as a official language, given the large number of Sindhis who had settled in those states following Partition. On 10 October 1949, the Sindh Hindu Seva Samiti (also spelled Sewa and Samity) ‘Sindh Hindu Service Committee’, with Nanik Motwani as Secretary, wrote to the Ministry of Education requesting that the Convention’s resolutions be implemented forthwith (National Archives of India, 2018a, p. 57).73 Opposing the calls for introducing 𝚜𝚍-𝙳𝚎𝚟𝚊 in primary schools was a group of Sindhi litterateurs and school officials, who wrote to the Minstry of Education asking for continued support for 𝚜𝚍-𝙰𝚛𝚊𝚋 (National Archives of India, 2018b, p. 66).
On 18 November 1949, the Indian Ministry of Education wrote to various state governments and universities around the country asking for objections to 𝚜𝚍-𝙳𝚎𝚟𝚊 being taught in government-funded schools and universities (National Archives of India, 2018a, p. 47). Since the question of teaching Sindhi primarily concerned the governments of Bombay, Rajasthan and the now-defunct Ajmer state, there was no noteworthy objection to the introduction of 𝚜𝚍-𝙳𝚎𝚟𝚊 (National Archives of India, 2018a, pp. 49–64). Accordingly, on 9 March 1950, the Ministry of Education notified all state governments that 𝚜𝚍-𝙳𝚎𝚟𝚊 now had official approval, and asked them to implement the decision in government-run institutions in the state offering Sindhi (National Archives of India, 2018b, p. 71). Shortly thereafter, the state government of Bombay confirmed that 𝚜𝚍-𝙳𝚎𝚟𝚊 would be used in primary schools starting from 1 March 1951. Besides asking all Sindhi-language teachers in the state to familiarise themselves with 𝚜𝚍-𝙳𝚎𝚟𝚊, the government also invited authors and publishers to prepare suitable 𝚜𝚍-𝙳𝚎𝚟𝚊 textbooks (National Archives of India, 2018b, p. 73).
In response, on 16 November 1950, the Bombay-based Committee for Sindhi Language and Script, whose Secretary was the noted Sindhi litterateur Kirat Babani, wrote to the Prime Minister of India strongly opposing the introduction of 𝚜𝚍-𝙳𝚎𝚟𝚊 and appealing for 𝚜𝚍-𝙰𝚛𝚊𝚋 to be reinstated in government-funded educational institutions (National Archives of India, 2018b, pp. 82–85). According to Babani, the government’s decision would effectively cut off Sindhi children from existing literature in 𝚜𝚍-𝙰𝚛𝚊𝚋. Noting that transliterating this literature into 𝚜𝚍-𝙳𝚎𝚟𝚊 would involve enormous labour, time and expenditure, he asked if the central or state government was prepared to take up the responsibility of the task. Highlighting the opposition to 𝚜𝚍-𝙳𝚎𝚟𝚊 by certain Sindhi educationists, Babani also underscored what he felt were irregularities in the pro-𝚜𝚍-𝙳𝚎𝚟𝚊 resolution passed by the All-India Sindhis (Displaced People) Convention, including the lack of unanimity behind the resolution as well as appeals to emotion that 𝚜𝚍-𝙰𝚛𝚊𝚋 was ‘Muslim’. That said, Babani’s justification of 𝚜𝚍-𝙰𝚛𝚊𝚋 contianed the following:
In Sindhi [i.e., 𝚜𝚍-𝙰𝚛𝚊𝚋], certain words with same pronunciation but with some what [sic] different spelling have different meanings. They cannot be written differently in Devnagri Script. There will be confusion in their meaning.
(Babani, 16 November 1950, in National Archives of India, 2018b, p. 84)
In terms of factual validity or lack thereof, the arguments in favour of 𝚜𝚍-𝙰𝚛𝚊𝚋 had much in common with the Sindhi Sahitya Sabha’s portrayal of Devanagari as a “scientific script”. Regardless, the appeals to emotion in both sides’ arguments had an impact on the government. On 2 January 1951, in an internal note in response to Babani’s letter, Tara Chand, Assistant Secretary to the Government of India, wrote:
I am not at all sure that our decision [to exclusively support 𝚜𝚍-𝙳𝚎𝚟𝚊] is technically correct. The Article 29(1) of the Constitution distinctly provides that “any section of the citizens in the territory of India… shall have the right to conserve” its distinct language and script. If a Section of Sindhis insists upon its right to regard the Arabic script in which Sindhi language has been written for centuries as its distinctive script, it is doubtful whether Govt. can force them to abandon it in favour of Deva Nagari.
(Chand, 2 January 1951, in National Archives of India, 2018b, p. 7)
Tara Chand’s observation was accepted by the Indian Minister of Education, Abul Kalam Azad, who added that the Sindhis’ preferred script for their traditional language would emerge with time (National Archives of India, 2018b, p. 8). Consequently, on 29 January 1951, the Indian Ministry of Education issued a press note stating that the government would allow both 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 to be used in state-supported educational institutions, with parents able to choose their desired medium. However, the government added the caveat that a particular writing system would be implemented only if at least forty students in the school, or ten students in a class, demanded it (National Archives of India, 2018b, p. 80).
Unsurprisingly, the central government’s co-recognition of 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 was swiftly opposed from all sides. The pro-𝚜𝚍-𝙳𝚎𝚟𝚊 lobby, spearheaded by Mamtora, Motwani, Gidwani and colleagues, argued that the government’s backtracking on its previous resolution created confusion. It also reiterated the subjective argument on how 𝚜𝚍-𝙳𝚎𝚟𝚊 would “further the cause of our language and literature, taking into consideration the genesis and philology of our language and its relations with other sister languages of the Indo-Aryan group” (National Archives of India, 2018b, p. 119). In attempting to demonstrate a tradition of writing in 𝚜𝚍-𝙳𝚎𝚟𝚊, the faction noted that the first printed dictionary of Sindhi (Stack, 1849b) was in 𝚜𝚍-𝙳𝚎𝚟𝚊. However, it also claimed that Sami’s 𝚜𝚍-𝙶𝚞𝚛𝚞 works (§5.1.4) and traders’ commercial records in 𝚜𝚍-𝚂𝚒𝚗𝚍, amounted to ‘varieties’ of 𝚜𝚍-𝙳𝚎𝚟𝚊. Finally, it characterised 𝚜𝚍-𝙰𝚛𝚊𝚋 supporters as “only a very small group of dissidents, some of whom have their own vested interests” (National Archives of India, 2018b, p. 120). On the other side, the pro-𝚜𝚍-𝙰𝚛𝚊𝚋 faction, spearheaded by Babani, claimed that approving both 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 would divide Indian Sindhis (National Archives of India, 2018b, pp. 100–102). Common to both parties was the argument that approving both writing systems would require additional resources and expenditure. On 23 February 1951, in response to delays by the state government of Bombay in recognising 𝚜𝚍-𝙰𝚛𝚊𝚋 as co-official, the Committee for Sindhi Language and Script submitted a strongly-worded petition to the President of India (National Archives of India, 2018b, pp. 130–226). Containing 1017 signatures, the petition demanded that the recognition of 𝚜𝚍-𝙳𝚎𝚟𝚊 be “withdrawn” and that of 𝚜𝚍-𝙰𝚛𝚊𝚋 be “restored”, while also reiterating the call for recognising Sindhi as an official language (National Archives of India, 2018b, p. 130). The vast majority of the signatories’ names, occupations and addresses were written in Roman — effectively in 𝚜𝚍-𝙻𝚊𝚝𝚗 — likely to ensure readability by non-Sindhi central government officials. That said, a few entries were in 𝚜𝚍-𝙰𝚛𝚊𝚋 and even 𝚜𝚍-𝚂𝚒𝚗𝚍.
In general, though, once 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 were jointly recognised by the central government, an implicit truce ensued and the script issue took a backseat. Both factions now shifted their focus to practical issues, such as ensuring that state governments complied with the central government’s order, and getting the Sindhi language recognised in the Indian Constitution. On the latter issue, efforts were already underway. On 21 January 1951, the residents of Pimpri camp, Poona, sent a petition to the President of India asking for Sindhi to be recognised as an official language in Indian states with significant Sindhi populations, as well as at the national level (National Archives of India, 2018b, pp. 109–115). Compared to the near-contemporaneous petition by the Committee for Sindhi Language and Script, the Pimpri residents’ petition only contained around two hundred and fifty signatures. However, the signatures on the latter were graphematically much more diverse than those on the former, with comparable numbers in 𝚜𝚍-𝙻𝚊𝚝𝚗, 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝚂𝚒𝚗𝚍. Of the last category, most were in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, namely without γ-vowels. This offers some evidence that 𝚜𝚍-𝚂𝚒𝚗𝚍 was still in use in personal domains at the time of Partition. Notably, only four signatures were recognisably in 𝚜𝚍-𝙳𝚎𝚟𝚊. A selection of the signatures is shown in Figure 5.2.

Source: National Archives of India (2018b, p. 112)
In response to the petition, the Indian Ministry of Law replied that recognising Sindhi as a state language was up to individual state governments, while recognising Sindhi as an official language of India would require a constitutional amendment. Regarding the latter point, the Ministry noted that “this is hardly the time at which any proposal for an amendment of the Constitution can be made with any chance of success” (National Archives of India, 2018b, p. 22). Nevertheless, petitions for official recognition of Sindhi continued throughout the 1950s. These petitions were bolstered when state governments began gradually winding back special provisions made for Sindhi refugees, which included primary schools (National Archives of India, 2018b, pp. 306, 343). In the meantime, away from the heat of the public stage, bureaucratic discussions on matters of graphematic standardisation continued quietly. Over 1952 and 1953, suggestions were made on standardising the 𝚜𝚍-𝙳𝚎𝚟𝚊 graph inventory (National Archives of India, 2018b, pp. 362–363), which resulted in the now-ubiquitous 𝚜𝚍-𝙳𝚎𝚟𝚊 graphs |ॻ ॼ ॾ ॿ| for the φ-implosives [ɠ ʄ ɗ ɓ]. However, less attention was paid to the finer points of 𝚜𝚍-𝙳𝚎𝚟𝚊 spelling, the impacts of which are still felt to the present day (§7.5). The narrow focus on standardising 𝚜𝚍-𝙳𝚎𝚟𝚊’s graph inventory while sidelining matters of spelling was ironically reminiscent of the events surrounding the official adoption of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹, almost exactly a hundred years prior (§5.2.1).
After more than fifteen years of having two official scripts but no official language status, Sindhi was finally recognised in the Indian Constitution in 1967. Paradoxically, Sindhi’s recognition as an official language of India had the effect of rekindling the script debate. With its new status making it eligible for greater government funding and support, both 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 supporters now wanted a greater share of the pie for teaching and publication in their favoured writing system (Daswani, 1979, p. 66). This resulted in the two factions attempting to elbow out the other where possible, with arguments laced with ever-increasing verbal sophistry and appeals to emotion. The pro-𝚜𝚍-𝙳𝚎𝚟𝚊 lobby has continued to claim that their favoured script is linguistically more suitable to the Sindhi language, and that there exists a historical and cultural link of the script with the language. In the process, script and religious identity are often conflated, and the Arabic script is identified with Islam. Along these lines, it is claimed that Devanagari was “buried underground by Muslim conquerors” (Asani, 2003, p. 625). It is also claimed that the Devanagari script is ubiquitous in India due to its use for writing Hindi. On this basis, it is argued that the adoption of 𝚜𝚍-𝙳𝚎𝚟𝚊 is in the interest of the Sindhi language’s long-term survival in India. On the other hand, the pro-𝚜𝚍-𝙰𝚛𝚊𝚋 lobby asserts that using their preferred script would continue to ensure the readability of past Sindhi literature, maintain a link between Indian and Pakistani Sindhis, and confer a distinct visual identity on the written form of their language. Using 𝚜𝚍-𝙳𝚎𝚟𝚊, they argue, would re-emphasise the hegemony of the Hindi language and Devanagari script over Indian Sindhis, especially over the younger generation. In the process, the pro-𝚜𝚍-𝙰𝚛𝚊𝚋 lobby paints the pro-𝚜𝚍-𝙳𝚎𝚟𝚊 lobby as sectarian, due to the latter’s use of anti-Islamic rhetoric in their propaganda.
The infighting and indecision on the Sindhi script issue in post-Partition India has been criticised by various authors, from different perspectives. Daswani (1979, p. 66) states that the script limbo has made the Sindhi community disillusioned with the issue, causing a large section of the younger generation to have no opinion in the matter. Anand (1996, p. 128) disapproves of the “compromise” of having two official scripts for Sindhi, adding that it exacerbates the precarious situation of a language whose speakers are geographically dispersed. On the other hand, scholars like Khubchandani have taken a broader view of the situation, and object to the very preoccupation with standardisation and codification of language and script. Khubchandani opines that the overall endeavour at “bringing order to chaotic diversity” (1984, p. 172) ultimately stems from a Western monolingual and homogenising mindset.
In the meantime, the Indian government has resolutely kept out of the Sindhi script debate, leaving the final decision to the community itself. Consequently, the language may be taught as 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊 or both in different Indian states. Government institutions, including the Central Institute of Indian Languages (CIIL), usually bring out their Sindhi-language publications in both 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊. According to Daswani, this leads to “duplication and a waste of public funds” (1979, p. 67). Although the intensity of the script debate is no longer as intense as it was in the immediate aftermath of Partition, there remains a degree of one-upmanship between the two factions. For instance, the Sahitya Akademi, or the National Academy of Letters, only considers works in 𝚜𝚍-𝙰𝚛𝚊𝚋 to be eligible for its Sindhi literature awards. This has been attributed to 𝚜𝚍-𝙰𝚛𝚊𝚋 supporters holding influential positions in the Academy (Hardwani, personal communication, November 8, 2014). The indecision on the script issue also leads to occasional symbolic setbacks, such as Sindhi-language text being left out from Indian rupee currency notes (Young, 2009, pp. 165–166). Figure 5.3 shows the language panel from the reverse of an Indian ten-rupee note (Mahatma Gandhi Series, 1996–2016), which is conspicuously devoid of Sindhi-language text in any script.

Source: Reserve Bank of India (https://www.rbi.org.in/scripts/ic_languagepanel.aspx). Copyright by Reserve Bank of India.
Other writing systems such as 𝚜𝚍-𝚂𝚒𝚗𝚍, 𝚜𝚍-𝙶𝚞𝚛𝚞 and 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 have all but disappeared from everyday usage, both in Pakistan and India. Consequently, persons literate in these writing systems tend to be older. Grapholinguistic remnants in these systems dating from the pre-Partition era or early post-Partition years may still survive. In Sindh, there remain a few instances of 𝚜𝚍-𝚂𝚒𝚗𝚍 on pre-Partition public signage (Boivin, 2015). Similarly, religious publications in 𝚜𝚍-𝙶𝚞𝚛𝚞 targeted at Hindu-Sikh women may still exist, although most such literature would have likely been reprinted in 𝚜𝚍-𝙳𝚎𝚟𝚊 (Gidwani C. P., 2012). Notwithstanding the decline of 𝚜𝚍-𝙶𝚞𝚛𝚞, the use of Gurmukhi for the Punjabi language has flourished in the post-Partition era, with Punjabi-Gurmukhi (𝚙𝚊-𝙶𝚞𝚛𝚞) having been granted official status in India’s Punjab state. Gurmukhi’s cousin Khojki has not been as fortunate, and its adoption to write Gujarati in the form of 𝚐𝚞-𝙺𝚑𝚘𝚓 did not last long (§5.2.4). Unlike the rest of the Sindhi community, which was split between its Pakistani and Indian sections largely along religious lines, the Ismaili section of the community found itself in both countries (Shackle & Moir, 1992, p. 10). Ismailis in Sindh were now separated from their kin in Kutch, Gujarat and Bombay by the Indo-Pak international border. However, since Ismailis in Sindh were concentrated in Karachi, the Khojki script continued to be taught for a while in Karachi-based Ismaili religious schools in Pakistan. As a result, a small number of publications in 𝚐𝚞-𝙺𝚑𝚘𝚓 and 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 continued to appear (Asani, 1991, p. 57; Valliani, 2008, pp. 94–95). This lasted until 1975, when Ismaili schools in Pakistan stopped teaching Khojki citing student burden and the apparent disuse of Khojki in the global Ismaili diaspora (Tajddin Sadik Ali, 1989; Valliani, 2008, p. 95). Since then, Khojki-script publications have been largely restricted to ginanic works (Pandey, 2011b, p. 2) and primers prepared by lay and academic community members (Moir, Shackle, & Mitha, n.d.; Tajddin Sadik Ali, 1989). Despite the dwindling of Khojki in the twentieth century, the Ismaili community, especially those outside of Sindh, still refer to the script as ‘Sindhi’ (Asani, 1991, pp. 56–57).
Notwithstanding graphematically unstandardised practices and sociolinguistically subordinate status, 𝚜𝚍-𝙻𝚊𝚝𝚗 has emerged as the writing system most widely known by literate Sindhi speakers worldwide today. To a large extent, implicit community familiarity with 𝚜𝚍-𝙻𝚊𝚝𝚗 has been driven by the ubiquity of the Roman script and comparatively limited support for the Arabic and Devanagari scripts on computers and mobile devices worldwide. However, transcribing a language in an ad-hoc Roman-script-based writing system on electronic devices is commonly attested worldwide, regardless of language. As such, the use of ad-hoc 𝚜𝚍-𝙻𝚊𝚝𝚗 is sociolinguistically unremarkable, although it remains graphematically interesting. That said, there exists some community support exists for using 𝚜𝚍-𝙻𝚊𝚝𝚗 as a formal auxiliary system, to circumvent technological hindrances to writing Sindhi on electronic devices, as well as to create a writing system easily readable by Sindhis across the world. The most organised and prominent community group advocating for 𝚜𝚍-𝙻𝚊𝚝𝚗 as a sociolinguistically auxiliary writing system for Sindhi is the Romanized Sindhi group (RomanizedSindhi.org, 2010a). With a membership that spans several countries worldwide, the Romanized Sindhi group conducts regular workshops and outreach events worldwide to popularise its 𝚜𝚍-𝙻𝚊𝚝𝚗 orthography. At the time of writing this book, the Romanized Sindhi 𝚜𝚍-𝙻𝚊𝚝𝚗 orthography appeared on certain sections of the SLA’s website as a transliteration of 𝚜𝚍-𝙰𝚛𝚊𝚋 (Sindhi Language Authority, 2017a). The orthography does not appear to have been officially endorsed by the SLA, though. For a closer look at the Romanized Sindhi 𝚜𝚍-𝙻𝚊𝚝𝚗 orthography, see Section 12.3.
Regarding the issue of a Braille-based writing system for South Asian languages, the disagreements between the two Advanis’ systems persisted even after Partition. In the meantime, calls began to grow from Blind advocates from other countries to ensure harmony among Braille-based writing systems worldwide. Against this background, the government of newly independent India handed the issue over to UNESCO in 1949, requesting them to pursue the creation of a “world Braille” (Ministry of Education, India, 1952; Kabir, 1949; Mackenzie, 1954, pp. 9–10). UNESCO accepted the Indian government’s request, and initiated a series of conferences of international Braille experts, including the two Advanis. By 1954, a Braille-based system for South Asian languages that was largely harmonious with homoscriptal systems such as English-Braille and French-Braille was finalised, and officially adopted by the governments of independent India and Ceylon (today Sri Lanka) (Ministry of Education, India, 1952, p. 11; Mackenzie, 1954, p. 148). Pakistan devised a distinct Braille-based writing system, albeit only for Urdu (Mackenzie, 1954, pp. 37–38, 131–134). Since then, standardised Braille-based systems have been widely adopted and used in India and Pakistan, with the exception of Sindhi-Braille (UNESCO, 2013). The languishing of 𝚜𝚍-𝙱𝚛𝚊𝚒 appears particularly stark when one considers the pivotal role that Sindhis played in standardising Braille-based systems — not just in South Asia, but worldwide. For a detailed history of the events leading to the standardisation of World Braille, see Section 11.1.
5.4 Summary
The diachronic overview of Sindhi-language graphematics and graphosociolinguistics reveals rich and diverse traditions of writing the language, conditioned by the people who wrote it and the purposes for which they did. The writing systems of Sindhi, therefore, carry immense potential to test and advance graphematic and graphosociolinguistic theories as they currently exist. Each of the next seven chapters is exclusively devoted to describing and evaluating script-specific writing systems for Sindhi, including subvariants and orthographies. These are Arabic (𝚜𝚍-𝙰𝚛𝚊𝚋), Devanagari (𝚜𝚍-𝙳𝚎𝚟𝚊), Khudawadi (𝚜𝚍-𝚂𝚒𝚗𝚍), Gurmukhi (𝚜𝚍-𝙶𝚞𝚛𝚞), Khojki (𝚜𝚍-𝙺𝚑𝚘𝚓 and 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓), Braille (𝚜𝚍-𝙱𝚛𝚊𝚒) and Roman (𝚜𝚍-𝙻𝚊𝚝𝚗) (ScriptSource, 2022b). Complementing the graphematic analysis, and concluding Part Two of the book, is a sociolinguistic investigation into contemporary community attitudes towards 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗 among Indian Sindhis.
6 Arabic
If one accepts that Sindhi has been written in the Arabic script for almost a millennium now (§5.1), this would make Sindhi in the Arabic script (𝚜𝚍-𝙰𝚛𝚊𝚋) one of the oldest attested writing systems for the language. Over the centuries, 𝚜𝚍-𝙰𝚛𝚊𝚋 has been through a fascinating journey, undergoing several graphematic twists and turns and manifesting in various avatars. Today, 𝚜𝚍-𝙰𝚛𝚊𝚋 is recognised as the official writing system for the Sindhi language in Pakistan, and a co-official script, along with Devanagari, in India (Daswani, 1979).
6.1 Graphematic foundations
Broadly speaking, all variants of the 𝚜𝚍-𝙰𝚛𝚊𝚋 writing system are based on the Persian-Arabic writing system (𝚏𝚊-𝙰𝚛𝚊𝚋), itself derived from the Arabic-Arabic writing system (𝚊𝚛-𝙰𝚛𝚊𝚋). Consequently, Sindhi is often described in the grapholinguistic literature as being written in Perso-Arabic (Iyengar, 2018; Khubchandani, 2007, p. 696). Probably the most salient feature of 𝚜𝚍-𝙰𝚛𝚊𝚋 — indeed, of most Arabic-script-based writing systems worldwide — is dextrosinistrality, in that the general direction of writing is right-to-left.74 A notable exception to this rule is that of numerals (or digits), which are written left to right. Accordingly, and assuming that numerals fall under the category of logograms (§2.8), 𝚜𝚍-𝙰𝚛𝚊𝚋 might be more precisely described as dextrosinistral when it comes to phonograms. Another salient graphematic feature of 𝚜𝚍-𝙰𝚛𝚊𝚋, again common to with most Arabic-based-systems worldwide, is inherent graphetic cursiveness. That is, most — but not all — graphs within a written word are joined to the next one. Such cursiveness causes graphs to manifest as distinct allographs or rasms (§2.7), depending on their position within a written word. In the context of Arabic-script writing, rasms that are considered allographs of each other are called POSITIONAL VARIANTS (Bauer, 1996). Table 6.1 shows the principal rasms in the Arabic-script graph inventory, grouped according to their complementary positional variants. Rasms in rows marked in grey are the calligraphic forms commonly used in 𝚜𝚍-𝙰𝚛𝚊𝚋, although considered allographs of the rasms in the row immediately above.
| Isolated | Initial | Medial | Final |
|---|---|---|---|
| ا | ا | ـا | ـا |
| ٮ | ٮـ | ـٮـ | ـٮ |
| ح | حـ | ـحـ | ـح |
| د | د | ـد | ـد |
| ر | ر | ـر | ـر |
| ر | ر | ر | ر |
| س | سـ | ـسـ | ـس |
| ص | صـ | ـصـ | ـص |
| ط | طـ | ـطـ | ـط |
| ع | عـ | ـعـ | ـع |
| ڡ | ڡـ | ـڡـ | ـڡ |
| ٯ | ٯـ | ـٯـ | ـٯ |
| ک | کـ | ـکـ | ـک |
| ڪ | ڪـ | ـڪـ | ـڪ |
| ك | كـ | ـكـ | ـك |
| ل | لـ | ـلـ | ـل |
| م | مـ | ـمـ | ـم |
| م | مـ | ـمـ | ـم |
| ں | ںـ | ـںـ | ـں |
| و | و | ـو | ـو |
| ھ | هـ | ـهـ | ـه |
| ہ | ہـ | ـہـ | ـہ |
| ى | ىـ | ىـ | ى |
| ے | ے | ـے | ـے |
| ء | ء | ء | ء |
It emerges from Table 6.1 that a particular rasm may act as the so-called Initial or Medial positional variant of more than one Isolated variant. For example, the Isolated variants |ٮ ں ى| are graphetically distinct from each other, but their Initial and Medial variants are identical — |ٮـ| and |ـٮـ|, respectively. To distinguish graphetically identical rasms, dots called nuqtas are often added to rasms.75 The number and position of nuqtas depends on the graph nventory in question. Nuqtas are considered intrinsic to the graph, making them graphosubsegmental in nature (Meletis, 2020). The graphosubsegmental nature of nuqtas is seen in Table 6.2, which contains a selection of phonograms and phonogram sequences from the 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 graph inventories. The table is designed as a matrix, with graphs representing consonants (henceforth γ-consonants) along the vertical axis and graphs representing vowels (henceforth γ-vowels) along the horizontal axis. The intersection of γ-consonants and γ-vowels contains the graph representing the corresponding phonological [CV] sequence.
[table]
Table 6.2 reveals that, in the 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 inventories, γ-consonants occupy their own graphosegmental space. Also occupying their own graphosegmental space are |ا ﺋ|, which are used as graphetic bases for γ-vowels in certain positions. While |ا| is a rasm, |ﺋ| is itself a complex graph composed of the rasm |ىـ| and a diminutive form of |ء|. In contrast, the γ-vowels |◌َ ◌ِ ◌ُ|, as well as |◌ْ|, are graphosubsegmental in that they only occur along with a base, be it a γ-consonant or one of |ا ﺋ|. Consequently, in the literature, γ-consonants in 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 are often described as “basic letters”, while γ-vowels, especially |◌َ ◌ِ ◌ُ|, are termed “diacritics” (Bauer, 1996). In terms of phonosegmental representation, a φ-[CV] sequence is shown by a γ-consonant with the γ-vowel written above, below or to the right. A φ-[C] by itself, without a φ-vowel following, is shown by a γ-consonant with the graph |◌ْ| or its allographs |◌ۡ| or |◌ٛ| above it. Outside of a φ-[CV] sequence, a φ-[V] by itself is shown by the corresponding γ-vowel written on the rasm |ا| when word-initial, and on the graph |ﺋ| when word-medial. For this reason, |ا ﺋ| are often termed “vowel holders” (Iyengar, 2018) or “vowel carriers” (Gnanadesikan, 2017a). Additional subsegmental graphs or ‘diacritics’ include the morphologically-salient |◌ً ◌ٍ ◌ٌ| to indicate the Arabic adverbial suffixes [an ɪn ʊn], as well as |◌ّ|, written over a γ-consonant to indicate gemination of the corresponding φ-consonant. The Sindhi and English names of the vowel carriers and subsegmental graphs described so far are listed in (6). Where multiple English names exist, the ones preferred in this book are shown in emphasised type.
In terms of orthographic and sociolinguistic convention, most subsegmental graphs are omitted from 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 texts, and included only when the author considers it important to accurately reflect the intended pronunciation in written form. Consequently, subsegmental graphs are typically included only in certain text genres, such as children’s books or religious publications (Bauer, 1996, p. 562). At the same time, graphs from the 𝚊𝚛-𝙰𝚛𝚊𝚋 inventory whose phonological values have become identical in 𝚏𝚊-𝙰𝚛𝚊𝚋, such as |ث س ص| and |ذ ز ض ظ| (see Table 6.2), are retained unchanged in the spellings of words. As a result, the 𝚏𝚊-𝙰𝚛𝚊𝚋 system features a many-to-one mapping between graphs and phones. Additionally, 𝚏𝚊-𝙰𝚛𝚊𝚋 contains the graphs |پ چ ژ گ| for the phonemes /p t͡ʃ ʒ ɡ/, which are present in the Persian language but not in Arabic. Other modifications in 𝚏𝚊-𝙰𝚛𝚊𝚋 include the substitution of |ك ي| with the allographs |ک ی| to denote /k j/, and conventionally eliminating the use of sukun in the vowel graphs |◌ِی ◌ُو ◌َي ◌َو| /i u ej ow/ (Kaye, 1996). These 𝚏𝚊-𝙰𝚛𝚊𝚋-specific conventions are illustrated in Table 6.2 in the paradigms for |پ چ ژ ک گ ی|.
Numerals in the Arabic-script graph inventory and their allographs are shown in (7). Individual Arabic-based writing systems may prefer certain allographs (ScriptSource, 2022b; SIL International, 2022), although ‘mixing and matching’ of allographs remains common (Allana, 1993 [1964], p. 8).
Besides numerals, potential logographs in the Arabic-script graph inventory include the written forms of benedictions, the most prominent being |اللّٰه| ‘Allah’ and its subtly varying allograph |اللّٰہ|. Commonly characterised as a ‘ligature’ (§2.7), the graph |اللّٰه| tends to remain constant across Arabic-script-based writing systems, irrespective of the system’s specific graphematic properties.76
The Arabic-script-based systems used for Sindhi adhere to the principles of dextrosinistrality and inherent cursiveness. However, they vary in terms of the actual graphs employed, their graphetic manifestations and the spellings of individual words. Based on common patterns of use, major subvariants of 𝚜𝚍-𝙰𝚛𝚊𝚋 may be identified. In the sections that follow, each such 𝚜𝚍-𝙰𝚛𝚊𝚋 variant will be assigned and referred to by a unique — albeit unofficial — IETF-style language subtag (§2.9). These derivative 𝚜𝚍-𝙰𝚛𝚊𝚋 variants are individually described in the sections that follow.
6.2 Early use and Abul Hasan’s norms
Although 𝚜𝚍-𝙰𝚛𝚊𝚋 is supposed to have first emerged a thousand years ago, idiosyncratic variation in graphematic conventions persisted for several centuries thereafter. As mentioned in Section 5.1, the earliest significant attempt at standardising 𝚜𝚍-𝙰𝚛𝚊𝚋 writing practices is that of Abul Hasan (d. 1711), a theologian hailing from the town of Thatta in southern Sindh. In the year 1700, Abul Hasan wrote a religious treatise in Sindhi rhyming verse, albeit with the Arabic-language title Muqaddimat as-Salat ‘Introduction to prayer’.77 Written in a modified version of the Arabic script to account for Sindhi-specific φ-consonants (Schimmel, 1963, p. 229), Abul Hasan’s augmented graph inventory and graphematic practices exerted a significant influence on subsequent 𝚜𝚍-𝙰𝚛𝚊𝚋 Use. Hence, in addition to being considered “decisive” in the history of Sindhi literature (Schimmel, 1974, p. 18), Abul Hasan’s treatise also represents a foundational work in the history of 𝚜𝚍-𝙰𝚛𝚊𝚋 writing. His quasi-standardised graph inventory and graphematic practices, often referred to as “Abul Hasan Sindhi” (Allana, 1993 [1964]; Lekhwani, 2011, p. 28 footnote), remained in vogue until the British proclaimed a new Arabic-script-based system in 1853 (§6.3). Accordingly, Abul Hasan Sindhi will be assigned the language subtag 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍.
In terms of content, most works composed in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 were religious or didactic in nature (Rahman, 1999; Schimmel, 1963; 1974). Handwritten specimens of several such works have been compiled and presented in Baloch (1993), accompanied by a painstaking transliteration into present-day 𝚜𝚍-𝙰𝚛𝚊𝚋 spelling (§6.5). The lack of suitable movable types and the high cost of lithography restricted the number of books printed in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍. A section of the Bible, the Gospel of Matthew, was translated into Sindhi in 1825 at Serampore (in present-day West Bengal, India) in the “Arabic character” (Nida, 1972, p. 393). However, not much is known about its publication or of any extant copies (Grierson, 1919, p. 13; Hooper, 1938, p. 131). What the Sindhi Language Authority considers the “first book printed in the Sindhi language” (Hauze, 2016b) is a lithographed publication in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 titled Hukayut Oosalaheen or stories of good men written in Sindee (Wulle Mahomed & Hafiz Sedeek, 1851).78 An extract from the title page of this book is shown in Figure 6.1.

In the preface to the book, EP Arthur, Lieutenant of Police in Sindh, describes the work thus:
The Hukayut Oosalaheen consists of 20 Chapters in each of which some religious or moral duty is enforced & illustrates by a number of tales and allegories. It was translated from the Arabic language into Sindee by Wullee Mahomed at the Command of Hafiz Sedeek. The date of the translation is not known.
(Arthur, in Wulle Mahomed & Hafiz Sedeek, 1851, Preface, para. 1)
Arthur goes on to state that the colonial government of Sindh commissioned the work to be lithographed from a handwritten copy for the benefit of “those who are studying Sindee for more practical purposes”, namely for government officials needing to learn Sindhi for administrative purposes (§5.2.1). Regarding spelling and related graphematic practices, Arthur writes:
[I]n a language which has been so long neglected & of which so few even now pretend to know the correct Orthography and rules of Grammar many mistakes beyond those incidental to even the most careful transcription, are likely to meet the eye of the critical reader.
(Arthur, in Wulle Mahomed & Hafiz Sedeek, 1851, Preface, para. 3)
Arthur’s quote above reiterates the need to interpret 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 as a loose collection of quasi-standardised practices rather than as a full-fledged orthography in the modern sense. Table 6.3 lists the key graph variants used in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍, along with their usual linguistic values.
Sources: Stack (1849b, pp. 3–8) and Trumpp (1872, pp. 534–535)79
| ـَ | آ اٰ ـَا | ـِ | ـِيۡ | ـُ | ـُوۡ |
| ə | a | ɪ | i | ʊ | u o |
| ـٖيۡ | ـَيۡ | ـَوۡ | ـٍ | ـٌ | ـ﮼ |
| e | ɛ | ɔ | ɪ̃ ĩ | ʊ̃ ũ õ | ẽ ɛ̃ |
| ڪۡ کۡ | نۡڪۡ نۡکۡ | چۡ | ڇۡ | جۡ | ڃۡ | ڄۡ ﺟﻬۡ جہۡ | نڃۡ نڃۡ |
| k kʰ ɡ ɠ ɡʱ |
ŋ | t͡ɕ | t͡ɕʰ | d͡ʑ | ʄ | d͡ʑʱ | ɲ |
| ٺۡ | ٽۡ | ڏۡ | ڊۡ | تۡ | ٿۡ | دۡ | ڌۡ | نۡ |
| ʈ ʈɾ | ʈʰ | ɗ | ɖ ɖɾ ɖʱ | t̪ | t̪ʰ | d̪ | d̪ʱ | n (n̪) |
| پۡ | ف࣫ فہۡ ڤۡ | بۡ | ٻۡ | ڀۡ | مۡ مۡ |
| p | pʰ | b | ɓ | bʱ | m |
| يۡ | رۡ رۡ | لۡ | وۡ | شۡ | سۡ | هۡ | ﮧ |
| j | ɾ ɽ | l | ʋ | ɕ | s | ɦ | Ø |
Based on Allana’s (1993 [1964]) description, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 practices may be categorised into graphematic revitalisation, recycling and invention. graphematic revitalisation entailed more frequent use of existing graphematic devices such as the γ-vowel markers |◌َ ◌ِ ◌ُ| to indicate the Sindhi φ-vowels [ə ɪ ʊ], respectively (see (6) and Table 6.2). A φ-consonant with no φ-vowel after it was overtly denoted in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 with the jazm |◌ۡ| or |◌ٛ|, or occasionally by the allographic sukun |◌ْ| (see (6)). As described in Section 6.1, these subsegmental graphs are not frequently used in 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋. Hence, the conscious use of these graphs in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 likely reflected writers’ implicit awareness of Sindhi’s vowel-heavy phonology and the resultant lexical and grammatical significance of φ-vowels in the language (§4.3.2, §4.4).
Graphematic recycling involved the deployment of graphs available in 𝚊𝚛-𝙰𝚛𝚊𝚋 but with different linguistic values assigned to them. For instance, the 𝚊𝚛-𝙰𝚛𝚊𝚋 subsegmental graphs |◌ً ◌ٍ ◌ٌ| (see (6)) were repurposed in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 to denote the Sindhi nasalised φ-vowels [ĩ ũ], respectively, in word-final position (Allana, 1993 [1964], pp. 92, 115). Less frequently, |◌ً| was used to denote word-final [ə̃], and the compound graph |◌اً| for final [ã] (Grierson, 1919, p. 21). The subsegmental graph |◌ٖ| occasionally used in Quranic texts was recycled in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 to denote the Sindhi φ-vowel [e]. Most often, it manifested as the compound graph |◌ٖيۡ|. Nasalised [ẽ], particularly in word-final position, was written |◌﮼|. Curiously, no distinct graph was allocated for the φ-vowels [o] and [õ]. As seen in Table 6.3, the Sindhi φ-vowels [u o] were written identically, with the graph |◌ـُوۡ|, while their nasalised counterparts [ũ õ] were also written homographically, using |◌ٌ|. The Hukayut Oosalaheen (Wulle Mahomed & Hafiz Sedeek, 1851) features several instances of tanvin being used productively in this manner, of which frequently occurring ones are shown in (8):
Of the spellings shown in (8), |۽| and |۾| persist in present-day 𝚜𝚍-𝙰𝚛𝚊𝚋 as logograms. On occasion, |۽| is equated with the Roman-script logogram |&|, as seen in Unicode’s description of |۽| as U+06FD ARABIC SIGN SINDHI AMPERSAND (Unicode, 2024a). Notwithstanding their present-day use as logograms, |۽| and |۾| qualify as complex phonograms in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍, given the productive use of |◌ٍ ◌ٌ| in that system. At the same time, the use of |◌ً ◌ٍ ◌ٌ| in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 to denote φ-vowel nasalisation was not exclusive. Often, 𝚊𝚛-𝙰𝚛𝚊𝚋 loanwords with |◌ٍ ◌ٌ| denoting [ɪn ʊn] were incorporated unmodified into 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 texts (Allana, 1993 [1964], pp. 92, 115). This put the onus on the reader to glean the phonological value of |◌ٍ ◌ٌ| from the context.
Graphematic innovation in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 entailed the development of new, distinct graphs to denote Sindhi-specific φ-consonants, especially aspirate and retroflex stops. As mentioned in Section 5.1, such graphs were typically formed by adding subsegmental nuqtas to existing 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 rasms and graphs, based on the 𝚏𝚊-𝙰𝚛𝚊𝚋 graphematic precedent of adding nuqtas to |ب ج ز| [b d͡ʒ z] to create |پ چ ژ| [p t͡ʃ ʒ]. New graphs in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 were also created by rearranging nuqtas on existing graphs. For instance, 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 |ت| [t] was adopted in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 to denote [t̪], after which the nuqtas were rearranged to create |ٺ| to denote Sindhi-specific [ʈ].80 The creation of unique graphs for aspirate and retroflex φ-consonants in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 by adding or rearranging nuqtas caught the attention of nineteenth-century European scholars, albeit not always in a positive manner. In his Essay on the Sindian Alphabets (1857), Trumpp dismisses such innovation as “load[ing] the Arabic alphabet with a confusing heap of dots and other diacritical marks” (p. 685). However, in his (1872) grammar, Trumpp describes the practice of creating new graphs by adding nuqtas to existing ones in a more measured and insightful manner:
The Sindhis had in this undertaking apparently the Sanskrit alphabet before their eyes, where the aspirates are written and treated as one sound. Accordingly they tried to express the aspiration of a letter by additional dots, which overloaded the few Arabic bases with diacritical signs. […] This attempt to adapt the Arabic characters to the sounds of a Prakrit language is very interesting, […]
Despite these attempts at proto-standardisation, idiosyncratic practices persisted in the use of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍. Apart from decrying the addition of nuqtas as indiscriminate and unmethodical, Trumpp (1872, pp. 2–3) also notes that certain Sindhi φ-consonants were altogether ignored in the process, sometimes inexplicably so. For instance, velar [k kʰ ɡ ɠ ɡʱ] were all represented in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 by |ک|, despite the availability of 𝚏𝚊-𝙰𝚛𝚊𝚋 |گ| [ɡ]. Similarly, separate graphs were not created for retroflex [ɽ] and [ɳ], which were represented simply by |ر| [ɾ] and |ن| [n]. Also employed were digraphs such as |نک| for [ŋ], which proved ambiguous given the multiple phonological values of |ک|. As a result, the linguistic values of the graphs in question remained variable.
Given the variation in the graph inventory and graph-phone correspondences of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍, it is unsurprising that the spellings of individual words also showed considerable variation. This was the case even with frequently occurring items. For instance, the graphematic composition of the Sindhi third-person singular copula form [aɦe] ‘is’ ranged from the now-normative |آهي| to the now-obsolete |اٰهِ| (Allana, 1993 [1964], p. 121). Notwithstanding such variation, these practices continued until the mid-nineteenth century, until British efforts at further standardisation resulted in the introduction of a modified graph inventory and linguistic values.
6.3 Barrow Ellis’ system
As outlined in Section 5.2, Commissioner Bartle Frere’s proclamation of Sindhi as the language of administration in British-ruled Sindh set into motion government efforts towards creating a standardised writing system for the language — at least more standardised than prevalent ones. Frere’s deputy, Assistant Commissioner Barrow Ellis, put together a committee to decide on the matter. After much debate, the committee decided to adopt a writing system based on the Arabic script with additional graphs for Sindhi-specific phones. The system was finalised in July 1853 (Government of Bombay, 1857, p. 104) and officially proclaimed on 29 August 1857 (Hauze, 2016g). The resultant 𝚜𝚍-𝙰𝚛𝚊𝚋 system has been described by Allana (1993 [1964]) as “Ellis’ orthography”.81 Colonial-era authors have dubbed the system the “Government Alphabet” (Trumpp, 1872, pp. 534–535) or the “Government Sindhī alphabet” (Grierson, 1919, p. 335), alluding to its bureaucratic origins. In terms of language subtags, the system will be referred to as 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹. As was the case with books printed in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍, the first books printed in the 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 system were also lithographed, with publications using metal types appearing only in 1863 (Goldsmid, 1863, p. v).
6.3.1 Phonograms
An overview of γ-consonants in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 is shown in Table 6.4.
Source: Goldsmid (1863, pp. 28–29) and Trumpp (1872, pp. 534–535)
| ث | ٺ | ٽ | ٿ | ت | ڀ | ٻ | ب |
| s | ʈʰ | ʈ | t̪ʰ | t̪ | bʱ | ɓ | b |
| ح | ڇ | چ | ڃ | ﺟﻬ | ڄ | ج | ڦ | پ |
| ɦ | t͡ɕʰ | t͡ɕ | ɲ | d͡ʑʱ | ʄ | d͡ʑ | pʰ | p |
| ڙ | ر | ذ | ڍ | ڊ | ڏ | ڌ | د | خ |
| ɽ | ɾ | z | ɖʱ | ɖ | ɗ | d̪ʱ | d̪ | x |
| غ | ع | ظ | ط | ض | ص | ش | س | ز |
| ɣ | Ø | z | t̪ | z | s | ɕ | s | z |
| ڱ | ﮔﻬ | ڳ | گ | ک | ڪ | ق | ف |
| ŋ | ɡʱ | ɠ | ɡ | kʰ | k | q | f |
| ي | ھ | و | ڻ | ن | م | ل |
| j | ɦ | ʋ | ɳ (ɽ̃) | n (n̪) | m | l |
Illustrations of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 γ-vowels comprising subsegmental graphs combined with alif, hamza and |ب| [b] are shown in Table 6.5. Where variant forms exist, the choice of form may be determined by graphematic environment in certain instances, and freely by the writer in others.
| with alif | |||||||||
| ɔ | o | ɛ | e | u | ʊ | i | ɪ | a | ə |
| اَو اَؤ |
او | اَي اَئِ |
اي | اُو اوُ |
اُ | اِي ايِ |
اِ | آ | اَ |
| with hamza | |||||||||
| ɔ | o | ɛ | e | u | ʊ | i | ɪ | a | ə |
| ئَو ئَؤ |
ئو | ئَي ئَئِ |
ئي | ئُو ئوُ |
ئُ ءُ |
ئِي ئيِ |
ئِ ءِ |
ئا | ئَ ءَ |
with |ب| [b] |
||||||||||
| bɔ | bo | bɛ | be | bu | bʊ | bi | bɪ | ba | bə | b |
| بَو بَؤ |
بو | بَي بَئِ |
بي | بُو بوُ |
بُ | بِي بيِ |
بِ | با | بَ | ب بۡ |
Comparing Table 6.3 and Table 6.4, it is evident that the main distinction between the 𝚜𝚍-𝙰𝚛𝚊𝚋 systems of Abul Hasan and Barrow Ellis lay in the makeup of their respective graph inventories and graph-phone correspondences. In particular, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 featured modified graphetic forms of certain graphs, as well as more predictable correspondences between graphs and their linguistic values. The number of graphs listed in the collation order was also set at 52. Despite these measures, the new system was far from comprehensive. One of the earliest detailed critiques of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 is found in Trumpp (1872), who writes:
This new system [𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹], instead of striking at the root of the previous confusion [𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍], merely endeavoured to make up some deficiencies of the old, while retaining all its errors, so that it cannot even boast of the compactness of the old system.
Trumpp’s critique focuses on γ-consonants. Regarding the velars, he expresses surprise at the endorsement of |ڪ| [k] and |ک| [kʰ]. In 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍, |ڪ| appeared only as a stylistic allograph of |ک| in Initial and Medial positions (Gacek, 2008, pp. 8, 43; 2009, p. 275).82 On this basis, Trumpp opposes |ڪ| being spun off into a distinctive phonogram. He also criticises the creation of |ڱ| [ŋ] and |ڳ| [ɠ] for various reasons, primarily for featuring a surfeit of nuqtas. Regarding the alveolo-palatals, retroflexes and labials, he notes the apparently unsystematic and, occasionally, unnecessary rearrangement of nuqtas on some graphs compared to the previous system, while also disapproving of the creation of |ڻ| /ɳ/. While he approves of the incorporation of 𝚞𝚛-𝙰𝚛𝚊𝚋 |گ گھ جھ ڙھ| /ɡ ɡʱ d͡ʑʱ ɽʱ/, he also questions this piecemeal inclusion as opposed to adopting the Hindustani graph inventory in its entirety for Sindhi:
[T]he old Sindhī system of writing [𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍] did not answer its purposes, quite abstracted from its deficiency; but instead of emendating the old system by a different distribution of dots and inserting a few Hindūstānī letters, we consider it far more advisable, to adopt the whole Hindūstānī consonantal system, and to mark those sounds, which are peculiar to the Sindhī, by convenient dots.
On this basis, Trumpp proposes a new variant of 𝚜𝚍-𝙰𝚛𝚊𝚋, with a graph inventory, linguistic values and spellings based on 𝚞𝚛-𝙰𝚛𝚊𝚋, described in Section 6.4.
An aspect of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 absent from Trumpp’s critique but raised by Allana (1993 [1964], p. 104 footnote) is that of aspirate φ-sonorants in Sindhi. Allana’s stance is that [mʱ nʱ ɳʱ lʱ ɽʱ ʋʱ] should be considered standalone phonemes in Sindhi phonology, similar to aspirate oral stops.83 According to Allana, the interpretation of [mʱ nʱ ɳʱ lʱ ɽʱ ʋʱ] as clusters of a φ-sonorant and [ɦ] is mistaken, as is their digraphic representation as shown in (9):
Allana contends that representing each of [mʱ nʱ ɳʱ lʱ ɽʱ ʋʱ] with a digraph has given rise to gratuitous or redundant graphematic practices, such as affixing subsegmental γ-vowels multiple times on them (Allana, 1993 [1964], p. 149). As outlined in Section 4.3.1, Allana’s stance on the phonological status of [mʱ nʱ ɳʱ lʱ ɽʱ ʋʱ] in Sindhi is echoed by Nihalani (1999), but not by Cole (2001) or Khubchandani (2007). As Cole (2001) observes, there are few, if any, instances in Sindhi where [mʱ nʱ ɳʱ lʱ ɽʱ ʋʱ] contrast with the sequences [mɦ nɦ ɳɦ ɽɦ lɦ ʋɦ].84 This may explain why visually distinct graphs may not have been considered for these phones. Indeed, it appears that no major South Asian writing system — including those of Sindhi — features dedicated graphs for any of these segments.85 Nevertheless, Allana’s observation on the potential ambiguities caused by the digraphic representation of [mʱ nʱ ɳʱ lʱ ɽʱ ʋʱ] and the inconsistent addition of subsegmental graphs is valid, and continues to be observable in present-day 𝚜𝚍-𝙰𝚛𝚊𝚋 orthographic practices. As will be described in Section 6.5, such variable practices may have implications for 𝚜𝚍-𝙰𝚛𝚊𝚋 pedagogy and literacy.
With regard to the graphematic representation of φ-vowels, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 largely persisted with the 𝚡-𝚝𝚛𝚊𝚍 practice of explicitly denoting all γ-vowels, including any subsegmental elements. However, it also retained the shortcomings of the 𝚡-𝚝𝚛𝚊𝚍 variant, such as the graphematic underdifferentiation of [u] and [o], with both written |◌ـوُ|. A prominent example of this phenomenon is seen in Bartle Frere’s proclamation on 29 August 1857 (Hauze, 2016g) declaring Sindhi the official language of government work in Sindh. The title of the document features the spelling |پَڌَرۡناموُ| [pəd̪ʱəɾᵊnamo] ‘proclamation’, with [o] written |◌ـوُ|. Similar instances are also seen in the body text of the proclamation, such as |تَرجموُ| [t̪əɾᵊd͡ʑəmo] ‘translation’ and |مَهـيِـۡنوُ| [məɦino] ‘month’. Furthermore, while the new system persisted with using |◌ٍ ◌ٌ| for word-final [ĩ ũ (õ)] (Allana, 1993 [1964], p. 115), it also permitted |◌ـِين ◌ـُون| as graphematic equivalents. This resulted in at least two possible ways to spell words containing these word-final φ-vowels.
The main reason why 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 fell short of its intended aim of being a ‘standardised’ writing system for Sindhi was its failure to explicitly rule on the finer points of graphotactics (Lekhwani, 2011, p. 34). As Allana (1993 [1964], p. 129) notes, while Ellis’ system standardised the graph inventory to a large extent, it failed to usher in clarity on the spellings of individual words. As a result, words continued to be spelt in a variety of idiosyncratic ways, even by scholars. Such variable spellings extended to commonly occurring lexical items, such as [poᶦ] ‘afterwards’ appearing as |پوءِ| as well as |پوئي|, and [ʊn(ɦ)ənᶦ] ‘3PL.OBL’ being written as either |اُنَن| or |اُنَهنِ| (Allana, 1993 [1964], p. 130). Particularly vexing was the graphematic representation of nasalised final φ-vowels. Since word-final [ĩ ũ õ] could now be spelt |◌ـِين ◌ـُون|, there was greater room for ambiguity on the phonological value of final |ن|. This issue was partly addressed by Shirt, Thavurdas and Mirza in their Sindhi-English dictionary (1879, p. iv), by adopting the following convention:
- |ن| with jazm |◌ٛ| denotes [
n] - |ن| with a γ-vowel denotes [
n] followed by a φ-vowel - ‘bare’ |ن| denotes nasalisation of the preceding φ-vowel
In their dictionary, Shirt, Thavurdas and Mirza also make a rather telling statement on orthographic variation in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹:
Some apology seems to be required for the many alternative forms that will be found in the Dictionary. Numerous as these may appear, it does not seem possible to eliminate them at present ; for they not only exist in the colloquial, but have all found a place in the written language. They cannot probably all survive the struggle for existence ; and the sooner the usage of some of them is discontinued, the better, but at present we can only speculate as to which forms will eventually prevail. This is a question which should form a subject of discussion by the Vernacular Literature Committee, and in future authors should confine themselves to those forms that meet with the approval of that body. Sindhi, though an old language, is still vigorous and growing, […]
While the authors must be commended for attempting to describe rather than prescribe 𝚜𝚍-𝙰𝚛𝚊𝚋 graphematic practices, the “many alternative forms” they speak of is aptly illustrated in the dictionary entry for the Sindhi word [ɦoɗãɦᶷ̃]:
هوڏانهون , هوڏانهُون , هوڏانهِين , هوڏانئُن , هوڏانئِين , هوڏاهَنئُن or هوڏائون adv. There, in that direction.
All the same, Shirt et al.’s expectation that a graphematic natural selection would eventually prevail has indeed materialised to some extent. In the twenty-first century, 𝚜𝚍-𝙰𝚛𝚊𝚋 dictionaries commonly list only one spelling for the word [ɦoɗãɦᶷ̃], albeit one that is absent from Shirt et al.’s dictionary: |هوڏانهُن| (Baloch, 1998, p. 723; Lekhwani, 1996, p. 199; Rohra, Bijani, & Gurnani, 2011, p. 566).86 Questions of spelling also extended to the nature of subsegmental graphs in a graphematic word. In the initial years of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹, subsegmental graphs — most of which were γ-vowels — were generally written. Soon after, though, most subsegmental graphs, with the exception of tanvin, began to be omitted on a discretionary basis. For instance, a matriculation examination paper on Sindhi grammar from the year 1866 features 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 text largely devoid of subsegmental graphs. However, the same paper also features questions like “Give the names of the short and long vowel marks [in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹]” and “What are the names of the following marks, and what are the uses of each [in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹]? ( ◌ۡ ) ( ◌ّ ) ( ◌ٓ ) ( ◌ٌ )” (University of Bombay, 1867, pp. xxxviii–xliii). The explicit recognition and inclusion of subsegmental graphs in formal education was accompanied by the implicit understanding that they would be left out of everyday 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 writing. On the one hand, dropping subsegmental graphs from everyday use was consistent with 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 practice, as well as with abjadic unstandardised Landa writing (§5.1.1). On the other hand, the surface omission of subsegmental graphs from 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 increased its graphematic opacity, eventually resulting in uncertainty on the underlying spellings of words. Swimming against the tide somewhat was the tanvin |◌ٍ ◌ٌ ◌﮼|, which continued to be extensively used in nineteenth-century 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 writing to denote word-final [ĩ ũ ẽ]. Figure 6.2 features an extract from a Sindhi translation of the Bible’s Gospel of John (American Bible Society, 1893, p. 26) in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹. First translated in 1858 (Nida, 1972, p. 393), the text features several instances of tanvin being productively used, such as the word |ڎِناءٍ| [ɗɪnaĩ] ‘he gave’.87

“For God so loved the world, that he gave his only begotten Son, that whosoever believeth in him should not perish, but have everlasting life.”
Source: American Bible Society (1893, p. 26)
By the early twentieth century, though, the tanvin had given way to bare |ن| as the standard graphematic device to denote φ-vowel nasalisation.88 This aligned with a large-scale, albeit incremental move, in the late nineteenth century towards resolving issues of graphematic irregularity in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹. In 1888, the Education Inspector of Sindh, HP Jacobs, had a chart of the various spellings of certain words prepared. A chart of these words was distributed to schools throughout Sindh. However, this chart failed to address the spellings of words with final nasalised φ-vowels, as well as a few others. On 13 February 1913, educational experts along with members of the Sindhi Literature Committee passed a resolution to finalise standardised spellings for words omitted in the 1888 chart. This was followed up by a committee instituted in 1915, whose members included the renowned Sindhi author and translator Mirza Qalichbeg (Allana, 1993 [1964], pp. 131–135; Boivin, 2008c). Notably, the committee decided to retain the tanvin in the spellings of three commonly occurring words: |۽| [aᶦ̃ ~ aĩ] ‘and’, |۾| [mẽ] ‘in, within’ and |آءٌ| [aᶷ̃ ~ aũ] ‘1SG.NOM’ (see (8)). The decision to retain these spellings reflects their conventionalisation in the 𝚜𝚍-𝙰𝚛𝚊𝚋 graphosphere. Indeed, these three words appear to be the only entries featuring a tanvin in Shirt et al.’s (1879) and Mewaram’s (1910) Sindhi-English dictionaries.
Of these dictionaries, Mewaram’s (1910) work is now considered a lexicographic milestone in 𝚜𝚍-𝙰𝚛𝚊𝚋, and remains a key reference work more than a century after its publication (Addleton & Brown, 2010, p. xvi). It is unclear, though, whether and to what extent Mewaram’s dictionary might have contributed to the 1913–1915 reforms. By and large, though, the reforms succeeded in constraining the graphematic solution space for certain words in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍. At the same time, it is difficult to unequivocally assert that 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 as updated in the 1915 reforms has prevailed as the undisputed variant of 𝚜𝚍-𝙰𝚛𝚊𝚋. The 1947 Partition of British India resulted in the split of the 𝚜𝚍-𝙰𝚛𝚊𝚋 graphosphere into Pakistani and Indian subgroups, and ongoing political tensions between Pakistan and independent India have resulted in these subgroups being relatively isolated from each other. Such mutual isolation has resulted in minor, albeit noticeable divergence in 𝚜𝚍-𝙰𝚛𝚊𝚋 graphematic practices between the two graphospheres, which will be described and evaluated in Section 6.5.
6.3.2 Logograms and collation order
The first book printed in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 using movable type (Goldsmid, 1863) contained the numeral forms |۱ ۲ ۳ ۴ ٥ ٦ ٧ ۸ ۹ ۰| ‘1 2 3 4 5 6 7 8 9 0’ (see (7)). These forms are identical to those commonly used in present-day 𝚊𝚛-𝙰𝚛𝚊𝚋 except for |۴| ‘4’, which usually appears as |٤| (Bauer, 1996, p. 562). Graphs used as punctuation in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 were largely adopted from the Roman-script inventory, although their use was highly variable. The Roman-script full stop | . | varied freely with the hyphen-like equivalent |۔| adopted from the 𝚞𝚛-𝙰𝚛𝚊𝚋 inventory (Grierson, 1919; University of Bombay, 1875, pp. xlvii–l). Asymmetrical graphs such as | , ; ? | initially appeared in their Roman-script orientations (University of Bombay, 1900, p. xlviii). They were eventually replaced by visually mirrored ones, presumably to harmonise with the dextrosinistral flow of 𝚜𝚍-𝙰𝚛𝚊𝚋.
Regarding the collation order of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹, Allana (1993 [1964], p. 105) lists the following 52-graph sequence:
ا ب ٻ ڀ ت ٿ ٽ ٺ ث پ ڦ ج ڄ ﺟﻬ ڃ چ ڇ ح خ د ڌ ڏ ڊ ڍ ذ ر ڙ ز س ش ص ض ط ظ ع غ ف ق ڪ ک گ ڳ ﮔﻬ ڱ ل م ن ڻ و ھ (ء) ي
The above collation order is largely identical to the one listed in the very first 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 printed using movable type (Goldsmid, 1863, pp. 28–29). However, the latter list omits hamza |ء|, resulting in a total of 51 graphs:
ا ب ٻ ڀ ت ٿ ٽ ٺ ث پ ڦ ج ڄ ﺟﻬ ڃ چ ڇ ح خ د ڌ ڏ ڊ ڍ ذ ر ڙ ز س ش ص ض ط ظ ع غ ف ق ڪ ک گ ڳ ﮔﻬ ڱ ل م ن ڻ و ﮪ ي
In their Sindhi-English dictionary, Shirt et al. (1879) use the following collation order:
ا ب ٻ ڀ ت ٿ ٽ ٺ ث پ ڦ ج ڄ ﺟﻬ ڃ چ ڇ ح خ د ڌ ڏ ڊ ڍ ذ ر ڙ ز ژ س ش ص ض ط ظ ع غ ف ق ڪ ک ڱ گ ڳ ﮔﻬ ل م ن ڻ و ﮪ ي
This is also the order that Grierson (1919, p. 21) lists in the Linguistic Survey of India, terming it the earliest ‘standard’. This order differs from Goldsmid’s in the position of |ڱ| [ŋ]. It also comprises 52 graphs thanks to the addition of the 𝚏𝚊-𝙰𝚛𝚊𝚋 |ژ| [ʒ] (see Table 6.2), despite the corresponding phoneme being absent in Sindhi.
Mewaram (1910) uses the following collation order in his classic dictionary:
ا (آ) ب ٻ ڀ ت ٿ ٽ ٺ ث پ ڦ ج ڄ ﺟﻬ ڃ چ ڇ ح خ د ڌ ڏ ڊ ڍ ذ ر ڙ ز س ش ص ض ط ظ ع غ ف ق ڪ ک گ ڳ گ ﮔﻬ ڱ ل م ن ڻ و ﮪ ي
In this order, the status of |آ| [a] is ambiguous. Mewaram’s dictionary lists headwords commencing with |آ| separately, albeit within the section for |ا|. Overall, though, Mewaram’s collation order represents a return to Goldsmid’s order in terms of the position of |ڱ| and the omission of |ژ|. The omission of |ژ| has proven decisive, resulting in the disappearance of the graph from modern-day 𝚜𝚍-𝙰𝚛𝚊𝚋 inventories (Jhangiani, 1987).
6.4 Ernest Trumpp’s system
As described in the previous section, one of the most outspoken critics of Ellis’ system was the German Christian missionary Ernest Trumpp. One of the earliest — if the not the earliest — mentions of Trumpp’s dislike of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 is found in the brief ‘Essay on the Sindian Alphabets’, published in the Journal of the Royal Asiatic Society (1857). In this article, Trumpp criticises 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 as being loaded “with a confusing heap of dots and other diacritical marks” (Trumpp, 1857, p. 685). As an alternative, Trumpp moots an alternative Arabic-script-based graph inventory and graph-phone correspondences based on 𝚞𝚛-𝙰𝚛𝚊𝚋. This system will be referred to henceforth by the language tag 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙. Ideally, though, Trumpp was inclined towards using Devanagari for Sindhi. Besides, he subscribed to the existence of supposed religious prejudice between Muslim and Hindu Sindhis, and the consequent need for separate alphabets for the two communities (§5.2.2). On this basis, Trumpp proposes two distinct writing systems for Sindhi — one based on 𝚞𝚛-𝙰𝚛𝚊𝚋, and the other on Sanskrit-Devanagari (𝚜𝚊-𝙳𝚎𝚟𝚊). The latter is taken up in Section 7.4.
The first instance of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 appearing in a printed work is likely in A Sindhi Reading-Book in the Sanscrit and Arabic Character (Trumpp, 1858). Comprising translations of Christian scriptures, the Sindhi translations in the book appear in 𝚜𝚍-𝙰𝚛𝚊𝚋 as well as in 𝚜𝚍-𝙳𝚎𝚟𝚊. This reflected Trumpp’s view that two separate writing systems were apparently needed for Muslim and Hindu Sindhis. In a German-language article on Sindhi grammar published in the Zeitschrift der Deutschen Morgenländischen Gesellschaft (ZDMG), Trumpp provides an overview of his proposed 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 systems, while making no bones about his feelings on 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹:
Die vorstehenden Alphabete [𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 & 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙] habe ich, sowie sie gegeben sind, erst selbst verfertigt; es sind also keineswegs althergebrachte Systeme. […] Das arabisirte Alphabet, für die Muhammedaner bestimmt, habe ich zum ersten male schneiden und damit drucken lassen; ich habe dabei das Hindūstānī-Alphabet zu Grunde gelegt, und die für das Sindhī nothigen Laute [sic] eingeschoben. Die Muhammedaner in Sindh gebrauchen verschiedene arabische Alphabete, theils mit, theils ohne diacritische Zeichen, aber so unwissentschaftlich zusammengestellt, dass sie einer Revision dringend bedürfen.
Um der herrschenden Confusion ein Ende zu Machen, hat kurz vor meiner Ankunft in Sindh, ein englischer Regierungsbeamter [Frere? Ellis?] ein neues arabisirtes Alphabet componirt, und es dem Lande aufgedrungen, das aber das albernste von allen genannt werden muss.
The alphabets presented here [𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 & 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙] are in no way established systems. Rather, they have been designed by me […] The Arabic alphabet, intended for Mohammedans, has been cast and used in print for the first time by myself.89 I have based it on the Hindūstānī alphabet, adding those sounds [sic] necessary for Sindhī. The Mohammedans in Sindh use several Arabic alphabets, sometimes with, sometimes without diacritical marks, but in a manner so unscientific that it had to be urgently revised.
In order to bring the reigning confusion to an end, an English government official [Frere? Ellis?] had an Arabic alphabet prepared and imposed upon the country. This alphabet, however, must be regarded as the most ridiculous of them all.
Trumpp also employs his 𝚜𝚍-𝙰𝚛𝚊𝚋 system in subsequent ZDMG articles. The first (1862) is a continuation of his Sindhi grammar from the previous year, while the second is an overview of Shah Abdul Latif’s poetry (1863). The latter work was eventually published as a separate compilation (Trumpp, 1866), marking the first appearance of Shah Latif’s poetry in print (Boivin, 2020, p. 95). Trumpp’s ZDMG articles on Sindhi grammar were also compiled and published as a book (1872), which is now considered a classic in the field of Sindhi linguistics.
On the question of script to be used for Sindhi, Trumpp writes in his grammar that “[t]he number of the Indian alphabets should not be augmented, but rather, wherever possible, be restricted, as they only serve as barriers to mutual intercourse” (Trumpp, 1872, p. 6). On this basis, he opines that, since the Sindhi language is “restricted to the comparatively small province of Sindh”, it makes sense to adopt the more widely used “Hindustani alphabet” (𝚞𝚛-𝙰𝚛𝚊𝚋), with suitable modifications as necessary to suit Sindhi phonology.
Compared to its first appearance in print (Trumpp, 1858), 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 varied ever so slightly in subsequent works until finalised (Trumpp, 1872). The description that follows is based on the final version, and emphasises the points of divergence from 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹.
6.4.1 Phonograms
Figure 6.3 is an extract from Trumpp’s grammar (1872), showing the inventory of γ-consonants in his proposed 𝚜𝚍-𝙰𝚛𝚊𝚋 system.

Source: Trumpp (1872, p. 7)
As seen in Figure 6.3, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 is founded upon the 𝚞𝚛-𝙰𝚛𝚊𝚋 graph inventory of the time. The most prominent evidence of this fact is the consistent use of |ھ| to denote an aspirated φ-stop. Similarly conspicuous is the choice of the 𝚞𝚛-𝙰𝚛𝚊𝚋 |ٿ ڐ ڙ| for [ʈ ɖ ɽ], respectively, which, for much of the nineteenth century, were in free variation with the now-standard |ٹ ڈ ڑ| (Lepsius, 1863, p. 101; Shakespear, 1813, p. viii). Phonologically, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 spellings reflect Siroli pronunciations in overtly denoting the clusters [ʈɾ ɖɾ], thus distinguishing them from simple [ʈ ɖ] (§4.3.1). Notable is the depiction of |ڙھ| as a compound graph for [ɽʱ], illustrated by its equivalence with 𝚜𝚍-𝙳𝚎𝚟𝚊 |ढ़|. The inclusion of |ڙھ| as a standalone entity in the inventory suggests that Trumpp considered [ɽʱ] phonemic (see Table 4.1). Also noteworthy is the presence of |ن࣪| for [ɳ]. Since [ɳ] is not well established in classical Urdu, |ن࣪| may be considered a marginal graph in 𝚞𝚛-𝙰𝚛𝚊𝚋 (Shakespear, 1813, p. 22). However, the phonological salience of [ɳ] in Sindhi meant that |ن࣪| was prominent in the 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 inventory. In contrast, the 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 inventory does not feature an equivalent for 𝚜𝚊-𝙳𝚎𝚟𝚊 |ष|, which denotes [ʂ(a)] in Sanskrit. The omission was deliberate, since Trumpp felt that the articulation of [ʂ] as such in Sindhi “is completely ignored by the common people” (Trumpp, 1872, p. 18). The graphs |ٻ ڄ ڎ| for the implosives [ɓ ʄ ɗ] are retained from 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍. However, [ɠ] is depicted by the Pashto-inspired |ڰ| (cf. Pashto |ګ| [ɡ]).90 Completing the inventory are the graph sequences |نگ نڄ| for [ŋ ɲ]. Trumpp admits to the ambiguity inherent in these graph sequences, but puts the onus on the reader to navigate them:
In Hindūstānī an independent guttural
ṅ[IPAŋ] is not to be met with ; we have therefore been compelled to circumscribe it [in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙] by the compound نگng[…] But one difficulty still will remain, that the guttural simpleṅcan thus not be distinguished from the gutturalṅpreceding a letter of its own varga [i.e., phonological category], as: اَنگُ (अङु)aṅu, body, and اَنگُ (अंगु, or more properly: अङ्गु)angu(aṅgu) a limb. […] Practically the difficulty will be easily surmounted by any careful student, […]
Allana (1993 [1964], p. 124) reiterates and critiques the above ambiguity. However, in doing so, Allana depicts the graph sequence for [ɲ] as |نج|, rather than Trumpp’s |نڄ|. This typographical mix-up may well be an inadvertent illustration of what Trumpp has termed “the reigning confusion” across 𝚜𝚍-𝙰𝚛𝚊𝚋 graph inventories (Trumpp, 1861, pp. 697–698 footnote).
Regarding consonant gemination, Trumpp recommends using tashdid |◌ّ| only for written disambiguation, offering the examples of |اُنَ| [ʊnᵊ] ‘3SG.OBL’ and |اُنَّ| [ʊnnᵊ] ‘wool’. However, he also states that, “in the old Sindhī writings the tašdīd is hardly ever to be met with […]” (1872, p. 29). Overall, Trumpp makes no explicit statements on whether phonological gemination in Sindhi should be considered contrastive (§4.3.1). Aside from these modifications, all γ-consonants originating in 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 are retained unchanged. This includes 𝚏𝚊-𝙰𝚛𝚊𝚋 |ژ| [ʑ ~ ʒ] (see Figure 6.3), which was absent from the initial version of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 (Trumpp, 1858).
Figure 6.4 shows the inventory of γ-vowels in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙.

Source: Trumpp (1872, p. 21)
In explicitly endorsing |◌ٖي| for [e], 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 adopts graphematic practice from 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹. However, there existed no comparable precedent for denoting [o]. Against this background, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙’s representation of [o] as |◌ۉ| counts as an innovation. Graphetically, |◌ۉ| is a compound of |و| and jazm |◌ٛ|, which precludes the latter from being unambiguously used in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 as an allograph of sukun |◌ْ| to show the absence of a postconsonantal φ-vowel [Ø]. Hence, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 only uses sukun |◌ْ| to denote [Ø].91 Regardless of nomenclature, |◌ْ| is also used in the 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 graphs |اَيْ| and |اَوْ|, denoting the diphthongs [ɛ ~ əɪ̯] and [ɔ ~ əʊ], respectively. Strictly speaking, |اَيْ| and |اَوْ| could also be read as [əj] and [əw], respectively, although doing so does not result in a phonemic contrast in Sindhi. Finally, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 explicitly deprecates the practice of using zer |◌ِ| [ɪ] to show the absence of a vowel [Ø] (Trumpp, 1872, p. 29). Yet, the use of |◌ِ| as a quasi-allograph of sukun |◌ْ| has persisted into the twenty-first century.
In terms of word-medial sequences of γ-vowels, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 codifies and explicitly endorses the use of hamza, including the distribution of its allographs. His recommendations are consistent with present-day 𝚜𝚍-𝙰𝚛𝚊𝚋 usage:
The sign ــٔـ (هَمْزَه hamzah, i.e. punction) is used in the midst and at the end of words as a vicarious base for ا; when two vowels, short or long, meet in a word, the second vowel must be supported by the base ى, furnished with hamzah, e.g.: […]هِنئَرَ hĩara, now; […] A final short vowel, preceded by ā, ū, ō is usually supported by the sign hamzah alone, as بهاءُ bhā-u, brother;
Trumpp includes a laborious — and occasionally inconsistent — explanation on how to use |ن| to denote nasalisation of a φ-vowel on the one hand, and the alveolar nasal φ-consonant [n] on the other (pp. 25–28). Regardless of the explanation, examples from his grammar reveal the following graphematic patterns and phonological values:
- bare |ن| denotes φ-vowel nasalisation, and is written immediately after the corresponding γ-vowel;
- |ن| suprafixed with sukun |◌ْ| represents the nasal φ-consonant [
n]; - |ن| affixed with a subsegmental γ-vowel represents [
n] followed by the corresponding φ-vowel.
In this regard, Trumpp’s representation of φ-vowel nasalisation is near-identical to that advocated by Shirt et al. (1879), although it remains unclear whether the latter was inspired in any way by the former. At any rate, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙’s conventions on the use of |ن| were more consistent than in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 (Trumpp, 1872, p. 28). Aside from its inconsistent use, Trumpp speaks out against using tanvin to mark φ-vowel nasalisation due to the potential for a clash with its 𝚊𝚛-𝙰𝚛𝚊𝚋 value:
Die Sindhī’s [sic] selbst haben versucht, einen auslautenden nasalisirten Vocal durch das arabische Tanvīn auszudrücken, z. B. sie schreiben کِيَاࣨ = किआंऊं; abgesehen davon, dass das arabische Tanvīn keine Nasalisation im Sinne der Prākritsprachen ausdrückt, tritt dabei auch noch der Misstand ein, dass die kurzen oder langen nasalisirten Vocale gar nicht mehr in der Schreibweise auseinander gehalten werden können. […] Allein die Form ۽ = ē̃ „und“ haben wir beibehalten, obschon sie an und für sich ein Monstrum ist, als eine bequeme Abkürzung, wie etwa unser & statt et; eigentlich sollte es اين oder اَيْن geschrieben werden.
The Sindhis themselves tried to mark a final nasalised vowel using the Arabic Tanvīn. Thus, they write کِيَاࣨ = किआंऊं. Besides the fact that the Tanvīn does not represent nasalisation of the Prākrit kind, the use of Tanvīn also means that short and long nasalised vowels can no longer be clearly distinguished in writing. […] We have only retained the form ۽ = ē̃ “and”, which is a monstrosity that, nevertheless, serves as a convenient abbreviation, much like our & for et. Ideally, it should have been written اين or اَيْن.
Thus, with the exception of logographic |۽| [ɛ̃ ~ əĩ] ‘and’, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 deprecates the use of tanvin to denote φ-vowel nasalisation. Consequently, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍 |۾| [mẽ] ‘in’ becomes 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 |مٖين| (Trumpp, 1866, p. 731). In general, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 discourages graphematic recycling from 𝚊𝚛-𝙰𝚛𝚊𝚋. By extension, it recommends retaining source writing conventions in borrowings, as in the use of medial |آ| in 𝚜𝚍-𝙰𝚛𝚊𝚋 |قُرآنُ| [qʊɾanᶷ ~ kʊɾanᶷ] ‘Quran’ (Trumpp, 1872, p. 28).
Overall, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 consistently and rigorously denotes all graphetically subsegmental elements. Although Trumpp emphasises the utility of retaining subsegmental graphs in works intended for a European readership, he concedes that they may well prove superfluous in works “destined for the use of natives” (p. 23).
6.4.2 Logograms and collation order
While 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 contains no explicit specifications on numeral forms per se, Trumpp’s works feature the graphs |۱ ۲ ۳ ۴ ٥ ٦ ٧ ۸ ۹ ۰| ‘1 2 3 4 5 6 7 8 9 0’ (Trumpp, 1866; 1872, pp. 157–168). These are identical to those employed by Goldsmid (1863), making the numeral inventories of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 identical. Also absent from 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 are rulings on punctuation marks, although a four-dot separator |⁛| is consistently used as the equivalent of the 𝚎𝚗-𝙻𝚊𝚝𝚗 full stop. In fact, Trumpp employs this graph not just in his 𝚜𝚍-𝙰𝚛𝚊𝚋 works, but also his 𝚜𝚍-𝙳𝚎𝚟𝚊 texts (Trumpp, 1858; 1866; §7.4, p. 201). Other prominent logograms in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 include the aforementioned |۽| [ɛ̃ ~ əĩ] ‘and’, and the benediction |اللّٰه| ‘Allah’. Trumpp does, however, augment the latter with subsegmental phonograms to denote Sindhi-specific noun declensions (§4.4), as in |اللّٰهُ| [əl(l)aɦᶷ] ‘Allah (nominative case)’ and |اللّٰهَ| [əl(l)aɦᵊ] ‘Allah (oblique case)’ (Trumpp, 1866). The juxtaposition of the graphosegmental logogram |اللّٰه| with the graphosubsegmental phonograms |◌َ ◌ُ| [ᵊ ᶷ], which also occurs in 𝚊𝚛-𝙰𝚛𝚊𝚋, presents an intriguing case of hybridity that tests the limits of prevailing grapholinguistic terminology and theory.
The comprehensiveness of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 is well-illustrated by the inclusion of a collation order, with graphs sorted based on an 𝚊𝚛-𝙰𝚛𝚊𝚋-inspired collation order (Trumpp, 1872, pp. 8–9):
ا ب ٻ پ ت ٿ ث ج ڄ ج ح خ د ڐ ڎ ذ ر ڙ ز ژ س ش ص ض ط ظ ع غ ف ق ک گ ڰ ل م ن ن࣪ و ه ي
Compared with the graphs shown in Figure 6.3 and Figure 6.4, the 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 collation order above does not list aspirate γ-consonants per se. This is likely due to Trumpp’s interpretation of aspirate γ-consonants as multigraphs comprising a γ-consonant and |ھ| (1872, p. 3). The sequence also omits hamza |ء|.
Apart from the odd incongruity, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 emerges as clear and consistent in terms of graph inventory and graph-phone correspondences. Its regularity stands in stark contrast to the variation observed in the use of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹, especially when one considers that the latter was instituted by a committee of scholars and administrators. Despite its graphematic robustness, though, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 was extensively employed only by Trumpp himself. At most, the system was acknowledged by other authors, and the graph inventory reproduced for purposes of demonstration (Lepsius, 1863, pp. 103–105). It is possible that other Arabic-script-based writing systems may have borrowed elements of the 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 graph inventory (Jukes, 1900, p. v), although this remains conjectural. Apart from references by third parties, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 does not seem to have been used in a book-length publication by any author other than Trumpp himself. Nor does there seem to be evidence of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 being used in Sindhi-language education or everyday writing. Thus, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 represents a case of a writing system fading into oblivion despite being well-designed and internally consistent. The fate of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 reinforces Meletis’ (2020, pp. 16–17) observation that the linguistic fit of a writing system does not guarantee its adoption by the community.
6.5 Post-Partition practices 92
As described in Section 6.3, the 1915 reforms of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 (helped constrain variation in spelling and, in turn, establish the foundations of a quasi-conventional orthography (Allana, 1993 [1964], p. 136). Although areas of ambiguity remained, increasing levels of literacy in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 led to standardised spellings becoming established over time. However, by the early twentieth century, the 𝚊𝚛-𝙰𝚛𝚊𝚋-inspired practice of omitting subsegmental graphs had caught on in 𝚜𝚍-𝙰𝚛𝚊𝚋. Due to the ‘out of sight, out of mind’ effect of omitting subsegmental γ-vowels, attempts at spelling standardisation were restricted almost entirely to matters of γ-consonants. Questions on which γ-vowels to use in certain words were largely overlooked (Allana, 1993 [1964], p. 136; Khubchandani, 1969, p. 204). A major event impacting the graphematic evolution of 𝚜𝚍-𝙰𝚛𝚊𝚋 was Partition in 1947, which resulted in the bifurcation of the Sindhi graphosphere into its Pakistani and Indian circles. Although 𝚜𝚍-𝙰𝚛𝚊𝚋 literary, pedagogical and lexicographic activity resumed shortly thereafter on both sides of the new international border, ensuing political tensions between the Pakistani and Indian governments impeded the cross-border exchange of 𝚜𝚍-𝙰𝚛𝚊𝚋 material. As a result, minor distinctions have emerged between Pakistani and Indian 𝚜𝚍-𝙰𝚛𝚊𝚋 graphematic practices in the post-Partition era.
Preeminent among post-Partition 𝚜𝚍-𝙰𝚛𝚊𝚋 lexicographic works in Pakistan is Baloch’s five-volume Jame Sindhi Lughat ‘Comprehensive Sindhi Dictionary’.94 Described as a “monumental” work (Khubchandani, 2007, p. 685), the five volumes of this dictionary were released over two decades, from 1961–1981. This was followed by a second edition starting in the 1990s (Addleton & Brown, 2010, p. xvi). A one-volume version of the dictionary has also been published (Baloch, 1998). Other specialised lexicons and thesauri in 𝚜𝚍-𝙰𝚛𝚊𝚋 have also been published over the years, many of which the Sindhi Language Authority has digitised and compiled into a searchable database on its website (Sindhi Language Authority, 2021a). The SLA has also produced an autodidactic online tutorial for spoken and written Sindhi, with the written form presented in 𝚜𝚍-𝙰𝚛𝚊𝚋 as well as 𝚜𝚍-𝙻𝚊𝚝𝚗 (§12.3). Albeit few in number, grapholinguistic works on 𝚜𝚍-𝙰𝚛𝚊𝚋 have also been published, the most prominent being Allana’s (1993 [1964]) monograph on the history and development of 𝚜𝚍-𝙰𝚛𝚊𝚋. Among 𝚜𝚍-𝙰𝚛𝚊𝚋 lexicographic works published in post-Partition India, Lekhwani’s trilingual Basic Sindhi-English-Hindi dictionary (1996) and bilingual An Intensive Course in Sindhi textbook (1997) are worthy of mention. Besides their lexicographic value, they also exhibit a high level of graphematic rigour. Lekhwani’s writing conventions have been adopted with slight modifications in the Indian Institute of Sindhology’s Trilingual Sindhi-Hindi-English dictionary (Rohra, Bijani, & Gurnani, 2011). The publication of these dictionaries and related pedagogical works has had a stabilising effect on the graph inventory of 𝚜𝚍-𝙰𝚛𝚊𝚋 on both sides of the Indo-Pak border, particularly regarding γ-consonants. Yet, open questions still remain on matters of subsegmental graphs, allography and spelling.
6.5.1 Graphematic vowel nasalisation
In their 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 Sindhi-English dictionary, Shirt et al. (1879) adopted the practice of graphematically denoting a nasalised φ-vowel with bare |ن|, devoid of any subsegmental graphs. Such practice was identical to that observed in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 (Trumpp, 1872). In the post-Partition era, Allana has endorsed this practice, and categorically proscribes adding jazm |◌ۡ| over |ن| to denote φ-vowel nasalisation:
سنڌي ڪتابن ۾ ’گهڻي نون‘ کي ’ساڪن‘ سمجهي، اُن جي مٿان جزم ڏني ويندي آهي. جزم جو اهڙي حالت ۾ استعمال سراسر غلط آهي.
Based on the interpretation of ‘nasal nun’ as ‘quiescent’ [vowelless], Sindhi books often affix jazm over nun. Such use of jazm is utterly wrong.
Despite advocacy by various authors, the written representation of φ-vowel nasalisation in 𝚜𝚍-𝙰𝚛𝚊𝚋 has been variable. For instance, the SLA’s online Sindhi tutorial (Sindhi Language Authority, 2015b) uses |◌نۡ| to denote φ-vowel nasalisation, and bare |ن| to indicate consonantal [n] with no subsequent φ-vowel. This convention is the converse of that endorsed by Shirt et al., Trumpp’s and Allana. That said, despite swapping the graphematic practices in question, the SLA tutorial is internally consistent in their application. Overall, though, the use of jazm in 𝚜𝚍-𝙰𝚛𝚊𝚋 of late seems to be reducing on both sides of the border, even in pedagogical works (see for example Varyani & Thakwani, 2003). As a result, bare |ن| may indicate either φ-vowel nasalisation, or consonantal [n] with no φ-vowel after it.
Overall, the omission of subsegmental graphs in 𝚜𝚍-𝙰𝚛𝚊𝚋 results in homographs and, consequently, an increase in graphematic opacity. Thus, |تَوھان| [t̪əʋʱã] ‘2PL.OBL’ and |تَوھِينَ| [t̪ɔɦinᵊ] ‘insult’ may both appear as underspecified |توھين|, while |مِينھُن| [mĩɦᶷ̃] ‘rain’ and |مينھِن| [mẽɦᶦ̃] ‘she-buffalo’ become graphematically indistinguishable as |مينھن|. It is evident that omitting subsegmental graphs in this manner puts the onus on the reader to correctly decode the spoken values of the underspecified written strings from context. This necessitates a high level of proficiency in spoken Sindhi as well as in written 𝚜𝚍-𝙰𝚛𝚊𝚋.
6.5.2 Graphematic consonant gemination
The disagreement on the presence of geminate φ-consonants in spoken Sindhi is reflected in its writing systems. In 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, Trumpp (1872, p. xxxiii footnote) uses tashdid only to avoid potential homographs. Trumpp cites the examples of |اُنَ| ‘his/her/its’ and |اُنَّ| ‘wool’, wherein the graphovocalised forms indicate the pronunciations [ʊnᵊ] and [ʊnnᵊ], respectively. However, in Mewaram’s 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 dictionary (1910, p. 25), the entry for ‘wool’ is spelt |اُنَ|. In the post-Partition era, scholars differ in their opinion on using tashdid. Allana (1993 [1964]) recommends that tashdid “should not be used in 𝚜𝚍-𝙰𝚛𝚊𝚋 orthography, except in Arabic-origin words” (p. 114).95 In contrast, and as outlined in Section 4.3.1, Lekhwani recommends avoiding tashdid altogether in 𝚜𝚍-𝙰𝚛𝚊𝚋. This seemingly insignificant difference in guidelines results in words having noticeably distinct written manifestations in practice. Revisiting the example of the Arabic-origin loanword meaning ‘respect’ in Sindhi (§4.3.1), the common Sindhi pronunciation of this word varies along a spectrum, ranging from the quasi-Arabic [ɪzzət̪] (Khubchandani, 2007, p. 697) to the Sindhi-ised [ɪzət̪ᵊ] (Lekhwani, 1996, p. 12). Theoretically, when fully graphovocalised, the pronunciation [ɪzzət̪] would be represented as |عِزَّتۡ|, with tashdid included. In contrast, [ɪzət̪ᵊ] would be written |عِزَتَ|, with tashdid absent. When subsegmental graphs are omitted, however, the result in both instances is identical, namely the underspecified |عزت|. Dictionaries may differ in the fully graphovocalised forms they cite, or may simply cite the underspecified forms, without subsegmental graphs. As a result, standard fully-graphovocalised 𝚜𝚍-𝙰𝚛𝚊𝚋 spellings for several Sindhi words are yet to emerge.
6.5.3 Graphematic allography
Variation also prevails in the graphematic manifestation of φ-vowels and φ-consonants. In the context of vowels, variation is seen primarily in the nature and position of subsegmental elements. As shown in Table 6.2, the φ-vowels [i u] are shown in 𝚜𝚍-𝙰𝚛𝚊𝚋 by the complex graphs |◌ِي ◌ُو|, respectively. However, [i u] may also appear as |◌يِ ◌وُ|, differing in the placement of the subsegmental elements zer |◌ِ| and pesh |◌ُ|, respectively. A similar pair of allographs is also observed in the written representation of the φ-vowels [ɛ ɔ]. In 𝚜𝚍-𝙰𝚛𝚊𝚋, the commonly used complex graphs for these vowels are |◌َي ◌َو|, respectively. However, | ◌َﺋِ ◌ؤ| are also seen, as evinced by Figure 6.5. The image features a signboard at an intersection in the Khar suburb of Mumbai, named after an Indian Sindhi educationist.96 The signboard displays the name of the intersection in 𝚜𝚍-𝙳𝚎𝚟𝚊, 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚎𝚗-𝙻𝚊𝚝𝚗-𝙸𝙽.97 In the 𝚜𝚍-𝙰𝚛𝚊𝚋 text, the Sindhi word [t͡ɕɔ̃kᶷ] ‘square, intersection’ appears in its graphematically underspecified form as |چؤنڪ|, with [ɔ] written as |◌ؤ|. In contrast, Mewaram (1910, p. 211), Lekhwani’s (1996, p. 57) and the SLA all list the word as |چَونڪُ|, in which [ɔ] is written |◌َو|. Allana (1993 [1964], pp. 117–118) and Lekhwani (1996, p. vi) consider | ◌َﺋِ ◌ؤ| and to be allographs in free variation.

Source: Arvind Iyengar
Similar variability is observed in the realisation of Sindhi [e], which may appear in 𝚜𝚍-𝙰𝚛𝚊𝚋 as |◌ٖي| or |◌يٖ|. In the post-Partition era, Pakistani 𝚜𝚍-𝙰𝚛𝚊𝚋 works have predominantly featured the former (Sindhi Language Authority, 2015b), while Indian 𝚜𝚍-𝙰𝚛𝚊𝚋 works have tended towards the latter (Lekhwani, 1996; 1997; Shahaney, 1967 [1906]; Varyani & Thakwani, 2003). Occasionally, though, a 𝚜𝚍-𝙰𝚛𝚊𝚋 work may depart from the trend typical of its location of publication, and feature cross-border practices instead. At the same time, the subsegmental element |◌ٖ| appears to be falling out of use on both sides of the border, even in fully graphovocalised texts. This has resulted in unintended graphematic standardisation, with Sindhi [e] being written simply as |◌ي| in most recent 𝚜𝚍-𝙰𝚛𝚊𝚋 publications (Lekhwani, 1996; 1997; Sindhi Language Authority, 2015b; Varyani & Thakwani, 2003). Graphetically, what distinguishes |◌ي| from visually similar graphs is the absence of a subsegmental graphetic component. Such distinctiveness-by-absence is reminiscent of the use of bare |ن| to indicate φ-vowel nasalisation. At the same time, the gradual exclusion of the element |◌ٖ| from |◌ي| is akin to the fading away of jazm from |ن|. In both instances, the elimination of the subsegmental graph may cause ambiguity and increase the system’s opacity.
Allography in representing φ-consonants primarily concerns [ɦ] and its written forms. With reference to Table 6.1, 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 denote the glottal fricative [ɦ] with the rasms |ه ﻫ ﻬ ﻪ|. The occurrence of these allographs or positional variants is conditioned by graphematic environment, putting the variants in mutually complementary distribution. In 𝚜𝚍-𝙰𝚛𝚊𝚋, however, consonantal [ɦ] is denoted by |ﮬ| in all graphematic positions (Dalwani, 2020; Kew, 2005; Motivational Skills By Sufi Shar, 2020; ScriptSource, 2022c). Moreover, 𝚜𝚍-𝙰𝚛𝚊𝚋 uses the rasm |ﻬ| as an invariant component in the digraphs |ﮔﻬ ﺟﻬ ﻣﻬ ﻧﻬ ﮢﻬ ﻟﻬ| [ɡʱ d͡ʑʱ mʱ nʱ ɳʱ lʱ] (see (9)) to denote φ-aspiration [ʱ]. Thus, in 𝚜𝚍-𝙰𝚛𝚊𝚋, the rasms |ﻬ ﮭ| cannot be considered allographic positional variants of the same underlying written unit. Certain 𝚜𝚍-𝙰𝚛𝚊𝚋 works adhere strictly to this allographic distinction (Lekhwani, 1996; NCPSL, 2005; 2014; 2015; Varyani & Thakwani, 2003). For instance, Lekhwani (1996) spells the word [d͡ʑəɦazᶷ] ‘ship’ as |جَھازُ|, using the rasm |ﮭ| to denote consonantal [ɦ]. In contrast, the headword [d͡ʑʱaɾᶦ] ‘flock of birds’ is transcribed |جهارِ|, where the rasm |ﻬ| marks aspiration. Extracts of these words as printed in Lekhwani (1996) are shown in Figure 6.6.
![[d͡ʑəɦazᶷ]](figures/Fig 6.6a.svg)
![[d͡ʑʱaɾᶦ]](figures/Fig 6.6b.svg)
ɦ] and |ﻬ| [ʱ]Source: Lekhwani (1996, pp. 62, 69)
However, adherence to these allographic distributions is by no means universal, and 𝚜𝚍-𝙰𝚛𝚊𝚋 texts may mix and match these rasms somewhat unpredictably. That is, a 𝚜𝚍-𝙰𝚛𝚊𝚋 text may use |ﻬ| to mark segmental [ɦ] (Shahaney, 1967 [1906], p. 9), or employ |ﻫ| to denote aspiration [ʱ] (Baloch, 1962; Lekhwani, 1997). This results in |ﮔﻬ ﺟﻬ| [ɡʱ d͡ʑʱ] appearing instead as |گھ جھ|, respectively. Figure 6.5 contains an example of this phenomenon in the word |جھمٽمل| [d͡ʑʱəməʈᵊməlᶷ], in which [d͡ʑʱ] is written as |جھ| instead of |ﺟﻬ|. Compounding matters is the fact that the rasms |و ر| do not join the following rasm (see Table 6.1). Consequently, the digraphs for [ɽʰ ʋʱ] almost always appear as |ڙھ وھ|, and hardly ever as |ڙﻬ وﻬ|. The appearance of the rasm |ھ| in the digraphs |ڙھ وھ| further muddies the waters when discussing the potential phonemic status of [ɽʰ ʋʱ] in Sindhi.
In addition, in 𝚜𝚍-𝙰𝚛𝚊𝚋, consonantal [ɦ] in word-final position may occasionally be written with the 𝚊𝚛-𝙰𝚛𝚊𝚋-style rasm |◌ﻪ|. Thus, the Sindhi word [ɦəmeɕəɦᵊ] ‘always’ is spelt by Lekhwani (1996, p. 194) as |هَميشَھَ|, but by Shahaney (1967 [1906], p. 21) as |هَميشَهَ|. The former spelling denotes final [ɦ] with |◌ﮫ|, while the latter uses |◌ﻪ|. No discernible patterns are observed behind such variation, and must be attributed to font limitations and idiosyncratic preference. Furthermore, in 𝚜𝚍-𝙰𝚛𝚊𝚋, the rasm |◌ﮧ| (see Table 6.1) is used word-finally in a handful of mostly monosyllabic words as a phonologically empty graph. Examples include |نَہ| [nə] ‘no’, |تَہ| [t̪ə] ‘that (complementiser)’, |بِہ| [bᶦ] ‘also’ and |جَئِہ| [d͡ʑɛ] ‘victory’. In such words, |◌ﮧ| is effectively ‘silent’, due to which it is sometimes termed imperceptible ‘h’ (Shahaney, 1967 [1906], pp. 21–22). However, the rasm |◌ﮧ| may sometimes be substituted with the 𝚊𝚛-𝙰𝚛𝚊𝚋-style rasm |◌ﻪ|. As a result, the 𝚜𝚍-𝙰𝚛𝚊𝚋 words listed above may appear as |نَه تَه بِه جَئِه|. This phenomenon is almost entirely restricted to electronic 𝚜𝚍-𝙰𝚛𝚊𝚋 texts, and is traceable to the absence of the appropriate Unicode character for |◌ﮧ| on 𝚜𝚍-𝙰𝚛𝚊𝚋 keyboards and input method editors (IMEs).
Thus, despite attempts by linguists, lexicographers and litterateurs to spin off 𝚊𝚛-𝙰𝚛𝚊𝚋 allographs into contrastive graphs in 𝚜𝚍-𝙰𝚛𝚊𝚋, universal acceptance has proven elusive. Yet, the allographic variation in the context of |ن| and |ﻫ| in 𝚜𝚍-𝙰𝚛𝚊𝚋 is not unique. A similar phenomenon is observed by Shackle (2007, p. 655) in the context of Arabic-script Punjabi (𝚙𝚊-𝙰𝚛𝚊𝚋). Despite proposals to standardise the use of |ن|, |ﻫ| and related graphs in 𝚙𝚊-𝙰𝚛𝚊𝚋, the forms in question continue to be used somewhat indiscriminately to denote disparate phonological values. Notwithstanding the variation described, its real-world impacts remain unclear. Sociolinguistically, the varying shapes of multigraphs like |ﮔﻬ ﺟﻬ| might be inconsequential to fluent readers of 𝚜𝚍-𝙰𝚛𝚊𝚋. Indeed, such readers may even fail to perceive the graphetic differences described above. However, the pedagogical impacts of such variation on learners of 𝚜𝚍-𝙰𝚛𝚊𝚋 are yet to be studied rigorously. The variation in question may also affect data sorting and collation. Moreover, it raises questions on whether the rasm |ﻬ|is potentially a grapheme in 𝚜𝚍-𝙰𝚛𝚊𝚋, or is simply a nongraphemic component of a multigraph.
Related to the subject of allography is that of calligraphic practice in and the visual appearance of 𝚜𝚍-𝙰𝚛𝚊𝚋. Typographically, 𝚜𝚍-𝙰𝚛𝚊𝚋 is characterised by the conventional use of the naskh calligraphic style (Shackle, 2014a). These features visually distinguish 𝚜𝚍-𝙰𝚛𝚊𝚋 from neighbouring Arabic-script-based writing systems such as 𝚞𝚛-𝙰𝚛𝚊𝚋, 𝚙𝚊-𝙰𝚛𝚊𝚋 and Kashmiri-Arabic (𝚔𝚜-𝙰𝚛𝚊𝚋), all of which are typically written and printed in the Nastaliq calligraphic hand. Although there is no graphematic restriction on 𝚜𝚍-𝙰𝚛𝚊𝚋 being written and printed in Nastaliq, doing so may be considered sociolinguistically anomalous (§2.6). Even within the Naskh style, 𝚜𝚍-𝙰𝚛𝚊𝚋 calligraphic tradition prefers certain rasmic forms, such as | ر م| over | ر م| (Gacek, 2009, pp. 318–319; ScriptSource, 2022d; SIL International, 2022; see also Table 6.1).
6.5.4 Spelling and orthography
As described earlier, the practice of omitting subsegmental graphs (see (6)) from quotidian 𝚜𝚍-𝙰𝚛𝚊𝚋 writing has perpetuated variability in when and how they manifest, even in scholarly works. For instance, the Sindhi word [d͡ʑɛɦᵋɽo] ‘which (correlative)’ is written in 𝚜𝚍-𝙰𝚛𝚊𝚋 without subsegmental graphs as |جھڙو|. However, if subsegmental graphs are to be included, their nature and position is unclear. Mewaram’s dictionary (1910, p. 181) graphovocalises |جھڙو| [d͡ʑɛɦᵋɽo] in two ways, |جِھَڙو| and |جَھِڙو|, and lists them as equivalent alternatives. In comparison, post-Partition publications suggest the emergence of a slight divergence in graphovocalisation based on geography. In Pakistan, the SLA’s online 𝚜𝚍-𝙰𝚛𝚊𝚋 dictionary (Sindhi Language Authority, 2021c) only lists the first form cited in Mewaram, namely |جِھَڙو|. In contrast, the Indian 𝚜𝚍-𝙰𝚛𝚊𝚋 dictionaries of Lekhwani (1996, p. 62) and Rohra et al. (2011, p. 201) only list the second one, |جَھِڙو|. The disagreement on the nature and position of subsegmental graphs in the underlying graphematic form of [d͡ʑɛɦᵋɽo] may have phonological implications. If |جِھَڙو| is considered the underlying form of the word, the implied phonemic makeup would be /d͡ʑɪɦəɽo/. In contrast, |جَھِڙو| maps on to /d͡ʑəɦɪɽo/.
Approaching the issue from a phonoprimary perspective proves similarly fraught. Although some scholars assert that all Sindhi words are phonemically vowel-final (§4.3.2), there is equivocation on whether this principle applies to recent loanwords that have entered the language. Consequently, it remains undecided whether an English-origin loanword like ‘mobile’ should be transcribed in 𝚜𝚍-𝙰𝚛𝚊𝚋 as |موبائِلۡ| or |موبائِلُ|. In terms of the underlying phonemic forms indicated, the former spelling denotes consonant-final /mobaɪ̯l/, while the latter spelling denotes vowel-final /mobaɪ̯lʊ/.
The question of the nature and position of subsegmental graphs also extends to the absence of a word-medial φ-vowel and its written representation. As Trumpp observes, in colloquial Sindhi speech, the lax φ-vowel [ɪ] freely alternates with post-consonantal [Ø] (§6.4). In the absence of established spellings, writers may graphovocalise 𝚜𝚍-𝙰𝚛𝚊𝚋 words based on their own speech. Consequently, a particular lexical item spelt by one author with zer |◌ِ| may be spelt by another with jazm |◌ۡ|. Allana (1993 [1964], pp. 137–145) recommends denoting post-consonantal [Ø] only with jazm |◌ۡ| and not with zer |◌ِ|. He recommends that the latter should be restricted to denote [ɪ]. However, this practice presupposes clarity on the underlying or phonemic makeup of words, which proves elusive.
In contrast to the equivocation on lax γ-vowels and subsegmental graphs in 𝚜𝚍-𝙰𝚛𝚊𝚋 spellings, the status of γ-consonants is far clearer thanks to their graphetic segmentality and graphematic obligatoriness. As seen in previous Sections, the graph inventories of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 have retained the majority of γ-consonant graphs from the 𝚊𝚛-𝙰𝚛𝚊𝚋 inventory, even when the phonological values of these graphs have changed or no longer contrast in Sindhi. In addition to graph retention, 𝚜𝚍-𝙰𝚛𝚊𝚋 also exhibits graphematic retention in retaining the source spellings of loanwords from the homoscriptal 𝚊𝚛-𝙰𝚛𝚊𝚋. This aligns with similar practice in 𝚏𝚊-𝙰𝚛𝚊𝚋 (§6.1). Share and Daniels (2016) refer to the retention of source spellings, even when phonologically unwarranted, as orthographic inertia. Pending agreement on the exact definition and scope of the term orthography, the alternative term graphematic inertia could be used. Illustrating the phenomenon of graphematic inertia is the 𝚊𝚛-𝙰𝚛𝚊𝚋 word |تعليم| ‘education’. In standard Arabic, this word is pronounced [tɑʕliːm]. This word has been borrowed into Sindhi, with its pronunciation indigenised to [t̪alimᵊ] or [t̪ɛlimᵊ]. However, its spelling in 𝚜𝚍-𝙰𝚛𝚊𝚋 has remained unchanged from the source 𝚊𝚛-𝙰𝚛𝚊𝚋 spelling. In general, Arabic and Persian loanwords that have entered Sindhi are assimilated phonologically but not graphematically. At most, there may be minor graphematic adaptations to align with Sindhi morphophonology. Such graphematic inertia sometimes serves a disambiguating purpose, as seen in Table 6.6.
Source: Lekhwani (1996)
| 𝚜𝚍-𝙰𝚛𝚊𝚋 spelling | Sindhi pronunciation | Gloss |
|---|---|---|
| مُدو | [mʊd̪o] |
‘time period’ |
| مُدعو | ‘issue, matter’ | |
| بَسَرُ | [bəsəɾᶷ] |
‘livelihood’ |
| بَصَرُ | ‘onion’ | |
| حالُ | [ɦalᶷ] |
‘condition, state’ |
| هالُ | ‘hall’ |
Graphematic inertia also means that the spellings of such loanwords in 𝚜𝚍-𝙰𝚛𝚊𝚋 take on a logographic dimension and may need to be memorised. This includes spellings that retain elements such as 𝚊𝚛-𝙰𝚛𝚊𝚋 |ال| [aɫ] ‘the’ and 𝚏𝚊-𝙰𝚛𝚊𝚋 |آباد| [ɒbɒd] ‘city, town’. Examples include 𝚜𝚍-𝙰𝚛𝚊𝚋 |بِالِڪُلِ| [bɪlᶦkʊlᶦ] ‘totally’ and |حَيدَرآبادُ| [ɦɛd̪əɾaba̪d̪ᶷ] ‘Hyderabad’. In these spellings, the occurrence of the strings |ال| and |آباد| are not entirely predictable based on their corresponding pronunciations, and must be explicitly learnt.
6.5.5 Logograms and collation order
Aside from logography arising from graphematic inertia, the most prominent logograms in present-day 𝚜𝚍-𝙰𝚛𝚊𝚋 are |۽| [ɛ̃ ~ əĩ] ‘and’, |۾| [mẽ] ‘in’ and |اللّٰه| ‘Allah’. The last logogram is also retained when part of a personal name, as in 𝚜𝚍-𝙰𝚛𝚊𝚋 |عبداللّٰه| [əbd̪ʊl(l)aɦᶷ] ‘Abdullah’. Other benedictory logograms related to the Islamic faith and borrowed from 𝚊𝚛-𝙰𝚛𝚊𝚋 may also appear in 𝚜𝚍-𝙰𝚛𝚊𝚋 texts, such as the basmala |﷽| ‘In the name of Allah, the compassionate, the merciful’. Notably, when fully graphovocalised within a 𝚜𝚍-𝙰𝚛𝚊𝚋 text, both |عَبۡدُاللّٰهُ| [əbd̪ʊl(l)aɦᶷ] and the invocation |بِاسۡمِاللّٰهِ| [bɪsmɪl(l)aɦᶦ] ‘In the name of Allah’ would feature the graphosegmental logogram |اللّٰه| together with the graphosubsegmental phonograms |◌ُ ◌ِ| [ʊ ɪ], respectively. As noted in Section 6.4.2, such co-occurrence — despite not being unique to 𝚜𝚍-𝙰𝚛𝚊𝚋 — is yet to be rigorously described and theorised.
On numerals, certain sources claim that present-day 𝚜𝚍-𝙰𝚛𝚊𝚋 comprises a subset of numeral graphs distinct from those in 𝚊𝚛-𝙰𝚛𝚊𝚋 (ScriptSource, 2022c; SIL International, 2022). However, this is far from clear-cut, and modern 𝚜𝚍-𝙰𝚛𝚊𝚋 publications may feature any combination of the Arabic-script numeral superset listed in (7). The variation in numeral graphs is comparable to that seen with the rasms |ﻬ ﮭ| in that a discernible pattern proves elusive. Salient punctuation graphs in the present-day 𝚜𝚍-𝙰𝚛𝚊𝚋 inventory include |. ⹁ ⁏ ⸮| as full stop, comma, semicolon and question mark, respectively (Priest Evans, 2020).
After a century and a half of variation in the collation order of 𝚜𝚍-𝙰𝚛𝚊𝚋, strides have been made towards standardisation in the recent past, especially in Pakistan. Baloch (2007, p. 10) uses the following sequence in the Jame Sindhi Lughat, which has also been adopted by the SLA in its 𝚜𝚍-𝙰𝚛𝚊𝚋 tutorials (Sindhi Language Authority, 2015b):
ا ( آ ) ب ٻ ڀ ت ٿ ٽ ٺ ث پ ج ڄ ﺟﻬ ڃ چ ڇ ح خ د ڌ ڏ ڊ ڍ ذ ر ڙ ز س ش ص ض ط ظ ع غ ف ڦ ق ڪ ک گ ڳ ﮔﻬ ڱ ل م ن ڻ و ﮪ ء ي
Compared to the collation orders followed by Mewaram and Grierson (§6.3.2), Baloch’s order differs mainly in the position of |ڦ| [pʰ], which now occurs after the graphetically similar |ف| [f] rather than after the phonologically similar |پ| [p]. Notably, it lists hamza |ء| as a distinct graph while subsuming |آ| under |ا|. In India, on the other hand, scholarly works continue to demonstrate slight variation in the 𝚜𝚍-𝙰𝚛𝚊𝚋 collation order. Below are a few collation orders used in works by prominent Indian Sindhi authors:
Hardwani (1991, p. x):
ا ب ٻ پ ڀ ت ٺ ٽ ث ٿ ک گ ڳ ڱ ﮔﻬ ف ڦ ر ز ڙ د ذ ڌ ڏ ڊ ڍ ح ج ڄ ڃ چ ڇ خ ع غ س ش ص ض ڪ ق ط ظ و ل م ن ڻ ﮪ ﺟﻬ ي ء
Lekhwani (1997, p. xii):
ا ب ٻ پ ڀ ت ٺ ٽ ث ٿ د ذ ڌ ڏ ڊ ڍ ج ڄ ڃ چ ڇ ح خ ر ڙ ز س ش ص ض ط ظ ع غ ف ڦ ق ڪ ک گ ڳ ﮔﻬ ڱ ل م ن ڻ و ﮪ ﺟﻬ ء ي
Varyani & Thakwani (2003, p. x):
ا ب ٻ پ ڀ ت ٺ ٽ ث ٿ ف ڦ گ ڳ ڱ ک ي د ذ ڌ ڏ ڊ ڍ ح ج ڄ ڃ چ ڇ خ ع غ ر ز ڙ م ن ل س ش و ق ص ض ڻ ط ظ ﮪ ﺟﻬ ﮔﻬ ڪ ء
Khubchandani (2007, p. 697):
ا ب ٻ ڀ ت ٿ ٽ ٺ ث پ ج ڄ ﺟﻬ ڃ چ ڇ ح خ د ڌ ڊ ڏ ڍ ذ ر ڙ ز س ش ص ض ط ظ ع غ ف ڦ ق ڪ ک گ ڳ ﮔﻬ ڱ ل م ن ڻ و ﮪ ي ء
Although the sort order by itself is typically not considered graphematically significant, idiosyncratic variation in this regard can have consequences for lexicographic works. In an increasingly digital world, it also has implications for computer-aided sorting.
6.6 Analysis
6.6.1 Graphematic typology
This chapter has shown that most 𝚜𝚍-𝙰𝚛𝚊𝚋 variants, but especially 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, provide for almost all φ-vowels in the Sindhi language — including the absence of a φ-vowel — to be explicitly indicated in writing. In this regard, the various 𝚜𝚍-𝙰𝚛𝚊𝚋 systems appear to have much in common with the various 𝚜𝚍-𝙳𝚎𝚟𝚊 systems that will be encountered in Chapter 7. Against this background, what should 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 be typologically categorised as? Is the label of ‘abjad’, traditionally applied to 𝚊𝚛-𝙰𝚛𝚊𝚋, appropriate for 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙? If not, is there is a case for revisiting the label of abjad for 𝚊𝚛-𝙰𝚛𝚊𝚋, too?
The label ‘abjad’ insinuates that the writing system in question comprises phonograms that solely or primarily denote φ-consonants, and leaves φ-vowels entirely or largely unmarked. However, as Table 6.2 reveals, the inventories of 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 comprise a comprehensive set of phonograms to explicitly indicate all φ-vowels in their target languages. While graphs for φ-vowels in 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 are usually omitted by choice, such omission is based on sociolinguistic discretion and not on graphematic limitations. The problematic nature of classifying 𝚊𝚛-𝙰𝚛𝚊𝚋, 𝚏𝚊-𝙰𝚛𝚊𝚋 and their daughter systems as abjads is neatly highlighted by Sproat’s (2010a, p. 53) deft example of |f u cn rd ths u cn b trnd as a scrtry nd gt a gd jb| (§5.1.1). Sproat’s example, transcribed in unstandardised 𝚎𝚗-𝙻𝚊𝚝𝚗, omits most non-initial γ-vowels when compared to its ‘fully-vowelled’ standardised version. Yet, most readers would hesitate to classify 𝚎𝚗-𝙻𝚊𝚝𝚗 as an abjad based on this example. At the same time, the very same readers might well accept the classification of 𝚊𝚛-𝙰𝚛𝚊𝚋, 𝚏𝚊-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙰𝚛𝚊𝚋 variants as abjads based on similar reasoning. The classification of several Arabic-script-based writing systems as abjads affirms the observation in Section 2.10 that writing systems are often assigned a particular graphematic label based on their sociolinguistic characteristics.
If 𝚊𝚛-𝙰𝚛𝚊𝚋, 𝚏𝚊-𝙰𝚛𝚊𝚋 and the major 𝚜𝚍-𝙰𝚛𝚊𝚋 variants described in this chapter are not abjads, then what graphematic type should they be categorised under? Since they are capable of denoting most or all φ-vowels in their target language, they should be considered vowelled segmentaries (Figure 2.2). The specific subtype of vowelled segmentary can be determined by addressing the questions underlying the classification in Figure 2.3, namely:
- Which postconsonantal φ-vowels can be graphematically represented?
- How are postconsonantal φ-vowels graphematically represented?
In 𝚊𝚛-𝙰𝚛𝚊𝚋, 𝚏𝚊-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, all φ-vowels in the target language can be reasonably represented in an overt manner, making these systems plenaries. Furthermore, in each of these systems, postconsonantal φ-vowels are represented in writing using bound allographs, making the systems alphasyllabaries. The latter finding aligns with Bright’s (1999, p. 50 footnote 2) classification of “fully pointed” or graphovocalised 𝚊𝚛-𝙰𝚛𝚊𝚋 and he-Hebr typologically alphasyllabic. Thus, in terms of graphematic type, 𝚊𝚛-𝙰𝚛𝚊𝚋, 𝚏𝚊-𝙰𝚛𝚊𝚋 and their derivatives 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, are all plenar alphasyllabaries.
At this juncture, it is worth noting that the distinction between an alphabet and an alphasyllabary in Figure 2.3 is based on γ-vowels in postconsonantal position showing up as bound allographs as opposed to their free forms. Here, the complementary distribution of the two allograph sets is graphematically determined, rather than graphetically. As shown for 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 in Table 6.5, the ‘free’ γ-vowel allographs are those formed by combining the ‘bound’ γ-vowel allographs |◌َ ◌ا ◌ِ ◌ِي ◌ُ ◌ُو ◌ي ◌َي ◌و ◌َو| [ə a ɪ iː ʊ u e ɛː o ɔː] with a vowel holder element as the graphetic base. Put differently, the classification of a γ-vowel as free or bound depends on whether the graphetic base is a phonologically ‘full’ one such as |ب| [b] or the phonologically empty alif or hamza. Hence, despite 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹’s free and bound γ-vowel allographs overlapping in their graphetic composition, their occurrence in distinct graphematically-conditioned patterns justifies the label ‘alphasyllabary’. Moreover, a similar pattern — albeit now obsolete — has been attested in 𝚜𝚍-𝙳𝚎𝚟𝚊 (§7.7.1, footnote 107), wherein a set of invariant graphetic elements that denote φ-vowels are combined with varying graphetic bases to form free and bound vowel allographs in complementary distribution. The fact that 𝚜𝚍-𝙳𝚎𝚟𝚊, too, is an alphasyllabary (§7.7.1) further vindicates classifying 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 as alphasyllabaries.
6.6.2 Graph inventory
In Section 2.2, a graph was defined as the basic unit of the written modality of language. According to this definition, every glottographic element counts as a graph, be it rasmic or graphetically complex in nature. Hence, ‘graph’ proves to be a useful catch-all term for a particular glottographic element, especially when its exact graphematic status is still uncertain.
Table 6.1 lists most of the rasms underlying the various 𝚜𝚍-𝙰𝚛𝚊𝚋 inventories. Most of them, such as |ٮ|, are underspecified and require further graphetic augmentation before potentially qualifying as phonograms in one or more of the 𝚜𝚍-𝙰𝚛𝚊𝚋 inventories. Thus, the rasm |ٮ| needs to be augmented with dots or nuqtas — as in |ب پ ت ث ٽ ٺ| — in order to become identifiable with a particular linguistic value and approach phonogram status.
Yet, determining which rasms and augmented graphs in the various 𝚜𝚍-𝙰𝚛𝚊𝚋 inventories qualify as graphemes in those inventories proves tricky. Per Meletis’ (2020, pp. 94–96) criteria outlined in Section 2.5, a graph needs to be minimal, contrastive and have linguistic value in order to qualify as a grapheme in a particular writing system. The rasm |ٮ| is not a grapheme as it is devoid of linguistic value. However, do the various nuqta patterns added to this rasm qualify as graphemic? That is, are |◌﮳ ◌﮶ ◌﮹ ◌﮽| graphemic in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 or 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙? Arguing in the affirmative proves to be an uphill task, since these nuqta patterns are not associated with identifiable linguistic values of any kind. In fact, Meletis (2020, p. 294) himself suggests that nuqtas in Arabic-script inventories are not graphemes per se, but simply “distinguishing features” that serve to “heterogenize” rasms. Thus, despite nuqtas in the 𝚜𝚍-𝙰𝚛𝚊𝚋 inventories — and Arabic-script inventories in general — creating contrast, evidence is thin for them qualifying as graphemes in themselves. In acting as nongraphemic distinguishing features, nuqta patterns share certain characteristics with phonological features such as aspiration.
Subsegmental graphs in 𝚜𝚍-𝙰𝚛𝚊𝚋 such as |◌َ ◌ِ ◌ُ| [ə ɪ ʊ] can safely be considered graphemes, as they neatly satisfy the three graphemic criteria. Their graphosubsegmentality does not prejudice their grapheme status (Meletis, 2020, p. 96 footnote 102). The sukun |◌ْ| and jazm |◌ۡ| also make the cut as potential graphemes, thanks to their linguistic value of [ᶦ ~ Ø]. The jury is still out on tashdid |◌ّ|, as its eligibility for grapheme status will depend on whether φ-consonant gemination is considered a ‘linguistic value’.
Curiously, it is segmental graphs whose grapheme status proves the most vexing. Prima facie, a graph like alif |ا| may be considered rasmic and linguistically underspecified, becoming fully specified only when combined with a suitable γ-vowel. At the same time, |◌ا| is used as the bound γ-vowel for [a], as in |با| [ba]. Moreover, in modern 𝚜𝚍-𝙰𝚛𝚊𝚋, certain authors may denote the Sindhi phonological sequence [ba] with the 𝚊𝚛-𝙰𝚛𝚊𝚋-style graphematic sequence |بَا| (Table 6.2). Allana (1993 [1964], p. 113 footnote) explicitly recommends against this practice in modern 𝚜𝚍-𝙰𝚛𝚊𝚋, but it remains unclear what the specific rule — if any — is on representing the φ-vowel [a] in postconsonantal position. As evident, the verdict on |◌َا| as a legitimate graphematic sequence in 𝚜𝚍-𝙰𝚛𝚊𝚋 to denote [a] will affect the grapheme status of alif |ا| per se. If one considers the fully specified bound γ-vowel form of [a] to be |◌َا|, bare alif |ا| becomes linguistically underspecified and, hence, nongraphemic. But if one follows Allana’s recommendation and writes the bound γ-vowel for [a] as bare alif |◌ا| without |◌َ|, it would make bare alif a grapheme. This conundrum highlights the crucial definitional role played by orthography in determining graphemes within a particular system.
A similar dilemma is encountered when using rasms to form γ-consonants. At first glance, one may assume that a graph like |د|, with linguistic value [d̪], satisfies the three criteria of minimality, contrast and linguistic value and, accordingly, attains grapheme status. However, a closer investigation throws a spanner into the works. Given the presence of sukun or jazm in the inventories of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, one may argue that, strictly speaking, the linguistic value [d̪] is actually denoted by a combination of |د| and jazm — namely |دۡ|. Adopting this stance would make |د| a linguistically underspecified form that becomes fully specified only when combined with a suitable bound γ-vowel or jazm. However, if an orthographic rule were to be introduced that eliminates jazm from the 𝚜𝚍-𝙰𝚛𝚊𝚋 inventory with no replacement, bare |د| would ostensibly acquire the linguistic vale of [d̪] and, hence, graduate to grapheme status. This situation reiterates how the status of a graph as a grapheme is conditioned by the specific orthographic module in play within the relevant writing system. Overall, these findings reaffirm the existence of graphemes at the level of writing system, and not at the level of script.
A comparably intricate issue is the status of the graphetic element |ﻬ| and its alternative form |ﻫ|, which in theory denotes aspiration [ʱ] in [ɡʱ d͡ʑʱ]. Building on Figure 6.6, If one argues that the authentic written forms of [ɡʱ d͡ʑʱ] are |ﮔﻬ ﺟﻬ|, and that |گھ جھ| are incorrect, then |ﻬ| emerges as a grapheme distinct from |ﻫ|. However, and as described in Section 6.5, vacillation between these graph sets is widespread. On this basis, if the two sets are simply considered free variants of each other, the elements |ﻬ| and |ﻫ| would emerge as allographs of each other in more-or-less free variation. Constraining and regulating the alternation would require appropriate orthographic specification, thereby reiterating the salience of a system’s orthographic module in determining its graphemes.
What about the status of |ﻬ| and |ﻫ| in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙? Since 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 is based on the 𝚞𝚛-𝙰𝚛𝚊𝚋 graph inventory, it deviates from 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 in consistently indicating phonological aspiration [ʰ ʱ] by adding a graphetic element to the unaspirated form of γ-consonants. However, the graphetic element may appear either as |ﻬ| or as |ﻫ| (Figure 6.3), albeit in complementary distribution conditioned by the graphetic properties of the previous and following graphs. Hence, |ﻬ| and |ﻫ| do not seem to be graphemes in 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 either, although one may argue that they are allographs of the same grapheme.
The analysis in this subsection shows that the orthography plays a crucial role in determining not only the specific subset of graphs that constitutes the inventory of a particular writing system, but also which graphs within the inventory are deemed to be graphemes. At any rate, the graph inventory and orthography are inextricably linked, with changes in one impacting the other. By extension, a graph potentially acquires grapheme status only in the context of a particular writing system and, often, in the presence of an identifiable orthography. Graphemes do not exist in a vacuum, or even at the script level. Consequently, in order to reliably bestow grapheme status to elements in the various 𝚜𝚍-𝙰𝚛𝚊𝚋 variants described in this Chapter, one needs to first address related questions on the structure of a writing system and its constituent modules, particularly orthography. As it turns out, the answers to these questions will require further scholarly debate and consensus. Thus, reliably identifying graphemes in the various 𝚜𝚍-𝙰𝚛𝚊𝚋 systems described here will have to remain a topic for future research.
6.6.3 Graphematics and orthography
So far, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 have simply been referred to by the generic label ‘(sub)variant’. In the context of the Modular Theory (MT), are each of the above variants distinct graphematic systems? Or are they better characterised as distinct orthographies? Furthermore, and to the extent the above variants qualify as orthographies, which of them are systematic and which conventional?
Unlike orthographies imposed in the context of European writing systems, graphematic or orthographic specifications in the context of 𝚜𝚍-𝙰𝚛𝚊𝚋 — especially 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 — was gradual and organic, taking place over decades. Moreover, in the twenty-first century, the contemporary avatar of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 exhibits elements of a top-down orthography — as in the spellings of certain words — that coexist with variable elements such as the graphetic composition of γ-vowels. Although such idiosyncratic variation within the graphematic solution space has been described in Section 6.5, it is yet to be rigorously incorporated into and accounted for by suitable descriptive-analytical frameworks.
A latent theme emerging from the description in Section 6.5 is that of subtly differing graphematic practices between Pakistani and Indian 𝚜𝚍-𝙰𝚛𝚊𝚋 use. This observation prompts one to ask whether they should be considered distinct 𝚜𝚍-𝙰𝚛𝚊𝚋 subvariants or orthographies. In other words, is there an argument to be made for the existence of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝙿𝙺 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝙸𝙽 based on mutual graphematic differences? Although initial evidence may point in that direction, additional evidence is desirable. For instance, there exist geographic tendencies in whether the bound γ-vowels for [i u] appear as |◌ِي ◌ُو| or |◌يِ ◌وُ|, but they remain tendencies and are far from being firmly established. Indeed, writing practices characteristic of one region are often found in the other, sometimes in works by the same author or even in the same text. In any event, identifying and grouping distinct patterns in writing practice requires guidelines on how different the patterns need to be from each other. Even if sufficient evidence emerges for the existence of distinct 𝚜𝚍-𝙰𝚛𝚊𝚋-𝙿𝙺 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝙸𝙽 subvariants, the question remains on what they should be termed as — graphematic systems, orthographies, or something else. These questions reinforce the inextricable intertwining of the graphematic and orthographic modules with the graph inventory, including in matters of graphetic composition as illustrated by |◌ِي ◌ُو| and |◌يِ ◌وُ|.
6.6.4 Logography
In contrasting phonography with logography, Section 2.8 cited the examples of 𝚎𝚗-𝙻𝚊𝚝𝚗 ⟨deer⟩ and ⟨dear⟩ (Gnanadesikan, 2017a, p. 15), wherein two homophonous lexical items are distinguished by distinct spellings. Both spellings are licensed by 𝚎𝚗-𝙻𝚊𝚝𝚗’s graphematic solution space, but remain somewhat arbitrary selections. With regard to the Japanese writing system, particularly the Kanji inventory, Honda (2021, p. 628) notes that the correspondence between individual Kanji characters and phonological elements in the Japanese language “relies entirely on conventional orthography”. In other words, there is a strong logographic element in the selection of Kanji to represent certain Japanese-language morpholexical items. Honda’s observation on the somewhat arbitrary graph-phone correspondences seen in logographic writing is consistent with that of Sproat and Gutkin (2021, pp. 5–7), who note that logography is characterised by the notion of different words being spelt differently, even if phonologically similar.
An impressionistic appraisal of the logographic element in 𝚜𝚍-𝙰𝚛𝚊𝚋, particularly 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 in its post-Partition stage of evolution, places it in a league similar to 𝚎𝚗-𝙻𝚊𝚝𝚗. As seen in Table 6.6, the use of distinct elements and sequences in the written representations of words is helpful in lexico-semantic disambiguation, particularly when γ-vowels may be omitted. However, the instances of 𝚜𝚍-𝙰𝚛𝚊𝚋 logography seen in Table 6.6 are distinct from those in, say, Japanese-Kanji, in that they result from organic historical phonological mergers and accompanying graphematic inertia than from planned top-down orthographic decisions. As elaborated in the paragraphs preceding Table 6.6, 𝚜𝚍-𝙰𝚛𝚊𝚋 features numerous instances of graphematic retention from 𝚊𝚛-𝙰𝚛𝚊𝚋, of which several pairs of graphematically distinct lexical items happen to be realised homophonously in spoken Sindhi. Comparing and contrasting different types of logography across writing systems is a fruitful area of research, for which Sproat and Gutkin (2021) propose an innovative method of measurement.
6.6.5 Sociolinguistics
Chapter Six has shed light on how, over the centuries, individual 𝚜𝚍-𝙰𝚛𝚊𝚋 variants simultaneously possessed areas of graphematic clarity and ambiguity. The findings in this chapter also corroborate the MT’s view on the orthographic module being a theoretically optional component of a writing system, and reiterate the cosmetic nature of standardised collation orders and related finishing touches. Yet, despite orthography and standardisation being understood as optional in scholarly circles, they assume importance for lay users. This is particularly true under contemporary sociolinguistic mores, under which literacy is prized and written languages are accorded greater cultural value than oral ones (Coulmas, 2014, p. 1; Fishman, 1997, p. 154). Moreover, as Bunčić (2016a, p. 16) states, “the invention of the printing press made people think that every language had (and had to have) a uniform orthography”. Jaffe echoes this sentiment in observing that:
it is not only important [from the layperson’s perspective] to have an orthography, but it is also critical for that orthography to have prescriptive power – to be standardised and authoritative […]
Consequently, in a literate society, standardisation or lack thereof in matters of orthography, graph inventory and collation order add to or detract from the popular image of a language. Subtle variation in writing practices may not impact proficient readers of 𝚜𝚍-𝙰𝚛𝚊𝚋. However, such variation does carry ramifications for 𝚜𝚍-𝙰𝚛𝚊𝚋 pedagogical material, including dictionaries and primers. In this regard, the lack of orthographic prescriptivism may negatively impact learners of 𝚜𝚍-𝙰𝚛𝚊𝚋. Ambiguity over spelling-related minutiae may seem insignificant in isolation, but may cumulatively result in learner frustration and consequent loss of motivation. Moreover, in a modern world where orthographic consistency is highly regarded and variability disparaged, a writing system devoid of a prescriptive orthographic module may be looked down upon and deemed unrefined. Subjective impressions of defectiveness and crudeness may also be weaponised, as evinced by the arguments against 𝚜𝚍-𝙰𝚛𝚊𝚋 in post-Partition India (§5.3). The real-world sociolinguistic significance of an orthographic module, therefore, exists in a tension with its supposed graphematic dispensability.
7 Devanagari
The twentieth century saw the rise of 𝚜𝚍-𝙰𝚛𝚊𝚋 as the preeminent writing system for Sindhi, whose position was further cemented following Partition (§5.3). At the same time, Partition also resulted in the rise of a writing system that remains the only one to have noticeably challenged 𝚜𝚍-𝙰𝚛𝚊𝚋’s sociolinguistic status in recent times. Recognised by the Indian government as co-official with 𝚜𝚍-𝙰𝚛𝚊𝚋, Sindhi-Devanagari (𝚜𝚍-𝙳𝚎𝚟𝚊) has, since Partition, seen a remarkable rise in interest among scholars and laypersons alike. The writing system has also been at the core of a vigorous and often acrimonious script debate in post-Partition India, with some of its supporters seeking to establish it as the sole official writing system of Sindhi in India. As a result, 𝚜𝚍-𝙳𝚎𝚟𝚊 has been the topic of much academic and popular debate, resulting in the spread of fact as well as fiction on the writing system’s graphematics and historical sociolinguistics.
7.1 Graphematic foundations
Despite being graphetically unstandardised and graphematically variable, early 𝚜𝚍-𝙳𝚎𝚟𝚊 writing was broadly based on a Sanskrit-Devanagari (𝚜𝚊-𝙳𝚎𝚟𝚊) canonical template. Consequently, all 𝚜𝚍-𝙳𝚎𝚟𝚊 variants, whether historical or contemporary, align with 𝚜𝚊-𝙳𝚎𝚟𝚊’s graphematic typology in being abugidic and alphasyllabic in nature. In the post-Partition era, writing practices from Hindi-Devanagari (𝚑𝚒-𝙳𝚎𝚟𝚊) have also significantly influenced those in 𝚜𝚍-𝙰𝚛𝚊𝚋. Table 7.1 contains a selection of 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊 phonograms that form the graphematic foundation of 𝚜𝚍-𝙳𝚎𝚟𝚊. Like Table 6.2, Table 7.1 is also designed as a matrix, with γ-consonants shown along the vertical axis and γ-vowels along the horizontal axis. The intersection of a row and column contains the graph representing the corresponding phonological [CV] sequence.
Table 7.1 reveals several graphe(ma)tic similarities between 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊 on the one hand, and 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 on the other (see Table 6.2). In all these systems, γ-consonants occupy their own segmental space and can occur on their own. In contrast, the γ-vowels | ा ि ी ु ू े ै ो ौ| and the graph |्| [Ø] can only occur together with a γ-consonant.98 Hence, the dichotomous description of 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 γ-consonants and γ-vowels as “basic letters” and “diacritics”, respectively (Bauer, 1996) has also been applied to 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊 γ-consonants and γ-vowels (Bright, 1996, p. 376).
[table]
However, the two sets of writing systems differ slightly when it comes to denoting φ-[CV] sequences. In most Devanagari-based writing systems, there exists one φ-vowel which, when occurring after post-consonantally, is represented implicitly in writing, without any overt graphetic element. This φ-[V] is commonly known as the ‘default’ or ‘inherent’ vowel, denoted here by φ-[V₀]. The phonological quality of [V₀] varies with language. In 𝚜𝚊-𝙳𝚎𝚟𝚊, φ-[V₀] is [a], whereas in 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙳𝚎𝚟𝚊, it is [ə] (§4.3.2). Thus, 𝚜𝚊-𝙳𝚎𝚟𝚊 [ba] and 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙳𝚎𝚟𝚊 [bə] are denoted simply by |ब|, where the presence of postconsonantal φ-[V₀] is implied by the absence of a corresponding graph. As a result, graphs denoting φ-[CV₀] are considered graphematically primary or ‘basic’ (Bright, 1996, p. 376). A φ-[CV] sequence is denoted by combining the graph for φ-[CV₀] with the appropriate bound γ-vowel. Thus, |बी| [bi(ː)] is obtained by concatenating |ब| [ba ~ bə] and |ी| [i(ː)]. A pure φ-[C] with no subsequent φ-vowel is written with the corresponding graph for φ-[CV₀] combined with |्|. While the graph |्| may be known by different names depending on the language, it is increasingly referred to by the generic term virama in the context of Indic scripts.99 In acting as a ‘vowel killer’, the virama is the Indic counterpart of the Arabic sukun. Alternatively, in some instances, a pure φ-[C] may be written with a graphetically ‘truncated’ allograph. Thus, [b] may appear as |ब्| or |ब्◌|, conditioned by graphetic factors, the graphematic environment and orthographic guidelines. Additionally, the writing system — or, more precisely, its orthography — may, in certain environments, permit the use of a graph denoting φ-[CV₀] to also denote φ-[C]. For instance, 𝚑𝚒-𝙳𝚎𝚟𝚊 allows the use of |ब| [bə] to denote [b] in specific word positions, especially finally. The motivation behind this graphematic practice is the phonological rule of schwa deletion (see Table 4.5). However, the practice also adds a layer of opacity to 𝚑𝚒-𝙳𝚎𝚟𝚊’s graph-phone correspondences compared to the biunique mappings of 𝚜𝚊-𝙳𝚎𝚟𝚊.
Outside of a φ-[CV] sequence, a φ-[V] by itself, which includes φ-[V₀], is written with a distinct set of γ-vowel allographs, |अ आ इ ई उ ऊ ए ऐ ओ औ|. These allographs can occur on their own and occupy their own graphosegmental space. For nomenclatural convenience, graphs denoting φ-[CV₀], such as |ब| [ba ~ bə], will be referred to as free forms of γ-consonants. Similarly, |अ आ इ ई उ ऊ ए ऐ ओ औ| will be termed the free allographs of γ-vowels. Graphetically truncated or ‘half’ forms such as |ब्◌| [b], as well as the ‘diacritics’ |ा ि ी ु ू े ै ो ौ| will be called bound γ-consonants and γ-vowels, respectively. As a bound graph, the virama |्| [Ø] bears similarities to the bound γ-vowels. To sum up, in 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊, free graphs such as |ब| or |ई| can occur on their own, and are comparable to the Isolated forms of 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋. Bound graphs such as |ब्◌| or |ी| can only occur together with a free graph as the graphe(ma)tic base, and may be subject to additional orthographic restrictions. Generally, multiple bound graphs cannot co-occur on the same base. Exceptions include the chandrabindu or anunasika |ँ|, the anusvara |ं| and the visarga |ः|.100
The chandrabindu is rare in 𝚜𝚊-𝙳𝚎𝚟𝚊 but widely used in 𝚑𝚒-𝙳𝚎𝚟𝚊. In the latter system, the graph is used to denote the nasalisation suprasegmental on a φ-vowel. Graphematically, the chandrabindu is written above a free or bound graph. However, if competing for segmental space with another supralinear graphetic element, the chandrabindu may be visually truncated and appear identically to anusvara |ं|, as shown in (10):
(10)
| 𝚑𝚒-𝙳𝚎𝚟𝚊 graph | अँ | आँ | इँ | ईं | उँ | ऊँ | एँ | ऐं | ओं | औं |
| Phonological value | ə̃ | ã | ɪ̃ | ĩ | ʊ̃ | ũ | ẽ | ɛ̃ | õ | ɔ̃ |
| 𝚑𝚒-𝙳𝚎𝚟𝚊 graph | कँ | काँ | किँ | कीँ | कुँ | कूँ | कें | कैं | कों | कौं |
| Phonological value | kə̃ | kã | kɪ̃ | kĩ | kʊ̃ | kũ | kẽ | kɛ̃ | kõ | kɔ̃ |
For consistency and ease, some 𝚑𝚒-𝙳𝚎𝚟𝚊 writers may denote φ-vowel nasalisation in all instances by the anusvara-style |ं|. Such use may clash with the use of anusvara |ं| to denote other phonological values. Used only occasionally in 𝚜𝚊-𝙳𝚎𝚟𝚊 but extensively in 𝚑𝚒-𝙳𝚎𝚟𝚊, the anusvara indicates the nasal segment in a homorganic nasal-oral φ-consonant cluster. Coupled with its use as an allograph of chandrabindu, the phonological values of anusvara in 𝚑𝚒-𝙳𝚎𝚟𝚊 encompass [ŋ (ɲ) ɳ n n̪ m ◌ ̃], with its precise value determined from written context. At the same time, the nasal φ-consonants [ŋ (ɲ) ɳ n n̪ m] may also be written with the allographs |ङ् ञ्◌ ण्◌ न्◌ म्◌| (see Table 7.1). The sequences listed in (11), all of which adhere to 𝚑𝚒-𝙳𝚎𝚟𝚊 graphematic principles, illustrate how the anusvara may be homophonous with |ङ् ञ्◌ ण्◌ न्◌ म्◌| depending on written environment:
(11)
| Anusvaric spelling | Alternative spelling | Hindi pronunciation 101 |
|---|---|---|
| अंक | अङ्क | əŋk |
| अंच | अञ्च | ənt͡ɕ |
| अंट | अण्ट | əɳʈ |
| अंत | अन्त | ən̪t̪ |
| अंप | अम्प | əmp |
| अंश | अन्श | ənɕ |
| अंस | अन्स | əns |
The examples in (11) show that the presence of anusvara allows for some homophonous heterography when representing nasal-oral φ-consonant clusters in 𝚑𝚒-𝙳𝚎𝚟𝚊. This property has led scholars to describe the anusvara as a graphematic abbreviation of sorts for a nasal γ-consonant. Such descriptions have ranged from the terse “shorthand notation” (Salomon, 2007, p. 84) to the poetic “compendium scripturæ” (Grierson, 1881, p. 2). However, individual writing systems may prefer one spelling over the other. For instance, spellings with overt nasal γ-consonants are more frequent in 𝚜𝚊-𝙳𝚎𝚟𝚊. In 𝚑𝚒-𝙳𝚎𝚟𝚊, [ɳ n m] may appear either as |ण्◌ न्◌ म्◌| or as |ं|. However, [ŋ ɲ] only rarely appear as |ङ् ञ्◌|, and are almost always written using with |ं|. This graphematic distribution is likely due to [ɳ n m] being phonemic in Hindi, with [ŋ ɲ] only surfacing as allophones of [n]. Ultimately, though, the final choice of spelling is determined by various factors, including word etymology and personal preference. Also playing a part is the sociolinguistic prestige of Sanskrit in South Asia, which may induce some 𝚑𝚒-𝙳𝚎𝚟𝚊 writers to prefer the 𝚜𝚊-𝙳𝚎𝚟𝚊-style spellings (Salomon, 2007, p. 84).
The final bound graph in this class, the visarga |ः|, is frequently found in 𝚜𝚊-𝙳𝚎𝚟𝚊, where it denotes syllable-final [ɦ]. It is rare in 𝚑𝚒-𝙳𝚎𝚟𝚊, and found only in Sanskrit borrowings in formal registers.
The inventory of γ-consonants also includes several graphs that are commonly termed ‘ligatures’ despite being rasmically distinct. As outlined in Section 2.7, a graph based on a distinct rasm but representing a φ-consonant cluster is often termed a ligature. Thus, the motivation behind classifying such graphs as ligatures is not their written manifestation but their spoken values. In 𝚑𝚒-𝙳𝚎𝚟𝚊, commonly occurring graphs in this category include |क्ष त्र ज्ञ श्र क्त| [kɕ(ə) t̪ɾ(ə) ɡj(ə) ɕɾ(ə) kt̪(ə)]. Of these, |क्ष त्र ज्ञ| are commonly listed in 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊 symbol charts, but not |श्र क्त| or others.
In terms of typographical preference, certain rasms or graphs may be preferred over others as allographs. Although phonologically inconsequential, the choice of allographs may be semiotically loaded (Salomon, 2007, p. 84). The allographs in question, grouped by their indexical associations, are shown in (12).
(12)
| ‘Traditional’ allograph | ‘Modern’ allograph | Hindi pronunciation |
|---|---|---|
| अ आ ओ औ… | अ आ ओ औ… | ə a o ɔ… |
| ख | ख | kʰ(ə) |
| झ झ | झ | d͡ʑʱ(ə) |
| ण | ण | ɳ(ə) ⁓ ɽ̃(ə) |
| ल | ल | l(ə) |
| श | श | ɕ(ə) |
| क्ष | क्ष | kɕ(ə) |
| त्र | त्र | t̪ɾ(ə) |
Notwithstanding the indexical associations mentioned in (12), it is common to see allographs from both styles featured in a particular Devanagari-script text, whether due to idiosyncratic preference or typographical limitations. There may also be writing traditions that draw in a predictable manner from both groups of allographs. For instance, contemporary Marathi-Devanagari (𝚖𝚛-𝙳𝚎𝚟𝚊) texts tend to feature modern-style |अ ख झ ण क्ष| but traditional-style |ल श त्र|.
In the twentieth century, the 𝚑𝚒-𝙳𝚎𝚟𝚊 graph inventory has been augmented to unambiguously denote Hindi phones absent in Sanskrit, as well as to mark certain Perso-Arabic-origin phones that have been absorbed into Hindi phonology. Graphetically, the new graphs have been created by augmenting existing ones with a subfixed nuqta, as shown in (13):
(13)
| क़ | ख़ | ग़ | ज़ | फ़ | ड़ | ढ़ |
| q(ə) | x(ə) | ɣ(ə) | z(ə) | f(ə) | ɽ(ə) | ɽʱ(ə) |
While graphs for Hindi-specific phones absent from Sanskrit have been added to 𝚑𝚒-𝙳𝚎𝚟𝚊’s inventory, the converse has not occurred. Graphs for Sanskrit-specific phones absent from Hindi, such as |ऋ ृ| [ɾ̩] and |ष| [ʂ] have not been deleted from 𝚑𝚒-𝙳𝚎𝚟𝚊’s inventory and are retained as they are. Such graphematic inertia is reminiscent of similar practice in 𝚏𝚊-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙰𝚛𝚊𝚋, wherein 𝚊𝚛-𝙰𝚛𝚊𝚋 graphs and spellings are retained near-unchanged (§6.5.4). Masica opines that the graphematic inertia observed in South Asian writing systems based on the Arabic and Devanagari scripts is motivated by the liturgical nature of the principal languages associated with these scripts — Arabic and Sanskrit, respectively:
[R]edundant Arabic graphemes (with no attempt at distinctive articulation) are preserved in the spelling of Arabic loanwords in most languages using the Perso-Arabic script, just as redundant Neo-Brahmi letters are preserved in the spelling of Sanskrit loanwords in most languages using Neo-Brahmi scripts – although there are more such letters in Perso-Arabic. Attempts to simplify the orthographies by spelling words as they sound […] have occasionally been made, but have not met with general acceptance, since the Arabic language is as sacrosanct for Muslims as Sanskrit is for Hindus.
The seemingly sacrosanct nature of 𝚜𝚊-𝙳𝚎𝚟𝚊 has also encouraged the retention of certain benedictory logograms, particularly |ॐ| [om] (§2.8). Punctuation graphs in 𝚜𝚊-𝙳𝚎𝚟𝚊 are minimal, with the salient ones being the sentence separator |।| and paragraph separator |॥|. In 𝚑𝚒-𝙳𝚎𝚟𝚊, which follows punctuation principles similar to those in 𝚎𝚗-𝙻𝚊𝚝𝚗, |।| has been repurposed as a full stop. However, other modern Devanagari-script-based writing systems such as 𝚖𝚛-𝙳𝚎𝚟𝚊 have replaced |।| with Roman-script |.| Overall, most punctuation graphs commonly used in modern 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚖𝚛-𝙳𝚎𝚟𝚊 have been borrowed from the Roman-script inventory, such as |, ; ? !|. Numeral graphs in the Devanagari inventory, along with prevalent allographic forms, are shown in (14). As with the phonographic allographs shown in (12), the choice of numeral allograph may be conditioned by various graphematic and sociolinguistic factors, and defies neat prediction.
(14)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 |
|---|---|---|---|---|---|---|---|---|---|
| १ | २ | ३ | ४ | ५ ५ |
६ | ७ | ८ ८ |
९ ९ |
० |
Modern Sindhi-Devanagari (𝚜𝚍-𝙳𝚎𝚟𝚊) makes use of many of the graphs and writing practices described above, while also deviating from them in places. Moreover, 𝚜𝚍-𝙳𝚎𝚟𝚊 also features certain unique practices. Details of 𝚜𝚍-𝙳𝚎𝚟𝚊’s graphematic makeup, along with its historical evolution, follow in the sections below.
7.2 Early use
As outlined in Section 5.1, script inventories graphetically resembling present-day Devanagari forms have been used to write Sindhi and related speech varieties for at least two centuries, if not more. Prominent instances of early 𝚜𝚍-𝙳𝚎𝚟𝚊 use are seen in the works of Qazi Qadan and Pran Nath. That said, the use of 𝚜𝚍-𝙳𝚎𝚟𝚊 experienced noticeable spikes in use at two distinct moments in time, the first immediately following the British annexation of Sindh in the mid-1800s, and the second following Partition in 1947. The first surge in 𝚜𝚍-𝙳𝚎𝚟𝚊 writing was driven largely by British and European interest in Sindhi, typically with administrative or Christian-missionary aims in mind. One of the earliest such 𝚜𝚍-𝙳𝚎𝚟𝚊 publications dates from 1834, when parts of the Bible’s Gospel of Matthew were translated into Kutchi (ISO-639 𝚔𝚏𝚛) and transcribed using Devanagari (Nida, 1972, p. 212). Graphematically, the writing system in question is not 𝚜𝚍-𝙳𝚎𝚟𝚊 but 𝚔𝚏𝚛-𝙳𝚎𝚟𝚊. The 𝚔𝚏𝚛-𝙳𝚎𝚟𝚊 extract is reproduced and retranscribed in Figure 7.1.

- 1 When he [Jesus] saw the crowds he went up the mountain. He sat down and his disciples joined him.
- 2 He started to teach them, saying:
- 3 Fortunate are the spiritually poor, for theirs is heaven’s kingdom.
- 4 Fortunate are the grieving, for they shall be consoled
- 5 Fortunate are the kindly, for they shall be given the world.
Source: Bagster (1851, plate V)
Apart from the now-archaic spellings, Figure 7.1 features at least two noteworthy graphematic practices. The first is the use of |ष ख| as freely varying allographs of each other. In 𝚜𝚊-𝙳𝚎𝚟𝚊, |ष| has the linguistic value [ʂ(a)], and |ख| has the value [kʰ(a)]. However, Figure 7.1 features the 𝚔𝚏𝚛-𝙳𝚎𝚟𝚊 spellings |षुदा| [kʰʊd̪a ~ xʊd̪a] ‘god’ (5:3) and |षुश| [kʰʊɕ ~ xʊɕ] ‘happy’ (5:4) on the one hand, and |सीखा| [sɪkʰa ~ sikʰa] ‘teaching’ (5:2) on the other. The practice of using |ष ख| in a mutually substitutable manner was common among Devanagari-based writing systems used in north-western South Asia, until at least the early twentieth century (Mandal, 2021). In 𝚜𝚍-𝙳𝚎𝚟𝚊, this convention was also followed by George Stack (§7.3).
The second noteworthy graphematic practice in Figure 7.1 is the contrastive use of |ॸ| [ɖ(ə)] and |ड| [ɽ(ə), ɽʱ(ə)]. Viewed against a modern-day Kutchi pronunciation, verse 1 reads as follows:
|एं ऊ माडू एं जी मंढली ॸिसी हिकडे ॸूंगरतें चडी वियो एं जॸें ऊ वेठो उनज चेला उन वट आया|
[ẽ u maɽu ẽ d͡ʑi məɳɖ(ʱ)ᵊli ɖɪsi ɦɪkᵊɽe ɖũɡəɾᵊt̪ẽ t͡ɕəɽ(ʱ)i ʋɪjo ẽ d͡ʑəɖẽ u ʋeʈʰo ʊnᵊd͡ʑᵊ t͡ɕela ʊnᵊ ʋəʈᵊ aja]
Here, the Kutchi words |ॸिसी| [ɖɪsi] ‘having seen’, |ॸूंगरतें| [ɖũŋɡəɾᵊt̪e] ‘on a mountain’ and |जॸें| [d͡ʑəɖɛ̃] ‘when’ feature the graph |ॸ| for [ɖ(ə)].103 In contrast, |माडू| [maɽu] ‘men, people’, |हिकडे| [ɦɪkᵊɽe] ‘a, one’ and |चडी| [t͡ɕəɽ(ʱ)i] ‘having climbed’ feature |ड| for [ɽ(ə) ~ ɽʱ(ə)]. Graphematically, such contrastive use of |ॸ| [ɖ(ə)] and |ड| [ɽ(ə)] is most closely associated with Devanagari-script Marwari (𝚖𝚠𝚛-𝙳𝚎𝚟𝚊), although |ॸ| fell out of use in 𝚖𝚠𝚛-𝙳𝚎𝚟𝚊 by the early twentieth century (Pandey, 2010b). Despite unclear graphetic origins, Pandey speculates that |ॸ| may be derived from a homoglyphic and homophonic graph in the Sharada script traditionally used for Kashmiri (Pandey, 2005; 2010b, p. 3). Graphematically, the use of distinct graphs for [ɖ] and [ɽ] in Kutchi has parallels in other writing systems for Kutchi, particularly Khojki (see Chapter 10).
Aside from the graphematic significance of individual graphs and their linguistic values, the 𝚔𝚏𝚛-𝙳𝚎𝚟𝚊 extract also proves sociolinguistically significant. As the compiler, Samuel Bagster, notes in his work:
A translation of the Gospel of St. Matthew into Cutchee [i.e., Kutchi] was executed by the late Rev. James Gray, one of the chaplains at Bombay; and in 1835 a small edition, consisting of 500 copies, was printed. This edition was, however, found to be of little or no service, from the circumstance of its being issued in the [Devanagari] character, with which the people of Cutch are unacquainted.
Thus, the 𝚔𝚏𝚛-𝙳𝚎𝚟𝚊 specimen in Figure 7.1 may not be reflective of actual in-group or emic usage. This is consistent with the observation that, in the nineteenth century, it was Europeans who were the primary drivers and users of Sindhi-Kutchi in Devanagari. Exemplifying such etic use of 𝚜𝚍-𝙳𝚎𝚟𝚊 are the works of grammarian, lexicographer and translator, George Stack.
7.3 George Stack’s system
The first book-length works to feature Sindhi written in Devanagari were the pioneering grammar and dictionaries of Captain George Stack, a military officer in the East India Company. Initially posted to Bombay in 1843–44 shortly after the Company’s annexation of Sindh, Stack began acquainting himself with the Hindustani and Sanskrit languages during his tenure there. In 1845, he was transferred to Hyderabad, Sindh, as Deputy Collector, following which he acquired a remarkable level of proficiency in Sindhi within a relatively short time (Encyclopedia Sindhiana, n.d., p. 7130). By March 1847, he had prepared a grammar of Sindhi, which, however, went to press only in 1849 (Stack, 1849a, p. vii). Besides containing several pages of “Stories for Exercise” in typeset 𝚜𝚍-𝙳𝚎𝚟𝚊 (pp. 134–153), Stack’s grammar also contains extensive samples of handwritten 𝚜𝚍-𝙳𝚎𝚟𝚊. Stack’s grammar was accompanied by an English-Sindhi dictionary (1849b), followed by a posthumously-published Sindhi-English dictionary (1855).
Stack’s rationale for choosing Devanagari to transcribe Sindhi is outlined in the introduction to his grammar (§5.2.1). To reiterate, Stack opts for Devanagari since it was the script most familiar to British officers of the East India Company. To Stack, the fact that Devanagari was not widely used for the language by Sindhis themselves was apparently of less importance. Barrow Ellis corroborates this sentiment in his foreword to Stack’s Sindhi-English dictionary (1855):
The reasons which induced Captain Stack to print in the Devanagri [sic] character he has slightly touched on in his Preface to the English and Sindhi dictionary. Lest his views be misunderstood I may mention that he frequently assured me, that he adopted the character merely as one generally known to those officers who might be supposed to be the persons most likely to use these books — and not with any view to its permanent adoption by Sindhis. Had I myself been required to decide the point, I do not think I should have adopted the same character, but it was obviously better to act and do something which might be useful to a large class of students, than to talk and wait for the termination of an apparently interminable controversy to settle a Sindhí character for universal adoption.
To be borne in mind is the fact that the above foreword was published after the official adoption of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹, in which Ellis himself played a key role (§6.3). Notwithstanding the etic use of Devanagari, Stack’s 𝚜𝚍-𝙳𝚎𝚟𝚊 system was largely consistent across his works, and subject only to minor variations. Such consistency was all the more noteworthy given that Stack’s 𝚜𝚍-𝙳𝚎𝚟𝚊 system was largely an ex-nihilo creation, without precedent to refer to:
I have had considerable difficulty in fixing the Orthography. Many of the words I have given will be found to be pronounced and written very differently by different persons. I have tried to choose the most common forms of spelling, or to follow the general manner of pronunciation, without at the same time going into actual vulgarisms; but my choice was very arbitrary, and it will doubtless be thought that I am often incorrect.
Following the IETF format for language tags, Stack’s Sindhi-Devanagari system will be referred to as 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔. Table 7.2 provides an overview of the graph inventory and graph-phone correspondences of 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 as listed in Stack’s (1849a) grammar.
Source: Stack (1849a, pp. 3–8)
| अ | आ | इ | ई | उ | ऊ | ए | ऐ | ओ | औ |
| ə | a | ɪ | i | ʊ | u | e | ɛ | o | ɔ |
| क | ख | ग | ग़ | घ | ङ | च | छ | ज | ज़ | झ | ञ |
| k(ə) | kʰ(ə) | ɡ(ə) | ɠ(ə) | ɡʱ(ə) | ŋ(ə) | t͡ɕ(ə) | t͡ɕʰ(ə) | d͡ʑ(ə) | ʄ(ə) | d͡ʑʱ(ə) | ɲ(ə) |
| ट | ट़ | ठ | ड | ड़ | ॾ | ढ | ण |
| ʈ(ə) | ʈɾ(ə) | ʈʰ(ə) | ɽ(ə) | ɖ(ə) | ɖɾ(ə) | ɖʱ(ə) | ɳ(ə) |
| त | थ | द | ध | न | प | फ | ब | ब़ | भ | म |
| t̪(ə) | t̪ʰ(ə) | d̪(ə) | d̪ʱ(ə) | n(ə) | p(ə) | pʰ(ə) | b(ə) | ɓ(ə) | bʱ(ə) | m(ə) |
| य | र | ल | व | श | ष | स | ह |
| j(ə) | ɾ(ə) | l(ə) | ʋ(ə) | ɕ(ə) | ɕ(ə) | s(ə) | ɦ(ə) |
Table 7.2 reveals that the γ-vowels in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 are derived from 𝚜𝚊-𝙳𝚎𝚟𝚊 in terms of linguistic values and graphotactic behaviour. The latter aspect is especially evident in the complementary distribution of free and bound γ-vowel allographs (Stack, 1849a, p. 127). In terms of γ-consonants, Table 7.2 shows that 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 does not contain separate graphs for the φ-consonants [q x ɣ z f]. This is consistent with Stack’s intention to spell Sindhi words according to “the general manner of pronunciation, without […] going into actual vulgarisms” (1849b, p. iv; see also quote above). Thus, Stack spells Sindhi [komᵊ] ‘tribe, race’ as |कोम| (1855, p. 68). Compare this spelling with the modern 𝚜𝚍-𝙳𝚎𝚟𝚊 spelling |क़ौम| (Rohra, Bijani, & Gurnani, 2011, p. 115), which reflects the pronunciation [qɔmᵊ]. Nevertheless, given that the everyday pronunciation of the word is [komᵊ], the newer spelling |क़ौम| may actually be considered an etymologically-inspired spelling (cf. Arabic [qawm] ‘ibid.’). On the other hand, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 does provide for separate graphs for implosive [ɠ(ə) ʄ(ə) ɗ(ə) ɓ(ə)]: |ग़ ज़ ड़ ब़|, respectively. However, |ड़| is also used to denote plosive [ɖ(ə)]. Stack deems it unnecessary to graphematically differentiate implosive [ɗ(ə)] and plosive [ɖ(ə)], claiming that “the distinction though plain to Natives, is not at first apparent to European ears, and is of little importance” (1849b, p. 9 footnote). Stack’s graphematic underdifferentiation of [ɖ(ə)] and [ɗ(ə)] has been criticised by Lepsius (1863, pp. 105–106) and Trumpp, with the latter terming the underdifferentiation “very embarrassing” (1858, p. iii) and “a great mistake” (1872, p. 16). According to Trumpp, “[a] Sindhi will never confound [ɖ(ə)] and [ɗ(ə)]; they are in his mouth thoroughly distinct from each other” (1872, p. 16).104
Despite conflating [ɖ(ə)] and [ɗ(ə)], 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 represents [ɽ(ə)] distinctly, with undotted |ड|. Thus, the pattern of graphematically distinguishing (im)plosive |ड़| [ɗ(ə) ɖ(ə)] from the approximant |ड| [ɽ(ə)] bears similarities to that seen in Figure 7.1, in which |ॸ| [ɗ(ə) ɖ(ə)] is graphematically distinguished from |ड| [ɽ(ə)]. Furthermore, Stack’s system represents aspirate [ɖʱ(ə)] with |ढ|, but writes [ɽʱ(ə)] with the graph sequence |ड्ह|. Noteworthy is the use of distinct graphs |ट़ ॾ| for the φ-clusters [ʈɾ(ə) ɖɾ(ə)], respectively, which Stack justifies by citing similar practice in Sindhi-Khudawadi (𝚜𝚍-𝚂𝚒𝚗𝚍).105 By extension, [ɖʱɾ(ə)] is written |ढ़|. It is conceivable that the distinct representation of [ʈɾ(ə) ɖɾ(ə)] in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 inspired similar practice in Trumpp’s system (§7.4).
Although listed as a distinct graph in the inventory, Sanskritic |ष| is hardly used in Stack’s grammar (1849a, pp. 8, 127) and English-Sindhi dictionary (1849b). However, |ष| appears occasionally in his Sindhi-English dictionary (1855), as in the entries |संतोखु, संतोषु| [sən̪t̪okʰᶷ, sən̪t̪oɕᶷ] ‘contentment’ (p. 385) and |कष्टु| [kəɕʈᶷ] ‘wretchedness, misery’ (p. 50). In contrast, Stack’s English-Sindhi Dictionary (1849b) only lists |संतोखु| (p. 26), and lacks an entry corresponding to |कष्टु|. Phonologically, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔’s equating of the graphs |ष ख| reflects the phonological merger of Sanskritic retroflex [ʂ] with New Indo-Aryan [kʰ] (Grierson, 1881, p. 3; Masica, 1991, p. 105). Also, while |ष| is marginal in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔, it is altogether absent from 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 (see Figure 6.3; see also Section 6.4, p. 163).
To represent φ-nasalisation, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 provides for the use of the anunasika graph |ँ|, also known as chandrabindu. In his English-Sindhi dictionary (1849b, p. 10), Stack claims to use the anunasika distinctly from the anusvara |ं|, restricting the latter to denoting a φ-nasal homorganic with the following φ-obstruent. However, his works reveal somewhat vacillating use of these graphematic devices. The Sanskritic graphs |ऋ ृ| [ɾ̩] and |ः| [ɦ] (see Table 7.1) are absent from 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔.
In terms of graphetic form and typography, Stack’s (1849a) grammar features different allographs in print and handwriting. The φ-vowel [ə] and the φ-consonants [d͡ʑʱ(ə) ɳ(ə)] are printed as |अ झ ण|, but handwritten as |अ झ ण|, respectively. Also, while the print samples indicate [ɽʱ(ə)] with |ड्ह|, the handwritten samples feature the form |ड्ह|. Figure 7.2 shows the handwritten forms of |चाड्ह्याईं| [t͡ɕaɽʱᶦjãĩ] ‘he/she raised’ and |झूनाग़ड्हु| [d͡ʑʱunaɠəɽʱᶷ] ‘Junagadh (a region of present-day Gujarat)’ as they appear in Stack’s work.


Source: Stack (1849a, Appendix, pp. 3, 14)
Overall, graphetic combinations of γ-consonants or so-called ligatures are widely attested in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔, although Stack (1849b, p. 128) specifies that such graphetic combination or ligation is optional. This is affirmed by the freely varying use of atomic |ड्ह| and ligated |ड्ह| for [ɽʱ(ə)].
Stack also translated the Biblical Gospel of Matthew into Sindhi using 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔, which was published in 1850 (Grierson, 1919, p. 13; Nida, 1972, p. 393).
7.4 Ernest Trumpp’s system
Following closely in the heels of 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 was an alternative graph inventory and graphematic system for 𝚜𝚍-𝙳𝚎𝚟𝚊, designed by Ernst Trumpp. Aside from the graph inventory of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, Figure 6.3 and Figure 6.4 also feature that of 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, with linguistic values shown in Lepsius’ Standard Alphabet. Trumpp’s system differs from Stack’s in very minor ways, almost entirely in the domains of γ-consonants and their phonological values. The distinctions in graph-phone correspondences between 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 and 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 are shown in (15):
(15)
The examples in (15) reveal that, at least for the graphs in question, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 was somewhat more regular than 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔. Graphetically, though, the use of |ॾ| for [ɗ(ə)] disrupts the visual harmony in the set of γ-implosives |ग़ ज़ ॾ ब़|. The Sanskritic graphs |ऋ ष ः| along with any bound forms (see Table 7.1) are excluded from 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, although Trumpp (1872, p. 18) acknowledges Stack’s sporadic use of |ष|. Similar to 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 uses both |ँ| and |ं| to denote φ-vowel nasalisation in a somewhat arbitrary manner. In terms of graphetic features, Figure 6.4 shows the 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 γ-vowel inventory with [ə a o ɔ] represented by |अ आ ओ औ|, respectively. These forms may be considered allographs in free variation with |अ आ ओ औ|, respectively. Similar to 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 features the distinctive four-dot graph |⁛| as a full stop or sentence separator (§6.4).
As with 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 was apparently not used by any author other than its creator. At most, the system was employed as a transliteration or transcription in the odd scholarly work, most notably in Grierson (1919). Building on Trumpp (1858, p. vi) and Lepsius (1863, p. 103), Grierson (1919, p. 22) augments the 𝚜𝚍-𝙳𝚎𝚟𝚊 repertoire as shown in (16):
(16)
| Devanagari graph | 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 | 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 | 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 (Grierson, 1919) |
|---|---|---|---|
| अ़ | – | – | ʕ(ə) |
| क़ | – | – | q(ə) |
| ख | – | – | x(ə) |
| ग़ | ɠ(ə) | ɠ(ə) | ɠ(ə) |
| ज़ | ʄ(ə) | ʄ(ə) | ʄ(ə) |
| ट | ʈ(ə) | ʈ(ə) | ʈ(ə) |
| ट़ | ʈɾ(ə) | – | – |
| ट्र | – | ʈɾ(ə) | ʈɾ(ə) |
| ड | ɽ(ə) | ɖ(ə) | ɖ(ə) |
| ड़ | ɖ(ə), ɗ(ə) | ɽ(ə) | ɗ(ə) |
| ॾ | ɖɾ(ə) | ɗ(ə) | ɽ(ə) |
| ड्र | – | ɖɾ(ə) | ɖɾ(ə) |
| ड्ह ड्ह | ɽʱ(ə) | – | – |
| ढ | ɖʱ(ə) | ɖʱ(ə) | ɖʱ(ə) |
| ढ़ | ɖʱɾ(ə) | ɽʱ(ə) | ɽʱ(ə) |
| ढ्र | – | ɖʱɾ(ə) | ɖʱɾ(ə) |
| फ़ | – | – | f(ə) |
| ब़ | – | – | ɓ(ə) |
| ष | ɕ(ə) ~ kʰ(ə) | – | – |
| स़ | – | – | sˁ(ə) |
| ह़ | – | – | ħ(ə) |
As evident from (16), Grierson reverts to the 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 paradigm of using |ग़ ज़ ड़ ब़| for the φ-implosives [ɠ(ə) ʄ(ə) ɗ(ə) ɓ(ə)], and redeploys |ॾ| for [ɽ(ə)]. Notably, Grierson adds the graphs |स़ ह़ ख़ (स़) अ़ फ़ क़| as canonical equivalents of 𝚊𝚛-𝙰𝚛𝚊𝚋 (left-to-right) |ث ح خ (ص) ع ف ق|, respectively. He also uses these graphs in his 𝚜𝚍-𝙳𝚎𝚟𝚊 text samples (1919, pp. 99, 107), making it a rare instance of 𝚊𝚛-𝙰𝚛𝚊𝚋 |ث ح ص ع| being distinctly and reversibly transliterated in 𝚜𝚍-𝙳𝚎𝚟𝚊 running text. Despite his eye for detail, deviations from the above norms are found in Grierson’s work.106 Yet, they remain few in number, and might well be unintended typographical errors. Grierson also replaces the four-dot sentence separator |⁛| with the 𝚜𝚊-𝙳𝚎𝚟𝚊-style sentence separator |।| (§7.1).
7.5 Post-Partition practices107
In early twentieth-century Sindh, as 𝚜𝚍-𝙰𝚛𝚊𝚋 became increasingly adopted as the primary writing system for Sindhi, publications in 𝚜𝚍-𝙳𝚎𝚟𝚊 remained limited in number. However, Partition gave 𝚜𝚍-𝙳𝚎𝚟𝚊 a new lease of life. As outlined in Section 5.3, a considerable support base for 𝚜𝚍-𝙳𝚎𝚟𝚊 began to emerge in post-Partition India, leading to official recognition as well as increasing standardisation of the writing system. However, several areas of graphematic variation continue to persist in 𝚜𝚍-𝙳𝚎𝚟𝚊.
In the post-Partition era, almost all 𝚜𝚍-𝙳𝚎𝚟𝚊 publications have originated from India. Pakistani 𝚜𝚍-𝙳𝚎𝚟𝚊 publications are most likely to be of a pedagogical nature, and published by linguistic or literary institutions such as the Sindhi Language Authority (Hussain, 2011). Such publications exhibit graphematic regularity and variation in line with Indian 𝚜𝚍-𝙳𝚎𝚟𝚊 publications.
7.5.1 Graph inventory
Steps towards standardising 𝚜𝚍-𝙳𝚎𝚟𝚊’s graph inventory began in the early 1950s. Since Hindi and Sindhi share their phonologies to a large extent, the 𝚑𝚒-𝙳𝚎𝚟𝚊 graph inventory was implicitly adopted as the basis for 𝚜𝚍-𝙳𝚎𝚟𝚊. On the suggestion of linguist Suniti Kumar Chatterji, the Sindhi implosives [ɠ(ə) ʄ(ə) ɗ(ə) ɓ(ə)] began to be written |ॻ ॼ द॒ ॿ| (National Archives of India, 2018b, pp. 362–363). Of these, |द॒| has since been replaced by |ॾ|. However, Chatterji’s suggestion of representing the free γ-vowels as |अ आ अि अी अु अू अे अै ओ औ|, with |अ| used as a rasmic base akin to 𝚜𝚍-𝙰𝚛𝚊𝚋’s alif |ا|, did not meet with similar success.108 Efforts towards graphematic standardisation in 𝚜𝚍-𝙳𝚎𝚟𝚊 were buttressed by vigorous Sindhi-language literary activity in the two decades immediately after Partition. Described as defying expectations (Lekhwani, personal communication, December 8, 2014), such literary activity further stimulated the publication of several 𝚜𝚍-𝙳𝚎𝚟𝚊 lexicographic (Hardwani, 1991; Lekhwani, 1996; Rohra, Bijani, & Gurnani, 2011) and pedagogical works (Lekhwani, 1997; Varyani & Thakwani, 2003). These events and publications have cumulatively precipitated a gradual standardisation of the 𝚜𝚍-𝙳𝚎𝚟𝚊 graph inventory and, to a lesser extent, its graphematic practices.
Yet, 𝚜𝚍-𝙳𝚎𝚟𝚊’s journey thus far towards standardisation has not been smooth, nor has it been exhaustive. Just as the 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 graph inventories and graphematic practices exert pressure on 𝚜𝚍-𝙰𝚛𝚊𝚋, so too do 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊 influence 𝚜𝚍-𝙳𝚎𝚟𝚊. This results in the retention of graphs from the former inventories in 𝚜𝚍-𝙳𝚎𝚟𝚊, even when phonologically superfluous in the context of modern spoken Sindhi (Khubchandani, 2007, p. 699). Thus, the 𝚜𝚊-𝙳𝚎𝚟𝚊 free graphs |ऋ ष| (Sanskrit: [ɾ̩ ʂa]) and their bound allographs |ृ ष्◌| are pronounced [ɾɪ ɕ(ə)], respectively, making them homophonous with 𝚜𝚍-𝙳𝚎𝚟𝚊 |रि श|. Similarly, 𝚜𝚊-𝙳𝚎𝚟𝚊 |ज्ञ| [ɟɲə] is realised in 𝚜𝚍-𝙳𝚎𝚟𝚊 as [ɡjə], identically to |ग्य|. Certain authors may choose to retain the Sanskritic |ऋ ष ज्ञ| and their allographs in their 𝚜𝚍-𝙳𝚎𝚟𝚊 work, while others may opt for the phonologically more transparent |रि श ग्य|. Also inherited in the 𝚜𝚍-𝙳𝚎𝚟𝚊 inventory are modified graphs for the Perso-Arabic phones [q x ɣ z f] (see (13)). Based on the precedent of 𝚑𝚒-𝙳𝚎𝚟𝚊, the 𝚜𝚍-𝙳𝚎𝚟𝚊 inventory features |क़ ख़ ग़ ज़ फ़| for [q(ə) x(ə) ɣ(ə) z(ə) f(ə)], created by subfixing a nuqta to |क ख ग ज फ| [k(ə) kʰ(ə) ɡ(ə) d͡ʑ(ə) pʰ(ə)]. However, [q x ɣ z f] are unstable in modern Indian Sindhi and vary unpredictably with [k kʰ ɡ d͡ʑ pʰ] (§4.3.1). As a result, popular or casual 𝚜𝚍-𝙳𝚎𝚟𝚊 writing may substitute underdotted |क़ ख़ ग़ ज़ फ़| with the graphetically simpler |क ख ग ज फ|. Scholarly works in 𝚜𝚍-𝙳𝚎𝚟𝚊 usually retain the underdotted forms |क़ ख़ ग़ ज़ फ़|, although they may allude to their near-homophony with |क ख ग ज फ| to various extents. For instance, a 𝚜𝚍-𝙳𝚎𝚟𝚊 primer published by the NCPSL (Varyani & Thakwani, 2003, p. x) explicitly considers |क़ क| to be homophonous, with both pronounced [k(ə)]. The Indian Institute of Sindhology (Rohra, Bijani, & Gurnani, 2011) has attempted to lay down guidelines on the status and use of homophonous graphs in 𝚜𝚍-𝙳𝚎𝚟𝚊 (§7.6).
Comparing homophonous graphs in 𝚜𝚍-𝙰𝚛𝚊𝚋 with 𝚜𝚍-𝙳𝚎𝚟𝚊, it emerges that such instances are fewer in 𝚜𝚍-𝙳𝚎𝚟𝚊. In contrast, the distribution and use of homophonous graphs in 𝚜𝚍-𝙳𝚎𝚟𝚊 writing appears more unpredictable. Such variation has implications for 𝚜𝚍-𝙳𝚎𝚟𝚊 lexicography. For instance, the Sanskrit-derived Sindhi lexical root [ʋɪɡjanᶷ] ‘science’ is spelt |विज्ञानु| in one dictionary (Lekhwani, 1996, p. 168) but |विग्यानु| in another (Hardwani, 1991, p. 442). Moreover, differences in graph inventory may also be seen in works by the same author. In most of his 𝚜𝚍-𝙳𝚎𝚟𝚊 works, Hardwani (1991; 2013) lists and uses the underdotted graphs |क़ ख़ ग़ ज़ फ़ ड़ ढ़| [q(ə) x(ə) ɣ(ə) z(ə) f(ə) ɽ(ə) ɽʱ(ə)] (see (13)). However, in a more recently published primer (Hardwani, 2017), he only includes |ड़ ढ़| as part of the 𝚜𝚍-𝙳𝚎𝚟𝚊 inventory, and excludes augmented graphs to denote phones of Perso-Arabic origin. In the foreword to his (2017) publication, Hardwani writes:
मां देवनागरी सिंधी खे अरबी सिधीअ खां अलॻ भाषा समुझंदो आहियां, छो त ॿिन्ही जी अखरमाला अलॻ-अलॻ आहे ऐं शब्द-भंडारु पंहिंजे पंहिंजे नमूने जो आहे. […] इन करे हिन किताब में अरबी सिंधी अखरमाला वारा ख़, ग़, ज़, फ़ वर्ण या अखर कोन खंया विया आहिनि. ऐं इएं करण सां सिंधी भाषा पढ़ण-लिखण में कोई अड़चन पैदा कान थींदी. देवनागरी सिंधीअ जी हीअ पंहिंजी वर्णमाला / अखरमाला आहे.
I consider Devanagari-Sindhi to be a separate language [sic] from Arabic-Sindhi, since their letter inventories and vocabularies are distinct. […] Accordingly, the Arabic-Sindhi-inspired letters ख़, ग़, ज़, फ़ are omitted from this book. Doing so does not create any difficulties in reading and writing the Sindhi language. After all, this letter inventory is intrinsic to Devanagari-Sindhi.
Hardwani’s motivation for omitting |क़ ख़ ग़ ज़ फ़| based on semiotic connotations rather than on phonological grounds exemplifies the kinds of graphosociolinguistic battles permeating the Sindhi script debates in post-Partition India (§5.3). That said, while Hardwani is upfront about his ideological stance, not all 𝚜𝚍-𝙳𝚎𝚟𝚊 writers are. As a result, it is often unclear whether grapholinguistic practices seen in a particular 𝚜𝚍-𝙳𝚎𝚟𝚊 publication are attributable to sociolinguistic ideology, technological limitations or plain human oversight.
7.5.2 Graphematic allography
In the early years after Partition, as efforts towards standardising the 𝚜𝚍-𝙳𝚎𝚟𝚊 inventory were in still in its infancy, it was common to see a large degree of allography in 𝚜𝚍-𝙳𝚎𝚟𝚊 publications involving the sets shown in (12)(14) and (14). The most frequent instances of allography involved the phonograms for [ə d͡ʑʱ(ə) ɳ(ə) l(ə) ɕ(ə)], whose forms alternated between the ‘traditional’ forms |अ झ ण ल श| and their ‘modern’ counterparts |अ झ ण ल श|, respectively. Less frequently, variation was also seen between the free γ-vowel forms |ए| and |अे|, both denoting [e]. Other allographic sets in free variation involved graphs denoting φ-consonant clusters, such as |क्त ष्ट्र| and |क्त ष्ट्र| for [kt̪(ə) ɕʈɾ(ə)]. Although not allography per se, homophonous heterography was also seen in the depiction of [ɳ n̪ m] in a φ-consonant cluster either with an anusvara |ं| or with the bound allographs |ण्◌ न्◌ म्◌|. Notably, variation was often ‘free’ to the extent that the allographs in question often appeared in the same publication, on the same page, or even within the same sentence, with no evident conditioning factors. Table 7.3 features such instances of free variation from three 𝚜𝚍-𝙳𝚎𝚟𝚊 publications from the 1960s: a work of fiction (Bhambhani, 1964), a work of non-fiction (Jagtiani, n.d.) and a government-sanctioned school textbook (Maharashtra State Board of Secondary Education, 1967).
|
|अ अ| |
|
|
|ए अे| |
(Maharashtra State Board of Secondary Education, 1967, pp. 13, 17) |
|
|ण ण| |
(Jagtiani, n.d., p. ix; Maharashtra State Board of Secondary Education, 1967, p. 18) |
|
|ण ण| |ं म्◌| |
|
|
|ल ल| |
|
|
|ष्ट्र ष्ट्र| |
|
|
|श श| |क्त क्त| |
|
|
|क्त क़्त क्त क़्त| |
|
|
|ं न्◌| |ख़्श क्ष| |
(Maharashtra State Board of Secondary Education, 1967, pp. 3, 12) |



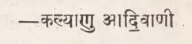














Notwithstanding the allographic variability demonstrated in Table 7.3, the publications in question were consistent in featuring |द॒| [ɖ(ə)]. This graph was subsequently supplanted by |ॾ|. One of the texts (Maharashtra State Board of Secondary Education, 1967) also writes [ɛ̃] consistently as |अैं|, an allograph that has since given way to |ऐं|.
The use of anusvara |ं| has since become the preferred graphematic option in modern 𝚜𝚍-𝙳𝚎𝚟𝚊 to indicate [ɳ n̪ m] in a homorganic nasal-oral φ-consonant cluster. At the same time, the use of anusvara to indicate nasalisation of a φ-vowel has also become conventionalised in 𝚜𝚍-𝙳𝚎𝚟𝚊, with chandrabindu |ँ| becoming implicitly deprecated. As with 𝚑𝚒-𝙳𝚎𝚟𝚊 (see (10)), the polyvalent use of anusvara introduces opacity into an otherwise relatively transparent writing system. For instance, a nonfluent reader of Sindhi may decode 𝚜𝚍-𝙳𝚎𝚟𝚊 |नांगु| either as [nãɡᶷ] or as [naŋɡᶷ], both of which are plausible. Similarly, |हंसु| may be justifiably interpreted either as [ɦə̃sᶷ] or as [ɦənsᶷ]. However, the ‘correct’ or desired pronunciations are [nãɡᶷ] and [ɦənsᶷ], meaning ‘cobra’ and ‘swan’, respectively. Given the lack of graphematic cues, retrieving the intended phonological forms requires the reader to be proficient in spoken Sindhi.
7.5.3 Spelling and orthography
Despite 𝚜𝚍-𝙳𝚎𝚟𝚊’s overall similarity to 𝚑𝚒-𝙳𝚎𝚟𝚊, the two differ in certain aspects. One of the key areas of difference concerns the representation of lax φ-vowels [ə ɪ ʊ] in certain word positions, in which they often manifest as their reduced allophones [ᵊ ᶦ ᶷ]. As a phonological feature, reduced φ-vowel allophones are largely absent from most other languages written using Devanagari, including Hindi.109 However, due to the greater sociolinguistic prominence of 𝚑𝚒-𝙳𝚎𝚟𝚊, readers may decode 𝚜𝚍-𝙳𝚎𝚟𝚊 while applying the graphematic and orthographic rules of 𝚑𝚒-𝙳𝚎𝚟𝚊, leading to ill-formed results.
As outlined in Section 7.1, the inherent φ-[V₀] in 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙳𝚎𝚟𝚊 is [ə]. However, aside from some Sanskrit neologisms, Hindi phonotactics do not permit [ə] in word-final position (Gumperz, 1958, p. 216) or in a [VC_CV] phonological environment (see the Indo-Aryan schwa deletion rule in Table 4.5). Consequently, in 𝚑𝚒-𝙳𝚎𝚟𝚊, writers abstain from explicitly denoting the absence of [ə] in these word positions, say, by affixing a virama onto a φ-[CV₀] graph, or by using the appropriate bound form of the φ-[CV₀] graph. Thus, in 𝚑𝚒-𝙳𝚎𝚟𝚊, [ə] is left graphematically unsuppressed in word-final and φ-[VC_CV] environments, as the phonotactics of Hindi preclude [ə] from occurring in these positions. A fluent reader of 𝚑𝚒-𝙳𝚎𝚟𝚊 is implicitly aware of this orthographic practice, and mentally suppresses [ə] where required when decoding 𝚑𝚒-𝙳𝚎𝚟𝚊 text. In contrast, Sindhi phonotactics permit [ə] in word-final and φ-[VC_CV] environments, usually in its reduced form [ᵊ]. Hence, if a reader unwittingly applies 𝚑𝚒-𝙳𝚎𝚟𝚊 orthographic conventions when decoding 𝚜𝚍-𝙳𝚎𝚟𝚊, they may end up erroneously suppressing [ə]. Table 7.4 lists certain homographic words common to 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊. Despite their identical spelling and meaning, the words differ in pronunciation in terms of final [ə].
| 𝚑𝚒-𝙳𝚎𝚟𝚊 & 𝚜𝚍-𝙳𝚎𝚟𝚊 spelling | Hindi pronunciation | Sindhi pronunciation | Gloss |
|---|---|---|---|
| तार | [t̪aɾ] |
[t̪aɾᵊ] |
‘wire’ |
| ख़बर | [xəbəɾ] |
[xəbəɾᵊ] |
‘news’ |
| ज़मीन | [zəmin] |
[zəminᵊ] |
‘ground, land’ |
In addition to the restrictions on [ə], Hindi phonotactics also do not permit lax [ɪ ʊ] in word-final position (Gumperz, 1958, p. 216; Schmidt, 2007, p. 341). Consequently, in 𝚑𝚒-𝙳𝚎𝚟𝚊, the bound γ-vowels |ि ु| in word-final position are phonologically decoded as tense [i u]. On the other hand, Sindhi phonotactics do permit lax [ɪ ʊ] in word-final position, typically as the reduced allophones [ᶦ ᶷ]. Thus, in 𝚜𝚍-𝙳𝚎𝚟𝚊, |ि ु| or |इ उ| at the end of a word should be decoded as reduced [ᶦ ᶷ]. These graphs should also be decoded as reduced [ᶦ ᶷ] when corresponding to φ-[VC_CV] environments (see Table 4.5 and Table 4.6). The 𝚜𝚍-𝙳𝚎𝚟𝚊 examples listed in Table 7.5 illustrate this phenomenon.
ᶦ] and [ᶷ] in 𝚜𝚍-𝙳𝚎𝚟𝚊
| 𝚜𝚍-𝙳𝚎𝚟𝚊 spelling | Sindhi pronunciation | Gloss |
|---|---|---|
| दिलि | [d̪ɪlᶦ] |
‘heart’ |
| पुछु | [pʊt͡ɕʰᶷ] |
‘tail’ |
| गुज़िरणु | [ɡʊzᶦɾəɳᶷ] |
‘to pass’ |
Also implicated in the subtle graphematic differences between 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙳𝚎𝚟𝚊 are the written forms of loanwords from Sanskrit. Modern literary Hindi is rich in in Sanskrit-derived lexicon, including neologisms (King R. D., 2001). Due to the revered status of Sanskrit in India (Deshpande, 2016), writers are often loath to tinker with the spellings of loanwords. As a result, the source 𝚜𝚊-𝙳𝚎𝚟𝚊 spellings of loanwords are typically retained in 𝚑𝚒-𝙳𝚎𝚟𝚊, although their pronunciation is usually adapted to suit the phonotactics of modern Hindi. In other words, graphematic authenticity takes precedence over phonological authenticity. Consequently, 𝚜𝚊-𝙳𝚎𝚟𝚊 |शक्ति| ‘strength’ and |वस्तु| ‘thing’ are used in 𝚑𝚒-𝙳𝚎𝚟𝚊 with their graphematic composition unchanged, but are phonologically rendered [ɕəkt̪i] and [ʋəst̪u], respectively (Shapiro, 2007, p. 284). This reflects the 𝚑𝚒-𝙳𝚎𝚟𝚊 rule of interpreting final |ि ु| as [i u]. In modern Sindhi, Sanskrit loanwords tend to be pronounced in line with their Hindi pronunciations. Thus, the Sindhi pronunciation of the Sanskritic words for ‘strength’ and ‘thing’ would also be [ɕəkt̪i] and [ʋəst̪u]. However, their written forms, |शक्ति| and |वस्तु|, pose a graphematic problem. According to the rules of 𝚜𝚍-𝙳𝚎𝚟𝚊, final |ि ु| should be decoded as reduced [ᶦ ᶷ], which result in the ill-formed [ɕəkt̪ᶦ] and [ʋəst̪ᶷ], respectively. Notwithstanding the misalignment between graphematic and phonological forms, graphosociolinguistic pressures may oblige some 𝚜𝚍-𝙳𝚎𝚟𝚊 authors to persist with the source 𝚜𝚊-𝙳𝚎𝚟𝚊 spellings, potentially giving rise to unpredictable spelling variation and ambiguity for readers, especially learners. The resultant unpredictable variation is aptly illustrated by Table 7.3, which reveals the spellings |शक्ति| and |शक्ती| appearing in the very same 𝚜𝚍-𝙳𝚎𝚟𝚊 school textbook.
An argument in favour of having etymologically-determined uniform spellings for words across 𝚜𝚊-𝙳𝚎𝚟𝚊, 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙳𝚎𝚟𝚊 is learner convenience and the conceivable facilitation of literacy transfer. The disadvantage of such spellings is the likelihood for conflict with 𝚜𝚍-𝙳𝚎𝚟𝚊 guidelines, due to which certain written forms would need to be learnt as exceptions. This results in an increased learning curve.
Complicating matters is the emergence of the New Variety of Sindhi and its divergent pronunciations from the Old Variety. As outlined in Section 4.3.2, the reduced allophones [ᵊ ᶦ ᶷ] are absent or noncontrastive in the New Variety. As a result, in the Sindhi New Variety, the words listed in Table 7.4 tend to be pronounced almost like their Hindi equivalents, while those in Table 7.5 are generally pronounced [dɪl], [pʊt͡ɕʰ(ᵊ)] and [ɡʊz(ᵊ)ɾəɳ(ᵊ)], respectively. Hence, a Sindhi New Variety speaker who is dominant in 𝚑𝚒-𝙳𝚎𝚟𝚊 may be doubly disadvantaged when attempting to decode certain 𝚜𝚍-𝙳𝚎𝚟𝚊 spellings, which tend to be based on Old Variety pronunciations. That said, a 𝚑𝚒-𝙳𝚎𝚟𝚊-dominant reader might find it more intuitive to decode 𝚜𝚊-𝙳𝚎𝚟𝚊-based spellings such as |शक्ति| and |वस्तु|, thereby mitigating the disadvantage somewhat.
Given that 𝚜𝚍-𝙳𝚎𝚟𝚊 is not biunique in its graph-phone correspondences, it is evident that its graphematic solution space needs to be constrained by a widely accepted orthography. The absence of such a normative orthography has resulted in the proliferation of idiosyncratic spellings in 𝚜𝚍-𝙳𝚎𝚟𝚊 texts. Variable spellings are particularly noticeable in certain phonological contexts. For instance, [ɽʱ(ə)] may be spelt |ड़ह ड़्ह ढ़ ढ़्ह ढ़ह| (see (16)), reflecting the uncertainty in its phonemic status (§4.3.1). Similar uncertainty on the existence of φ-consonant gemination in Sindhi results in multiple possible spellings for a given word, reminiscent of the analogous phenomenon in 𝚜𝚍-𝙰𝚛𝚊𝚋 (§6.5.2). Thus, in Hardwani’s 𝚜𝚍-𝙳𝚎𝚟𝚊 dictionary (1991, p. 403), the Sindhi word for ‘wool’, pronounced [ʊnᵊ ~ ʊnnᵊ], has two equivalent spellings listed for it: |उन| and |उन्न|. In addition, speakers of Sindhi varieties that feature the clusters [ʈɾ ɖɾ] may reflect these pronunciations in their 𝚜𝚍-𝙳𝚎𝚟𝚊 writing. Thus, the Sindhi festival of Cheti Chand, pronounced [t͡ɕeʈi t͡ɕəɳɖᶷ] in the Vicholi variety and [t͡ɕeʈɾi t͡ɕəɳɖɾᶷ] in Siroli, might be transcribed in by speakers of the latter as |चेट्री चंड्रु| (The Sindhu World, 2021). The Indian Institute of Sindhology has attempted to resolve some of these open questions through its recent lexicographic works (Rohra, Bijani, & Gurnani, 2011), the details of which are described in Section 7.6.
7.5.4 Logograms and collation order
Logograms in 𝚜𝚍-𝙳𝚎𝚟𝚊, including numerals and punctuation marks, largely overlap with those in modern 𝚑𝚒-𝙳𝚎𝚟𝚊. Exceptions include the graph for a full stop. While some 𝚜𝚍-𝙳𝚎𝚟𝚊 works in the immediate post-Partition era used the 𝚑𝚒-𝙳𝚎𝚟𝚊-inspired |।| as a sentence separator, most present-day 𝚜𝚍-𝙳𝚎𝚟𝚊 publications feature the Roman-script full stop |.|.
In terms of collation order, there exist minor differences in the works of different authors. For instance, Lekhwani’s dictionary (1996, p. vi) does not explicitly list |ऋ| and |ं| in the enclosed 𝚜𝚍-𝙳𝚎𝚟𝚊 character chart, although it uses |ं| extensively in spelling 𝚜𝚍-𝙳𝚎𝚟𝚊 entries. On the other hand, Khubchandani (2007, p. 698) includes not only |ऋ| and |ं| in his sequence of graphs, but also the Sanskritic visarga |ः|, which is rarely, if ever, used in modern 𝚜𝚍-𝙳𝚎𝚟𝚊. The Sanskritic |ष| tends to be explicitly listed in most 𝚜𝚍-𝙳𝚎𝚟𝚊 sort orders.
In sum, there exist aspects of graphematic regularity as well as fuzziness in 𝚜𝚍-𝙳𝚎𝚟𝚊. These aspects may reflect corresponding regularity and fuzziness in 𝚜𝚍-𝙰𝚛𝚊𝚋, or may be traceable to the sociolinguistic impact of 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊. As in 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊 authors may adopt writing practices that reflect their ideological affiliation. The resultant variation is tolerated, and may even go unnoticed, by fluent readers. However, such variation may snowball into confusion and disenchantment for learners of 𝚜𝚍-𝙳𝚎𝚟𝚊. In the context of variation in 𝚖𝚛-𝙳𝚎𝚟𝚊, Deshpande (2016, p. 72) states that “seemingly trivial issues of signs and dots gradually emerge as part of larger ones about literacy, historicity, [and] community”. This statement appears to hold true for 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 as well.
7.6 Indian Institute of Sindhology’s system
In the twenty-first century, the Indian Institute of Sindhology’s (IIS) has attempted to constrain and regulate certain aspects of graphematic variation in 𝚜𝚍-𝙳𝚎𝚟𝚊 by means of its Standard Trilingual Dictionary (Sindhi – Hindi – English) (Rohra, Bijani, & Gurnani, 2011). The trilingual-triscriptal structure of this work is similar to that of Lekhwani (1996), with headwords listed in 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙰𝚛𝚊𝚋, and meanings provided in Hindi (𝚑𝚒-𝙳𝚎𝚟𝚊) and English (𝚎𝚗-𝙻𝚊𝚝𝚗). The graphematic rules listed in the dictionary (pp. xix–xx) are comprehensive enough to warrant them assigned a distinct language subtag: 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜.
7.6.1 Graph inventory and allography
Although attempting to take a stance on certain areas of graphematic ambiguity, the graph inventory of 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 remains largely consistent with post-Partition 𝚜𝚍-𝙳𝚎𝚟𝚊 practice. For instance, in Sanskrit-origin words, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 explicitly treats |ऋ ज्ञ क्ष ष| as graphematically equivalent to |रि ग्य क्श श| (Rohra, Bijani, & Gurnani, 2011, p. xix), making the two sets of allographs — or homophonous heterographs — in free variation. Accordingly, |ऋ ज्ञ क्ष ष| do not receive their own dictionary sections, although spellings involving these graphs are listed separately in headword entries as equivalent alternatives. A selection of such listings is shown in (17):
Furthermore, |ऋ ज्ञ क्ष ष| are not used to spell non-Sanskritic words. Thus, Sindhi [ɾikᶦɕa] ‘rickshaw’ is only spelt |रिक्शा| (p. 455).
Spellings with γ-consonant clusters are permitted in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜. However, universal rules are absent, and spellings seem to have been decided on an individual basis. Thus, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 writes [pᶦjaɾᶷ] as |प्यारु| instead of |पियारु| (pp. xix–xx), but [kabɪlᶦjətə] ‘capability’ as |क़ाबिलियत|, not |क़ाबिल्यत| (p. 98).
Regarding graphs for the Perso-Arabic phones [q x ɣ z f], 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 considers the nuqta-bearing graphs |क़ ख़ ग़ ज़ फ़| to be distinct from dotless |क ख ग ज फ|. Notably, words beginning with |ख़ ग़ ज़ फ़| receive their own sections, while words beginning with |क़| are listed under the heading for |क| and ordered after it. Thus, the entry |काफ़िरु| [kafɪɾᶷ] ‘infidel’ appears before |क़ाफ़िलो| [qafɪlo] ‘convoy’, which in turn precedes |काफ़ी| [kafi] ‘enough’ (p. 98). The 𝚜𝚍-𝙰𝚛𝚊𝚋 graphs |ث ح ذ ص ض ط ظ ع غ| do not have canonical equivalents in 𝚜𝚍-𝙳𝚎𝚟𝚊, and 𝚜𝚍-𝙰𝚛𝚊𝚋 words featuring these graphs are sorted based on their 𝚜𝚍-𝙳𝚎𝚟𝚊 spelling.
A salient graphetic feature of 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 is the representation of [ɾʊ ɾu] as the compositionally transparent |रु रू| rather than the customary |रु रू|. While the latter forms are plausible within the graphematic solution space of 𝚜𝚍-𝙳𝚎𝚟𝚊, they are rarely seen in any prevalent Devanagari-based writing system.
7.6.2 Spelling and orthography
Gemination of γ-consonants is not marked in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜, and loanwords are (re)spelt to reflect this rule. Thus, 𝚑𝚒-𝙳𝚎𝚟𝚊 |सत्ता| [sət̪t̪a] becomes 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 |सता| [sət̪a] ‘political power’.
Indeclinable adjectives that are pronounced in the Sindhi New Variety chronolect with a final φ-consonant or epenthetic [ᵊ] are (re)spelt accordingly. Thus, the Sindhi words for ‘happy’, ‘clever’ and ‘interesting’, listed in Lekhwani (1996) as |ख़ुशि|, |चालाकु| and |दिलचस्पु|, are respelt in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 as |ख़ुश|, |चालाक| and |दिलचस्प|, respectively, to better reflect their New Variety pronunciations as [xʊɕ(ᵊ)], [t͡ɕalak(ᵊ)] and [d̪ɪlᵊt͡ɕəsp(ᵊ)].
Certain nouns may also be respelt to better reflect their New Variety φ-vowel makeup. Thus, 𝚜𝚊-𝙳𝚎𝚟𝚊 |नीति| ‘policy, ethics’, realised in Sindhi as [nit̪i], is spelt in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 as |नीती|. Conversely, the Sindhi word for ‘fragrance’, whose New Variety pronunciation is [xʊɕᵊbu], has been respelt from the hitherto prevalent |ख़ुशबूइ| as 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 |ख़ुशबू|. That said, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 is discretionary in graphematically indicating noun gender. Native or assimilated nouns whose Old Variety pronunciation and spelling comprised a final lax vowel indexing grammatical gender (§4.4) are not respelt to match their New Variety pronunciations. Thus, Old Variety [d̪ɪlᶦ] ‘heart’ and [kɪt̪abᶷ] ‘book’, traditionally spelt |दिलि| and |किताबु|, are not respelt in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 to reflect their New Variety pronunciations [d̪ɪl(ᵊ)] and [kɪt̪ab(ᵊ)], respectively. Their spellings retain the final bound γ-vowels |ि ु| that index feminine and masculine gender, respectively. On the other hand, unassimilated English-origin nouns for inanimate referents, which are pronounced in the New Variety with a final φ-consonant or epenthetic [ᵊ], are spelt in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 with a final γ-consonant without a virama. Thus, English ‘fashion’, pronounced [fɛɕən(ᵊ)] in the New Variety, is spelt |फ़ैशन|, with final |न| [n(ə)]. A comparison of 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 spellings with their equivalents in Lekhwani (1996) is shown in (18):
Words featuring [ɛ ɔ] are consistently spelt in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 with |ै ौ|. Thus, [pɛso] ‘money’ is |पैसो| and [t͡ɕɔk(ᵊ)] ‘square, intersection’ is |चौंकु|, with their 𝚜𝚍-𝙰𝚛𝚊𝚋 equivalents listed as |پَسو| and |چَونڪُ|. By doing so, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 deprecates the previously-used alternative spellings |पइसो پَئِسو| and |चउंकु چَؤنڪُ|, respectively (see Figure 6.5). Words whose New Variety pronunciation no longer features [ɛ ɔ] are respelt accordingly. Thus, the word for ‘education’, pronounced [t̪ɛlimᵊ] in the Old Variety and spelt |तइलीम| (Lekhwani, 1996, p. 80), tends to be pronounced [t̪alim(ᵊ)] in the New Variety (see also §6.5.4). Accordingly, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 spells the word as |तालीम| to reflect the latter pronunciation.
7.6.3 Collation order
Although headwords in the IIS’ dictionary are listed in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 as well as in 𝚜𝚍-𝙰𝚛𝚊𝚋, they are ordered according to the following Devanagari-based collation order (Rohra, Bijani, & Gurnani, 2011, p. xxiv):
(ं) अ आ इ ई उ ऊ ए ऐ ओ औ
क (क़) ख ख़ ग ग़ ॻ घ (ङ)
च छ ज ॼ ज़ झ (ञ)
ट ठ ड (ड़) ॾ ढ (ढ़) ण
त थ द ध न
प फ फ़ ब ॿ भ म
य र ल व श स ह
This collation order is similar to the one used in Lekhwani (1996, p. vi). Graphs in parentheses do not have their own dictionary sections. While the situation of |क़| has been described earlier, the other parenthesised graphs do not occur word-initially in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜. Words containing anusvara are sorted thus: |अंगु| [əŋɡᶷ] ‘number’ → |अंसु| [ənsᶷ] ‘component’ → |अगरि| [əɡəɾᶦ] ‘if’ → |असुली| [əsᶷli] ‘real’ (pp. 1–26). Graphs based on the same rasm are sorted with the graphetically basic form first, followed by the underlined or underdotted form. If a rasm has an underlined as well as an underdotted counterpart, there appears to be no pattern on which one occurs first, as seen in the sequences |क क़|, |ख ख़|, |ग ग़ ॻ|, |ज ॼ ज़|, |ड ड़ ॾ|, |ढ ढ़|, |फ फ़| and |ब ॿ|.
7.7 Analysis
7.7.1 Graphematic typology
The description of 𝚜𝚍-𝙳𝚎𝚟𝚊’s gradual evolution since the early nineteenth century reveals that, despite various developments and refinements in its graphematic makeup, the writing system has continued to be abugidic and alphasyllabic in nature. In this regard, 𝚜𝚍-𝙳𝚎𝚟𝚊’s typology has remained identical to that of its founding systems, 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚜𝚊-𝙳𝚎𝚟𝚊 (§7.1; see also Figure 2.3). Moreover, 𝚜𝚍-𝙳𝚎𝚟𝚊’s conceptual Swarakhadi-style free γ-vowel allographs|अ आ अि अी अु अू अे अै ओ औ|, with |अ| as a common base, are compositionally near-identical to 𝚜𝚍-𝙰𝚛𝚊𝚋’s free γ-vowels, which use alif |ا| as a common base. This graphetic and graphematic commonality between 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙰𝚛𝚊𝚋 further reinforces the alphasyllabic nature of both systems (§6.6.1).
7.7.2 Graph inventory
Following the description of 𝚜𝚍-𝙳𝚎𝚟𝚊’s evolution over the years, including additions and modifications to its graph inventory, the focus turns to the graphematic categorisation of the inventory’s elements. When it comes to identifying rasms, the most evident ones are the bound γ-vowels |ा ि ी ु ू े ै|, which canonically denote the Sindhi vowels [a ɪ i ʊ u e ɛ], respectively. Since they are minimal, contrastive and have an identifiable linguistic value, these bound γ-vowels also appear to qualify as graphemes in 𝚜𝚍-𝙳𝚎𝚟𝚊. In contrast, the bound γ-vowels |ो ौ| [o ɔ] are not graphetically minimal, being composed of the elements |ा| and |े| or |ै|. As a result, |ो ौ| fail to qualify as graphemes in 𝚜𝚍-𝙳𝚎𝚟𝚊. Indeed, Meletis (2020, p. 102 footnote 112) uses similar reasoning in the context of graphetically complex γ-vowels in the Tamil (𝚝𝚊-𝚃𝚊𝚖𝚕) writing system, arguing that such γ-vowels do not constitute graphemes based on the tripartite definitional criteria on hand.
Deciding the status of other graphs in the inventory is less straightforward. A look at Table 7.1 suggest that certain graphs, such as the free γ-vowels |अ इ उ ए| and the free γ-consonants |ङ ट ठ ड ढ र| [ŋ(ə) ʈ(ə) ʈʰ(ə) ɖ(ə) ɖʱ(ə) ɾ(ə)] seem likely candidates for grapheme status. A handful of rasms, such as the free γ-consonants such as |क फ| [k(ə) pʰ(ə)] and their associated bound or ‘half’ forms |क्◌ फ्◌| [k pʰ], also fulfil the grapheme criteria individually. In fact, all bound γ-consonant forms — whether graphetically predictable forms like |ब्◌| [b] or unexpected ones like |र्◌| [ɾ] — appear to qualify as graphemes in themselves, since they are minimal, contrastive and have linguistic value. The majority of 𝚜𝚍-𝙳𝚎𝚟𝚊’s ‘full’ γ-consonants, though, appear to be graphetically composed of their associated half form and the element |ा|.110 Thus, |ब| [b(ə)] may be interpreted as a graphetic combination of |ब्◌| and |ा|. However, bound γ-consonants and |ा| have already been identified as potential graphemes themselves. As a result, those free γ-consonants in the 𝚜𝚍-𝙳𝚎𝚟𝚊 inventory that graphetically comprise a bound γ-consonant and |ा| would fail the minimality test and emerge as nongraphemes. The matter is further complicated by the fuzziness around the presence of φ-consonant clusters in Sindhi phonology (§4.3.1) and, consequently, the tenability of using bound or half forms of γ-consonants in 𝚜𝚍-𝙳𝚎𝚟𝚊.
Other areas of uncertainty include the graphs |इ ई| [ɪ i]. By itself, |इ| is likely a grapheme in 𝚜𝚍-𝙳𝚎𝚟𝚊. However, |ई| may be considered a graphetic fusion of the graphemes |इ| and |र्◌| [ɾ], in the process failing the minimality criterion. At the same time, both |उ ऊ| [ʊ u] would satisfy all three grapheme criteria since the tail-like element on |ऊ| is not a grapheme by itself. Although the tail-like elements on |ई| and |ऊ| are not identical, they are, nevertheless, very similar in visual appearance and in their function as distinguishing elements compared to |इ| and |उ|, respectively. Faced with this line of reasoning, can one justifiably reconcile granting grapheme status to |ऊ| while denying it to |ई|, particularly when the visual similarity of the tail-like element on |ई| with |र्◌| [ɾ] is likely a coincidental outcome of typographical modularisation?
The analysis presented here suggests that the tripartite defining criteria for a grapheme must continue to be applied to and tested across several writing systems. No doubt, Meletis’ proposed criteria constitute a significant step forward in ‘reclaiming’ the concept of a grapheme. Nevertheless, further testing and refinement are essential for the criteria to remain theoretically sound and capable of delivering consistent and plausible verdicts on identifying graphemes across a diverse range of writing systems. As was the case with 𝚜𝚍-𝙰𝚛𝚊𝚋, the current state of grapholinguistic theory does not allow us to conclusively determine the graphemes in the 𝚜𝚍-𝙳𝚎𝚟𝚊 inventory. Although seemingly anti-climactic, such an outcome is just as well, since the status of complex graphs in 𝚜𝚍-𝙳𝚎𝚟𝚊, including so-called ligatures, presents much food for thought for ongoing holistic evaluations in this regard.
7.7.3 Graphematics and orthography
In Table 7.3 , the 𝚜𝚍-𝙳𝚎𝚟𝚊 complex graphs |क्त ष्ट्र| shine the spotlight on the concept and scope of ligatures Devanagari-based writing systems, including their mandatory or optional nature (§2.7). In 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊, the phonological sequences [kt̪(ə) ɕʈɾ(ə)] may be written either as |क्त ष्ट्र| or as |क्त ष्ट्र|, with the only implications being stylistic or semiotic in nature (see Example (12)). On the other hand, 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊 require that the phonological sequences [ɕɾ(ə) kɕ(ə)] always be written |श्र क्ष|, and not as |श्र क्ष|. Viewed from the lens of the Modular Theory, the graphematic solution spaces of 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊 license |श्र क्ष| as well as |श्र क्ष| as potential representations of [ɕɾ(ə) kɕ(ə)]. However, the implicit orthographies of these writing systems constrain the available solutions and mandate |श्र क्ष| as the only ‘correct’ choice. Some of these writing practices and constraints, such as those governing |श्र क्ष|, have been adopted more or less unchanged into post-Partition 𝚜𝚍-𝙳𝚎𝚟𝚊. At the same time, certain 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊 traditions have fallen away or been tacitly weakened in 𝚜𝚍-𝙳𝚎𝚟𝚊. For instance, 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊 consider |ज्ञ ग्य| to be graphematically distinct and not interchangeable, whereas 𝚜𝚍-𝙳𝚎𝚟𝚊 treats them as freely varying allographs for [ɡj(ə)] (§7.5.1).
The advent of 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 and its guidelines has resulted in the legitimisation of certain graphs and graph sequences previously considered inauthentic. These include the compositionally more transparent sequences |क्ष| and |रु रू| as alternatives for |क्ष| [kɕ(ə)] (see Example (17)) and |रु रू| [ɾʊ ɾu]. In addition, |क्ष| is optional — albeit preferred — while |रु रू| is across the board. These developments reiterate the observation in Section 2.7, that the concept of ‘ligature’ is primarily graphematic in nature and based on the homophony or phonological equivalence between two graphs or graph sequences. Graphetically speaking, a ‘ligature’ may turn out to be simpler than its compositionally transparent equivalents; a deconstruction of |क्ष| and |क्ष| reveals that the former comprises the rasms |क्ष्◌ ा| and the latter |क्◌ ष्◌ ा|. This reality sits somewhat uneasily with the popular interpretation of a ligature as a supposedly complex combination of graphs. In addition, the fact that such rulings on ligatures were conceived of and promulgated in a top-down manner by a language body — the IIS — suggests that ligatures owe their existence in part to the orthographic module. Moreover, the fact that 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 considers some ligatures optional and others mandatory further strengthens the idea that assigning ‘ligature’ status to a graph is heavily conditioned by the graphematic and orthographic modules of a writing system.
The discussion on orthographic module brings us to the topic of 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜’s credentials. As the product of a language body featuring a codified set of writing rules, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 may be considered a conventional orthography as defined in Section 2.9. Although promulgated in a top-down manner, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 does not introduce any graphematic forms or spellings not already licensed by 𝚜𝚍-𝙳𝚎𝚟𝚊’s graphematic solution space. Although 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 may still leave specific questions answered, the availability of an accompanying dictionary as a reference greatly mitigates the number and extent of spelling-related grey areas.
If 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 is deemed an orthography, why is the same label not assigned to 𝚜𝚍-𝙰𝚛𝚊𝚋? Considering that the IIS trilingual-triscriptal dictionary (Rohra, Bijani, & Gurnani, 2011) features Sindhi-language headwords in 𝚜𝚍-𝙳𝚎𝚟𝚊 as well as 𝚜𝚍-𝙰𝚛𝚊𝚋 (§7.6), is there an argument to be made for the existence of a 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚒𝚒𝚜? If yes, what about a potential 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚕𝚊, considering that the SLA in Pakistan performs a role very similar to that of the IIS in India? The answers to these questions will depend on the precise definition of orthography, as well as the related concept of orthography reform. According to Neef (2021), the existence of an orthography implies the availability of a “codified and binding norm” of graphematic rules and spellings, while orthographic reform presupposes “[a]n authority that has the power to change the norm”. As it turns out, the guidelines listed by the IIS in its trilingual-triscriptal dictionary pertain only to 𝚜𝚍-𝙳𝚎𝚟𝚊, and not to 𝚜𝚍-𝙰𝚛𝚊𝚋. Although the guidelines make numerous references to 𝚜𝚍-𝙰𝚛𝚊𝚋 as a point of comparison, no recommendations are made on 𝚜𝚍-𝙰𝚛𝚊𝚋 spelling rules. Per Neef’s conceptualisation of orthography, the absence of a codified set of rules targeting 𝚜𝚍-𝙰𝚛𝚊𝚋 leaves insubstantial evidence for the existence of a 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚒𝚒𝚜 orthography.
Along similar lines, the absence of an identifiable set of codified norms governing 𝚜𝚍-𝙰𝚛𝚊𝚋 undermines the argument in favour of a 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚕𝚊 orthography, while also precluding the existence of reforms. Whereas the SLA has implicitly regulated variation in 𝚜𝚍-𝙰𝚛𝚊𝚋 over the decades through its dictionaries and publications, the institution does not appear to have disseminated a consolidated set of rules governing 𝚜𝚍-𝙰𝚛𝚊𝚋 graphematics and spelling. Evidently, stating that the SLA has yet to set out orthographic norms for 𝚜𝚍-𝙰𝚛𝚊𝚋 strikes one as disingenuous considering the copious amounts of 𝚜𝚍-𝙰𝚛𝚊𝚋 material published under the SLA’s auspices. This palpable incongruity reiterates the earlier observation on the existence of an orthography depending on one’s individual understanding of the concept, and the consequent need for a comprehensive definition of the term.
7.7.4 Sociolinguistics
Besides the existence of an identifiable norm, Neef’s conceptualisation of orthography and its reform also presupposes the existence of a language body that has authority and power over the norm and its modifications. Whether the language body is a governmental or semi-governmental agency or a private lexicographer, the authority it commands is crucial in determining the success of its orthographies. This brings us to examining the authority that language bodies such as the IIS have, and how such authority may be reasonably measured or assessed. As it turns out, reliable tools and frameworks for evaluating the authority of a language body and its orthographies are scant. Then again, it seems uncontroversial to state that 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 is not binding in any manner. In fact, knowledge of this ‘norm’ appears low among lay Sindhis in India, evinced by the persistence of unstandardised 𝚜𝚍-𝙳𝚎𝚟𝚊 practices on social media and messaging apps even after a decade of 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜’s release. The situation is unsurprising, since the emic relegation of 𝚜𝚍-𝙳𝚎𝚟𝚊 usage primarily to unofficial domains of use takes away any educational, legal or social incentive to follow specific orthographic norms. Thus, the perceived authority of 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 is undermined by the sociolinguistic inconspicuousness of 𝚜𝚍-𝙳𝚎𝚟𝚊 writing in the Indian Sindhi graphosphere.
In sum, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 emerges as a reasonably lucid and comprehensive set of graphematic guidelines that, nevertheless, lacks sociolinguistic authority. From an orthographic perspective, the situation with the IIS and 𝚜𝚍-𝙳𝚎𝚟𝚊 is the converse of that involving the SLA and 𝚜𝚍-𝙰𝚛𝚊𝚋. While the former falls short in terms of authority, the latter does so with regard to codification. This finding prompts one to ask: what kind of relative weightage should the components of codification and authority have when deciding whether a collection of graphematic norms deserves the label ‘orthography’?
8 Khudawadi
In the twenty-first century, written Sindhi is most often associated with the Arabic and Devanagari scripts. However, in the mid-nineteenth century, what locals and Europeans considered the “Sindhi” script were the Landa inventories prevalent in the region (Stack, 1849a, p. 2; Trumpp, 1858, p. ii). By extension, the moniker ‘Sindhi’ was also applied to the proto-standardised and best-known offshoots of the Landa inventories of Sindh — Khojki and Khudawadi (§5.1.4). Inadvertently reinforcing this association is the four-letter ISO 15924 script code for Khudawadi — 𝚂𝚒𝚗𝚍 (Pandey, 2010f). Consequently, the language subtag for the Sindhi-Khudawadi writing system is 𝚜𝚍-𝚂𝚒𝚗𝚍.
As suggested by Figure 5.1, the proto-standardised Landa inventories of Punjab and Sindh formed a geographically-conditioned graphetic continuum, ranging from Gurmukhi in the north to Khojki in the south. In the geographical and graphetic middle lay the Multani script of southern Punjab, and Khudawadi. Multani was the proto-standardised Landa inventory used to write the Siraiki language (𝚜𝚔𝚛-𝙼𝚞𝚕𝚝). The linguistic closeness of the Siraiki and Sindhi languages, the graphetic likeness of the Multani and Khudawadi inventories, and the typological similarity of the 𝚜𝚔𝚛-𝙼𝚞𝚕𝚝 and 𝚜𝚍-𝚂𝚒𝚗𝚍 writing systems as used in the mid-nineteenth century led to the two often being depicted alongside each other in nineteenth century European-authored works (Bagster, 1851, p. 12; Faulmann, 1880a; Taylor, 1883, pp. 338–339).
By 1870, however, there emerged what was claimed to be a new-and-improved avatar of 𝚜𝚍-𝚂𝚒𝚗𝚍, which was typologically very distinct from its predecessor. Even so, the new variant of 𝚜𝚍-𝚂𝚒𝚗𝚍 was rejected by its target population in favour of the previous variant. Hence, 𝚜𝚍-𝚂𝚒𝚗𝚍 represents a noteworthy example of a transparent writing system being rejected in favour of an opaque one. This makes 𝚜𝚍-𝚂𝚒𝚗𝚍 and its variants worthy subjects of further graphematic and sociolinguistic investigation.
8.1 Graphematic foundations and early use
Compared to 𝚜𝚍-𝙰𝚛𝚊𝚋 or 𝚜𝚍-𝙳𝚎𝚟𝚊, which are ultimately based on the relatively transparent systems of 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚜𝚊-𝙳𝚎𝚟𝚊, respectively, early unstandardised variants of 𝚜𝚍-𝚂𝚒𝚗𝚍 were comparatively opaque. That said, the opacity of unstandardised 𝚜𝚍-𝚂𝚒𝚗𝚍 was distinct from the kind caused by discretionary omission of subsegmental graphs in 𝚜𝚍-𝙰𝚛𝚊𝚋. As a general rule, all variants of 𝚜𝚍-𝙰𝚛𝚊𝚋 have graphematic provisions to ensure a high degree of phonological transparency. However, writers often choose not to harness the full graphematic repertoire available. In contrast, early versions of 𝚜𝚍-𝚂𝚒𝚗𝚍 simply lacked the requisite provisions for reflecting spoken Sindhi in a transparent manner. Put differently, the opacity of 𝚜𝚍-𝙰𝚛𝚊𝚋 was and is sociolinguistically conditioned, while that of early 𝚜𝚍-𝚂𝚒𝚗𝚍 was graphematically conditioned. The opaque variant of 𝚜𝚍-𝚂𝚒𝚗𝚍 was the only one in popular use until 1869 (§8.2), based on which it has been assigned the language subtag 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍. Table 8.1 shows the most common 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 phonograms reproduced from Stack’s (1849a) handwritten chart and Bagster’s (1851, p. xliv) plate. Graph-phone correspondences in the table follow Stack (1849a), with Bagster’s graphs included primarily for graphetic comparison.
Sources: Stack (1849a, pp. 3–8) and Bagster (1851, p. xliv)
| Stack (1849a) | Bagster (1851) | Modern typeface | Phonological value(s) in IPA |
|---|---|---|---|
 |
 |
𑊰 | ə a ɪ i ʊ u e ɛ o ɔ |
 |
 |
𑊲 | ɪ i ʊ u e ɛ o ɔ |
| not listed |  |
𑊴 | ɪ i ʊ u e ɛ o ɔ |
 |
 |
𑊺 | k (q) |
 |
 |
𑊻 | kʰ (x) |
 |
 |
𑊼 | ɡ ɡʱ (ɣ) |
 |
 |
𑊽 | ɠ |
 |
not listed | 𑊿 | ŋ ɲ |
 |
 |
𑋀 | t͡ɕ |
 |
 |
𑋁 | t͡ɕʰ |
 |
 |
𑋂 𑋘 | d͡ʑ d͡ʑʱ (j) (z) |
 |
 |
𑋃 | ʄ |
 |
 |
𑋅 | ŋ ɲ |
 |
 |
𑋆 | ʈ |
| same as above |  |
– | ʈʰ |
 |
 |
𑋈 | ʈɾ ɖɾ |
  |
not listed | 𑋊 ॥ | ɽ (ɽʱ) ɾ (ɾʱ) |
 |
not listed | 𑋋 | ɖ ɖʱ |
 |
 |
𑋶 | ɗ |
 |
 |
𑋌 | ɳ (ɽ̃) |
 |
 |
𑋍 | t̪ |
 |
 |
𑋎 | t̪ʰ |
 |
 |
𑋏 | d̪ d̪ʱ |
| same as above |  |
– | (d̪ʱ) |
 |
 |
𑋑 | n |
 |
 |
𑋒 | p |
 |
 |
𑋓 | pʰ (f) |
 |
 |
𑋔 | b bʱ |
 |
 |
𑋕 | ɓ |
 |
 |
𑋗 | m |
 |
 |
𑋘 | d͡ʑ d͡ʑʱ (j) |
 |
not listed | ॥ | ɾ |
| under ‘Shikarpuri’ |  |
𑋙 | ɾ |
 |
 |
𑋚 | l |
 |
 |
𑋛 | ʋ |
 |
 |
𑋝 | s (ɕ) |
 |
 |
𑋞 | ɦ |
Graphetically, certain graphs in the 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 inventory have cognates not just in other Landa-based inventories, but also in Devanagari-based inventories. Some of these cognate graphs in different inventories reflect historical phonological mergers. Thus, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 |𑊻| [kʰ] is graphetically cognate with 𝚜𝚊-𝙳𝚎𝚟𝚊 |ष| [ʂə], reflecting the realisation of Sanskritic [ʂ] as New Indo-Aryan [kʰ] (see §7.3, p. 199).
In terms of inventory, and like its Landa-derived sister writing systems, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 features only three γ-vowels: |𑊰 𑊲 𑊴|. Of these, only |𑊰| was used word-initially, irrespective of the φ-vowel in question (Coulmas, 1996a, p. 282; Stack, 1849a, pp. 2, 3 footnote). Crucially, there were no bound γ-vowel allographs. While the second member of a φ-[VV] sequence was occasionally — and idiosyncratically — written with any one of |𑊰 𑊲 𑊴|, medial and final φ-vowels occurring in a φ-[CV] sequence were almost never written. In this regard, Pandey’s (2012, p. 2) summary of the 𝚜𝚔𝚛-𝙼𝚞𝚕𝚝 writing system is entirely applicable to 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍:
[Siraiki-Multani] is closer in structure to an abjad than an alphasyllabary. There is no VIRAMA. There are […] no dependent vowel signs. [Graphematic] Vowels are generally not written unless they occur in isolation, in word-initial position, or in the final position of monosyllabic words. [Graphematic] Consonants theoretically possess the inherent [φ-]vowel /
a/, but as [γ-]vowels are not explicitly marked, the actual syllabic value of a [γ-]consonant in running text is ambiguous and must be inferred from context. […] there are no [γ-]conjuncts.
Thus, Pandey characterises 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 as structurally abjadic, aside from the occasional use of free γ-vowels in non-initial position. He describes the latter practice as “alphabetic” (Pandey, 2011c, pp. 2–3). He further opines that the opacity of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 writing requires the reader to decode it at the morphological level (Pandey, 2011c, p. 3). In several instances, graphematic and sociolinguistic context may also be required. The need for additional context to accurately decipher abjadic 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 writing is succinctly illustrated by Stack (1849a, p. 2) using the graph sequence |𑊼𑋚|:
Thus 𑊼𑋚 might stand for गोलो [
ɡolo], गोली [ɡoli], गुलु [ɡʊlᶷ], गलो [ɡəlo], गेलि [ɡelᶦ], गिलो [ɡɪlo], गिला [ɡɪla], गोलु [ɡolᶷ], गुलू [ɡʊlu], or for any other word that might happen to be in use, formed by pronouncing these two [γ-]Consonants with any of the vowel sounds.111
Faulmann (1880a) compares the absence of bound γ-vowels in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚔𝚛-𝙼𝚞𝚕𝚝 with the conventional omission of subsegmental graphs in writing systems based on the Arabic and Hebrew scripts:
Die vorstehenden Schriften sind […] beachtenswert, […] weil sie in gleicher Weise wie die semitischen Schriften die Vokale in der Mitte der Wörter nicht schreiben, z. B. Sindisch 𑋍𑋞𑋘 tuhidžo, […]
These scripts [𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚔𝚛-𝙼𝚞𝚕𝚝] are […] noteworthy for their omission of word-medial [bound γ-]vowels exactly as the Semitic scripts do, e.g., Sindhi 𑋍𑋞𑋘 tuhidžo [
t̪ʊ̃ɦᶦ̃d͡ʑo] […]
In a subsequent work, Faulmann (1880b, pp. 454–455) also compares the three free vowel graphs of the Khudawadi and Multani inventories with the Hebrew-Hebrew (𝚑𝚎-𝙷𝚎𝚋𝚛) inventory of |ו י א| [a i u]. On this basis, Faulmann portrays writing systems based on the Khudawadi and Multani inventories as a bridge between Semitic and Indic systems. However, and as mentioned at the start of this section, it is necessary to distinguish the absence of subsegmental graphs in the Semitic-origin 𝚜𝚍-𝙰𝚛𝚊𝚋 from the superficially similar phenomenon in the Indic-origin 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍. First, in 𝚜𝚍-𝙰𝚛𝚊𝚋, only a subset of subsegmental γ-vowels — those denoting [ə ɪ ʊ] — are sociolinguistically omissible. All other γ-vowels need to be written, else the text would be viewed as incorrect or unacceptable. In contrast, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 did not possess bound γ-vowels at all. Even the three free γ-vowels in its inventory, |𑊰 𑊲 𑊴|, were sociolinguistically omissible in medial and final position. More importantly, 𝚜𝚍-𝙰𝚛𝚊𝚋 featured near-biunique correspondences between vowel graphs and phones. This meant that a 𝚜𝚍-𝙰𝚛𝚊𝚋 text could be quite transparent as long as the writer included all γ-vowels. In 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, however, the number of γ-vowels in the script fell far short of the number of φ-vowels in spoken Sindhi. This made it graphematically impossible to write 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 in a transparent manner, even if the writer so desired. Hence, the underlying factors conditioning the absence of γ-vowels were distinct in the Semitic 𝚜𝚍-𝙰𝚛𝚊𝚋 and the Indic 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, despite the superficial similarities of their end results.
The number of graphs in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍’s inventory was also insufficient for unambiguously representing Sindhi’s φ-consonants (see Table 8.1). Some of these cases of apparent graphematic underdifferentiation were phonologically justifiable. For instance, the lack of contrast in spoken Sindhi between [ɽ ɾ] and their aspirated counterparts [ɽʱ ɾʱ] (§4.3.1) would have likely prompted the interchangeable use of |𑋊 ॥|. A similar absence of phonemic distinction between [s ɕ] in native Sindhi vocabulary at the time (Trumpp, 1872, p. xvii) would have rendered distinct graphs for these phones redundant, with |𑋝| sufficing for the purpose. The phonological merger of Sanskritic [j] into Middle Indo-Aryan [d͡ʑ] and the consequent loss of a distinctive [j] in the latter group of languages (Grierson, 1881, p. 3; Trumpp, 1872, p. xxviii) would have prompted the use of |𑋘| for [d͡ʑ] and [j] alike. Also attributable to historical-etymological reasons is the emergence of |𑋈| for [ʈɾ ɖɾ]. Trumpp (1858, p. iii) traces the origin of Sindhi [ʈɾ] to Sanskrit [t̪ɾ], and, in doing so, demonstrates the relation of Khudawadi |𑋈| to Devanagari |त्र| (Sanskrit [t̪ɾə]). Bagster (1851, p. 12), too, lists |𑋈| [ʈɾ ~ t̪ɾ] separately from |𑋆| [ʈ] and |𑋍| [t̪]. What remains unclear, though, is why |𑋈| was also used for [ɖɾ].
Notably, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 typically features only one graph for each pair of voiced φ-plosives — [ɡ ɡʱ], [d͡ʑ d͡ʑʱ], [ɖ ɖʱ], [d̪ d̪ʱ] and [b bʱ] — but assigns dedicated graphs to each of the φ-implosives [ɠ ʄ ɗ ɓ] (Stack, 1849a, p. 1). Such a distribution was also seen in other unstandardised Landa-based scripts, including Multani and Khojki (see Chapter 10). Masica (1991) traces this phenomenon to a supposed a recalibration of canonical phone-graph correspondences:
[…] it would appear that in the various mercantile scripts of Laṇḍā type used in Sind, the distinctive Sindhi [φ-]implosives were written with the symbol originally standing for the voiced plosive, while the ordinary voiced and aspirate voiced plosives (g/gh, etc.) were both written with another set of symbols and not clearly distinguished from one another.
Furthermore, in a homorganic nasal-stop φ-consonant cluster such as [mb], the nasal element was usually not written. Likewise, the nasalisation of φ-vowels was also graphematically unmarked. Again, such practice was in line with those observed in Landa-script-based writing systems, as attested by Pandey in the context of Marwari-Mahajani (𝚖𝚠𝚛-𝙼𝚊𝚑𝚓) (Pandey, 2011c, p. 3):
[Phonological] Nasalization is not represented using special signs, such as ANUSVARA. The letter 𑅧 NA is used in cases where nasalization is explicitly recorded. In several cases, words are written simply with [γ-]nasalization deleted, eg. Devanagari हुंडी huṃḍī and Mahajani 𑅱𑅠 hḍ.
An early specimen of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 is found in Prinsep’s (1837) review of Wathen’s Sindhi grammar (§5.1), on a facsimile of a Sindhi hundi — an indigenous bill of exchange. The 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 text on the hundi, along with Prinsep’s auxiliary transcriptions into 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗 are reproduced in Figure 8.1.



Source: Prinsep (1837, p. 352 foldout)
The 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 text in Figure 8.1, accompanied by an IPA transcription and gloss based on Prinsep’s (1837) interpretation, is shown in (19):112
(19)
| 𑋒 | 𑋂 | 𑋝 | 𑋚 | 𑋗 | 𑋍 | 𑋞 | 𑋛 | 𑊼 | 𑋌 | 𑋔 | 𑊲 | 𑋆 | 𑊺 | 𑋀 | 𑋐 |
| pu | d͡ʑᵊ | sə | la | mᵊ | t̪i | ɦo | ʋẽ | ɡʱə | ɳi | bʱa | i | ʈe | kᵊ | t͡ɕə | n̪d̪ᶷ |
| ‘(I) pray that health may be abundant to brother Tek Chand’ | |||||||||||||||
| 𑋁 | 𑋔 | ॥ | 𑋑 | 𑋎 | 𑋊 | 𑊰 | 𑋋 | 𑊽 | 𑋘 | 𑊿 | 𑊻 | 𑋈 | 𑋓 | 𑊴 | 𑋉 |
| t͡ɕʰa | bᵊ | ɾa | na | t̪ʰᶷ | ɽa | e | ɖʱᵊ | ɠə | d͡ʑə | ŋ | kʰə | ʈɾɪ | pʰə | ɗa | u |
| ??? | |||||||||||||||
| 𑋑 | 𑋗 | ॥ | 𑋵 | 𑊲 | 𑋵 | 𑋂 | 𑋛 | 𑋞 | 𑋍 | 𑋞 | 𑋂 | 𑋕 | 𑋌 | ॥ | 𑋵 | 𑊲 | 𑋵 | 𑋂 | 𑋞 | 𑋵 | ॥ | 𑋔 | ॥ | 𑋶 | 𑋛 | 𑋌 |
| ni | mᶦ | ɾʊ | pᶦ | e | pə | nd͡ʑᶷ | ʋi | ɦᵊ | tə̃ | ɦᶦ̃ | d͡ʑa | ɓi | ɳa | ɾʊ | pᶦ | e | pə | nd͡ʑa | ɦᶷ | pu | ɾa | bʱə | ɾe | ɗɪ | ʋə | ɳa |
| ‘One half (being) rupees twenty-five, double fifty, to be paid in full’ | ||||||||||||||||||||||||||
This example of a 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 text succinctly illustrates the need to rely on graphematic and sociolinguistic context to unpack its meaning, without which the text assumes a cryptic nature. As shown in (19), Prinsep (1837, p. 352) is able to decode and decipher the first line of the salutation and the countersign. However, he is unable to offer a cogent decipherment of the second line, offering instead this explanation:
The second line has probably a meaning also, but not a single word of it can be found in [Wathen’s] vocabulary; nor can the natives be persuaded to divulge it, whether from superstitious prejudice or from ignorance.
The 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 text on the hundi also exemplifies several of the characteristics outlined in the previous section. As Figure 8.1 reveals, a postconsonantal φ-vowel, i.e., one in a φ-[CV] sequence, is not marked in writing. In a φ-[VV] sequence, the second φ-[V] is unpredictably denoted with |𑊰 𑊲 𑊴|. A voiced φ-plosive and its aspirated version are indicated by the same graph, while φ-implosives have distinct graphs. Nasalisation of φ-vowels and the nasal component in a homorganic nasal-oral φ-consonant cluster are not indicated. Also absent are any regular patterns of word spacing or punctuation.
One of the largest extant corpora of early 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 writing is found in an unpublished handwritten wordlist compiled by British orientalist and administrator Edward Backhouse Eastwick. The wordlist comprises a list of English headwords and their Sindhi equivalents transcribed in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, accompanied by an 𝚎𝚗-𝙻𝚊𝚝𝚗-influenced 𝚜𝚍-𝙻𝚊𝚝𝚗 transcription. In a later publication (Eastwick, 1883, p. 63 footnote), the author claims his wordlist contains approximately 2200 entries. He also states its completion date as 1840, although the handwritten manuscript of the worldlist is dated 1843. A few years after its completion, Eastwick (1849, p. 119) sheds further light on the preparation of his wordlist or “Vocabulary”:
In preparing the Vocabulary, I, of course, had to learn the [Khudawadi] character, which has this peculiarity, that only initial [γ-]vowels (with a very few exceptions,) are written: consequently, there is the greatest difficulty in decyphering [sic] writings, for only the [γ-]consonants appear, and you must insert the [φ-]vowels as you think will best suit the sense. Thus, the word Pirín [
pᶦɾĩ], “beloved,” is written exactly like pare [pəɾe], “beyond,” for only the p and the r are represented [𑋒𑋙]. The consequence of such an elliptical mode of writing is, that even the natives make egregious blunders in extracting the pith of the queer little epistles with which their correspondents favour them.
Eastwick’s wordlist also groups the Sindhi terms into the speech varieties of “Sár” and “Lár”, corresponding to upper and lower Sindh, respectively. However, the latter category of words is only sparsely populated. A selection of entries from Eastwick’s list, along with their present-day pronunciations in standard Sindhi, is shown in Table 8.2.
| Page | English headword | Sindhi equivalent in “Dialect of Sár” | Modern pronunciation | Notes | |
|---|---|---|---|---|---|
| 1 | Abandon, to | Chhadiyan | 𑋁𑋊𑋌 | t͡ɕʰəɗəɳᶷ |
𑋊 = [ɗ] |
| 26 | Good | Chango, Mocháro | 𑋀𑋅 𑋗𑋀𑋙 | t͡ɕʰəŋo mot͡ɕaɾo |
𑋅 = [ŋ] |
| 26 | Go, to | Wanyan, Halan | 𑋛𑋅𑋌 𑋞𑋚𑋌 | ʋəɲəɳᶷ ɦələɳᶷ |
𑋅 = [ɲ] |
| 18 | Deserted | Sunya | 𑋝𑊿 | sʊɲᵊ |
𑊿 = [ɲ] |
| 11 | Cage | Pinjro | 𑋒𑊿𑋙 | pɪɲᵊɾo |
𑊿 = [ɲ] |
| 11 | Carder of cotton | Pinyáro | 𑋒𑊿𑋙 | |
𑊿 = [ɲ] |
| 32 | Jump, to | Trapan | 𑋈𑋒𑋌 | ʈ(ɾ)əpəɳᶷ |
𑋈 = [ʈɾ] |
| 41 | Ocean | Samundr | 𑋝𑋗𑋈 | səmʊɳɖ(ɾ)ᶷ |
𑋈 = [ɖɾ] |
| 33 | Know, to | Jánan | 𑋃𑋙𑋌 | ʄaɳəɳᶷ |
𑋃 = [ʄ]𑋙 = [ ɳ ~ ɽ] |
| 40 | Net | Járó | 𑋃𑋙 | ʄaɾo |
𑋃 = [ʄ] |
| 41 | Obligation | Thoro | 𑋎𑋙 | t̪ʰoɾo |
|
| 48 | Read, to | Parhan | 𑋒𑋙𑋌 | pəɽʱəɳᶷ |
𑋙 = [ɽʱ ~ ɾʱ] |
| 60 | Violence | Jor | 𑋂𑋊 | zoɾᶷ |
𑋂 = [d͡ʑ ~ z]𑋊 = [ ɾ] |
| 41 | Opium | Afím | 𑊰𑋓𑋗 | əfim |
|
| 11 | Cardamoms | Phonto | 𑋓𑋆 | pʰoʈo |
|
| 41 | Ornament | Gahnah | 𑊽𑋞𑋌 | ɠɛɦᵋɳo (sg.) ɠɛɦᵋɳa (pl.) |
𑊽 = [ɠ] |
| 60 | Village | Gót, Wasti | 𑊽𑋆 𑋛𑋝𑋍 | ɠoʈʰᶷ ʋəsᶦt̪i |
𑊽 = [ɠ] |
| 40 | Necessary(ies) | Ghurjé | 𑊼𑋙𑋂 | ɡʱʊɾᶦd͡ʑe |
𑊼 = [ɡʱ] |
| 41 | Tail | Dhrigho | 𑋈𑊼 | ɖ(ɾ)ɪɡʱo |
𑋈 = [ɖɾ]𑊼 = [ ɡʱ] |
| 35 | Lick | Chatan | 𑋀𑋆𑋌 | t͡ɕəʈəɳᶷ |
𑋆 = [ʈ] |
| 35 | Lid | Dhakan | 𑋆𑊺𑋌 | ɖʱəkəɳᶷ |
𑋆 = [ɖʱ] |
| 14 | Coppersmith | Thántháro | 𑋆𑋋𑋙 | ʈʰaʈʰaɾo |
𑋋 = [ʈʰ] |
| 11 | Cake | Laddu | 𑋚𑋉 | ləɖũ |
𑋉 = [ɗ] |
| 57 | Tooth | Dand | 𑋉𑋏 | ɗən̪d̪ᶷ |
𑋉 = [ɗ]𑋏 = [ d̪] |
| 61 | Wash, to | Dhuwan | 𑋏𑋛𑋌 | d̪ʱʊəɳᶷ |
𑋏 = [d̪ʱ] |
| 61 | Tie, to | Bandhan | 𑋕𑋏𑋌 | ɓən̪d̪ʱəɳᶷ |
𑋕 = [ɓ]𑋏 = [ d̪ʱ] |
| 34 | Language | Boli | 𑋕𑋚 | ɓoli |
𑋕 = [ɓ] |
| 61 | Wall | Bhit | 𑋔𑋍 | bʱɪt̪ᶦ |
𑋔 = [bʱ] |
| 57 | Tongue | Jibh | 𑋃𑋔 | ʄɪbʱᵊ |
𑋃 = [ʄ]𑋔 = [ bʱ] |
| 41 | Oppression | Julm | 𑋂𑋚𑋗 | zʊlᶷmᶷ |
𑋂 = [d͡ʑ ~ z] |
| 64 | Yesterday, day before | Tiyo-din | 𑋈𑊲 𑋉𑋞 | ʈ(ɾ)ᶦjõ ɗĩɦᶷ |
𑊲 = [jo ~ jõ]𑋉 = [ ɗ] |
| 17 | Dark | Andháro, Undhai | 𑊰𑋏𑋙 𑊰𑋏𑋞𑊲 | ən̪d̪ʱaɾo un̪d̪ɛɦᵋ |
𑊰 = [ə ~ u]𑊲 = [ ᶦ] |
| 2 | After | Poi | 𑋒𑊰 | poᶦ |
𑊰 = [ᶦ]alphabetical |
| 3 | Also | Bhí | 𑋔𑊲 | bʱi |
𑊲 = [ᶦ]alphabetical |
| 3 | Among | Wich, Men | 𑋛𑋀 𑋗𑊲 | ʋɪt͡ɕᵊ mẽ |
𑊲 = [ẽ] |
| 3 | And | Own, Biyo | 𑊰𑊲 𑋕𑊰 | əũ ɓᶦjo |
𑊲 = [ũ]𑊰 = [ o] |
| 11 | Carry, to | Niyan | 𑋑𑊰𑋌 | nɪəɳᶷ |
|
| 64 | Yes | Hân | 𑋞𑊰 | ɦa |
𑊰 = [a]alphabetical |
| 15 | Copulate, to | Jahan | 𑋂𑋞𑋌 | jəɦəɳᶷ ~ d͡ʑəɦəɳᶷ |
𑋂 = [d͡ʑ ~ j] |
| 56 | Thing | Shai | 𑋝𑊰 | ɕɛ ~ ɕəɪ̯ |
𑋝 = [ɕ ~ s]𑊰 = [ ᶦ] |
Table 8.2 shows that the 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 entries in Eastwick (1843a) largely agree with the graph inventory and phonological values outlined in Table 8.1. Minor areas of divergence in Eastwick’s work include the transcription of [ɾ] with the Shikarpuri allograph |𑋙| (Grierson, 1919, p. 18; Stack, 1849a, p. 8), instead of the traditional Khudawadi graph |॥|. Minor graphetic variation is also seen in the shapes of |𑋅 𑊿| [ŋ ɲ], with Eastwick’s work depicting the dot element in these graphs with a circle (Grierson, 1919, p. 101). Overall, though, the 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 spellings in Eastwick (1843a) largely correspond with their modern-day pronunciations, with unexpected spellings usually reflecting phonologically plausible variations. For instance, in present-day Sindhi, the word for ‘to know’ is pronounced [ʄaɳəɳᶷ]. Theoretically, the corresponding 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 transcription of this pronunciation would be |𑋃𑋌𑋌|. In contrast, Eastwick’s wordlist (1843a, p. 33) provides the spelling |𑋃𑋙𑋌|. In Eastwick’s spelling, the presence of |𑋙| in place of medial |𑋌| can be easily explained as reflecting an idiolectal surface realisation [ʄaɾ̃əɳᶷ], which is consistent with the [ɽ ~ ɾ] alternation common in spoken Sindhi. An analogous alternation between [ɳ] and [ɽ̃] has also been attested (§4.3.1, Consonant allophony).
Graphematically, Table 8.2 affirms the abjadic practice prevalent in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, with most φ-vowels not marked in writing. Exceptions include the entries |𑋞𑊰| [ha] ‘yes’ and |𑋔𑊲| [bʱi] ‘also’, where the sole φ-vowel in these monosyllabic words is explicitly marked using a free γ-vowel. Typologically, such practice is effectively alphabetic (Pandey, 2011c, pp. 2–3).
Eastwick’s Sindhi wordlist was subsequently published in the Journal of the Asiatic Society of Bengal (Eastwick, 1843b; credited as ‘J. B. Eastwick’) but with the Sindhi text printed only in Roman. The omission of the 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 is attributed to unavailability of metal types for the script (Eastwick, 1843b, p. 1). Half-a-century later, Eastwick’s Sindhi wordlist was republished, this time accompanied by a Punjabi one (Eastwick, 1883). However, this trilingual wordlist, too, was published entirely in the Roman script, despite Khudawadi and Gurmukhi types being available by then.
Looking back from a present-day perspective, one may be tempted to regard Eastwick’s wordlist as amateurish. Indeed, the work has received its share of criticism, with Hoernle (1885, p. 162) dismissing it as “a promiscuous collection of words”. Vindicating Hoernle’s description are entries like ‘penguin’, cited as “Píán 𑋒𑊰𑋑” in the handwritten manuscript (Eastwick, 1843a, p. 46) and as “peean” in the print version (Eastwick, 1843b, p. 14). Evidently, Eastwick did not consider it linguistically or ecologically anomalous to find a word for ‘penguin’ in the language of a subtropical, semi-arid region in the northern hemisphere. The Sindhi gloss for ‘penguin’ might be a misinterpretation of the Sindhi word for ‘pelican’, [peɳᶦ] (Mewaram, 1910, p. 160; Stack, 1855, p. 248), although this remains conjectural.
Despite its shortcomings, Eastwick’s vocabulary remains invaluable as a historical-grapholinguistic artefact. Moreover, the biscriptal listing of Sindhi entries in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝙻𝚊𝚝𝚗 acts as a parallel text. Despite its anglicised nature and opaqueness, the 𝚜𝚍-𝙻𝚊𝚝𝚗 text often helps fill in graphematic and phonological gaps in the abjadic 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 entries, especially when it comes to vowels.
At this stage, it is worth revisiting the apocryphal jokes on misinterpretations arising from abjadic 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 writing described in Section 5.1.1. The examples cited are reiterated in (20), transcribed in the IPA as well as in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍. To reiterate, the humour in these jokes hinges on the multiple ways in which the 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 writing may be decoded. Evidently, such a supposition implies that all of the possible phonological interpretations are necessarily written identically in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍. That is, the phonological strings mentioned in the jokes are homographic in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍. However, a closer look at the 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 transcriptions in (20) suggests otherwise, raising doubts on the graphematic plausibility of these jokes.
(20)
| Sindhi-language message | Corresponding 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 transcription | |
|---|---|---|
| Grierson (1919, p. 14 footnote): | ||
| Writer’s intention | [nəɳɖʱ(ɾ)i ʋəɦi puʈʰe sud̪ʱi]‘small notebook with cover’ |
𑋑𑋈𑋛𑋞𑋒𑋆𑋝𑋏 | Reader’s interpretation | [nəɳɖʱ(ɾ)i ʋəɦu puʈ(ɾ)ə sud̪ʱi]‘youngest daughter-in-law with (her) son’ |
𑋑𑋈𑋛𑋞𑋒𑋈𑋝𑋏 |
| Interviewee 26M (see Chapter 13): | ||
| Writer’s intention | [ɦu əd͡ʑᶦmeɾᶦ ʋᶦjo]‘He went to Ajmer town’ |
𑋞𑊰𑋂𑋗𑋙𑋛𑊲 |
| Reader’s interpretation | [ɦu əʄᶷ məɾi ʋᶦjo]‘He died today’ |
𑋞𑊰𑋃𑋗𑋙𑋛𑊲 |
The transcriptions in (20) reveal that, in the first joke, the φ-word [puʈʰe] ‘cover (oblique)’ would be written |𑋒𑋆| or |𑋒𑋇| in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 (see Eastwick (1843a, p. 5) for the homographic cognate [pʊʈʰᶦ]). Further, [puʈ(ɾ)ə] ‘son (oblique)’ would likely appear as |𑋒𑋈| (Eastwick, 1843a, p. 53). This emerges from the fact that, in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, [ʈʰ] and [ʈ(ɾ)] were written with distinct graphs (see Table 8.1). Moreover, writers usually adhered to the graphematic distinction between the two. In the second joke, [əd͡ʑᶦmeɾᶦ] ‘to Ajmer’ would be spelt |𑊰𑋂𑋗𑋙|, and [əʄᶷ məɾi] ‘today (he/she) died’ as |𑊰𑋃𑋗𑋙|. Here, too, the φ-consonants [d͡ʑ] and [ʄ] would usually be graphematically distinguished in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 writing. Casting further doubt on the authenticity of these wordplays is the fact that similar witticisms are found in the context of other abjadic writing systems such as Hindi-Mahajani (Beames, 1872, p. 56).113 Hence, while amusing tales on the multiple interpretations of supposed homography in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 have become culturally iconic, their graphematic veracity remains dubious.
8.2 ‘Improved Hindu Sindhi’
Section 5.2 revealed the belief prevalent among several colonial-era European administrators and intellectuals that Hindu-Sikh Sindhis would not learn 𝚜𝚍-𝙰𝚛𝚊𝚋 due to religious prejudice and the Arabic script’s semiotic associations with Islam. Having witnessed the prevalence of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 among the mercantile Vania caste of Hindu-Sikh Sindhis, Barrow Ellis decided to standardise 𝚜𝚍-𝚂𝚒𝚗𝚍 and mandate it in government schools as an incentive for Vania children to attend. By 1869, a revised and standardised 𝚜𝚍-𝚂𝚒𝚗𝚍 graph inventory and graph-phone correspondences had been finalised under the supervision of then-Deputy Educational Inspector of Sindh, Narayan Jagannath Vaidya. This particular subvariant of Sindhi-Khudawadi will be referred to by the language subtag 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 (§5.2.3).
Colonial sources often describe 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 as “(improved) Hindu Sindhi” (Hughes, 1876, p. 373) or “(improved) Hindi Sindhi” (Grierson, 1919, p. 19). Pandey (2011a, p. 2) states that the adjective ‘Hindu’ or ‘Hindi’ refers to the Indic origin of the underlying Khudawadi script, while also distinguishing the writing system from 𝚜𝚍-𝙰𝚛𝚊𝚋 or ‘Arabic Sindhi’.
8.2.1 Phonograms
Table 8.3 shows the main phonograms in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 and their phonological values.
Sources: Grierson (1919, pp. 19–20) and Thanvardas (1873, pp. 1–4)
[table]
Compared to 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 (Table 8.1), 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿’s graph inventory and graph-phone correspondences comprise several salient modifications. The most significant one was to assign the rasms used for γ-consonants the phonological value φ-[CV₀], where [V₀] was [ə]. This established 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿’s status as an abugida (see Figure 2.3) and distinguished it typologically from the abjadic 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍. Graph-phone correspondences were also regularised. The graph|𑋂| [d͡ʑə] was listed as distinct from |𑋘| [jə], which implicitly reinforced the contrastiveness of the φ-consonants they denoted. Similarly, |𑋈| [ɖə] was codified separately from |𑋋| [ɖʱə]. In addition, [ʈɾə ɖɾə ɖʱɾə] were considered allophones of [ʈə ɖə ɖʱə], respectively, based on which they were simply written |𑋆 𑋈 𑋋|. This meant the 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 contrast between |𑋈| [ʈɾ ~ t̪ɾ] and |𑋆| [ʈ] was effectively neutralised in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿. |𑋊| was mapped to [ɽə], although no dedicated graph was assigned to [ɽʱə]. The graph |𑋙| was taken from the Shikarpuri inventory of Landa (§5.2.3) and assigned to [ɾə]. The Khudawadi-style graph |॥| [ɾə] was rejected, presumably to avoid graphetic confusion with |𑋌| [ɳə ~ ɽ̃ə] or with the logograms for fractions (§8.2.3). Finally, new graphs were created from existing ones where needed. The rasms |𑊼 𑋂 𑋏 𑋔| denoting the voiced unaspirated φ-plosives [ɡə d͡ʑə d̪ə bə] were graphetically modified as |𑊾 𑋄 𑋐 𑋖| to create unique graphs for the voiced aspirate φ-plosives |𑊾 𑋄 𑋐 𑋖| [ɡʱə d͡ʑʱə d̪ʱə bʱə]. Likewise, a curl was added to the rasm |𑋝| [sə] to create |𑋜| [ɕə]. Based on precedent from 𝚙𝚊-𝙶𝚞𝚛𝚞 and perhaps 𝚑𝚒-𝙳𝚎𝚟𝚊 (see (11)), the rasms |𑊻 𑊼 𑋂 𑋓| [kʰə ɡə d͡ʑə pʰə] were graphetically augmented with a subfixed nuqta to create |𑊻𑋩 𑊼𑋩 𑋂𑋩 𑋓𑋩| [xə ɣə zə fə]. Although graphematically licensed, |𑊺𑋩| [qə] was not commonly attested. The graphs for the implosives were largely unchanged from 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍.
The new system also addressed one of the principal criticisms of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 by introducing distinct γ-vowels into the inventory to match the number of φ-vowels in spoken Sindhi. The rasms |𑊰 𑊲 𑊴| were laid down as the free γ-vowels for [ə ɪ ʊ], including their reduced allophones [ᵊ ᶦ ᶷ]. This was accompanied by a full set of bound γ-vowels |𑋠 ◌𑋡 ◌𑋢 ◌𑋣 ◌𑋤 ◌𑋥 ◌𑋦 ◌𑋧 ◌𑋨| corresponding to [a ɪ i ʊ u e ɛ o ɔ]. The graphetic shapes of the bound γ-vowels were inspired by those in the Gurmukhi inventory (Pandey, 2010d, p. 24). The inventory of γ-vowels in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 was completed by appropriately concatenating the rasms |𑊰 𑊲 𑊴| with the aforementioned bound allographs to create the free forms |𑊱 𑊳 𑊵 𑊶 𑊷 𑊸 𑊹| [a i u e ɛ o ɔ]. The complementary distribution of free and bound γ-vowels made 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 an alphasyllabary (see Figure 2.3). Rounding off the inventory of bound γ-vowels was a virama |𑋪|.
Other bound graphs in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 included an anusvara |𑋟|. Like its present-day 𝚑𝚒-𝙳𝚎𝚟𝚊 counterpart (see (13)), the 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 anusvara could denote either the nasalisation suprasegmental of a φ-vowel, or the nasal segment in a homorganic nasal-oral φ-consonant cluster. In the context of the latter, it became system-internal practice to write phonological sequences like [ns nɕ] not with anusvara but with ‘full’ |𑋑𑋪| [n]. Thus, the Sindhi word [mʊn(ᶦ)ɕi] ‘secretary, scribe’ was written |𑋗𑋣𑋑𑋪𑋜𑋢| (Thanvardas, 1873) rather than |𑋗𑋣𑋟𑋜𑋢|. Analogous to its counterpart in 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙳𝚎𝚟𝚊, the anusvara in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 can co-occur with free as well as bound γ-vowels. Certain Sindhi primers in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 (Thanvardas, 1873) also listed a bound visarga |◌𑈺| as a canonical equivalent of the 𝚜𝚊-𝙳𝚎𝚟𝚊 visarga. However, outside of didactic charts of the 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 alphasyllabary, the visarga does not seem to have been used in everyday writing. Grierson (1919, p. 19) does not list a visarga as part of the 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 graph inventory.
8.2.2 Spelling and orthography
Early publications in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 include the primers |𑋞𑋡𑋟𑋏𑋤 𑋝𑋡𑋟𑋐𑋢 𑋒𑋞𑋪𑋙𑋡𑋘𑋧𑋟 𑊺𑋡𑋍𑋠𑋔𑋣| ‘Hindu-Sindhi First Book’ (1873) and |𑋝𑋡𑋟𑋐𑋢 𑋕𑋡𑊸 𑊺𑋡𑋍𑋠𑋔𑋣| ‘Sindhi Second Book’ (1871) by Udharam Thanvardas Mirchandani and |𑋝𑋡𑋟𑋐𑋣𑋂𑋢 𑋗𑋣𑊻𑋩𑋪𑋍𑋝𑋙𑋪 𑋍𑋠𑋙𑋢𑊻𑋩| ‘A Brief History of Sindh’ (1871) by Alumal Trikamdas Bhojwani.114 All these works were intended as school textbooks for Vania children. Since types for 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 were cast only after 1872 (Government of Bombay, 1874, p. 262), the aforementioned books were all lithographed. Figure 8.2 shows an extract from Thanvardas (1873, p. 10), followed by an IPA transcription of the ‘spelling pronunciation’ suggested by the text, as well as of the modern standard Sindhi pronunciation where required.

| 𑋑𑋡𑋍𑋣 | 𑋗𑊺𑋪𑋍𑋔𑋗𑋥𑋟 | 𑋛𑋅𑋪𑋂𑋥 – | 𑊰𑋛𑋚𑋪 | 𑊱𑊻𑋩𑋤𑋟𑋏𑊻𑋥 | 𑋝𑋚𑋠𑋗𑋣 |
| nɪt̪ᶷ | mək(ᵊ)t̪əbᵊmẽ | ʋəɲ(ᶦ)d͡ʑe | əʋəl(ᶦ) | axun̪d̪ᵊkʰe | səlamᶷ |
| 𑊺𑋡𑋂𑋥 | 𑋒𑋧𑊲 | 𑋒𑋙𑋪𑋞𑋌 | 𑋛𑋥𑋞𑋪𑋂𑋥 – | 𑋒𑋙𑋪𑋞𑋌𑋂𑋥 | 𑋛𑋥𑋚𑋥 |
| kɪd͡ʑe ~ kəd͡ʑe | poᶦ | pəɽʱəɳᵊ | ʋeɦ(ᶦ)d͡ʑe | pəɽʱəɳᵊd͡ʑe | ʋele |
| 𑋕𑋢𑊰 | 𑊺𑋟𑋞𑋡𑋟 | 𑊽𑋠𑋚𑋪𑋞𑋡𑋂𑋥 | 𑋐𑋡𑋘𑋠𑋑𑋣 | 𑋑𑊺𑋡𑋂𑋥 | 𑊰𑋟𑊲𑋟 |
| ɓiᵊ | kɛ̃ɦᵋ̃ | ɠalʱᶦd͡ʑo | d̪ʱᶦjanᶷ | nəkɪd͡ʑe ~ nəkəd͡ʑe | ə̃ɪ̃ ~ ɛ̃ |
| 𑊺𑋟𑋞𑋡𑋟 | 𑋁𑋧𑊺𑋙𑋝𑋠𑋟 | 𑋔𑋡 | 𑋑𑊽𑋠𑋚𑋪𑋞𑋠𑊲𑋂𑋥– | ||
| kɛ̃ɦᵋ̃ | t͡ɕʰokəɾᵊsã | bᶦ | nəɠalʱaᶦd͡ʑe | ||
“Go to school every day. First, greet your teacher, then sit down to study. When studying, do not think about anything else, nor talk with another boy.”
Compared to the abjadic 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 (see Figure 8.1), the most striking visual aspect of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 as demonstrated by Figure 8.2 is the presence of bound γ-vowels. Also present in Figure 8.2 are so-called ligatures, or complex graphs derived from two distinct rasms. An example is | | [
| [pəɽʱəɳᵊ] ‘to study (oblique)’, in which [ɽʱə] is denoted by a so-called ligature of |𑋙| [ɽə] and |𑋞| [ɦə]. Indeed, the three 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 textbooks in question (Trikamdas, 1871; Thanvardas, 1871; 1873) feature several so-called ligatures involving the rasms |𑋞| [ɦə] and |𑋘| [jə] as the secondary graphetic element. This practice may have been influenced by the 𝚙𝚊-𝙶𝚞𝚛𝚞 practice of using the bound allographs |੍ਹ| [ɦə] and |੍ਯ| [jə] to denote [ɦə] and [jə] as the second element in a φ-consonant sequence (see §8.3 & Table 9.1). At first glance, the attestation of ligatures based on |𑋞| [ɦə] and |𑋘| [jə] appears to contradict Pandey’s (2011a, p. 3) statement that 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 does not feature “half-forms and ligatures”. The discrepancy may be explained if one looks at subsequent publications in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 printed using movable type. The typeset publications do not feature complex graphs or ligatures of the kind attested in the earlier lithographed textbooks. The eschewing of complex graphs may have been a deliberate typographical decision aimed at simplifying the printing process. The legacy of dispensing with complex graphs in the standardised Khudawadi graph inventory and favouring atomic graphs continues to influence present-day Khudawadi typography. At the time of writing this book, no publicly available Unicode-compliant Khudawadi fonts allowed for the automatic rendering of complex graphs involving |𑋞| [ɦə] and |𑋘| [jə].
Aside from the aforementioned bound allographs for |𑋞| [ɦə] and |𑋘| [jə], therefore, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 was almost completely devoid of noteworthy complex graphs of any kind. Consequently, another visually conspicuous aspect of early 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 text is the liberal use of the virama. That said, if one assumes that the use of a virama necessarily indicates the absence of a φ-vowel, the presence of a virama in word-final position contradicts the phonological maxim that all Sindhi words end in a φ-consonant (§4.3.2). For instance, in Figure 8.2, the spelling |𑊰𑋛𑋚𑋪| ‘first’ graphematically corresponds to the pronunciation [əʋəl], which is φ-consonant-final. In contrast, present-day 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 feature the spellings |اَوَلِ| and |अवलि|, respectively, both of which correspond to the φ-vowel-final pronunciation [əʋəlᶦ] (Rohra, Bijani, & Gurnani, 2011, p. 24; Sindhi Language Authority, 2021d). Needless to say, colloquial pronunciation may vary on a spectrum between the two.
Other noteworthy spelling practices in Figure 8.2 include the absence of a graphomorphemic boundary in |𑋗𑊺𑋪𑋍𑋔𑋗𑋥𑋟| [məkᵊt̪əbᵊmẽ] ‘in(to) school’, |𑊱𑊻𑋩𑋤𑋟𑋏𑊻𑋥| [axun̪d̪ᵊkʰe] ‘to the teacher’ and |𑋑𑊽𑋠𑋚𑋪𑋞𑋠𑊲𑋂𑋥| [nəɠalʱaᶦd͡ʑe] ‘should not talk’. In these spellings, the postpositions |𑋗𑋥𑋟| [mẽ] ‘in(to)’ and |𑊻𑋥| [kʰe] ‘to’, and the negation particle |𑋑| [nə] ‘no, not’ are graphematically fused with their nominal or verbal stems. This contrasts with practice in later 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 texts (see Figure 8.3) as well as in present-day 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 writing, in which postpositions and stems are almost always separated by a graphematic space. Along similar lines, Figure 8.2 features the Sindhi word for ‘and’, [ɛ̃ ~ əĩ], spelt as |𑊰𑋟𑊲𑋟|. However, a few pages later in the same publication, the word is spelt |𑊰𑋟𑊳𑋟| (Thanvardas, 1873, p. 25). The spelling |𑊷𑋟| (see Figure 8.3) was eventually settled on, which is graphematically analogous to the now-obsolete 𝚜𝚍-𝙳𝚎𝚟𝚊 |अैं| (§7.5.2).
Notwithstanding government efforts to standardise and popularise 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, the Vania community persisted with 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 in their personal lives (§5.2.3). As a result, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 never got off the ground, and government publications in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 had nearly ceased by 1910 (Hotchand & Bhojwani, 1982 [1915], p. 165 footnote). Occasional publications in the system, typically by community outsiders, continued to appear into the early twentieth century. A Sindhi translation of the Bible’s Gospel of Matthew in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 was published in 1913 from Lahore, transliterated from existing 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙶𝚞𝚛𝚞 editions (Nida, 1972, p. 393). An extract of this translation is shown in Figure 8.3.

| 𑋍 | 𑋍𑋤𑋟 | 𑋒𑋡𑋙𑋪𑋖𑋤 | 𑋒𑋟𑋞𑋡𑋟𑋂𑋥 | 𑋒𑋙𑋡𑋗𑋥𑋝𑋙 | 𑊻𑋥 | 𑋒𑋤𑋃𑋡; |
| t̪ə | tũ | pɪɾᶦbʱu | pɛ̃ɦᵋ̃d͡ʑe | pəɾᶦmesəɾᵊ | kʰe | puʄᶦ |
| 𑊷𑋟 | 𑋙𑋣𑊽𑋧 | 𑊴𑋑𑋪𑋞𑋢𑊰 | 𑋂𑋢 | 𑊳 | 𑋜𑋥𑋛𑋠 | 𑊺𑋙𑋡 – |
| ɛ̃ | ɾuɠo | ʊnʱiᵊ | d͡ʑi | i | ɕeʋa | kəɾᶦ |
“Worship the Lord your God and serve Him only”
Source: Nida (1972, p. 393)
Serving as a particularly useful source of Sindhi texts is the Linguistic Survey of India (Grierson, 1919), thanks to its collection of parallel texts in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚜𝚝𝚊𝚌𝚔 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹, accompanied by a Roman transliteration. Extracts of the Biblical Parable of the Prodigal Son in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 as published in Grierson (1919, p. 101) are shown in Figure 8.4.115


Figure 8.4 reveals that Grierson’s 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 text features graph-phone correspondences and spelling principles similar to those in Thanvardas (1871; 1873) and Trikamdas (1871). Where it differs from the latter is in being devoid of complex graphs or ligatures of any kind. That said, the text samples in Grierson (1919) were intentionally commissioned. Hence, one may consider these texts ‘manicured’ and not reflective of everyday writing practice. At the same time, the point may be somewhat moot, as 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 was never really used in everyday writing. Consequently, asserting the graphematic authenticity of any 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 text proves problematic.
Logograms and collation order
Compared to 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 was largely free of logographic elements, aside from numeral and punctuation graphs. Numeral graphs in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 were identical to those used in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍. In his review of Wathen’s Sindhi grammar, Prinsep (1837, p. 352) appears to state that certain 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 graphs do double duty as phonograms and numerals. On this basis, he draws a parallel with the Divehi-Thaana writing system, in which ten phonograms are graphetically derived from Arabic-script numerals:116
[W]ith one or two exceptions the letters are merely represented by ciphers, combinations of numbers, and fractional parts : for example 𑋌 (¾ths) for n ; 𑋀 (4) for ch ; &c. &c. !
Having on a former occasion noticed the singular application of the Arabic numerals to the alphabet of the Maldive islands, we were struck by the apparent similarity of the process here pointed out at the opposite extremity of India!
Indeed, in handwritten specimens (Stack, 1849b, p. 8; Thanvardas, 1871; 1873; Trikamdas, 1871), 𝚜𝚍-𝚂𝚒𝚗𝚍 numeral graphs may look very similar to certain γ-consonants. However, the graphetic resemblance is coincidental, and the Khudawadi numeral graphs are clearly related to their equivalents in the Devanagari and Gujarati inventories. Also coincidental is the graphetic similarity of the 𝚜𝚍-𝚂𝚒𝚗𝚍 rasms |॥| and |𑋌| (see Table 8.1) with then-prevalent numerical logograms |꠱| ‘half’ and |꠲| ‘three-fourths’, respectively (Pandey, 2007). The graphetic similarities between 𝚜𝚍-𝚂𝚒𝚗𝚍 numeral graphs and certain phonograms are shown in (21):
(21)
| 𝚜𝚍-𝚂𝚒𝚗𝚍 numerals | 𑋱 | 𑋲 | 𑋳 | 𑋴 | 𑋵 | 𑋶 | 𑋷 | 𑋸 | 𑋹 | 𑋰 |
|---|---|---|---|---|---|---|---|---|---|---|
| Graphetically similar phonogram | 𑋂 | 𑋐 | 𑋊 | 𑋀 | 𑋒 | 𑋉 | 𑋍 | 𑋆 | 𑋔 | 𑋛 |
| Phonological value in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 | d͡ʑ(ə) | d̪ʱ(ə) | ɽ(ə) | t͡ɕ(ə) | p(ə) | ɗ(ə) | t̪(ə) | ʈ(ə) | b(ə) | ʋ(ə) |
Early specimens of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 (Thanvardas, 1871; 1873; Trikamdas, 1871) are particularly light on punctuation, as seen in the sentence |𑋗𑋤𑋟𑊻𑋥 𑊴𑋅 𑋚𑊽𑋢 𑊱𑋞𑋥 𑋒𑋠𑋌𑋢 𑋉𑋥| [mũ kʰe ʊɲᵊ ləɠi aɦe paɳi ɖe] ‘I am thirsty give me water [sic]’ (Thanvardas, 1873, p. 7). That said, all three sources consistently use a hyphen-like graph |–| as a full stop or sentence separator (see Figure 8.2). While some later publications persisted with this graph (see Figure 8.3), others adopted an 𝚎𝚗-𝙻𝚊𝚝𝚗-style full stop (see Figure 8.4).
Being unstandardised, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 did not feature a specific collation order per se. The 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 sequence featured in Thanvardas (1873, p. 1) is as follows:
𑊺 𑊻 𑊽 𑊼 𑊾 𑊿 𑋀 𑋁 𑋂 𑋃 𑋄 𑋅 𑋆 𑋇 𑋊 𑋉 𑋈 𑋋 𑋍 𑋎 𑋏 𑋐 𑋑 𑋌 𑋒 𑋓 𑋕 𑋔 𑋖 𑋗 𑋘 𑋙 𑋂𑋩 𑋚 𑋛 𑋜 𑋝
𑋞 𑊻𑋩 𑊼𑋩 𑋓𑋩
𑊰 𑊱 𑊲 𑊳 𑊴 𑊵 𑊶 𑊷 𑊸 𑊹 𑊰𑋟 𑊰:
Noteworthy in Thanvardas’ collation order is his listing of the free γ-vowels after the γ-consonants, and not before as is commonly done based on the Sanskritic tradition. Also conspicuous is his inclusion of visarga within the compound graph |𑊰:|. However, and as mentioned in Section 8.2.1, Thanvardas likely included the visarga due to sociolinguistic pressure from the 𝚜𝚊-𝙳𝚎𝚟𝚊 inventory, only to give the 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 symbol chart a semblance of paradigmatic completeness. In no 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 publication does the visarga seem to appear in the body text.
8.3 Analysis
8.3.1 Graphematic typology
In the previous two chapters, we saw that, regardless of disparity in their graph inventories and graphematic-orthographic nuances, all subvariants of 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 were typologically alike. Nuances aside, all derivatives of 𝚜𝚍-𝙰𝚛𝚊𝚋 emerge as plenar alphasyllabaries, while those of 𝚜𝚍-𝙳𝚎𝚟𝚊 are abugidic alphasyllabaries. Can the same be said for 𝚜𝚍-𝚂𝚒𝚗𝚍’s subvariants, namely 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿? Or does the evidence require slotting them into separate typological categories?
The descriptions of unstandardised Sindhi-Landa in general (§5.1.4) and unstandardised Sindhi-Khudawadi or 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 in particular (§8.1) leaves little doubt on 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍’s abjadic nature. Apart from the γ-vowel rasms |𑊰 𑊲 𑊴|, of which |𑊰| was used most often, there was simply no graphematic provision in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 to denote Sindhi’s φ-vowels with any degree of predictability. Typologically, therefore, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 meets the definition of a true consonantary or abjad to a far greater extent than contemporary 𝚊𝚛-𝙰𝚛𝚊𝚋 or 𝚑𝚎-𝙷𝚎𝚋𝚛 do. On the other hand, “improved Hindu Sindhi” or 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, which was graphematically based on the Indic model and whose graphetics drew heavily on Gurmukhi, clearly falls into a distinct typological category. The incorporation of graphematic principles such as an ‘inherent’ or implicit [ə] in γ-consonants and the complementary use of free and bound vowel allographs conditioned by environment establish 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿’s credentials as an abugidic alphasyllabary.
Thus, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 represent a case of intrasystemic typological difference in that they fall into distinct typological categories despite involving the same language and script components. This finding reiterates the fact that the same language and script pair can be mapped onto each other in different ways, resulting in distinct graph-phone correspondences and, consequently, distinct typological categorisations. Such a conclusion also justifies preferring the term ‘graphematic typology’ to ‘script typology’ (§2.4), since it is the mapping between language and script that determines the system’s categorisation. Although relatively uncommon, intrasystemic differences in graphematic typology are by no means unusual. In contemporary times, a prominent instance of intrasystemic typological difference is that of Berber languages written in the Tifinagh script (𝚋𝚎𝚛-𝚃𝚏𝚗𝚐). Traditional 𝚋𝚎𝚛-𝚃𝚏𝚗𝚐 is largely devoid of graphematic devices to indicate φ-vowels and, therefore, lies on the abjadic end of the typological spectrum. In contrast, a recently devised 𝚋𝚎𝚛-𝚃𝚏𝚗𝚐 system involving an expanded graph inventory and reconfigured graph-phone mappings — known as neo-Tifinagh — allows for φ-vowels to be distinctly represented. This makes neo-Tifinagh an alphabet (Brenzinger, 2007; Buckley, 2010).
At this stage, it is worth revisiting the commonly attested characterisation of writing in unstandardised Landa — including 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 — as ‘shorthand’ writing.117 While this may be acceptable as a sociolinguistic or contextual label, how accurate is it as a graphematic label? As outlined in Section 2.10.2, a shorthand presupposes the existence of a longhand counterpart. However, this chapter has revealed that 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 existed without a corresponding longhand. Even after the introduction of a relatively standardised 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, unstandardised 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 continued to prevail independently, including after the standardised subvariant died out. Thus, the two cannot be considered shorthand and longhand counterparts of each other.
Another characteristic of a shorthand system listed by Daniels (1996b, p. 815) is its intended capturing of speech as well as writing. In other words, shorthand systems often serve a dual purpose, serving as an abbreviated notation for phonological and graphematic units. Evidently, the graphematic units are those of the corresponding longhand, which users are also assumed to be literate in. However, in the context of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, there was no longhand to speak of. Essentially, Sindhi Vanias who wrote in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 were using it only as a reference to speech units — namely segments, syllables and lexemes of spoken Sindhi. Moreover, the common depiction of a shorthand as a special or marked variant of a longhand fails to capture the use of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 as the customary, default or unmarked form among Sindhi Vanias. Indeed, for most Sindhi Vanias, it was the only form of writing they were literate in. The phenomenon of exclusive literacy in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 is comparable to the hypothetical scenario of users being literate in abjadic or near-consonantal 𝚊𝚛-𝙰𝚛𝚊𝚋 or 𝚑𝚎-𝙷𝚎𝚋𝚛 but not in their graphovocalised alphasyllabic variants. Thus, while unstandardised 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 may be justifiably described as abjadic or near-abjadic, it does not fulfil the graphematic criteria to be called a shorthand.
8.3.2 Graph inventory
As outlined in Section 5.1.4, the emergence of the term ‘Khudawadi’ reflects the fact that, notwithstanding the variability in its graph-phone correspondences, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 did feature a recognisable and, hence, a visually coherent graph inventory. In contrast, Khudawadi’s predecessors — the unstandardised Landa inventories — do not lend themselves as easily to being described as a visually consistent collection of graphs. This raises the terminological question of how the unstandardised Landa inventories should be depicted. Can the Landa inventories be considered a single ‘script’ manifesting as multiple typographical and stylistic variants? Or are they better understood as a family of scripts, wherein each typographical or stylistic variant — such as Khudawadi — is considered a distinct ‘script’?
In terms of nomenclature, the ISO 639 standard for language names and codes has a provision for the category of ‘macrolanguage’. For instance, Norwegian (ISO 639 code 𝚗𝚘) is considered a macrolanguage that encompasses the ‘languages’ Bokmål (𝚗𝚋) and Nynorsk (𝚗𝚗). In contrast, the ISO 15924 standard for script names and codes does not provide for a category of ‘macroscript’, which the Landa inventories would presumably fit under. Although ISO 15924 does list the option of 𝚉𝚣𝚣𝚣 as a ‘code for uncoded script’, using this code for the Landa inventories might imply that Landa is distinct from Khudawadi, in the process blurring the intrinsic relation between them. From the perspective of Unicode, Pandey (2010a) proposes that fonts for regional varieties of Landa not already encoded in Unicode utilise the Khudawadi block as the foundation for their characters, with glyphs designed to reflect the desired Landa variant. In terms of encoding, such an approach is akin to designing Fraktur or Gaelic fonts based on the Unicode codepoints for Roman-script characters, or Nastaliq fonts that utilise the same Arabic-script Unicode codepoints as Naskh fonts do. Yet, from a graphematic-typological perspective, there is also an argument for considering the Fraktur, Gaelic or Nastaliq calligraphic hands as distinct graphetic inventories in their own right and, therefore, as independent scripts (§2.6).
In terms of practical impact, designing fonts for visually distinct Landa variants based on the Khudawadi Unicode block may make it tricky to, say, simultaneously display the Khudawadi and Shikarpuri variants of a certain graph using the same font. For instance, someone wishing to depict Khudawadi-based 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 |॥| [ɾ] and Shikarpuri-derived 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 |𑋙| [ɾə] with the same font would have to resort to typographical workarounds if both glyphs are encoded on the same Unicode codepoint. Whereas Unicode-compliant fonts can allow for the same underlying character to be rendered with different surface glyphs or ‘stylistic sets’ by tweaking certain parameters, harnessing this capability to reliably display, say, the Shikarpuri or Memon variants of a particular Landa graph in the same context might require some thought.
8.3.3 Graphematics and orthography
The distinct typological categories and graph inventories of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 imply that there is a noticeable difference in their graph-phone correspondences. Hence, the question posed in Section 6.6.1 is worth asking here, too: how should 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 be characterised within the context of the Modular Theory? Are they simply distinct sets of graph-phone mappings, or is there a superior terminological alternative? Also, given the deliberate design and top-down promulgation of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 — reminiscent of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 as well as 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜 — is there a case for it to be classified as an orthography? If yes, and as alluded to in Section 6.6.3, the definition of an orthography would have to account for its potential impact on the graph inventory.
With regard to the graph inventory, the fact that the visarga was nominally included in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 primers as part of the symbol chart reinforces the maxim that a collation order is based on tradition and convention, and not reflective of graphematic structure or sociolinguistic use. Neither does the collation order of a writing system necessarily comprise all graphs employed in that system, nor does it conclusively indicate the graphematic status of those graphs. At most, a collation order may be considered graphematically relevant in that it is often influenced by the orthographic module.
8.3.4 Sociolinguistics
The inclusion of visarga in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿’s collation order, despite likely never being used, demonstrates how sociolinguistic pressure can influence the elements included in a graph inventory. Moreover, the presence of visarga in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿’s inventory bears some resemblance to graphematic retention in 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 in being conditioned by a dominant writing system’s inventory and practices.
Finally, the fact that a graphematically comprehensive writing system such as 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 turned out to be a sociolinguistic dud and faded into oblivion is starkly reminiscent of the fate of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙. Both these cases affirm Meletis’ (2020, pp. 16–17) observation that a robust linguistic fit is no guarantee of a writing system’s sociolinguistic fit and, consequently, of its success.
9 Gurmukhi
In a sense, Gurmukhi is to the Punjab what Khudawadi is to Sindh — a Landa-origin script native to the region and traditionally used to transcribe local speech varieties (see Figure 5.1). At the same time, Gurmukhi differs from Khudawadi in that the former is still widely used in the twenty-first century, while the latter has become obsolete, at least in everyday use (Pandey, 2011a, p. 2). The graphetic roots of Gurmukhi in its present form lie in a Punjabi-origin Landa inventory used to transcribe the devotional hymns of the Sikh religion (Mann, 2001, p. 5). Since Sikhism originated in the Punjab, it was logical that Sikh liturgical compositions were written down in the local Landa inventory. The initial collection of Sikh hymns transcribed in Gurmukhi appeared in the early seventeenth century under the name Adi Granth ‘First Book’ (Shackle, 2007, p. 638). The final, enlarged collection of hymns is now called the Guru Granth Sahib, and is considered the sacred scripture of the Sikhs (Kohli, 1961, p. 12). Legend has it that the second Sikh spiritual master or guru, Guru Angad, improved the unstandardised Punjabi-Landa inventory in vogue at the time by furnishing it with additional graphs (Grierson, 1916, p. 624). As a result, the refined graph inventory came to be known as Gurmukhi ‘from the mouth of the Guru’ (Salomon, 2007, p. 92). In contrast, academic consensus is on the script being a descendant of Brahmi and on individual graphs in the inventory existing in a recognisable form prior to Guru Angad’s times (Bahri, 2011, p. 181; Kohli, 1961, pp. 13–14 footnote). Regardless of its origin, Gurmukhi has come to be revered by Sikhs, according it a status comparable to that of the Arabic script among Muslims and Devanagari among north Indian Hindus (Jain, 2007, pp. 59–60; Mann, 2001, p. 5). In post-Partition India, Gurmukhi has also been recognised in the Indian state of Punjab as the official script for the Punjabi language (Jain, 2007, p. 59; Shackle, 2007, p. 640), and is widely used in administration, education and mass media in that state.
The close association of the Gurmukhi script with the Punjabi language on the one hand, and with Sikh scriptures on the other, sometimes leads to people describing the Guru Granth Sahib as containing Punjabi-language hymns. In reality, the hymns of the Guru Granth Sahib are composed in a mixture of north-western Indo-Aryan speech varieties, often with discernible Persian influence (Grierson, 1916, pp. 618, 624; Kohli, 1961; Mann, 2001, p. 5). In graphematic terms, the writing system used in these hymns reflects not just Punjabi in Gurmukhi (𝚙𝚊-𝙶𝚞𝚛𝚞) but multiple languages written in the script, among them Sindhi (𝚜𝚍-𝙶𝚞𝚛𝚞; see Example (24)). Regardless, the pervasiveness of popular indexical associations often results in the terms ‘Gurmukhi’ and ‘Punjabi’ being interchangeably used to describe the language and the script, respectively. Despite the seemingly intertwined and inextricable links between language and script, they must be treated as distinct. Grierson (1916, p. 624) provides a pithy summary of the situation in noting that “[t]here is no more a ‘Gurmukhī’ language than there is a ‘Dēva-nāgarī’ one”. Besides, he reiterates that several languages have been written in Gurmukhi, which includes Sindhi.
9.1 Graphematic foundations
It is likely that early unstandardised Gurmukhi-based transcriptions of regional lects would have followed quasi-abjadic principles, much like 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍. Notwithstanding its legendary origin, Gurmukhi’s use in liturgical contexts and the desire to record and reproduce Sikh hymns in a phonologically accurate manner encouraged a gradual, organic process of graphetic and graphematic standardisation. Thus, compared to 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, Gurmukhi-based writing systems departed from their abjadic origins and moved towards the abugidic end of the typological spectrum at a much earlier stage of evolution.
The Sindhi-Gurmukhi (𝚜𝚍-𝙶𝚞𝚛𝚞) graph inventory is based on the Punjabi-Gurmukhi (𝚙𝚊-𝙶𝚞𝚛𝚞) inventory, the main elements of which are shown in Table 9.1.
Sources: Gill (1996, p. 395) and Shackle (2007, p. 651)
[table]
The graph inventory of 𝚙𝚊-𝙶𝚞𝚛𝚞 began to undergo standardisation by the nineteenth century, not least due to its increasing appearance in print. Figure 9.1 features 𝚙𝚊-𝙶𝚞𝚛𝚞’s free γ-vowels as seen in an early nineteenth-century publication.

Source: Carey (1812, p. 5)
Typographically, the free γ-vowels in Figure 9.1 bear a strong resemblance to their present-day counterparts in Table 9.1. In terms of graphetic composition, however, the free γ-vowel forms |ੲੈ| [æ] and | | [
| [ɔ] were variable in their rasmic base and also appeared as |ਐ ਔ|, respectively (Stack, 1849a, p. 4). While the latter forms have become standard in the modern Gurmukhi inventory, the graph || persists as part of the benedictory logogram |ੴ| ‘God is one’.
Reviews of handwritten (Stack, 1849a, pp. 3–8) and printed samples (Faulmann, 1880a, p. 123) of the Gurmukhi inventory over the course of the nineteenth century reveals a steady but palpable process of graphetic standardisation. Additionally, in the context of 𝚙𝚊-𝙶𝚞𝚛𝚞, several new γ-consonants were created by subfixing a nuqta to existing rasms. These included |ਖ਼ ਗ਼ ਜ਼ ਫ਼ ਸ਼| for Perso-Arabic-origin [x(ə) ɣ(ə) z(ə) f(ə) ɕ(ə)], and |ਲ਼| for indigenous [ɭ(ə)] (Gill, 1996, p. 396; Shackle, 2007, p. 651). As was the case in 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝚂𝚒𝚗𝚍, a graphematically plausible |ਕ਼| [q(ə)] did not become well-established in 𝚙𝚊-𝙶𝚞𝚛𝚞, likely due to the marginal nature of the corresponding phone [q] in Punjabi. Along similar lines, the absence of Sanskritic [ʂ] in Punjabi likely reduced the motivation to create a standalone 𝚙𝚊-𝙶𝚞𝚛𝚞 equivalent of 𝚜𝚍-𝙳𝚎𝚟𝚊 |ष|, with the graphetically related graph |ਖ| being allocated instead to [kʰ(ə)] (§7.3, p. 199; §8.1, p. 221).
Present-day 𝚙𝚊-𝙶𝚞𝚛𝚞 has the characteristics of an abugida, in that so-called consonant graphs in the inventory actually denote φ-[CV₀]. In modern Punjabi, the so-called inherent φ-vowel [V₀] has the value [ə]. The inventory also contains a bound virama |੍| [Ø] to suppress φ-[V₀], in line with other Indic abugidas. In practice, though, the virama is rarely used in modern 𝚙𝚊-𝙶𝚞𝚛𝚞, and writers and readers typically rely on graphematic environment to encode and decode the presence of φ-[V₀] (Masica, 1991, p. 149; Shackle, 2007, p. 652). Like 𝚜𝚍-𝚂𝚒𝚗𝚍, 𝚙𝚊-𝙶𝚞𝚛𝚞 is poor in bound allographs or ‘half forms’ of γ-consonants (Shackle, 2007, p. 652). At most, the graph inventory provides for |੍ਯ ੍ਰ ੍ਵ ੍ਹ| as bound allographs of |ਯ ਰ ਵ ਹ| [j(ə) ɾ(ə) ʋ(ə) ɦ(ə)]. The bound forms are used when the corresponding phones occur as the second member of a consonant cluster. These bound allographs may also be used for other purposes, such as marking phonological tone in Punjabi. In the past, |੍ਰ| was occasionally used to form the compound graph |ਲ੍ਰ| for [ɭ(ə)] (Grierson, 1916, p. 627), although this has now given way to |ਲ਼|.
Modern 𝚙𝚊-𝙶𝚞𝚛𝚞’s abugidic characteristics also derive from its free and bound γ-vowels occurring in complementary distribution. Notably, free γ-vowels in 𝚙𝚊-𝙶𝚞𝚛𝚞 are formed using just three rasms as graphetic bases (see Table 9.1; see also (23)). The distribution of graphetic rasms forms a pattern with the qualities of the φ-vowels represented. Thus, |ਅ| is used as the base for the low φ-vowels [ə a æ ɔ], |ੲ| for the high and mid-high front φ-vowels [ɪ i e], and |ੳ| for the high and mid-high back φ-vowels [ʊ u o] (Gill, 1996, p. 396; Salomon, 2007, p. 93). The rasm |ਅ| also serves as the fully-specified free γ-vowel for [ə], while graphetically truncated |ੳ| in the form of |ਓ| stands for [o]. The other eight free γ-vowels are formed by combining the bound allographs |ਾ ਿ ੀ ੁ ੂ ੇ ੈ ੋ ੌ| with one of the three rasmic bases, resulting in |ਆ ਇ ਈ ਉ ਊ ਏ ਐ ਔ| [a ɪ i ʊ u e æ ɔ].
In terms of graphetic compositionality, the 𝚙𝚊-𝙶𝚞𝚛𝚞 rasms |ਅ ੲ ੳ| most closely resemble 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 |𑊰 𑊲 𑊴|. Echoing conjecture in the context of 𝚜𝚍-𝚂𝚒𝚗𝚍 (§8.1), scholars have postulated that the presence in Gurmukhi of three rasms as graphetic bases for free γ-vowels reflects Semitic influence (Masica, 1991, pp. 150–151; Salomon, 2007, p. 93; Shackle, 2007, p. 651). On this basis, authors have described the rasms |ਅ ੲ ੳ| as “vowel carriers” or “vowel bearers” (Gill, 1996, pp. 395–396; Masica, 1991, pp. 150–151), which are terms used more commonly in the context of Semitic writing systems (§6.1).
Like 𝚑𝚒-𝙳𝚎𝚟𝚊 |ं| and |ँ|, 𝚙𝚊-𝙶𝚞𝚛𝚞 contains two bound graphs to denote nasality, known as tippi |ੰ| and bindi |ਂ|. Both graphs may denote either φ-vowel nasalisation or the nasal component of a nasal-oral φ-consonant cluster. However, the distribution of |ੰ| and |ਂ| is distinct from 𝚑𝚒-𝙳𝚎𝚟𝚊 |ं| and |ँ|. Unlike the latter, the occurrence of 𝚙𝚊-𝙶𝚞𝚛𝚞 |ੰ| and |ਂ| is determined purely by the graphematic environment (Grierson, 1916, p. 627; Shackle, 2007, p. 653), resulting in complementary distribution as shown in (22):
(22)
| tippi | ਅੰ | ਇੰ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ੰ | ਿੰ | ੁੰ | ੂੰ | |||||||
| bindi | ਆਂ | ਈਂ | ਉਂ | ਊਂ | ਏਂ | ਐਂ | ਓਂ | ਔਂ | ||
| ਾਂ | ੀਂ | ੇਂ | ੈਂ | ੋਂ | ੌਂ |
A noteworthy bound graph in 𝚙𝚊-𝙶𝚞𝚛𝚞 is |ੱ|, known as addak.118 The addak indicates gemination of the φ-consonant represented by the graph immediately following, as in |ਪੱਥਰ| [pət̪t̪ʰəɾ] ‘stone’ (Grierson, 1916, p. 627). Evidently, the graphotactic distribution of the addak precludes indicating word-initial φ-consonant gemination. However, this does not pose a problem for 𝚙𝚊-𝙶𝚞𝚛𝚞, since Punjabi phonology prohibits word-initial φ-consonant gemination. Scholars have attributed the introduction of the addak in the nineteenth century to Christian missionaries (Shackle, 2007, p. 654). Authors have also highlighted its graphetic similarity with the functionally near-identical 𝚊𝚛-𝙰𝚛𝚊𝚋 tashdid (Masica, 1991, p. 149; Salomon, 2007, p. 93). Despite its availability, the use of addak in 𝚙𝚊-𝙶𝚞𝚛𝚞 remains inconsistent (Shackle & Skjærvø, 2006, p. 548). Even rarer is the use of 𝚙𝚊-𝙶𝚞𝚛𝚞 visarga |ਃ|. It is occasionally used when one intends to authentically transcribe Sanskrit words into Gurmukhi (𝚜𝚊-𝙶𝚞𝚛𝚞). In older liturgical texts, the visarga may be used as an abbreviation marker.
The numeral graphs in 𝚙𝚊-𝙶𝚞𝚛𝚞 are |੦ ੧ ੨ ੩ ੪ ੫ ੬ ੭ ੮ ੯| ‘0 1 2 3 4 5 6 7 8 9’. Emic graphs for punctuation include |। ॥|, which are graphetically and graphematically identical to their 𝚜𝚊-𝙳𝚎𝚟𝚊 counterparts (§7.1). Modern 𝚙𝚊-𝙶𝚞𝚛𝚞 writing makes extensive use of 𝚎𝚗-𝙻𝚊𝚝𝚗 numeral and punctuation graphs.
The traditional 𝚙𝚊-𝙶𝚞𝚛𝚞 symbol chart is shown in (23) (Gill, 1996, p. 396; Shackle, 2007, p. 652). It comprises thirty-five graphetic rasms, due to which 𝚙𝚊-𝙶𝚞𝚛𝚞 was also historically referred to as paintih ‘the thirty-five’ (Punjabi: [pæ̃t̪í]) (Gill, 1996, p. 395; Shackle, 2007, p. 651). The chart departs from the traditional Sanskritic collation order in commencing not with fully-specified free γ-vowels but with the underspecified γ-vowel rasms |ੳ ਅ ੲ|. Occasionally, these three rasms may appear in the Sanskrit-influenced sequence |ਅ ੲ ੳ| (Grierson, 1916, p. 625). The three γ-vowel rasms are succeeded by |ਸ ਹ| [s(ə) ɦ(ə)], followed by other γ-consonants in the conventional Sanskritic order. The list concludes with |ੜ| [ɽ(ə)].
(23)
| ੳ | ਅ | ੲ | ਸ | ਹ |
| ਕ | ਖ | ਗ | ਘ | ਙ |
| ਚ | ਛ | ਜ | ਝ | ਞ |
| ਟ | ਠ | ਡ | ਢ | ਣ |
| ਤ | ਥ | ਦ | ਧ | ਨ |
| ਪ | ਫ | ਬ | ਭ | ਮ |
| ਯ | ਰ | ਲ | ਵ | ੜ |
In denoting the retroflex flap [ɽ(ə)] with the distinct rasm |ੜ|, 𝚙𝚊-𝙶𝚞𝚛𝚞 contrasts with 𝚑𝚒-𝙳𝚎𝚟𝚊’s graphetically augmented |ड़| while harmonising with 𝚜𝚍-𝚂𝚒𝚗𝚍’s |𑋊|. The presence of a distinct rasm for [ɽ(ə)] in 𝚙𝚊-𝙶𝚞𝚛𝚞 and 𝚜𝚍-𝚂𝚒𝚗𝚍 also serves as a subtle graphematic reminder of the Landa origins of their constituent inventories.
9.2 Early use
The rise of Gurmukhi as a distinct inventory more or less coincides with its use in Sikh liturgical writing. Hence, the hymns in the seventeenth-century Adi Granth may be considered the earliest specimens of Gurmukhi-based writing. The graph inventory used in the Adi Granth was devoid of underdotted γ-consonants and the addak, since they were introduced only in the nineteenth century. Also absent or rarely marked was nasalisation on γ-vowels (Shackle, 2007, p. 653), which was consistent with practice in pre-standardised Landa (§5.1.1). On the other hand, certain graphematic practices used in the Adi Granth have persisted and been codified into modern 𝚙𝚊-𝙶𝚞𝚛𝚞 orthography. Prominent among them is the representation of word-medial [j] with the bound γ-vowel |ਿ| [ɪ] (Shackle, 2007, p. 653).
At the same time, the Adi Granth comprised hymns composed in various north-western Indo-Aryan speech varieties, including Sindhi. Thus, the collection also contains some of the earliest instances of Sindhi in Gurmukhi (𝚜𝚍-𝙶𝚞𝚛𝚞). Kohli (1961, p. 62) has identified verses in the Adi Granth whose language lies on a continuum between the Siraiki of southern Punjab and Siroli of northern Sindh (§4.2). He notes that these verses are collectively called dakhne [ɖəkʰ(ə)ɳe] (cf. Sindhi [ɗəkʰəɳᶷ] ‘south’), which alludes to their ‘southern’ idiom. An example of such a verse in the Adi Granth (later Guru Granth Sahib) is shown in (24), with recognisably Sindhi elements bolded and accompanied by an IPA transcription and English gloss.
(24)
| 𝚜𝚍-𝙶𝚞𝚛𝚞 text | Indicative pronunciation | English gloss (Harbans Lal, 2021) |
|---|---|---|
| ਤੂ ਚਉ ਸਜਣ ਮੈਡਿਆ | t̪u₁ t͡ɕɔ₂ səd͡ʑ(ː)əɳᵊ mɛɖᶦja |
If Thou₁ say₂ so, I would cut off my head |
| ਡੇਈ ਸਿਸੁ ਉਤਾਰਿ ॥ | ɖei₃ sɪsᶷ ut̪aɾᶦ |
and give₃ it to Thee, O my Friend. |
| ਨੈਣ ਮਹਿੰਜੇ ਤਰਸਦੇ | nɛɳᵊ₄ məɦᶦ̃d͡ʑe₅ t̪əɾᵊsᵊd̪e |
Mine₅ eyes₄ long for Thee, |
| ਕਦਿ ਪਸੀ ਦੀਦਾਰੁ ॥੧॥ | kəd̪ᶦ pəsi d̪id̪aɾᶷ |
When shall I see Thine vision, O Lord? |
| ਨੀਹੁ ਮਹਿੰਜਾ ਤਊ ਨਾਲਿ | niɦᶷ₆ məɦᶦ̃d͡ʑa₇ t̪ɔ₈ nalᶦ |
My₇ love₆ is with Thee₈, |
| ਬਿਆ ਨੇਹ ਕੂੜਾਵੇ ਡੇਖੁ ॥ | bᶦja₉ neɦᵊ kuɽaʋe ɖekʰᶷ |
I have seen all other₉ loves to be false. |
| ਕਪੜ ਭੋਗ ਡਰਾਵਣੇ | kəpəɽᵊ bʱoɡᵊ ɖəɾaʋᵊɳe |
As long as I behold not my Beloved₁₀, |
| ਜਿਚਰੁ ਪਿਰੀ ਨ ਡੇਖੁ ॥੨॥ | d͡ʑɪt͡ɕəɾᶷ pᶦɾi₁₀ nə ɖekʰᶷ |
clothes and food seem dreadful to me. |
| ਉਠੀ ਝਾਲੂ ਕੰਤੜੇ | ʊʈʰi d͡ʑʱalu kən̪t̪əɽe |
O my spouse, I arise early |
| ਹਉ ਪਸੀ ਤਉ ਦੀਦਾਰੁ ॥ | ɦɔ pəsi t̪ɔ d̪id̪aɾᶷ |
to behold Thy vision. |
| ਕਾਜਲੁ ਹਾਰ ਤਮੋਲ ਰਸੁ | kad͡ʑəlᶷ ɦaɾᵊ t̪əmolᵊ ɾəsᶷ |
Collyrium, garlands, betel and dainties; |
| ਬਿਨੁ ਪਸੇ , ਹਭਿ ਰਸ ਛਾਰੁ ॥੩॥ | bɪnᶷ pəse ɦəbʱᶦ ɾəsᵊ t͡ɕʱaɾᶷ |
All such relishes are but dust without seeing Thee, O Lord. |
To a speaker of modern Sindhi, several items of the lexicon used in (24) may come across as archaic, or at least highly poetic and literary in nature. Of the lexical items still in use, some may appear in so-called non-standard or ‘dialectal’ forms. For instance, item #7, |ਮਹਿੰਜਾ| [məɦᶦ̃d͡ʑa] ‘my (sing.)’ is related to present-day Siroli [mə̃ɦᶦ̃d͡ʑo] ‘ibid.’ but distinct from Vicholi or standard Sindhi [mʊ̃ɦᶦ̃d͡ʑo] ‘ibid.’. Linguistically and geographically, the appearance of these lexical items is consistent with the Siraiki-Siroli idiom of the verses. Also consistent are the graphematic features in the verses with what is expected of the time. Thus, items #1 |ਤੂ| and #10 |ਪਿਰੀ|, if transparently interpreted, suggest the pronunciations [t̪u] and [pᶦɾi]. In contrast, the equivalent present-day Sindhi pronunciations of these words are [t̪ũ] and [pᶦɾĩ], respectively. The discrepancy is neatly explained if one considers that φ-vowel nasalisation was unpredictably marked in writing at the time.
9.3 British-era and post-Partition practices
Prior to the British conquest of Sindh, works in 𝚜𝚍-𝙶𝚞𝚛𝚞 were limited in number, which was consistent with the fact that written Sindhi was not widespread at the time. Probably the best-known 𝚜𝚍-𝙶𝚞𝚛𝚞 composition of this time is the poetry of celebrated Sindhi poet Chainrai Dataramani, popularly known by his pen-name ‘Sami’ (1743?–1850) (Jotwani, Shackle, & Das, 2015). Hardwani (2015, p. 2) speculates that Sami’s choice of Gurmukhi was natural, since he wrote most of his poetry in the Punjabi cultural centre of Amritsar. That said, Sami’s handwritten manuscripts were compiled and published only by the late 1800s (Jetley, 1989). It remains to be researched whether the graphematic features seen in published versions of Sami’s 𝚜𝚍-𝙶𝚞𝚛𝚞 writing are unchanged from the original, or have undergone subtle modifications along the way. For instance, a selection of his verses published in 1938 (Hauze, 2016f) features the composite graph |ੲੈਂ| [ɛ̃ ~ əĩ] ‘and’ instead of the 𝚙𝚊-𝙶𝚞𝚛𝚞-inspired |ਐਂ| (§9.1). Although |ੲੈਂ| is licensed by the graphematic solution spaces of both 𝚜𝚍-𝙶𝚞𝚛𝚞 and 𝚙𝚊-𝙶𝚞𝚛𝚞, the latter’s orthography implicitly licenses the composite graph |ਐਂ| (see Table 9.1). Hence, knowing whether the choice of |ੲੈਂ| in Sami’s published works was his own, or is a subsequent modification, would be valuable from a graphematic perspective.
Publication in 𝚜𝚍-𝙶𝚞𝚛𝚞 gained momentum after the British takeover of Sindh, with administrators, scholars and Christian missionaries professing interest in the writing system. In his Sindhi grammar, Stack (1849a, pp. 3–8) included handwritten samples of Gurmukhi graphs in his comparative chart. Despite eventually opting for Devanagari in his work, Stack (1849a, p. vi) describes Gurmukhi as “assimilating with the Sindhi somewhat more than Devenagari [sic] did, and […] being also more known to Hindoos in Sindh”. Stack’s contemporary and Christian missionary Andrew Burn translated the Gospel of John into 𝚜𝚍-𝙶𝚞𝚛𝚞, which was lithographed and published in Karachi in 1859 (Blumhardt, 1893, pp. 4–5; Nida, 1972, p. 393). An extract from Burn’s translation (John 3:16) is shown in Figure 9.2.

“For God so loved the world, that he gave his only begotten Son, that whosoever believeth in him should not perish, but have everlasting life.”
Source: American Bible Society (1893, p. 26)
New and revised translations of Biblical scriptures in 𝚜𝚍-𝙶𝚞𝚛𝚞 appeared in 1877, 1899, 1908 and 1917 (Nida, 1972, pp. 393–394). The 1877 edition of the Gospel of John, published by Oxford University Press, was a typographical landmark in the history of 𝚜𝚍-𝙶𝚞𝚛𝚞 publishing, as it was the first 𝚜𝚍-𝙶𝚞𝚛𝚞 publication to be printed using movable type (Afshar, 2020, p. 161). Other 𝚜𝚍-𝙶𝚞𝚛𝚞 publications in the late nineteenth century ranged from government-issued textbooks for girls’ schools to magazines aimed at women readers (§5.2.4). Publication in 𝚜𝚍-𝙶𝚞𝚛𝚞 began to wane in the twentieth century as 𝚜𝚍-𝙰𝚛𝚊𝚋 came to be increasingly accepted and used in Sindh. Indeed, among the numerous heterographic Sindhi-language text samples provided in the Linguistic Survey of India, 𝚜𝚍-𝙶𝚞𝚛𝚞 text samples are conspicuous by their absence.
An overview of accessible 𝚜𝚍-𝙶𝚞𝚛𝚞 works from the pre-Partition era reveals large degrees of inventorial overlap with 𝚙𝚊-𝙶𝚞𝚛𝚞. Stack’s comparative chart of scripts (1849a, pp. 3–8) does not contain distinct 𝚜𝚍-𝙶𝚞𝚛𝚞 graphs for the Sindhi implosives [ɠ ʄ ɗ ɓ]. Authors of Christian literature in 𝚜𝚍-𝙶𝚞𝚛𝚞 were likely the first to attempt creating distinct graphs for the φ-implosives. Thus, the text in Figure 9.2, dating from 1858, features the spellings |ਜਗ਼ਤ| [d͡ʑəɠət̪ᵊ] ‘world’ and |ਜ਼ਣ੍ਯਲੁ| [ʄəɳ(ᶦ)jəlᶷ] ‘born’. Here, the rasms for [ɡ(ə) d͡ʑ(ə)] have been graphetically subfixed with a nuqta to create |ਗ਼ ਜ਼| [ɠ(ə) ʄ(ə)]. By the late nineteenth century, however, the underdotted |ਖ਼ ਗ਼ ਜ਼ ਫ਼| began to be increasingly used to denote [x(ə) ɣ(ə) z(ə) f(ə)]. Consequently, new graphs needed to be created for [ɠ(ə) ʄ(ə)], if not for the entire φ-implosive set. A Christian publication from the early twentieth century featuring the Lord’s Prayer in 𝚜𝚍-𝙶𝚞𝚛𝚞 (Gilbert & Rivington, 1905, p. 136) denotes [ʄ(ə)] with two nuqtas subfixed on |ਜ|. The prayer does not contain any instance of [ɠ(ə)], although one may hypothesise that a similar graphetic pattern might have been used. On occasion, [ɓ(ə)] was transcribed as |ਭ਼| (Nida, 1972, p. 393), by underdotting the rasm |ਭ| [bʱ(ə)] rather than |ਬ| [b(ə)]. Overall in pre-Partition 𝚜𝚍-𝙶𝚞𝚛𝚞 texts, the relatively consistent adoption of |ਖ਼ ਗ਼ ਜ਼ ਫ਼| for [x(ə) ɣ(ə) z(ə) f(ə)] contrasted with the vacillation on graphs for the φ-implosives, despite the latter being native to the Sindhi language. In this regard, the 𝚜𝚍-𝙶𝚞𝚛𝚞 graph inventory contrasted with 𝚜𝚍-𝚂𝚒𝚗𝚍 in not having clear-cut graphs for the φ-implosives, in the process signalling Gurmukhi’s origins outside of Sindh.
The then-repertoire of 𝚜𝚍-𝙶𝚞𝚛𝚞 γ-vowels, too, was largely isographic with that of 𝚙𝚊-𝙶𝚞𝚛𝚞. Areas of inventorial and graphematic divergence included the greater prevalence in 𝚜𝚍-𝙶𝚞𝚛𝚞 of |ੲੈਂ| [ɛ̃ ~ əĩ] ‘and’, be it in Sami’s verses or in Christian publications. Graphematically, 𝚜𝚍-𝙶𝚞𝚛𝚞 was distinguished by its use of bound γ-vowels. Conditioned by the notion that most — if not all — Sindhi φ-syllables are vowel-final, as well as by the unpopularity of the virama in 𝚙𝚊-𝙶𝚞𝚛𝚞 writing, 𝚜𝚍-𝙶𝚞𝚛𝚞 writers often used |ਿ| to indicate [ᶦ ~ Ø]. This practice is homologous with the 𝚜𝚍-𝙰𝚛𝚊𝚋 practice of using zer |◌ِ| as a near-allograph of jazm |◌ٛ| to mark [ᶦ ~ Ø], itself dating from pre-British times (Stack, 1849a, p. 128). As with all the writing system variants seen thus far, 𝚜𝚍-𝙶𝚞𝚛𝚞, too, did not graphematically distinguish [ə ɪ ʊ] from their reduced allophones [ᵊ ᶦ ᶷ], and used the same set of γ-vowels for both. Nasalisation of φ-vowels generally followed the 𝚙𝚊-𝙶𝚞𝚛𝚞 distribution (see (22)), although idiosyncratic deviations were common. Evidence for an attested or recommended collation order in 𝚜𝚍-𝙶𝚞𝚛𝚞 proves elusive. It remains to be seen whether the preferred template is the 𝚙𝚊-𝙶𝚞𝚛𝚞 sort order (see (23)) or a 𝚜𝚍-𝙳𝚎𝚟𝚊-inspired one (§7.5.4, §7.6.3).
Publication in 𝚜𝚍-𝙶𝚞𝚛𝚞 largely ceased by the mid-twentieth century, with only the odd publication appearing in post-Partition India. Unsurprisingly, they remain rare and hard to come by. One such publication is an undated 𝚜𝚍-𝙶𝚞𝚛𝚞 booklet on Hindu spiritual themes, published in Ulhasnagar, Maharashtra (Kalyani, n.d.). The booklet largely follows the pre-Partition graphematic practices described above. An extract of a passage from the booklet is shown in (25), followed by an IPA transcription of the 𝚜𝚍-𝙶𝚞𝚛𝚞 spelling pronunciations. Where spelling pronunciations are divergent from standard Sindhi pronunciations, an IPA transcription of the latter is also provided.
(25)
| ਪਾਰਿਪਤੀ | ਦੇਵੀਅ | ਖੇਸਿ | ਜਵਾਭੁ | ਡਿਨੋ | ਤ | ‘ਪੁਟ! |
| paɾᶦpət̪i | d̪eʋi | kʰesᶦ | d͡ʑəʋabʱᶷ ~ d͡ʑəʋabᶷ | ɖɪno | t̪ə | pʊʈ(ɾ)ᵊ |
| ਛੋ | ਤ | ਤੂਂ | ਤਮਾਮੁ | ਘਣੇ | ਵਕਤ | ਖਾਂ |
| t͡ɕʰo | t̪ə | t̪ũ | t̪əmamᶷ | ɡʱəɳe | ʋəkət̪ᵊ ~ ʋəkt̪ᵊ | kʰã |
| ਪੋਇ | ਅਚੀ | ਅਸਾਂ | ਸਾਂ | ਮਿਲਿਯੌ | ਆਹੀਂ | ਜੰਹਿੰਕਰੇ |
| poᶦ | ət͡ɕi | əsã | sã | mɪlᶦjɔ ~ mɪlᶦjo | aɦĩ | d͡ʑɛ̃ɦᵋ̃kəɾe |
| ਮੁੰਹਿੰਜੇ | ਖੁਸ਼ੀਅ | ਜੀ | ਹਦ | ਈ | ਨ | ਆਹੇ |
| mʊ̃ɦᶦ̃d͡ʑe | kʰʊɕiə ~ xʊɕiə | d͡ʑi | ɦəd̪ᵊ | i | nə | aɦe |
| ੲੈਂ | ਮਾਂ | ਤੁਹਿੰਜੇ | ਪਿਤਾ | ਸ਼ੰਕਰ | ਭਗਵਾਨ | ਜੇ |
| ɛ̃ ~ əĩ | mã | tʊɦᶦ̃d͡ʑe ~ tʊ̃ɦᶦ̃d͡ʑe | pɪt̪a | ɕəŋkəɾᵊ | bʱəɡəʋanᵊ ~ bʱəɠəʋanᵊ | d͡ʑe |
| ‘ਵ੍ਰਿਤ’ | ਜੀ | ਤਾਕਤ | ਅਖਿਯੁਨਿ | ਮਾਂ | ਡਿਸੀ | ਰਹੀ |
| ʋɾɪt̪ᵊ ~ ʋɪɾt̪ᵊ | d͡ʑi | t̪akət̪ᵊ | əkʰᶦjʊnᶦ | mã | ɖɪsi | ɾəɦi |
| ਆਹਿਆਂ | ਜੰਹਿੰ | ਕਰੇ | ਖਿਲ | ੲੈਂ | ਖੁਸ਼ੀਅ | ਵਿਚਾਂ |
| aɦᶦjã | d͡ʑɛ̃ɦᵋ̃ | kəɾe | kʰɪlᵊ | ɛ̃ ~ əĩ | kʰʊɕiə ~ xʊɕiə | ʋɪt͡ɕã |
| ਰੁਕਿਜੀ | ਈ | ਨਥੀ | ਸਘਾਂ।’ | |||
| ɾʊkᶦd͡ʑi | i | nət̪ʰi | səɡʱã | |||
Goddess Parvati replied to him, “O son! Since you’ve come to see us after such a long time, my happiness knows no bounds; and seeing the power of your father Lord Shiva’s penance with my own eyes, I’m unable to contain myself with joy and laughter”.
Aside from adhering to the pre-Partition 𝚜𝚍-𝙶𝚞𝚛𝚞 practices described earlier, the extract in (25) also largely follows 𝚙𝚊-𝙶𝚞𝚛𝚞 practices. In line with (22), tippi |ੰ| and bindi |ਂ| are in complementary distribution conditioned entirely by graphematic environment. In other words, both |ੰ| and |ਂ| may denote the nasal component of a homorganic nasal-oral φ-consonant cluster, or the nasalisation of a φ-vowel. Thus, in (25), tippi denotes homorganic [ŋ] in |ਸ਼ੰਕਰ| [ɕəŋkəɾᵊ] ‘Shiva’, but φ-vowel nasalisation [◌̃] in |ਮੁੰਹਿੰਜੇ| [mʊ̃ɦᶦ̃d͡ʑe] ‘my (oblique)’. Elsewhere in the booklet, the graphematic conditioning at play is further illustrated by the examples |ਕੰਦੇ| [kən̪d̪e] ‘while doing’ but |ਵੇਂਦਾ| [ʋen̪d̪a] ‘(they) will go’, in which both |ੰ| and |ਂ| denote homorganic [n̪] (Kalyani, n.d., p. 2). That said, the booklet also reveals deviations from the 𝚙𝚊-𝙶𝚞𝚛𝚞 distribution of these graphs. Most of them appear to be oversights that lie within the realm of graphematic plausibility. Thus, in |ਮੁਂਹਿੰਜੋ| (p. 2) and |ਤੁਂਹਿੰਜੋ| (p. 6), an expected |ੰ| is substituted by |ਂ|, while, in |ਤੁਹਿੰਜੇ| (p. 18), neither is present. However, there is also the odd deviation from the norm occurring consistently throughout the booklet, thereby appearing intentional. The most prominent of these is the spelling of the Sindhi pronoun [t̪ũ] ‘thou’, which is consistently written |ਤੂਂ| rather than the expected |ਤੂੰ| predicted by (22). Also occurring consistently is |ੲੈਂ| [ɛ̃ ~ əĩ] ‘and’, which, although distinct in its rasmic base from 𝚙𝚊-𝙶𝚞𝚛𝚞-style |ਐਂ|, follows the norm in featuring a bindi.
The booklet does not use distinct graphs for the φ-implosives, representing them homographically with their φ-plosive counterparts using |ਗ ਜ ਡ ਬ|. Also underdifferentiated are the Perso-Arabic-origin [x ɣ z f] from [kʰ ɡ d͡ʑ pʰ], with rasms |ਖ ਗ ਜ ਫ| used for both sets. On occasion, the booklet also uses |ਭ| [bʱ(ə)] where one would expect |ਬ| [b(ə)], albeit unpredictably. Thus, 𝚜𝚍-𝙶𝚞𝚛𝚞 |ਜਵਾਬੁ| [d͡ʑəʋabᶷ] ‘reply’ appears in (25) as |ਜਵਾਭੁ|, suggesting the nonstandard pronunciation [d͡ʑəʋabʱᶷ].
The booklet extensively uses the handful of bound γ-consonants available in the Gurmukhi inventory: |੍ਯ ੍ਰ ੍ਵ ੍ਹ|. Accordingly, Sindhi [əʋʱĩ] ‘you (pl.)’ is transcribed as |ਅਵ੍ਹੀਂ| (p. 6). Where possible, the graphematic makeup of Sanskrit loanwords is retained. Thus, Sanskrit [kɾod̪ʱᵊ] ‘anger’ is transcribed |ਕ੍ਰੋਧ| (p. 6), whose spelling suggests the pronunciation [kɾod̪ʱ] rather than the assimilated Sindhi pronunciation [k(ᶦ)ɾod̪ʱᶷ]. The booklet does not appear to use the virama at all, preferring instead to use |ਿ| to indicate [ᶦ ~ Ø]. Curiously, the latter practice also extends to English words transcribed into 𝚜𝚍-𝙶𝚞𝚛𝚞. For instance, the name of the publisher, “L. Kishinchand and Sons, Booksellers”, is transcribed on the cover as |ਏਲਿ. ਕਿਸ਼ਿਨਿਚੰਦੁ ੲੈਂ ਸੰਸਿ ਭੁਕੁਸੇਲਰਿਸਿ|, suggesting the spelling pronunciation [elᶦ kɪɕɪnᶦt͡ɕən̪d̪ᶷ ɛ̃ sənsᶦ b(ʱ)ʊkᶷseləɾᶦsᶦ]. With regard to logograms, the booklet uses the standard 𝚙𝚊-𝙶𝚞𝚛𝚞 set of numeral graphs, and, aside from |।| as full stop, uses 𝚎𝚗-𝙻𝚊𝚝𝚗 punctuation throughout.
9.4 Analysis
Compared to Sindhi’s Arabic, Devanagari and Khudawadi-based writing systems, 𝚜𝚍-𝙶𝚞𝚛𝚞 emerges as comparatively less normativised. Yet, the large degree of overlap between Sindhi and Punjabi phonology (§4.3) and a reasonably high level of pre-existing regularity in 𝚙𝚊-𝙶𝚞𝚛𝚞’s appears to have mitigated the need for large-scale customisations to 𝚜𝚍-𝙶𝚞𝚛𝚞. Consequently, some of the observations made in this section are based on, and also apply to, 𝚙𝚊-𝙶𝚞𝚛𝚞.
The lack of significant graphematic modifications specific to 𝚜𝚍-𝙶𝚞𝚛𝚞 render it typologically identical to 𝚙𝚊-𝙶𝚞𝚛𝚞 in being an abugidic alphasyllabary. This puts 𝚜𝚍-𝙶𝚞𝚛𝚞 in the same graphematic category as 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, while also aligning it with 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 in terms of their alphasyllabic nature. Graphematic commonalities among these systems are also evident in the principles governing the composition of their free γ-vowels. The three rasms |ਅ ੲ ੳ| used in 𝚙𝚊-𝙶𝚞𝚛𝚞 and 𝚜𝚍-𝙶𝚞𝚛𝚞 as graphetic bases to create free γ-vowels is analogous to 𝚜𝚍-𝚂𝚒𝚗𝚍’s use of |𑊰 𑊲 𑊴| and 𝚜𝚍-𝙰𝚛𝚊𝚋’s |ء ﺋ ا|. This principle is also followed in spirit by 𝚜𝚍-𝙳𝚎𝚟𝚊 in its use of |अ इ उ ए| as graphetic bases for free γ-vowels.
Against this background, can the use of three graphetic bases to create free vowel graphs be legitimately attributed to Semitic influence, as has also been speculated in the context of 𝚜𝚍-𝚂𝚒𝚗𝚍 (§8.1)? Or is the occurrence of three graphetic bases somewhat unremarkable, since 𝚜𝚍-𝙳𝚎𝚟𝚊 — and several Devanagari-based systems for Indo-Aryan languages — use only four graphetic bases to form distinct free graphs for their ten-or-so vowel phonemes (Table 4.3)? A comprehensive conclusion on this question will require targeted scrutiny, but the initial evidence emerging from the cross-systemic investigation of Sindhi’s writing systems points raises doubts on the extent of Semitic influence.
One area where 𝚜𝚍-𝙶𝚞𝚛𝚞 falls short in terms of graphematic precision is in possessing distinct graphs for Sindhi’s φ-implosives. This gap in 𝚜𝚍-𝙶𝚞𝚛𝚞’s graph inventory reflects the phonological fact that contrastive φ-implosives are absent among most north-western Indo-Aryan languages (§4.3.1). While certain authors, especially translators of Christian scriptures, attempted to create unique graphs for Sindhi’s φ-implosives by means of nuqtas, none of these innovations caught on. In theory, the noncontrastive nature of phonological gemination in Sindhi frees up the addak |ੱ| to potentially be used to denote φ-implosives. As will be seen in Chapter 12, a similar rationale has been used in the context of 𝚜𝚍-𝙻𝚊𝚝𝚗 to distinctly represent Sindhi’s φ-implosives (§12.2). However, as mentioned in Section 9.1, the graphotactic requirement for an addak to occur before the impacted graph poses a problem when the impacted graph is word-initial. Consequently, using an addak would not permit representing word-initial φ-implosives in Sindhi. Illustrating this limitation is the Sindhi word [ɖɪsi] ‘having seen’, which, in Example (25) is transcribed |ਡਿਸੀ| using plosive |ਡ| [ɖ(ə)].
In theory, the graphotactic requirements around 𝚜𝚍-𝙶𝚞𝚛𝚞’s addak may be modified to make it occur above the impacted graph, thereby aligning it with its homologues — 𝚜𝚍-𝙰𝚛𝚊𝚋’s tashdid and 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓’s tashdid (Chapter 10). However, the lack of a 𝚜𝚍-𝙶𝚞𝚛𝚞 graphosphere with a critical mass of reader-writers, not to mention a 𝚜𝚍-𝙶𝚞𝚛𝚞 language body with authority, meant that the ingredients for graphematic refinement and orthographic consolidation were simply absent.
10 Khojki
In the tapestry of Sindhi’s writing systems, the script now known as Khojki occupies a unique position. As Figure 5.1 shows, Khojki traces its origin to the unstandardised Landa inventories used in Sindh. Indeed, of the fourteen or so unstandardised Landa inventories prevalent in Sindh, Khojki and Khudawadi were the only ones that went on to be augmented, standardised and recognised as full-fledged scripts. In graphematic terms, Khojki’s ontogenesis and visual characteristics make it a sister script to Khudawadi.
In sociolinguistic terms, though, Khojki has more in common with Gurmukhi — its Landa ‘cousin’ from Punjab. While Khudawadi — as part of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 — underwent standardisation thanks to government intervention, the driving force behind standardising Gurmukhi and Khojki was their status as liturgical scripts. The status enjoyed by Gurmukhi within the Sikh community is mirrored by that of Khojki among the Nizari Ismailis of South Asia (Asani, 1987). The Nizari Ismailis are Shia Muslims who trace their roots primarily to the present-day regions of Sindh, Kutch, Gujarat and southern Punjab (Shackle & Moir, 1992). Indeed, the position of Khojki vis-à-vis the Nizari Ismaili community and the Sindhi language bears stark similarities with that of Gurmukhi’s status within the Sikh community and the Punjabi language.
The graph inventory today labelled Khojki was used in medieval times to transcribe Ismaili devotional hymns, known as ginans (§5.1.4).119 Like much medieval folklore of the region, the ginans originated as oral poetic compositions and were transmitted as such (Nanji, 1972, p. 24). The language of the ginans is a mélange of early New Indo-Aryan varieties of Sindhi, Kutchi, Punjabi, Gujarati and Hindi-Urdu with considerable influence from Sanskrit, Persian and Arabic (Asani, 1991, p. xi; Shackle & Moir, 1992). The “composite poetic idiom” of the ginans has been compared with that used in the Guru Granth Sahib (Shackle & Moir, 1992, p. 42). Additions, modifications and recensions make it difficult to date the ginans with certainty (Schimmel in Asani, 2002, p. xvi). While Shackle and Moir (1992, p. 15) consider the earliest ginans known today to have been orally composed in the sixteenth century, they admit that individual ginans may well comprise older elements. The oldest extant ginan in written form, which is also the oldest extant text in the Khojki script, dates from 1737 (Khakee, 1972, p. 5).
As with Gurmukhi, academic consensus on the Khojki script’s evolution from unstandardised Landa and, ultimately, from Brahmi stands in contrast to popular legends on its origin. Just as Sikh tradition talks of Gurmukhi having been created or polished by Guru Angad, Ismaili tradition considers Khojki to have been invented or refined by the fifteenth-century Ismaili missionary or pir, Pir Sadruddin (Allana, 1993 [1964], p. 37; Asani, 1987, p. 439). Moreover, just as the Guru Granth Sahib’s mixed idiom has not prevented the Gurmukhi script from becoming near-synonymous with the label ‘Punjabi’, so too has the variegated linguistic nature of the ginans not impeded the Khojki script from becoming intimately associated with the label ‘Sindhi’ (Virani, 2022). Thus, while a dispassionate academic argument may posit that Khojki is no more ‘Sindhi’ than Gurmukhi is ‘Punjabi’, popular opinion indicates otherwise.
10.1 Nomenclature
The term Khojki is the adjectival form of Khoja [kʰod͡ʑa ~ xod͡ʑa] — an alternative and commonly used appellation for South Asian Nizari Ismailis thought to be a phonological indigenisation of the Persian [xʷɒd͡ʒe] ‘master’ (Asani, 1991, p. 64; Shackle & Moir, 1992, p. 7; but see Akhtar, 2016, pp. 33–34).120 Whereas the term Khoja has been in use for centuries, the name Khojki is arguably of relatively recent origin. Historically, the script did not have a specific name, existing as it did on a graphetic continuum of unstandardised Landa inventories (§5.1.1). Nineteenth-century European authors tend to describe the script as a community-specific calligraphic hand of Sindhi-style Landa, on par with Khudawadi. In his comparative chart of graph inventories for the Sindhi language, Stack (1849a, pp. 3–9) includes the inventory of graphetic forms today identified as Khojki under the title ‘Khwajas’. Early twentieth-century publications in the script printed using metal types simply refer to the script as ‘Sindhi’ (Devraj, 1910).
According to Virani (2022), one of the earliest mentions in writing of a term resembling [kʰod͡ʑᶦki ~ xod͡ʑᶦki] is in a Gujarati language-and-script (𝚐𝚞-𝙶𝚞𝚓𝚛) report on the annual meeting of the Khoja Ismaili Library of Karachi. The report lists the library’s Khojki-script book holdings under the label |સીંધી ખોજકી| [sin̪d̪ʱi kʰod͡ʑ(ə)ki]. A decade later, another 𝚐𝚞-𝙶𝚞𝚓𝚛 community publication featured the term |ખોજાકી| [kʰod͡ʑaki], which varied slightly in form from the previous instance. Within the academic sphere, Virani attributes the introduction of the 𝚎𝚗-𝙻𝚊𝚝𝚗 form |Khojki| to the Russian scholar Wladimir Ivanow, who wrote in 1936:
It is generally accepted that in the earliest times, they [the ginans] were not written, but simply committed to memory by the faithful; it was only much later that they were written down in Sindhi (Khojki) characters.
In another research article a couple of years later, Ivanow (1938, pp. 57–59) once again uses the term |Khojki| to describe the liturgical script of the Ismailis. Over the following two decades, use of the name increased steadily within scholarship. Baloch’s (1962) 𝚜𝚍-𝙰𝚛𝚊𝚋 monograph contains mentions of |خوجڪي| [xod͡ʑᶦki] (pp. 107, 115), while Schimmel’s (1964) German-language article contains the Latin-script spelling |Khojki| (p. 241). Overall, though, Bhalloo and Akhtar (2018, p. 322) credit the spread of the term in academia to the first edition of Allana’s (1993 [1964]) 𝚜𝚍-𝙰𝚛𝚊𝚋 monograph on Sindhi orthography. Appearing to validate this claim is the steady rise in the scholarly use of |Khojki| and its equivalents in the years after Allana’s work, as attested in Noorally (1971), Khakee (1972), Nanji (1972) and Asani (1984). That said, the 𝚜𝚍-𝙰𝚛𝚊𝚋 form used by Allana (1993 [1964]) to describe the script is actually |خواجڪي| [xᶷwad͡ʑᶦki] and its variant |خواجڪو| [xᶷwad͡ʑᶦko] (pp. 37–39), both meaning ‘of the Khwajas’.121.
In this regard, Virani (2022) underscores the term’s origins as an externally introduced neologism. In particular, he observes that the uptake of |Khojki| has been the most vigorous in Western academia. Other sources corroborate the spread of |Khojki| within English-language scholarship (Tajddin Sadik Ali, 1989). In popular Ismaili literature, though, the term often appears juxtaposed with ‘Sindhi’, the latter being the historically prevalent emic name for the script. For Virani, the piecemeal and tentative adoption of the term |Khojki| in lay contexts points to implicit community awareness that the term is an external coinage. Virani himself refers to the script as |Khwājah Sindhi|, occasionally appending ‘Khojki’ for clarity.
In the context of the present book, adopting the term ‘Khwajah Sindhi’ for the Ismaili community’s traditional script may risk inadvertent confusion with the Sindhi language, and in the process impact reader comprehension. It would also warrant an analogous approach to the name ‘Khudawadi’ for reasons of consistency, since the latter script, too, was emically known simply as ‘Sindhi’. The interdependent nature of these onomastic considerations necessitates a thoroughgoing holistic treatment, which is beyond the scope of this book. Consequently, I retain the term ‘Khojki’ in this book purely for reasons of practicality and expedience.
Likewise, unambiguously identifying the writing system — or systems — that Khojki forms a part of proves contentious. As mentioned, much early Khojki-script writing, including the earliest ginans, are in a mixed idiom comprising various New Indo-Aryan speech varieties. If the idiom of a Khojki-script ginan is identifiably Sindhi, the resultant writing system may be labelled 𝚜𝚍-𝙺𝚑𝚘𝚓. Similarly, Khojki-script ginans whose language component is predominantly Kutchi or Gujarati may be designated 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 and 𝚐𝚞-𝙺𝚑𝚘𝚓, respectively. Despite the multilingual and fluid nature of the Khojki-script ginans, there are observable patterns and conventions to be found in their graph inventory and graph-phone correspondences. Collectively, therefore, the writing system featured in written ginans may be referred to as 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓.122 By the nineteenth century, however, the increasing socioeconomic status of the Gujarati language within the Ismaili community led to a shift towards publishing primarily in Gujarati, albeit still in the Khojki script (§5.2.4). In fact, apart from the ginans, most Khojki-script content issued from the printing presses set up at the turn of the twentieth century was in 𝚐𝚞-𝙺𝚑𝚘𝚓. Notably, many of these 𝚐𝚞-𝙺𝚑𝚘𝚓 publications were labelled as being in ‘Sindhi’ (Devraj, 1910), reflecting the then-prevalent name for the script and affirming Virani’s (2022) arguments in this regard.
Since the language of most twentieth-century Khojki-script publications is not Sindhi but Gujarati, it may be argued that an analysis of such works lies outside the scope of this book. Furthermore, the liturgical significance of Khojki for the Ismaili community has led to the script and its content being extensively researched from graphetic, graphematic and sociolinguistic perspectives (Allana, 1993 [1964]; Asani, 1987, 1991, 1992; Bruce, 2015; Khakee, 1972; Moir, Shackle & Mitha, n.d.; Shackle & Moir, 1992, Tajddin Sadik Ali, 1989). Yet, the close indexical association of the label ‘Sindhi’ with the Khojki script is a strong argument in favour of the latter’s inclusion in a book on Sindhi’s writing systems. Given the considerable volume of grapholinguistic research that already exists on Khojki (albeit not under the rubric of grapholinguistics), this chapter will be selective in its scope, and prioritise those aspects of the script and its derivative writing systems that reinforce the findings of the other chapters in this book.
10.2 Graphematic foundations and early use
As with 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, Khojki-based writing exhibits a high degree of variation, be it in graph-phone correspondences or in the visual appearance of individual graphs. However, the neat graphematic distinction between 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 does not have a parallel in Khojki-based — that is, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓 — subvariants. Instead, graph-phone correspondences and graphetic features are seen to evolve gradually along a chronological continuum. At the same time, the advent of Khojki-script printing in using metal types at the turn of the twentieth century ushered in several graphetic innovations and graphematic standardisations in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓. The rise of Khojki-script printing, thus, represents a watershed moment in the evolution of 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓, and will be used as a reference point to delineate the system’s subvariants (Shackle & Moir, 1992, p. 36) into 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 and 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗. The former subvariant encompasses the highly variable graph inventory, graph-phone correspondences and spellings observed in manuscripts and early lithographs, while the latter denotes the quasi-standardised graph inventory, graph-phone correspondences and spellings attested after Khojki began to be printed using movable type. Consequently, Khojki-script texts composed in the twentieth and twenty-first centuries tend to reflect 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗’s inventory and graph-phone correspondences, unless explicitly intended to be a facsimile of a 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 text.
Despite the variability inherent in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 inventories, an overall visual coherence was attestable. Moreover, manuscripts in the system were often appended with a tabular chart of forty graphs — whence the name chaliha akhari ‘forty-letter script’ (§5.1.4). An idealised chaliha akhari table as listed in Shackle and Moir (1992, p. 35) is reproduced in (26).
(26)
| 𑈀 | 𑈂 | 𑈃 | 𑈄 | 𑈊 |
| 𑈈 | 𑈉 | 𑈋 | 𑈌 | 𑈍 |
| 𑈎 | 𑈏 | 𑈑 | 𑈐 | 𑈓 |
| 𑈔 | 𑈕 | 𑈖 | 𑈗 | 𑈘 |
| 𑈙 | 𑈚 | 𑈜 | 𑈛 | 𑈞 |
| 𑈟 | 𑈠 | 𑈢 | 𑈡 | 𑈤 |
| 𑈥 | 𑈦 | 𑈧 | 𑈨 | 𑈝 |
| 𑈩 | 𑈜𑈵𑈦 | 𑈙𑈵𑈦 | 𑈪 | 𑈣 |
Manuscripts would traditionally commence with the 𝚜𝚍-𝙺𝚑𝚘𝚓 benediction |𑈀𑈧𑈬𑈪 𑈙𑈲 𑈁𑈪𑈬𑈦| [əlaɦ(ᵊ) t̪o aɦaɾ(ᵊ)] ‘with the help of Allah’ (Asani, 1992, p. 44). Alternatively, the benediction might be appended to the table, in which case it was often recast as the five-unit graphematic string |𑈀 𑈧𑈬 𑈙𑈲 𑈪𑈬 𑈦| to align with the five-by-eight matrix (Shackle & Moir, 1992, p. 35). Table 10.1 shows the handwritten forms of Khojki graphs and their phonological values as featured in Stack’s Sindhi grammar (1849a, pp. 3–8). Also shown are the phonological values of the graphs attested in other sources (Asani, 1991, pp. 51–72; Khakee, 1972, pp. 598–607; Pandey, 2011b; Shackle & Moir, 1992, pp. 35–42). Depending on graphematic environment, every graph that canonically denotes a φ-consonant may also correspond to φ-[CV₀], where φ-[V₀] is the inherent or default φ-vowel for the language represented. For most languages transcribed in Khojki, including Sindhi-Kutchi and Gujarati, the default vowel is [ə].
Source: Stack (1849a, pp. 3–8)
| Stack (1849a) | Modern typeface | Common value(s) in IPA | Alternative values in IPA |
|---|---|---|---|
 |
𑈀 | ə | |
 |
𑈁 | a | |
 |
𑈄 (𑈀𑈭 ) | ɪ | e |
 |
𑈂 | i | ɪ e j |
 |
 |
ʊ | u o |
 |
𑈃 | u | ʊ o |
 |
𑈄 (𑈀𑈭 ) | e | ɪ (ɛ) |
 |
𑈀𑈄 | əi̯ (ɛ) | |
 |
 |
o | (ɔ) |
|
𑈀 |
əʊ̯ (ɔ) | |
 |
𑈈 | k | (q) |
 |
𑈉 | kʰ | (x) |
 |
𑈊 | ɡ | ɡʱ ɠ (ɣ) |
 |
𑈋 | ɠ | ɡ ɡɾ |
 |
𑈌 | ɡʱ | ɡ ɠ |
 |
𑈓 (𑈍) | ŋ ɲ | |
 |
𑈎 | t͡ɕ | |
 |
𑈏 | t͡ɕʰ | |
 |
𑈐 | d͡ʑ | d͡ʑʱ ʄ (z) |
 |
𑈑 | ʄ | d͡ʑ d͡ʑʱ ɲ (z) |
 |
(𑈐?) | d͡ʑʱ | d͡ʑ ʄ (z) |
 |
𑈔 (𑈕) | ʈ ʈɾ ʈʰ | |
 |
𑈙𑈵𑈦 | ʈ ʈɾ | t̪ɾ |
 |
𑈘 (𑈖) | ɽ | ɖ ɳ (ɽ̃) |
 |
𑈜 | ɗ | ɖ d̪ d̪ʱ |
 |
𑈛𑈵𑈦 | ɖɾ | ɗ d̪ d̪ɾ d̪ʱɾ |
 |
𑈗 | ɖʱ | ɖ |
 |
𑈙 | t̪ | |
 |
𑈚 | t̪ʰ | |
 |
𑈛 | d̪ | d̪ʱ |
 |
𑈝 | d̪ʱ | d͡ʑʱ d̪ (z) |
 |
𑈞 | n (n̪) | |
 |
𑈟 | p | |
 |
𑈠 | pʰ | (f) |
 |
𑈡 | b | ɓ bʱ |
 |
𑈢 | ɓ | b bʱ |
 |
𑈣 | bʱ | b ɓ |
 |
𑈤 | m | |
 |
𑈦 | ɾ | |
 |
𑈧 | l | |
 |
𑈨 | ʋ | |
 |
𑈩 | s | (ɕ) |
 |
𑈪 | ɦ |
Absent from Stack’s chart are 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍’s bound γ-vowels, as well as variant forms of free γ-vowels. These are shown in (27), along with their respective phonological values (Asani, 1991, pp. 51–72; Khakee, 1972, pp. 598–607; Pandey, 2011b; Shackle & Moir, 1992, pp. 35–42).
(27)
| Bound vowel allograph | Values in IPA | Bound vowel allograph | Values in IPA |
|---|---|---|---|
| 𑈭 | ə ɪ i e (j) (Ø) | 𑉀 | ɪ i |
| 𑈬 | a | 𑈆 | ʊ u o |
| 𑈮 | ɪ i | 𑈃𑈲 | o |
| 𑈯 | ʊ u o | 𑈀𑈰 | e (ɛ) |
| 𑈰 | e (ɛ) | 𑈀𑈲 | o (ɔ) |
| 𑈲 | o (ɔ) | 𑈀𑈆 | əʊ̯ ~ ɔ |
Taken together, Table 10.1 and (27) reveal how the resemblance between Khojki and its Landa relatives goes deeper than mere visual or graphetic harmony. Similar to writing systems based on Khudawadi and Gurmukhi, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍, too, employs three distinct graphetic bases to form graphs for low, high front and high back φ-vowels (§5.1.4). In this regard, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓 |𑈀 𑉀 𑈆| are equivalent to 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 |𑊰 𑊲 𑊴| and 𝚙𝚊-𝙶𝚞𝚛𝚞 |ਅ ੲ ੳ|, respectively. Where 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 diverges from 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 while further resembling early 𝚙𝚊-𝙶𝚞𝚛𝚞 is in its use of bound γ-vowels in postconsonantal position (Shackle & Moir, 1992, p. 37). The use of bound γ-vowels can be attributed to the sustained use of the writing system in liturgical contexts, which incentivised organic development of transparency and consistency in graph-phone correspondences. Indeed, the use of bound γ-vowels distinguished 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 from the various unstandardised Landa-based writing systems used in pre-British Sindh. In his Sindhi grammar, Stack (1849a, p. 2) notes that, of all the communities in Sindh that wrote in Landa-based inventories at the time, “[t]he Khwájás alone occasionally use the lákaná, or medial vowel marks”.123
Yet, the distribution between free and bound γ-vowels was not mutually exclusive or exhaustive. Early manuscripts typically exhibited an inventory of six bound γ-vowels, shown in (27) (Shackle & Moir, 1992, p. 37). However, the phonological values of these bound γ-vowels were variable, as was their supposed allography with free γ-vowels. For instance, a particular 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 text might feature bound |𑈭 𑈮| [ɪ ~ i] but only free |𑈂|, resulting in a theoretical many-to-one correspondence between bound and free γ-vowels. Moreover, |𑈭| might also denote values other than [ɪ ~ i], resulting in further disparity with the idealised Indic alphasyllabary paradigm. With time, though, the crystallisation of graph values and distribution resulted in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 gradually featuring mutually exclusive free and bound γ-vowel pairs. Where necessary, new graphs were developed by combining rasmic bases. Thus, |𑈄| [ɪ ~ e] is likely the result of a graphetic merger between |𑈀| and |𑈭 | (Khakee, 1972, p. 604). Similarly, |𑈃| and the near-identical || appear to be fusions of |𑈆| and |𑈯|. Sociolinguistic pressure on the inventory’s scope also resulted in the introduction of Devanagari-inspired |𑈱 𑈳| for [əɪ̯ ~ ɛ] and [əʊ̯ ~ ɔ], respectively. These bound γ-vowels were then used to backform the corresponding free γ-vowels |𑈅 𑈇| as alternatives to the digraphic |𑈀𑈄 𑈀𑈆|, respectively. That said, |𑈱 𑈳| and their free counterparts are attested only rarely, with most texts employing |𑈰 𑈲| [e o] and their free allographs in their stead (Asani, 1991, pp. 51–72; Khakee, 1972, pp. 598–607; Pandey, 2011b; Shackle & Moir, 1992, pp. 35–42).
Notwithstanding the gradual normativisation of 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 free γ-vowels, allographs and graphetic variations were particularly noticeable in the composition of graphs denoting high back φ-vowels. For instance, Allana (1993 [1964], p. 39) lists |
 | as the free γ-vowels for [
| as the free γ-vowels for [ʊ ~ u]. While || may be considered a graphetic allograph of |𑈃| or || from Stack’s chart (Table 10.1), || has no parallel. Compositionally, it comprises the Khojki rasm |𑈆| juxtaposed with Gujarati-script |ૂ| within the same graphosegmental space. Notably, Khojki || appears compositionally equivalent to the Gujarati-script free γ-vowel |ઉૂ |, which is listed by Bagster (1851, p. xlv) as the 𝚐𝚞-𝙶𝚞𝚓𝚛 graph for [u]. Much like Khojki ||, Gujarati-script |ઉૂ | features the rasm |ઉ| [ʊ ~ u] combined with the bound γ-vowel |ૂ| [u]. While the Khojki-script graph || listed by Allana is graphetically and graphematically plausible, Asani (1991, pp. 58–59) notes that it does not appear to have been attested in any 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 manuscript. Asani makes a similar observation regarding || [o] listed by Stack (Table 10.1).
The phonological polyvalency of 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍’s γ-consonants has also been the subject of much scholarly attention. Based on Asani (1991, pp. 60–62), Pandey (2011b, p. 3) attributes the use of a single graph with multiple phonological values to the gradual spread of the proto-standardised Khojki inventory across regions with different dominant languages:
A reason for such [graphematic] ambiguity is the use of Khojki outside of Sindh by scribes unfamiliar with the Sindhi language. When non-Sindhi speakers wrote Khojki, certain characters [i.e., graphs] that represented sounds specific to Sindhi, such as the implosive consonant letters [denoting
ɠ(ə) ʄ(ə) ɗ(ə) ɓ(ə)] lost their original phonetic values. As a result of this neutralization, the original glyphs for these letters were reassigned to other consonants [i.e., consonant phones] within the same articulation class.
Pandey, thus, observes that Khojki texts with content in Sindhi or Kutchi — that is, texts where the writing system is 𝚜𝚍-𝙺𝚑𝚘𝚓 or 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 — tend to feature the graphs |𑈋 𑈑 𑈜 𑈢| with the phonological values [ɠ(ə) ʄ(ə) ɗ(ə) ɓ(ə)]. However, the phonological inventories of Gujarati, Hindi-Urdu and related South Asian languages do not feature φ-implosives. As a result, when Gujarati or Hindi-Urdu content was transcribed in Khojki, the graphs |𑈋 𑈑 𑈜 𑈢| were often ‘recycled’ and used to denote other φ-consonants in the relevant languages (Asani, 1991, p. 61; Shackle & Moir, 1992, p. 36). Thus, |𑈜|, which typically denoted [ɗ] in a 𝚜𝚍-𝙺𝚑𝚘𝚓 or 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 text, often took on the value [d̪] in a 𝚐𝚞-𝙺𝚑𝚘𝚓 text. Against this background, Asani (1991, pp. 61–62) notes that a correct phonological interpretation of a Khojki-script text often necessitates knowledge of the geographical region in which the text originated, in order to arrive at the likely speech variety represented in the text. This allows for the text to be decoded by applying graph-phone correspondences typical of that language. The phenomenon of distinct graph-phone correspondences based on the language denoted holds true not just for manuscripts, but also for print publications in Khojki. Thus, in the 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 text titled |𑈩𑈙𑈨𑈰𑈘𑈮 𑈨𑈜𑈮 𑈙𑈚𑈬 𑈞𑈭𑈴𑈗𑈮| [sət̪(ᵊ)ʋeɳi ʋəɗi t̪ət̪ʰa nɪɳɖʱi], |𑈜𑈮| denotes [ɗi], whereas in the 𝚐𝚞-𝙺𝚑𝚘𝚓 text titled |𑈞𑈬𑈞𑈲 𑈜𑈩 𑈀𑈨𑈙𑈬𑈦 𑈟𑈮𑈦 𑈩𑈜𑈦𑈜𑈮𑈞 𑈞𑈲 𑈦𑈎𑈰𑈧𑈲| [nano d̪əs əʋ(ə)t̪aɾ piɾ səd̪əɾd̪in no ɾət͡ɕelo], |𑈜 𑈜𑈮| indicate [d̪ə d̪i], respectively (Bruce, 2015, p. 45).
Yet, while graph-phone correspondences in Khojki-script texts display observable patterns of conditioning by the language being encoded, such patterns are not predictable or consistent. This means that a Khojki-script text featuring content in a language other than Sindhi-Kutchi — and which, therefore, does not feature φ-implosives — may feature |𑈋 𑈑 𑈜 𑈢| assigned to a host of different φ-consonants, depending on the scribe and their dominant language. For instance, the graph |𑈑| may denote [d͡ʑ(ə)] or [d͡ʑʱ(ə)] in a 𝚐𝚞-𝙺𝚑𝚘𝚓 text. In addition, Khakee (1972, p. 602) notes that a similar-looking graph is used to indicate [ɲ] in the oldest extant Khojki-script text, dating from 1737. Graphematically, the practice of using the same graph for [ʄ] as well as [ɲ] bears similarities to 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚊𝚍’s use of |ڃۡ| for [ʄ] and the graphetically similar |نڃۡ| for [ɲ] (Table 6.3). One may also conjecture that the graphetic similarity between 𝚐𝚞-𝙶𝚞𝚓𝚛 |ઝ| [d͡ʑʱ(ə)] and |ઞ| [ɲ(ə)] may have played a part here.
Related to |𑈑| is the graphetically similar |𑈝|, depicted in Stack’s chart as denoting [d̪ʱ(ə)]. However, a similar-looking graph has also been attested in manuscripts with the value [d͡ʑʱ(ə)] (Allana, 1993 [1964], p. 39; Asani, 1992, p. 681). Phonologically, [d̪ʱ] and [d͡ʑʱ] are fairly distinct in their places and manners of articulation. Hence, claiming that they would be written with one and the same graph merits further scrutiny. Pandey (2011b, p. 13) hypothesises that certain handwritten instances of |𑈝| [d͡ʑʱ(ə)] are effectively graphetic allographs of |𑈐| [d͡ʑ(ə)]. Offering support to this hypothesis is the lack of graphematic distinction between unaspirated and aspirated voiced φ-plosives observed in Khojki-script texts, and in unstandardised Landa-script texts more broadly. Graphematic underdifferentiation between [d͡ʑʱ(ə) d͡ʑʱ(ə)] is also attested in Stack’s chart (Table 10.1), which lists near-identical graphs for the two.
Other alternations such as the use of |𑈘 𑈖| for one or more of [ɖ ɽ ɳ (ɽ̃) (ɽʱ)] seems plausible when viewed against the fact that [ɖ ɽ] are not graphematically distinguished in many Indic-script-based writing systems (but see footnote 84). In systems that do have separate graphs for [ɖ ɽ], such as 𝚜𝚍-𝙳𝚎𝚟𝚊 |ड ड़|, the graphs themselves are rasmically identical and differ only subsegmentally. Moreover, given that [ɳ] is often realised intervocalically as [ɽ̃] in several Indo-Aryan languages (§4.3.1), the phonological distribution in question lies well within the realms of possibility.
Certain graphs in the 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 inventory bear graphetic similarities to their canonical equivalents or near-equivalents in other inventories. Thus, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓 |𑈉| [kʰ(ə)] corresponds graphetically and phonologically to 𝚜𝚍-𝚂𝚒𝚗𝚍 |𑊻| [kʰ(ə)], with both corresponding graphetically — but not phonologically — to 𝚜𝚊-𝙳𝚎𝚟𝚊 |ष| [ʂa] (Table 8.1).
Stack’s chart (1849a, p. 7) lacks a distinct graph for [j(ə)], listing instead the graph |𑈐| against it. This means that, in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍, |𑈐| could denote one or more of [d͡ʑ(ə) d͡ʑʱ(ə) j(ə)]. However, this mapping is consistent with that of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 |𑋘|, which could denote one or more of [d͡ʑ(ə) d͡ʑʱ(ə) j(ə)] (Table 8.1). In later 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 texts, [j(ə)] is denoted by |𑈥|, which likely emerged as a spin-off of the free γ-vowel |𑈂| [ɪ i] (Asani, 1991, p. 61).
Much like 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 and contemporary 𝚜𝚍-𝙳𝚎𝚟𝚊 practice, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 uses the same bound graph to denote the nasalisation suprasegmental on a φ-vowel as well as a nasal φ-consonant that forms a cluster with a homorganic oral φ-consonant. However, the use of this graph is erratic, especially in early 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍. Graphetically, it may appear as a dot or as a circle (Shackle & Moir, 1992, pp. 38–40), mirroring similar practice in 𝚐𝚞-𝙶𝚞𝚓𝚛 at the time (Grierson, 1908, p. 338). There was no dedicated virama in early 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍. Some early writers added a dot-like graph above a γ-consonant to function as a makeshift virama, which made it liable to misinterpretation as an anusvara (Asani, 1991, p. 63; Shackle & Moir, 1992, p. 37). Later manuscripts and early print texts often used |𑈭 | with the function of a virama (see (27)). Thus, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 |𑈟𑈭𑈦𑈰𑈤| may be decoded as [pᶦɾem] or [pɾem] (Asani, 1991, p. 63), and |𑈈𑈭𑈥𑈯𑈴| as [kᶦjũ] or [kjũ] (Shackle & Moir, 1992, p. 41). Phonologically, this practice reflects the free alternation of [Ø] with epenthetic [ɪ] in many spoken Sindhi varieties (§4.3.1). This practice is also consistent with the use of 𝚜𝚍-𝙰𝚛𝚊𝚋 | ◌ِ |, 𝚜𝚍-𝙳𝚎𝚟𝚊 |ि|, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 |𑋡| and 𝚜𝚍-𝙶𝚞𝚛𝚞 |ਿ|, all of which canonically denote |ɪ|, in near-free variation with their respective graphs for [Ø] (jazm or virama).
Later manuscripts also featured bound forms of the γ-consonants |𑈥 𑈦| [j(ə) ɾ(ə)] when denoting the second element of a φ-consonant cluster, as in |𑈈𑈵𑈥| [kj(ə)] and |𑈩𑈵𑈦| [sɾ(ə)] (Asani, 1992; Pandey, 2011b). Depending on the extent of graphetic integration, the bound γ-consonant may be classified as a ligature.
Numerals in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓, |૧ ૨ ૩ ૪ ૫ ૬ ૭ ૮ ૯ ૦|, may be considered identical to those in 𝚐𝚞-𝙶𝚞𝚓𝚛 (Moir, Shackle, & Mitha, n.d., p. 27; Pandey, 2011b, p. 10), which are themselves near-identical to numerals in other Landa inventories (see Example (21)) and in Devanagari (see Example (14)). Manuscripts feature expected graphetic variation in numeral shapes. Manuscripts in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 were also rich in indigenous punctuation practices attested in other Indic-script-based writing systems. These included the use of |𑈸 𑈹| to mark the end of sentences and verses, respectively (Pandey, 2011b, p. 9). At the same time, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 diverged from its contemporaries in using the colon-like graph |𑈺| as a word separator (Asani, 1992, p. 44). While graphetically similar to the visarga in several Indic-script inventories, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍’s lack of a dedicated visarga ruled out any potential conflation (Pandey, 2011b, p. 9). Manuscripts also featured |𑈻 𑈼|, lengthened as needed, to fill the space between the end of a sentence or paragraph and the page margin (Pandey, 2011b, p. 9).
10.3 Early twentieth-century practices
The appearance of Khojki-script publications in print in the late nineteenth and early twentieth century (§5.2.4) greatly incentivised graphetic and graphematic standardisation within 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓. At the same time, the rise of Gujarati as the prestige language in the Nizari Ismaili community meant that, aside from the ginans, most material published in the Khojki script was in the Gujarati language (𝚐𝚞-𝙺𝚑𝚘𝚓). However, there also appeared certain key publications in the Khojki script that were not in the Gujarati language, prominent among them being a parallel text in Persian-Khojki (𝚏𝚊-𝙺𝚑𝚘𝚓) and Kutchi-Khojki (𝚔𝚏𝚛-𝙺𝚑𝚘𝚓) (Devraj, 1904). Moreover, the need to accurately represent phonemes specific to the Arabic and Gujarati languages led to graphematically significant and insightful innovations in the parent system of 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓. As a result, modern publications in Khojki are distinct enough from 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 texts to warrant a distinct subtag: 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗. Notwithstanding these developments, publications in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗, regardless of the language(s) represented, remained associated with the sociolinguistic label of ‘Sindhi’, to the extent that 𝚐𝚞-𝙺𝚑𝚘𝚓 publications routinely featured ‘Sindhi’ in their titles (Devraj, 1910). These developments in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓 in the early twentieth century have several graphematic and sociolinguistic insights to offer, for grapholinguistics in general and Sindhi studies in particular.
The vast majority of innovations in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 can be attributed to Laljibhai Devraj (§5.2.4). In his role as ‘official’ publisher of ginanic material, Devraj cut some of the earliest metal types for Khojki graphs and published copious amounts of literature in the script (Asani, 1991; Bruce, 2015; Pandey, 2011b; Shackle & Moir, 1992). Following is an overview of 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗’s salient features that distinguish it from its traditional counterpart, many of which were initiated by Devraj.
10.3.1 Bound graphs
Initial publications in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 replicated the 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 practice of depicting anusvara with two allographs, one resembling a dot and the other a circle. While the two forms were in free variation in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍, there emerged hints of complementary distribution in early 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗. While the dot-like form |𑈴| prevailed in most contexts, the circle-like form was used only above the bound γ-vowel |𑈬| [a] (Pandey, 2011b, p. 7). Figure 10.1 features extracts from the title pages of two early Khojki-script publications printed using metal types (Devraj, 1904; 1910), with variable manifestations of the anusvara.


Sources: Devraj (1904; 1910)
In Figure 10.1, the first extract is from a publication with the 𝚏𝚊-𝙺𝚑𝚘𝚓 title |𑈠𑈴𑈛𑈮𑈁𑈙𑈺 𑈐𑈶𑈨𑈬𑈤𑈦𑈛𑈮𑈺| Pandiyat-e Javanmardi ‘Principles of Manliness’ (Devraj, 1904).124 Here, the word |𑈠𑈴𑈛𑈮𑈁𑈙| [pændi(j)ɒt] features the graphematic unit |𑈠𑈴| [pæn], with the nasal segment [n] denoted by a dot-like anusvara |𑈴|. However, in the word |𑈐𑈶𑈨𑈬𑈤𑈦𑈛𑈮| [d͡ʒævɒnmæɾdi], the nasal segment [n] is left altogether unmarked. It is unclear whether the nonrepresentation of [n] in |𑈐𑈶𑈨𑈬𑈤𑈦𑈛𑈮| is an inadvertent omission, or if it indicates the Indicised pronunciation [d͡ʑəʋãməɾd̪i] (Matthews, 2014), where segmental [n] is replaced by the nasalisation suprasegmental [◌̃]. Since the nasalisation suprasegmental was often left unmarked in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 (Shackle & Moir, 1992, pp. 38–40), the absence of anusvara in |𑈐𑈶𑈨𑈬𑈤𑈦𑈛𑈮| may reflect vestigial continuation of this practice.
In contrast, the 𝚐𝚞-𝙺𝚑𝚘𝚓 title of Devraj’s (1910) primer |𑈩𑈭𑈴𑈛𑈮 𑈟𑈪𑈰𑈧𑈮 𑈎𑈲𑈟𑈖𑈮| Sindhi Paheli Chopdi ‘Sindhi First Book’ features both anusvara allographs in free variation.125 As seen in Figure 10.1, the word |𑈩𑈭𑈴𑈛𑈮| ‘Sindhi’ is written with a circle-like anusvara on the first line, and with a dot-like allograph immediately below in smaller font. A look at the book’s body text reveals consistent use of |𑈴| throughout, with the circle-like allograph restricted to a handful of occurrences, usually in the truncated form |𑈾| (Devraj, 1910, seq. 2, 7). Therefore, it appears that, in this particular publication, the variation between the allographs of anusvara was purely graphetic and conditioned by the typeface used. This conclusion is bolstered by the fact that, apart from anusvara, the two instances of the word |𑈩𑈭𑈴𑈛𑈮| seen in Figure 10.1 also feature distinct graphetic allographs — or ligatures — of |𑈩𑈭| and |𑈛𑈮|.
Early texts in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 , especially those printed using movable type, often persisted with the 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 practice of using |𑈭 | in unstandardised ways as a substitute for a virama (see Example (27)). For instance, a lithographed text from the late nineteenth century (1890?) features the Sindhi-language benediction [əlaɦ(ᵊ) t̪o aɦaɾ(ᵊ)] (§10.2) transcribed in Khojki as |𑈀𑈧𑈬𑈪𑈭 𑈙𑈲 𑈁𑈪𑈬𑈦𑈭|, with the words |𑈀𑈧𑈬𑈪𑈭| [əlaɦ(ᵊ)] and |𑈁𑈪𑈬𑈦𑈭| [aɦaɾ(ᵊ)] affixed with a final |𑈭 | indicating [ᵊ ~ Ø]. In his (1910) primer, Devraj introduced a dedicated virama |𑈵| into the 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 inventory. Graphetically, it was inspired by the virama in Devanagari- and Gujarati-script-based inventories. Notably, Devraj also introduced the virama allograph |◌᳐| in complementary distribution with |𑈵|. The allograph |◌᳐| was to be used whenever the following graph was |𑈦| [ɾ(ə)]. This resulted in both virama allographs sometimes appearing within the same word. For instance, in Devraj (1910, seq. 3), the Sanskritic loanword [pɾəst̪aʋ(ə)na] ‘preface’ appears as |𑈟᳐𑈦𑈩𑈵𑈙𑈬𑈨𑈞𑈬|, with [pɾə] realised as |𑈟᳐𑈦| but [st̪a] as |𑈩𑈵𑈙𑈬|. Similarly, another Sanskritic loanword, [d̪ɾəʋj(ə)] ‘wealth’, is transcribed |𑈜᳐𑈦𑈨𑈵𑈥|, where [d̪ɾə] is denoted by |𑈜᳐𑈦| and [ʋj(ə)] by |𑈨𑈵𑈥| (Devraj, 1910, seq. 15). The motivation behind introducing this allograph for the virama is unclear, especially since complex graphs or ‘ligatures’ such as |𑈟𑈵𑈦| [pɾ(ə)] and |𑈨𑈵𑈥| [ʋj(ə)] were attested in manuscripts by the early twentieth century (§10.2). It is conceivable that typographical considerations may have discouraged the use of complex graphs denoting φ-consonant clusters, as was the case in Khudawadi type for 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 (§8.2.2). Indeed, Devraj’s works are deficient in dependent or ‘half’ γ-consonants of the kind seen in |𑈟𑈵𑈦| [pɾ(ə)] and |𑈨𑈵𑈥| [ʋj(ə)]. One may further hypothesise that the shape and function of Khojki |◌᳐| was inspired by the 𝚜𝚍-𝙰𝚛𝚊𝚋 jazm | ◌ٛ| (see Example (6)), as well as the bound γ-consonant |◌᳙| [ɾ(ə)] attested in 𝚐𝚞-𝙶𝚞𝚓𝚛 |ટ્ર ડ્ર| and 𝚑𝚒-𝙳𝚎𝚟𝚊 |ट्र ड्र| [ʈɾ(ə) ɖɾ(ə)]. However, unlike 𝚐𝚞-𝙶𝚞𝚓𝚛 and 𝚑𝚒-𝙳𝚎𝚟𝚊 |◌᳙|, which clearly maps to [ɾ(ə)], 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 |◌᳐| did not correspond to a phonological segment. Rather, as an allograph of the virama, it simply denoted [Ø]. Furthermore, the occurrence of 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 |◌᳐| above a γ-consonant was distinct from that of 𝚐𝚞-𝙶𝚞𝚓𝚛 and 𝚑𝚒-𝙳𝚎𝚟𝚊 |◌᳙|, which appear below a γ-consonant. While |◌᳐| appeared in a few other works published by Devraj’s Khoja Sindhi Printing Press (Asani, 1992, pp. 224, 323), it seems to have fallen out of favour not long thereafter.
Notwithstanding the ambiguous origins of |◌᳐|, Devraj (1910) introduced two other bound graphs whose roots lay clearly in the Sanskritic-Indic graphematic model. These graphs are |ૃ| and |ઃ|, intended as inventorial equivalents to 𝚜𝚊-𝙳𝚎𝚟𝚊 |ृ| [ɾ̩] and visarga |ः|, respectively (§7.1). Evidently, both graphs were restricted to transcribing Sanskrit-origin loanwords in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 — or, more specifically, in 𝚐𝚞-𝙺𝚑𝚘𝚓 (Srinidhi & Sridatta, 2017). However, just as Sanskrit [ɾ̩] is realised in Sindhi and Hindi as [ɾɪ] (Table 7.1; §7.6.1), it manifests in Gujarati as [ɾu]. Hence, the phonological value of 𝚐𝚞-𝙺𝚑𝚘𝚓 |ૃ| is effectively [ɾu]. Devraj (1910, seq. 5) himself states as much in the introduction to his primer, noting that |ૃ| is homophonous with the graphematic unit |𑈦𑈯| [ɾu]. This fact is also evident from the spellings of the Sanskrit-origin loanword [aʋɾut̪t̪i] ‘edition’ in 𝚐𝚞-𝙺𝚑𝚘𝚓 seen in Figure 10.1. On the left (Devraj, 1904), the word appears as |𑈁𑈨𑈦𑈯𑈙𑈮|, whereas, on the right (Devraj, 1910), it is spelt |𑈁𑈨𑉁𑈙𑈭|.126 Notably, there is no free counterpart of |ૃ|, along the lines of 𝚜𝚊-𝙳𝚎𝚟𝚊 |ऋ| and 𝚐𝚞-𝙶𝚞𝚓𝚛 |ઋ|. Regardless, the (1910) primer makes widespread and relatively consistent use of |ૃ| in transcribing Sanskrit-origin loanwords into 𝚐𝚞-𝙺𝚑𝚘𝚓 (Pandey, 2021c). Similarly, visarga also appears where mandated by Sanskritic etymological spelling, as in |𑈀𑈴𑈙𑈺𑈈𑈦𑈘| [ən̪t̪əkkəɾəɳ] ‘conscience’ and |𑈜𑈯𑈺𑈉| [d̪ukkʰ(ə)] ‘sadness’ (Devraj, 1910, seq. 15, 21). As evident, the Khojki visarga |ઃ| may be visually confused with the word separator graph |𑈺| common in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 (Pandey, 2021d). However, since the latter is not commonly used in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗, the scope for conflict is reduced.
In later twentieth-century publications, another bound graph, |𑈾|, began to be used to denote [Ø], this time in Quranic Arabic texts transcribed in Khojki (𝚊𝚛-𝙺𝚑𝚘𝚓). Intended as an inventorial equivalent to 𝚊𝚛-𝙰𝚛𝚊𝚋’s sukun (Pandey, 2014a; 2014b), its graphetic and graphotactic properties were inspired by the sukun’s circle-like allograph |◌ْ| (see Example (6)). Whereas the Khojki sukun |𑈾| remained largely restricted to 𝚊𝚛-𝙺𝚑𝚘𝚓 texts, another bound graph inspired from the Arabic script became relatively widely used in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 texts for a while. Derived from 𝚊𝚛-𝙰𝚛𝚊𝚋’s tashdid |◌ّ|, the Khojki |𑈷| was placed above a γ-consonant to denote phonological gemination. That said, it was generally written only on Arabic-origin words transcribed in Khojki. Thus, |𑈷| appears on the Arabic-origin word |𑈀𑈧𑈷𑈬𑈪| ‘Allah’ but not on the Sanskrit-origin word |𑈃𑈎𑈵𑈎𑈬𑈦| [utt͡ɕaɾ] ‘pronunciation’ (Devraj, 1910, seq. 5, 11).127 In this regard, the distribution of tashdid |𑈷| is akin to that of the Sanskritic bound graphs |ૃ| and |ઃ| in being conditioned by lexical-etymological factors.
While |ૃ| and visarga |ઃ| faded away in the years following, sukun |𑈾| and tashdid |𑈷| persisted until after Partition, at least in 𝚊𝚛-𝙺𝚑𝚘𝚓 texts (Pandey, 2014b). In general, the post-Partition era saw 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 do away with several bound graphs introduced at the start of the twentieth century. While these graphs may be still considered part of the 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 inventory, certain primers (Moir, Shackle, & Mitha, n.d.; Tajddin Sadik Ali, 1989) make no mention of them, including virama |𑈵| and its allographs. This has resulted in the re-emergence of certain underspecified spellings, where the reader is left to infer the precise occurrence of [Ø] or inherent [ə] from the graphematic environment. For instance, one primer (Moir, Shackle, & Mitha, n.d., p. 12) features the Arabic-origin loanword [fəɾz] ‘duty’ transcribed as the somewhat opaque |𑈠𑈦𑈐|, instead of the more transparent |𑈠𑈦𑈵𑈐𑈵|.
Apart from the various bound graphs described above, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 publications in the early twentieth century adopted and made extensive use of the bound γ-vowels |𑈱 𑈳|, canonically denoting [əɪ̯ ~ ɛ] and [əʊ̯ ~ ɔ], respectively. However, as in standard Sindhi (§4.3.2), these so-called diphthongs were often realised in Gujarati as the monophthongs [e o]. Hence, the introduction of |𑈱 𑈳| did not result in increased transparency. If anything, it could be described as graphematic overdifferentiation based on lexical-etymological spelling. Hence, within the 𝚐𝚞-𝙺𝚑𝚘𝚓 subvariant, spellings such as |𑈟𑈱𑈩𑈬| ‘money’ and |𑈤𑈳𑈧𑈬| ‘lord’ were effectively pronounced [pesa] and [mola], respectively, with |𑈱 𑈳| realised identically to |𑈰 𑈲| as [e o]. In later 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗, |𑈱 𑈳| are used sparingly, if at all. Primers may not list them as part of the γ-vowel inventory (Moir, Shackle, & Mitha, n.d.; Tajddin Sadik Ali, 1989), and suggest alternative spellings for impacted words. For instance, [mola] may be spelt |𑈤𑈲𑈧𑈬| or even |𑈤𑈃𑈧𑈬| (Moir, Shackle, & Mitha, n.d., p. 22), with the latter featuring the free γ-vowel |𑈃| [u].
Eventually, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 settled on a six-member inventory of bound γ-vowels, representing a codification of the graph-phone correspondences seen in Example (27). These were |𑈬 𑈭 𑈮 𑈯 𑈰 𑈲|, which represented canonical [a i i u e o]. The distinction between |𑈭 𑈮| was somewhat theoretical, due to which vacillation between them continued. In line with its abugidic nature, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 does not have a bound graph to denote [ə].
10.3.2 Free graphs
The 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 inventory of free vowel graphs eventually stabilised at |𑈀 𑈁 𑈂 𑈃 𑈄 𑈆|. As mentioned earlier, |𑈀|, which denotes [ə], does not have a corresponding bound counterpart. This results in a theoretical mismatch between free and bound γ-vowels in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗, with free |𑈂| corresponding to bound |𑈭 | as well as |𑈮|. Although the graph |𑉀| was attested in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 (see Example (27)), it failed to become established in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 as the exclusive free counterpart of |𑈭 | (Pandey, 2021b). Consequently, primers may list an ‘imbalanced’ or non-biunique set of free and bound γ-vowels, with |𑈂| corresponding to |𑈭 𑈮| both (Moir, Shackle, & Mitha, n.d.; Tajddin Sadik Ali, 1989).
In contrast, newly introduced graphs for φ-consonants or φ-[CV₀] sequences had more success in becoming accepted as part of the 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 inventory. Devraj’s (1910) primer introduced |𑈫 𑈈𑈵𑈩𑈶 𑈐𑈵𑈓|, intended as inventorial equivalents of 𝚐𝚞-𝙶𝚞𝚓𝚛 |ળ ક્ષ જ્ઞ| and Devanagari |ळ क्ष ज्ञ|, respectively. Within the 𝚐𝚞-𝙺𝚑𝚘𝚓 subvariant, their intended pronunciations were identical to their 𝚐𝚞-𝙶𝚞𝚓𝚛 equivalents, which represented [ɭ(ə)], [kɕ(ə) ~ ks(ə)] and [ɡn(ə)], respectively. Graphetically, the shape of 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 |𑈫| was clearly inspired from Devanagari’s |ळ|, which is used in writing Vedic Sanskrit (𝚜𝚊-𝙳𝚎𝚟𝚊-𝚟𝚜𝚗) and modern Marathi (𝚖𝚛-𝙳𝚎𝚟𝚊).128 In contrast, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 |𑈐𑈵𑈓| is a graphetic fusion or ligature of the homoscriptal |𑈊| [ɡ(ə)] and |𑈞| [n(ə)] whose shape has been conditioned by phonological factors. The shape of |𑈈𑈵𑈩𑈶| is harmonious with its Gujarati-script and Devanagari counterparts. No inventorial equivalent of 𝚜𝚊-𝙳𝚎𝚟𝚊 |ष| was introduced into 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗. Of these, |𑈫| has occasionally been used outside of 𝚐𝚞-𝙺𝚑𝚘𝚓 with slightly different phonological values. For instance, in some twentieth-century Kutchi-Khojki (𝚔𝚏𝚛-𝙺𝚑𝚘𝚓) and Urdu-Khojki (𝚞𝚛-𝙺𝚑𝚘𝚓) works, |𑈫| is sometimes used to denote [ɽ(ə)] (Asani, 1991, p. 62). Since the phonological inventories of Kutchi and Urdu lack a phonemic [ɭ(ə)], the graph |𑈫| can be ‘recycled’ for other uses in 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 and 𝚞𝚛-𝙺𝚑𝚘𝚓.
The 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 also included inventorial equivalents for certain 𝚊𝚛-𝙰𝚛𝚊𝚋 graphs, shown in (28):
(28)
| 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 | 𑈀𑈶 | 𑈄𑈶 | 𑈈𑈶 𑈿 | 𑈉𑈶 | 𑈊𑈶𑈶 | 𑈐𑈶 | 𑈙𑈶 | 𑈠𑈶 | 𑈩𑈶 | 𑈪𑈶 |
|---|---|---|---|---|---|---|---|---|---|---|
| IPA value | ə | e | k(ə) q(ə) | kʰ(ə) x(ə) | ɡ(ə) ɣ(ə) | d͡ʑ(ə) z(ə) | t̪(ə) | pʰ(ə) f(ə) | s(ə) ɕ(ə) | ɦ(ə) |
| 𝚊𝚛-𝙰𝚛𝚊𝚋 equivalent | ع | ع | ق | خ | غ | ظ ض ذ ز | ط | ف | (ص) ش | ح |
Of the 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 graphs listed in (28), the earliest to appear in nineteenth-century manuscripts was |𑈩𑈶|, created by augmenting |𑈩| [s(ə)] with the triple-nuqta pattern |𑈶| (Asani, 1992). As evident, the compositional inspiration behind this augmentation was the 𝚊𝚛-𝙰𝚛𝚊𝚋 graph pair of |س| and |ش| (Table 6.2). Notably, the triple-nuqta pattern |𑈶| — described by Shackle and Moir (1992, p. 38) as a “handsome superscript triple dot” diacritic — came to be conventionalised and used as a unit to augment existing rasms as needed, resulting in the appearance of |𑈐𑈶| and |𑈀𑈶| by the late nineteenth century (Asani, 1992). Again, the introduction of these augmented graphs was not based on phonological factors. Rather, they were intended purely as inventorial equivalents of their 𝚊𝚛-𝙰𝚛𝚊𝚋 counterparts, thanks to which they index ‘Arabicness’. The semiotic motivations behind using these augmented graphs is evinced by their “erratic use” (Shackle & Moir, 1992, p. 38) even when not phonologically warranted. For instance, Figure 10.1 shows the Persian-language title of Devraj’s (1904) publication, [pændi(j)ɒt e d͡ʒævɒnmæɾdi], transcribed into 𝚏𝚊-𝙺𝚑𝚘𝚓 as |𑈠𑈴𑈛𑈮𑈁𑈙𑈺 𑈐𑈶𑈨𑈬𑈤𑈦𑈛𑈮𑈺|. Here, the title features the augmented graph |𑈐𑈶|, despite there being no [z] in [d͡ʒævɒnmæɾdi]. Likewise, the body text of the work commences with the Sindhi-Kutchi benediction [əlaɦ(ᵊ) t̪o aɦaɾ(ᵊ)], transcribed into 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 as |𑈀𑈧𑈬𑈪𑈺 𑈙𑈲𑈺 𑈁𑈶𑈪𑈬𑈦|. Here, the Sindhi-Kutchi word [aɦaɾ(ᵊ)] features |𑈀𑈶|, suggesting that the word is of Arabic origin and is spelt in 𝚜𝚍-𝙰𝚛𝚊𝚋 with a corresponding |ع|. However, the word is actually of Sanskritic origin, and spelt in 𝚜𝚍-𝙰𝚛𝚊𝚋 as |آهارُ| (Sindhi Language Authority, 2021b). Again, the use of |𑈀𑈶| appears to be guided by its indexical values rather than its phonological values. Further evidence of such semiotically-motivated use of augmented graphs is seen in the 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 spellings |𑈐𑈶𑈤𑈮𑈞| [zəmin] ‘earth’ and |𑈙𑈬𑈐𑈶𑈜𑈮𑈞| [t̪ad͡ʑ(ʊd̪)d̪in] ‘Tajddin (name of an Ismaili pir)’ appearing on the same page of a Khojki primer (Moir, Shackle, & Mitha, n.d., p. 29). Here, |𑈐𑈶| is used regardless of whether the target phonological value is [z] or [d͡ʑ].
The other graphs listed in (28) emerged in subsequent years, based on the templatic precedent of |𑈩𑈶 𑈐𑈶 𑈀𑈶|. Their appearance coincided with the advent of an equivalent triple-nuqta pattern in 𝚐𝚞-𝙶𝚞𝚓𝚛, and augmented graphs based thereupon (Pandey, 2014a; 2014b). However, most of the graphs in (28) continued to be rendered homophonously with their rasmic counterparts. Thus, |𑈉𑈶 𑈊𑈶𑈶| were more likely to be pronounced [kʰ(ə) ɡ(ə)] than [x(ə) ɣ(ə)] (Asani, 1991; Khakee, 1972; Pandey, 2011b; Shackle & Moir, 1992). On occasion, two distinct graphs emerged in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 as equivalents of a particular 𝚊𝚛-𝙰𝚛𝚊𝚋 graph, as seen with |𑈈𑈶| and |𑈿| (Pandey, 2021a). Some of these augmented graphs were further adapted as abbreviations for Arabic-language benedictions, sometimes creating notional phonological ambiguity. Thus, 𝚊𝚛-𝙰𝚛𝚊𝚋 |ﷺ| ‘may Allah bless him and grant him salvation’ was sometimes rendered as 𝚊𝚛-𝙺𝚑𝚘𝚓 |𑈩𑈶𑈬| (Asani, 1992, pp. 51–52; Pandey, 2011b), despite |𑈩𑈶𑈬| also potentially denoting [ɕa].
In brief, 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 saw the introduction of several bound and free graphs primarily for inventorial equivalence with graphs in other prestige writing systems. In the context of 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 and the Nizari Ismaili community, these prestige writing systems were 𝚊𝚛-𝙰𝚛𝚊𝚋, 𝚏𝚊-𝙰𝚛𝚊𝚋, 𝚐𝚞-𝙶𝚞𝚓𝚛 and, prior to the twentieth century, 𝚜𝚊-𝙳𝚎𝚟𝚊. However, since the motivation behind creating augmented graphs was almost entirely lexical-etymological and nonphonological in nature, their presence in a 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 text is contingent on the scribe’s fastidiousness and etymological awareness.
Although 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 persisted with the numeral forms used in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍, it diverged from its predecessor in terms of punctuation. The advent of printing saw the increasing incursion of 𝚎𝚗-𝙻𝚊𝚝𝚗-inspired punctuation and word spacing practices. Still, traditional punctuation was retained for graphostylistic purposes, as seen in the ornamental use of the word separator |𑈺| in the title of Devraj (1904) (Figure 10.1).
10.3.3 Graph inventory
Table 10.2 shows a selection of Khojki phonograms sorted according to the collation order depicted in late twentieth-century publications. Also shown are their common phonological values in Sindhi-Kutchi and in Gujarati, the latter based on Mistry (1996). As described in Section 10.2, the phonological values of graphs in 𝚜𝚍-𝙺𝚑𝚘𝚓 (including 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓) and 𝚐𝚞-𝙺𝚑𝚘𝚓 differ slightly, especially when it comes to denoting φ-implosives and voiced aspirated φ-plosives (Asani, 1991, pp. 60–62). In addition, graphs — whether graphetically rasmic or complex — may be included or omitted from the collation order on an idiosyncratic basis. In general, though, augmented graphs other than |𑈩𑈶| tend not to be listed as part of the collation order. Also generally excluded are the bound graphs |𑈱 𑈳| and their free equivalents.
Sources: Bruce (2015, p. 50), Moir, Shackle and Mitha (n.d.) and Tajddin Sadik Ali (1989)
[table]
As stated at the start of this section, most twentieth-century print publications in Khojki are in 𝚐𝚞-𝙺𝚑𝚘𝚓, and feature the relevant graph-phone correspondences listed in Table 10.2. However, a notable exception to this rule is Devraj’s (1904) edition of the Pandiyat-e Javanmardi ‘Principles of Manliness’ (Figure 10.1), which features the Persian-language original and the Kutchi translation both transcribed into Khojki and presented as parallel texts in 𝚏𝚊-𝙺𝚑𝚘𝚓 and 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓. An extract from the book is shown in Figure 10.2, along with an English-language translation by Ivanow (1953). Also provided are the modern Persian pronunciation and an indicative Kutchi pronunciation of the 𝚏𝚊-𝙺𝚑𝚘𝚓 and 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 passages, respectively.

| 𝚏𝚊-𝙺𝚑𝚘𝚓 | 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 | ||||||
|---|---|---|---|---|---|---|---|
| 𑈤𑈲𑈤𑈞𑈺 | 𑈃𑈞𑈺 | 𑈪𑈩𑈙𑈈𑈰[𑈺] | 𑈤𑈲𑈤𑈞𑈺 | 𑈃𑈺 | 𑈁𑈄𑈈𑈰𑈺 | ||
| moʔmen | un | hæst ke | momɪn | u | a(ɦ)e ke | ||
| 𑈛𑈦𑈺 | 𑈪𑈦𑈺 | 𑈩𑈬𑈧𑈰𑈺 | 𑈛𑈯𑈁𑈶𑈐𑈶 | 𑈜𑈦𑈰𑈈𑈺 | 𑈨𑈦𑈪𑈰𑈐𑈬𑈺 | 𑈢𑈬𑈦𑈲𑈺 | 𑈤 |
| dæɾ | sɒle | dævɒz- | hæɾ | d̪əɾek | ʋəɾɦe d͡ʑa | ɓaɾo | mə- |
| 𑈛𑈰𑈪𑈺 | 𑈤𑈬𑈪𑈬𑈺 | 𑈁𑈶𑈤𑈬𑈧𑈺 | 𑈀𑈶𑈤 | 𑈪𑈮𑈞𑈬𑈺 | 𑈀𑈤𑈧𑈺 | 𑈩𑈬𑈦𑈲𑈺 | 𑈈𑈦𑈰[𑈺] |
| dæh | mɒh | æʔmɒl | ʔæm- | ɦina | əməl | saɾo | kəɾe |
| 𑈧𑈺 | 𑈩𑈬𑈧𑈰𑈪𑈺 𑈈𑈯𑈞𑈰𑈛𑈺 | 𑈨𑈺 | 𑈡𑈰 | 𑈞𑈰𑈺 | 𑈩𑈎𑈲𑈺 𑈢𑈲𑈧𑈰𑈺 | 𑈞𑈰𑈺 | 𑈩𑈎𑈲𑈺 𑈩𑈯 |
| æl | sɒleh konæd | væ | be | (ə)ne | sət͡ɕo ɓole | (ə)ne | sət͡ɕo sʊ- |
| 𑈪𑈈𑈺 | 𑈡𑈰𑈺 | 𑈊𑈯𑈥𑈛𑈺 | 𑈨𑈺 | 𑈘𑈰𑈺 𑈞𑈰𑈺 | 𑈩𑈎𑈬𑈂𑈩𑈰𑈺 | 𑈨𑈮𑈄𑈺 | 𑈞𑈰𑈺 |
| hæɢɢ | be | ɡujæd | væ | ɳe (ə)ne | sət͡ɕai se | ʋɪ(ɦ)e | (ə)ne |
| 𑈪𑈈𑈺 | 𑈡𑈰𑈩𑈶𑈞𑈰𑈨𑈛𑈺 | 𑈨𑈺 | 𑈪𑈿𑈺 | 𑈩𑈎𑈬𑈂𑈩𑈰𑈺 | 𑈪𑈧𑈰𑈺 | 𑈙𑈚𑈬𑈺 | 𑈃𑈞 |
| hæɢɢ | beʃenivæd | væ | (be)hæɢɢ | sət͡ɕai se | ɦəle | t̪ət̪ʰa | ʊn(ə) |
| 𑈞𑈩𑈶𑈮𑈞𑈰𑈛𑈺 | 𑈨𑈺 | 𑈪𑈿𑈺 | 𑈦𑈬𑈪𑈬𑈺 𑈦𑈭 | 𑈐𑈲𑈺 | 𑈛𑈮𑈧𑈺 | 𑈩𑈬𑈦𑈲𑈺 | 𑈪𑈲𑈄𑈺 𑈥𑈬 |
| neʃinæd | væ | (be)hæɢɢ | ɾɒh ɾæ- | d͡ʑo | d̪ɪl | saɾo | ɦoe ja- |
| 𑈨𑈛𑈺 | 𑈃𑈞𑈺 | 𑈛𑈭𑈧𑈩𑈶𑈺 | 𑈩𑈬𑈧𑈰𑈺 | 𑈞𑈰𑈺 | 𑈩𑈎𑈲𑈺 | 𑈪𑈲𑈄 | 𑈺𑈹૪𑈹𑈺 |
| væd | un | deleʃ | sɒleh | ni | sət͡ɕo | ɦoe | ‖4‖ |
| 𑈡𑈬𑈩𑈶𑈛𑈺 | 𑈥𑈬𑈞𑈰𑈺 | 𑈈𑈰𑈺 | 𑈛𑈮𑈧𑈩𑈶[𑈺] | ||||
| bɒʃæd | jæʔni | ke | deleʃ | ||||
| 𑈩𑈬𑈛𑈈𑈶𑈺 | 𑈡𑈬𑈩𑈶𑈛 | 𑈺𑈹૪𑈹𑈺 | |||||
| sɒdeɢ | bɒʃæd | ‖4‖ | |||||
“The (real) believer (mu‘min) is one who […] throughout the whole year of twelve months acts properly and piously, continuously remembering the Truth (Ḥaqq). He must speak the truth, listen to the truth, must abide in truth and walk in truth. His heart must be clean, and his thoughts sincere […]”
Source: Devraj (1904, seq. 7)
In terms of lexical and grammatical authenticity, the 𝚏𝚊-𝙺𝚑𝚘𝚓 text in Devraj (1904) may deviate in places from literary Persian norms.129 In terms of graphematics, though, the 𝚏𝚊-𝙺𝚑𝚘𝚓 and 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 passages in Figure 10.2 are generally consistent with the 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 graph-phone correspondences listed in Table 10.2. For instance, Persian [d] and Kutchi [d̪] are both transcribed using the base |𑈛|, which, in 𝚐𝚞-𝙺𝚑𝚘𝚓, usually denotes [d̪ʱ(ə)]. However, the Gujarati loanword [d̪əɾek] ‘every’ is spelt in 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 as |𑈜𑈦𑈰𑈈|, with [d̪(ə)] denoted by 𝚐𝚞-𝙺𝚑𝚘𝚓-style |𑈜|.130 Whether this is evidence of text-internal graphematic patterning based on lexical-etymological factors, or is a one-off irregularity, can only be determined by a thorough analysis of the entire text. What can be stated with certainty is the absence of a virama or ‘ligatures’ representing φ-consonant clusters. For instance, the Persian word [hæst] ‘is’ is transcribed in 𝚏𝚊-𝙺𝚑𝚘𝚓 simply as |𑈪𑈩𑈙|, with the reader having to discern the presence of [Ø] where appropriate. The absence of virama is unsurprising, since the text was printed before Devraj’s (1910) primer in which the virama allographs |𑈵| and |◌᳐| were introduced. Also absent are bound graphs such as the tashdid |𑈷|. Thus, the 𝚏𝚊-𝙰𝚛𝚊𝚋 word |حَقّْ| [hæɢɢ] ‘truth’ is transcribed into 𝚏𝚊-𝙺𝚑𝚘𝚓 as |𑈪𑈈|, with no overt indication of phonological gemination. At the same time, the word also appears |𑈪𑈿|, where |𑈿| is the inventorial equivalent for 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 |ق| (see Example (28)). The free variation between |𑈈| and |𑈿| reiterates the latter’s status as a semiotically-motivated invention indexing ‘Arabicness’, whose presence or absence in a text has almost no phonological impact. Along similar lines, the Persian word [dævɒzdæh] ‘twelve’ appears in 𝚏𝚊-𝙺𝚑𝚘𝚓 as |𑈛𑈯𑈁𑈶𑈐𑈶𑈛𑈰𑈪|, where |𑈀𑈶| is the inventorial equivalent for 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚏𝚊-𝙰𝚛𝚊𝚋 |ع| (see Example (28)). However, the 𝚏𝚊-𝙰𝚛𝚊𝚋 spelling of the word, |دوازده|, does not feature |ع|. Again, the inclusion of |𑈀𑈶| is likely due to its connotations of Arabicness, despite the word in question being of indigenous Persian origin. The somewhat gratuitous use of augmented graphs in Khojki-based texts, even when phonologically unwarranted, offers key sociolinguistic insights on potential conditioning factors behind writing patterns among lay users.
10.4 Analysis
10.4.1 Graphematic typology
The Khojki script and the writing systems it constitutes serve as a rich fount of graphematic and sociolinguistic insight, be it within the specific domain of the Sindhi and Kutchi speech communities and graphospheres, or within the broader context of grapholinguistics in general. Probably most salient among Khojki’s contributions to the body of knowledge is in breaking down preconceived notions on supposed intrinsic connections between language and script. Just as the Arabic, Devanagari and Gurmukhi scripts were used to write languages other than Sindhi, so too was Khojki used to transcribe a variety of languages, most prominently Sindhi-Kutchi, Gujarati, Hindi-Urdu, Arabic and Persian (Asani, 1992, p. 11). In this manner, Khojki-based writing implicitly demonstrates the existential discreteness of language, script and writing system. That said, the Arabic, Devanagari and Gurmukhi scripts were originally used for other languages and only subsequently adapted to write Sindhi. In contrast, Khojki was a script originally used to write Sindhi-Kutchi, and subsequently adapted to transcribe other languages. With Khojki, therefore, the direction of evolution was from 𝚜𝚍-𝙺𝚑𝚘𝚓 and 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 towards 𝚐𝚞-𝙺𝚑𝚘𝚓, 𝚞𝚛-𝙺𝚑𝚘𝚓, 𝚊𝚛-𝙺𝚑𝚘𝚓 and 𝚏𝚊-𝙺𝚑𝚘𝚓. The ontogenetic primacy of 𝚜𝚍-𝙺𝚑𝚘𝚓 and 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 neatly explains the persistence of the label ‘Sindhi’ for Khojki-based writing, regardless of the language encoded.
Typologically, early 𝚜𝚍-𝙺𝚑𝚘𝚓 and 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 writing shared the property of phonological opaqueness with their sister writing system 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍. However, 𝚜𝚍-𝙺𝚑𝚘𝚓 and 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓 were rarely, if ever, as abjadic in nature as 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍. Not only were bound γ-vowels present in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 from an early stage, the levels of graphovocalisation also increased steadily with time. By the early twentieth century, Devraj’s additions to the 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 inventory — particularly in 𝚐𝚞-𝙺𝚑𝚘𝚓 — resulted in the writing system becoming entrenched within the abugidic-alphasyllabic typological quadrant (Figure 2.3).
10.4.2 Graph inventory
In the scholarly literature, it is not uncommon to find descriptions of Khojki-based writing as being graphematically deficient, particularly with regard to γ-vowels. For instance, ScriptSource describes Khojki-based writing thus:
There is a discrepancy as to which sounds are represented by [free] vowel letters, and which are represented by [bound] vowel diacritics. Spoken Sindhi distinguishes between long and short [phonological] vowels. However, only the short [a] and long [a:] are represented by short and long vowel letters, and only the short [i] and long [i:] are represented by short and long vowel diacritics. The other letters and diacritics are used to represent both short and long variants of their respective vowels. This is unusual among Brahmic scripts, which tend to consistently represent vowel length in writing.
In the extract above, the text in bold appears to insinuate that languages written in Brahmic or Indic scripts feature contrastive φ-vowel length as a more-or-less predictable feature. This would imply that languages like Sindhi, Punjabi, Hindi and Gujarati feature φ-vowel pairs that differ only in length or quantity. However, as described in Section 4.3.2, Sindhi’s phonology does not exhibit contrastive φ-vowel length. In fact, the absence of identifiable long-short φ-vowel pairs was precisely why the language’s φ-vowels were alternatively categorised as lax and tense. Since Hindi’s inventory of φ-vowels is near-identical to that of standard Sindhi’s, the lax-tense grouping may also be applied to Hindi (Masica, 1991, p. 111). In Gujarati, lax [ɪ ʊ] are not phonemic at all, and surface only as allophones of [i u] in certain positions (Mistry, 1996, pp. 391–392). This gives Gujarati a monophthong inventory of [ə a i u e (ɛ) o (ɔ)] (cf. Table 10.2). In fact, an overview of several modern Indo-Aryan languages shows that they do not feature phonemic φ-vowel length, and any phonetic variation in φ-vowel length can usually be predicted by phonological rules (Masica, 1991). Therefore, the presence of graphs in their writing systems for so-called long and short φ-vowels is better understood as an inventorial relic inherited from the Sanskritic paradigm. In the context of modern Indo-Aryan languages, the long-short φ-vowel dichotomy may well emerge as redundant or even inaccurate. Yet, the influence of the Sanskritic paradigm in analyses of modern Indo-Aryan languages and their writing systems remains strong, and has been succinctly summed up by Salomon (2007) thus:
[A] standard phonetic repertoire based on that of Sanskrit became a conceptual straitjacket in the application of the Brāhmī-derived scripts to languages of the NIA [New Indo-Aryan] family (cf. Masica 1991:146).
It is the “conceptual straitjacket” imposed by the Sanskritic paradigm that frequently leads scholars and laypeople alike to assume that certain modern Indo-Aryan languages necessarily possess certain vowel phonemes that differ only in length. Further, if the language is written in an Indic script, it is also assumed that the script must possess distinct graphs — both bound and free — for denoting these supposed ‘long’ and ‘short’ φ-vowels. Broadly, this phenomenon amounts to graphematic inertia as seen in 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊, where graphs from a prestige writing system are retained in a homoscriptal writing system even when redundant. What sets apart 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗, however, is the lack of homoscriptality with a prestige writing system. With Khojki, it is the mere Indic origin of the script that appears sufficient to trigger imposition of the Sanskritic “conceptual straitjacket” and motivate graphematic inertia.
A notable instance of borderline graphematic inertia is the incorporation of the 𝚊𝚛-𝙰𝚛𝚊𝚋-inspired bound graphs such as the tashdid |𑈷| and the triple nuqta element |𑈶| into 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗. On the one hand, these elements were not, strictly speaking, examples of graphematic retention in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗. Indeed, they were consciously introduced into 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗. On the other hand, these elements were essentially adopted from the 𝚊𝚛-𝙰𝚛𝚊𝚋 inventory, and employed in a manner very similar to their 𝚊𝚛-𝙰𝚛𝚊𝚋 equivalents. Any assimilation they underwent was largely restricted to typographical harmonisation with the rest of the Khojki inventory. Therefore, even if not categorisable as graphematic inertia per se, the adoption and patterns of use of these inventorial elements remain graphematically and sociolinguistically noteworthy.
The incorporation of the triple nuqta element |𑈶| into the Khojki inventory also has graphematic and sociolinguistic parallels in other writing systems. In Divehi-Thaana (𝚍𝚟-𝚃𝚑𝚊𝚊), a subsegmental triple nuqta is used to augment the rasm |ސ| [s] and create |ޝ| [ʃ]. Likewise, in Javanese-Javanese (𝚓𝚟-𝙹𝚊𝚟𝚊), a subsegmental triple nuqta called cecak telu |꦳| is employed to augment existing rasms and create inventorial equivalents for 𝚊𝚛-𝙰𝚛𝚊𝚋 graphs (Everson, 2008). Significantly, in 𝚍𝚟-𝚃𝚑𝚊𝚊 and 𝚓𝚟-𝙹𝚊𝚟𝚊 alike, the triple nuqta is used even when phonologically unwarranted. In 𝚍𝚟-𝚃𝚑𝚊𝚊, Gnanadesikan (2017b, pp. 24, 32) notes that augmented graphs are commonly used in writing personal names of Arabic origin, but less often when writing common words of Arabic origin. For the latter group, rasmic graphs tend to be preferred over the augmented ones, since the two are often pronounced identically.131 Along similar lines, in 𝚓𝚟-𝙹𝚊𝚟𝚊, graphs augmented with a cecak telu are not always phonologically distinct from their rasmic counterparts. The use of augmented graphs in these writing systems, therefore, is motivated by a desire for graphematic equivalence with a prestige writing system than by a desire for phonological transparency. Such practice mirrors the patterns of augmented graph use seen in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗. More importantly, the employment of augmented graphs chiefly to transcribe sociolinguistically salient words — such as personal names or religioculturally significant terms — reflects the pattern noticed in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗. What stands out in the use of augmented graphs in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 is its use even when etymologically unwarranted. As explained in the discussion following Example (28), the Khojki triple nuqta |𑈶| was used somewhat gratuitously by certain authors primarily for its semiotic value of ‘Arabicness’ than for graphematic disambiguation of any kind.132 It is worth exploring whether such use makes the triple nuqta a logogram. Overall, the graphematic and sociolinguistic significance of such elements and their patterns of use, together with similar instances from other writing systems, should stimulate further inquiry in the realm of contact grapholinguistics.
The topic of contact grapholinguistics brings us to the presence of |𑈈𑈵𑈩𑈶| in 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗’s inventory, which proves particularly significant for our understanding of the concept of ‘ligature’. As outlined in Sections 2.7 and 7.7.3, several Devanagari-based writing systems consider |क्ष| to be a ‘ligature’ of |क| and |ष| based on phonological equivalence and complementary distribution. This is also the case with 𝚐𝚞-𝙶𝚞𝚓𝚛 |ક્ષ|, which is considered a ‘ligature’ of |ક| and |ષ| along the same principles applicable in Devanagari-based systems. While 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗’s inventory features |𑈈𑈵𑈩𑈶|, it does not possess an equivalent of 𝚑𝚒-𝙳𝚎𝚟𝚊 |ष| or 𝚐𝚞-𝙶𝚞𝚓𝚛 |ષ|. Thus, calling 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 |𑈈𑈵𑈩𑈶| a ‘ligature’ is graphematically dubious. The existence of 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 |𑈈𑈵𑈩𑈶| without there being a co-inventorial equivalent of |ष ષ| has analogies with the existence of |ß| in modern 𝚍𝚎-𝙻𝚊𝚝𝚗. As Osterkamp and Schreiber (2021, p. 174) observe, the graph |ß| emerged as a graphetic fusion of the 𝚍𝚎-𝙻𝚊𝚝𝚗 graphs |ſ| and |s|. With time, |ſ| fell away from the 𝚍𝚎-𝙻𝚊𝚝𝚗 inventory, in the process depriving |ß| of one of its “etymographical constituents”. On this basis, Osterkamp and Schreiber recommend that |ß| in contemporary 𝚍𝚎-𝙻𝚊𝚝𝚗 be considered a “new simplex” graph. Such a recommendation also appears to hold good for 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚖𝚘𝚍𝚎𝚛𝚗 |𑈈𑈵𑈩𑈶|. Moreover, this conclusion aligns with the argument (§2.7) that forms such as |क्ष ક્ષ 𑈈𑈵𑈩𑈶| might be better understood as graphetically rasmic — namely ‘simplex’ — in nature.
10.4.3 Graphematics and orthography
As explained in Section 10.4.1, Khojki shares with Arabic, Devanagari, Gurmukhi and the Landa-based inventories the status of having been used to write multiple languages. Each of these instantiations of Khojki also constitutes a distinct writing system (§2.3). That said, Khojki’s graph inventory seems to have been used for a variety of Indo-Aryan languages with only minimal modifications to its graph-phone correspondences. The most salient distinctions in this regard concern the phonological values of |𑈋 𑈑 𑈜 𑈢| in Sindhi-Kutchi on the one hand and Gujarati and Hindi-Urdu on the other (Table 10.2). This aligns with a similar phenomenon observed among the Devanagari and Gurmukhi-based writing systems and analysed in their respective previous chapters.
The low levels of graphematic rejigging observed between the various homoscriptal writing systems in question appears to have lessons for our understanding of when an orthography — namely the orthographic module — comes into play. On analysing the writing system pairs of 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙳𝚎𝚟𝚊, 𝚙𝚊-𝙶𝚞𝚛𝚞 and 𝚜𝚍-𝙶𝚞𝚛𝚞, and 𝚜𝚍-𝙺𝚑𝚘𝚓 (or 𝚔𝚏𝚛-𝙺𝚑𝚘𝚓) and 𝚐𝚞-𝙺𝚑𝚘𝚓, it emerges that a language’s writing system may be applied to another language with minimal changes if the two languages in question share very similar phonologies. Put differently, the greater the phonologies of two languages, the lesser the need to individually customise their (homoscriptal) writing systems. Since the Indo-Aryan languages in focus here — Sindhi, Kutchi, Punjabi, Gujarati and Hindi-Urdu — exhibit a large degree of phonological overlap (§4.3), they lend themselves well to being written in a reasonably transparent manner using each other’s graph inventories and graphematic rules. In short, phonological similarity between languages allows for a ‘one-size-fits-all’ graphematic module. Further, if the module in question is highly transparent and tends towards the biunique end of the spectrum, the scope and salience of the orthographic module may be diminished even further.
10.4.4 Sociolinguistics
This chapter began with a comparison between Khojki and its Landa cousin, Gurmukhi, and how their historical-sociolinguistic journeys bore several significant resemblances. Where the two differ starkly is in their continued use into the present day and, by implication, their role as part of a high-status or H writing system. In the twenty-first century, Gurmukhi, in its avatar of 𝚙𝚊-𝙶𝚞𝚛𝚞, continues to be religioculturally prestigious for the Sikh community. It has also taken on sociopolitical importance as the officially recognised writing system for the Punjabi language in India. Thus, contemporary 𝚙𝚊-𝙶𝚞𝚛𝚞 can safely be dubbed an H writing system. Although Khojki — in any of its various instantiations — remains historically and culturally prized within the Nizari Ismaili community, it is presently devoid of any economic or political weight. In short, the religiocultural import of Khojki-based writing has proven insufficient in elevating it to, and maintaining it at, the H level.
The reasons for Khojki-based writing failing to achieve or retain H status become evident when one examines its user-oriented and use-oriented distribution (§5.1.6). In terms of user base, Khojki as a recognisable graphetic entity was more or less restricted to the Nizari Ismaili community. As regards context of use, the employment of 𝚖𝚞𝚕-𝙺𝚑𝚘𝚓-𝚡-𝚝𝚛𝚊𝚍 to record much liturgical material ensured the script’s continuity for several centuries. Over the nineteenth century, though, the emergence of Gujarati as a socioeconomically prominent language among the Ismaili community incentivised language shift towards spoken Gujarati. Notwithstanding the shift in language, Khojki as a script persisted for a while longer in the community in the form of 𝚐𝚞-𝙺𝚑𝚘𝚓, thanks to the enterprise of Devraj and his contemporaries at the turn of the twentieth century. Despite their efforts, the socioeconomic rationality of harnessing the already-predominant 𝚐𝚞-𝙶𝚞𝚓𝚛 appears to have stymied the establishment of a lasting print culture in 𝚐𝚞-𝙺𝚑𝚘𝚓. In theory, the existence and persistence of a strong identitarian or semiotic association between the Khojki script and the Ismaili community could have acted as a bulwark against socioeconomic pressures. However, the religiocultural prestige of the Arabic language and its associated script among Muslims worldwide precluded Khojki’s ascendance to a comparable status among Ismailis. These factors, coupled with Partition and the resultant dispersal of the Ismaili community across Pakistan, India and the worldwide diaspora, resulted in Khojki-based writing becoming dormant in the latter half of the twentieth century (§5.3). In short, the lack of sufficient incentive — socioeconomic, liturgical or identitarian — hindered a Khojki-based writing system from prevailing within the community. While Khojki remains historically valued, it is nevertheless bereft of socioeconomic utility in present times. In terms of sociolinguistic fate, therefore, Khojki differs from its cousin Gurmukhi, while strongly resembling its sister Khudawadi.
11 Braille
In the world of sighted people, Braille-based writing has long existed on the epistemological margins. Around the world, most sighted people with a high-school education would have heard of Braille. Yet, very few of this cohort would know much about how Braille-based writing actually works. Unfortunately, the epistemological marginalisation of Braille-based writing also holds true for grapholinguistic endeavours, despite the vast potential it carries to inform our understanding of writing systems. Although the invention of Braille has been hailed as the “first effective digitization of writing” (Daniels, 1996c, p. 886), such writing remains chronically understudied and remains an outlier in graphematic and sociolinguistic investigations.
The frequent exclusion of Braille-based writing systems from grapholinguistic studies is likely an unfortunate fallout of its intended mode of decoding through the tactile mode (see Table 2.1). In Braille-related contexts, writing that is primarily meant to be tactually decoded or touch-read is contrasted with writing designed to be sight-read. The latter is conventionally termed inkprint writing, even if not printed as such (e.g., on electronic screens). Scholarship on Braille-based writing systems has tended to group them separately from inkprint systems. In certain contexts, the distinction may be warranted. For instance, Bunčić (2016e, pp. 100–101) excludes Braille from his study on biscriptal languages, grouping it instead with Morse Code as “technical alternative scripts for use with a different medium”. According to Bunčić, if Braille-based writing systems were to be considered equivalent to inkprint ones, every language with a Braille-based system would qualify as bi- or multiscriptal. This would render the phenomenon of bi- or multiscriptality “too universal” and, consequently, unremarkable. Bunčić’s argument that tactile or nonvisual writing systems are graphematically and/or sociolinguistically distinct from inkprint ones is conceptually justified. At the same time, it also appears true that the distinctness of such systems has led to their inadvertent sidelining from grapholinguistic studies. Such sidelining has, in turn, meant losing out on the insights nonvisual writing systems have to offer.
Against this background, Meletis (2020, p. 32 footnote 35) argues that Braille-based writing meets the definition of glottography and, therefore, should be regarded as such. In the context of this book, the topic of Sindhi-Braille (𝚜𝚍-𝙱𝚛𝚊𝚒) presents a dilemma for the researcher. On the one hand, the paucity of information on this writing system hinders a thoroughgoing analysis. On the other hand, ignoring 𝚜𝚍-𝙱𝚛𝚊𝚒 altogether would make one guilty of perpetuating the academic neglect of Braille-based writing. Hence, this brief chapter on 𝚜𝚍-𝙱𝚛𝚊𝚒 has been included in the book, primarily to draw attention to and spur interest in this overlooked field of study. In any event, as Section 11.5 will evince, even the preliminary findings that emerge from this chapter can inform and push the boundaries of our understanding of writing systems. Moreover, the history and development of Braille, not just in South Asia but globally, features two prominent personalities of Sindhi background, one sighted and one Blind. This historical connection further justifies the need and significance of the present chapter.
11.1 Early use
The eponymous Braille script was invented by Frenchman Louis Braille (1809–1852), who lost his sight in early childhood. As a young adult, Louis Braille began working with an existing method of tactile glottography comprising embossed or raised graphs. With time, he developed it into the graph inventory of raised dots that currently bears his name (Ministry of Education, India, 1952, p. 1). Although Louis Braille intended for his script to be a tactile transliteration of the inkprint 𝚏𝚛-𝙻𝚊𝚝𝚗, the script went on to become a standalone system for transcribing French (𝚏𝚛-𝙱𝚛𝚊𝚒) and, eventually, other languages worldwide (Daniels, 1996c, p. 886). The initial version of Braille’s 𝚏𝚛-𝙱𝚛𝚊𝚒 graph inventory and graph-phone correspondences appeared in 1829 (Indian Central Advisory Boards of Health and Education, 1944, p. 7), followed by a revised graph inventory and the first book-length publication in 1837 (Jiménez, et al., 2009, p. 147). Over the next century, the script went on to be adopted and adapted to transcribe various languages worldwide. In the twenty-first century, Braille-based systems continue to be created and proposed for a variety of languages, such as Inuktitut, Cherokee and even Klingon (Kearney, 2012; 2014; 2019).
In South Asia, the appearance of Braille-based systems coincided with the establishment of institutions for the Blind, the first of which was set up in 1887 in Amritsar, Punjab. It was followed by several more by the turn of the century (All India Confederation of the Blind, 2009, p. 1). Initially, individual institutions began to design Braille-based systems to transcribe the dominant languages of their respective locations, particularly Tamil and Hindi-Urdu. However, these systems used distinct graph-phone correspondences, rendering publications in one system largely inaccessible to those literate in others. Towards the end of the century, Blind educator Nilkanthrai Chhatrapati designed a Braille-based system intended for use with multiple major South Asian languages (Victoria Memorial School for the Blind, 1962, p. 2). This system came to be known as Nilkanthrai’s Braille or, alternatively, as “Indian Braille” (Advani, 1922, p. 254b). In 1902, two Christian missionaries affiliated with the British and Foreign Bible Society published another Braille-based system capable of transcribing all major South Asian languages, which they called “Oriental Braille” (Knowles & Garthwaite, 1902). Oriental Braille was used for transcribing Marathi and Gujarati in certain Blind schools in Bombay, before being replaced by Nilkanthrai’s Braille (Advani, 1922, p. 257). Modified versions of Nilkanthrai’s Braille and Oriental Braille were also adopted for transcribing Kannada and Bengali, respectively (Mackenzie, 1954, p. 29). Although sharing a graph inventory, Nilkanthrai’s Braille and Oriental Braille comprised distinct graph-phone correspondences, rendering them mutually incongruous. The incompatibility of these multilingual Braille-based systems had the unintended — and ironic — outcome of hindering the creation and uptake of Braille-script literature in South Asian languages (Mackenzie, 1954, p. 29).
In 1922, Sindhi educationist and theosophist Parmanand Mewaram (PM) Advani devised yet another Braille-based system, this time for the Sindhi language, intended for use at a newly set up School of the Blind at Karachi (Advani, 1922, p. 11; 1948, p. 19; Jinarājadāsa, 1948, p. 74). Advani’s experience with designing Sindhi-Braille led him to become an advocate of a uniform Braille-based system to transcribe all major South Asian languages (Advani, 1922; Ministry of Education, India, 1952, p. 6). Discussions and debates on the issue continued at the governmental level throughout the 1920s and 1930s (Indian Bureau of Education, 1942; Ministry of Education, India, 1952). In 1942, a six-member expert committee set up by the colonial government of India, of which PM Advani was a member, drafted a Braille-based system titled “Uniform Indian Braille” (Indian Bureau of Education, 1942). Based on feedback from various regions of British India, the draft was revised throughout the 1940s. Although the graph-phone correspondences of Uniform Indian Braille were consistently applicable to South Asian languages in general, they remained distinct from the graph-phone correspondences of English-Braille (𝚎𝚗-𝙱𝚛𝚊𝚒). Furthermore, none of the members of the expert committee were Blind (Mackenzie, 1954, p. 30).
In 1943, Sir Clutha Mackenzie, a New Zealand-born Blind war veteran, was appointed as Officer on Special Duty (Blindness) by the Government of India to investigate the extent of blindness in the country and make suitable recommendations (Indian Bureau of Education, 1947, p. 9). Mackenzie’s efforts contributed to the landmark Report on Blindness in India (Indian Central Advisory Boards of Health and Education, 1944), which set the stage for much government policy and practice with regard to the Blind community in the country (All India Confederation of the Blind, 2009, p. 2; Desai, 1954, p. 23). However, Mackenzie was also of the opinion that Blind people, whether in South Asia or elsewhere, would stand to benefit the most if graph-phone correspondences in Braille-based systems worldwide were as harmonious as possible (Mackenzie, 1949a; 1949b). Given that a standard set of graph-phone correspondences for English-Braille — itself based on French-Braille — had been agreed upon in 1932 (Mackenzie, 1954, p. 23), Mackenzie’s stance implied that any Braille-based system for South Asian languages should adopt, to the extent possible, the graph-phone correspondences of 𝚎𝚗-𝙱𝚛𝚊𝚒. To address this issue, Mackenzie set up an informal committee comprising eight members of South Asian and European background, seven of whom were Blind (Advani, 1948, pp. 23–24). In 1945, Lal Advani, a Sindhi-speaking Blind member of Mackenzie’s informal committee — and unrelated to PM Advani — drafted a new Braille-based system for South Asian languages, whose graph-phone correspondences aligned largely with those of 𝚎𝚗-𝙱𝚛𝚊𝚒 (Chander, 2014, p. 369). Lal Advani’s system was eventually termed “Standard Indian Braille” and positioned as an alternative to Uniform Indian Braille. This resulted in the intriguing situation of there being two competing Braille-based writing systems in British India vying for exclusive official recognition, each conceived by an Amil Sindhi named Advani. The significant difference between the two designers was that PM Advani was sighted, while Lal Advani was Blind.
Following the drafting of Standard Indian Braille, Mackenzie’s informal committee circulated its details to Blind institutions throughout British India, as well as to the central government (Advani, 1948, pp. 23–24). Over 1946 and 1947, the government-designated expert committee behind Uniform Indian Braille reviewed the proposal for Standard Indian Braille (Indian Bureau of Education, 1947, p. 9). However, the committee ultimately reiterated their support for Uniform Indian Braille, and recommended that it be adopted in institutions for the Blind across the country (Advani, 1948, pp. 23–24; Indian Bureau of Education, 1947, p. 9; Ministry of Education, India, 1952, p. 7). Yet, the impasse persisted. In 1948, a conference of the Blind held at Bombay rejected Uniform Indian Braille, and passed the following resolution:
This Conference, therefore, urges the government to appoint a Committee of the Blind, as, after all, the blind are most directly and deeply affected by the question, to be assisted by sighted linguists and expert phoneticians to frame and adapt a Uniform Indian Braille Code [sic] based on the similarity of sounds of the signs in the International Braille Code, as that will best facilitate the education of the blind and keep them in touch with the peoples and literatures of the world.
In view of the disagreement prevailing on the matter and the impending commissioning of Braille printing presses across the country, the Joint Secretary to the government of newly independent India, Humayun Kabir, decided to refer the matter to UNESCO in 1949. Kabir requested UNESCO to explore the possibility of harmonising Braille-based writing systems worldwide and establishing a potential “world Braille” (Ministry of Education, India, 1952; Kabir, 1949; Mackenzie, 1954, pp. 9–10). In response to Kabir’s request, UNESCO appointed Clutha Mackenzie as consultant to “study the world Braille situation as it stood and to advise Unesco [sic] on Braille systems” (Mackenzie, 1954, p. 10). In 1950, Mackenzie, Lal Advani, PM Advani, linguist Suniti Kumar Chatterji and several Braille experts from around the world met at a UNESCO-sponsored conference in Paris to discuss the issue of a World Braille (“A One-World Braille”, 1950; Ministry of Education, India, 1952; Mackenzie, 1954, p. 11). Among the experts’ recommendations was that:
World Braille […] should aim, primarily, at being a complete tactile representation of the visual script of the language concerned; secondly, at maintaining the closest uniformity between that language and other languages of the same group linguistically or by virtue of using the same script; thirdly, at achieving the maximum degree of consistency with the Braille systems of the other language groups.
(Ministry of Education, India, 1952, p. 9; Mackenzie, 1954, p. 124)
In 1951, at a follow-up UNESCO conference in Beirut, Lal Advani and Chatterji consulted with experts on Sinhala and Malay (Ministry of Education, India, 1952, p. 11; Mackenzie, 1954, p. 148) and further refined Standard Indian Braille. The resultant system was named Bharati Braille and subsequently adopted by the Government of India (Chander, 2014, p. 370; Ministry of Education, India, 1952, pp. 9–10; Mackenzie, 1954, p. 112).133
At its broadest, Bharati Braille was intended to act as a Braille-based writing system for most major South Asian languages, including Sindhi (Mackenzie, 1954, pp. 112–113). Accordingly, Bharati Braille may be referred to as 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽. However, the newly independent Pakistan, which had adopted Urdu in the Arabic script as its national language, formulated an Urdu-Braille writing system based on the graph-phone correspondences of Arabic-Braille and Persian-Braille (Mackenzie, 1954, pp. 37–38, 131–134). This resulted in distinct Urdu-Braille systems emerging in Pakistan and India (Ministry of Education, India, 1952, p. 11). In terms of language-script subtags, the two systems may be designated 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙸𝙽, respectively.
The prominence of the two Advanis in the creation of Bharati Braille and, indeed, in World Braille (§11.1), led to Sindhi-Braille being well-represented in early discussions on Braille-based inventories and mappings. This is seen in the first edition of UNESCO’s World Braille Usage handbook, which makes several references to the two Advanis as well as to Sindhi-Braille graph-phone correspondences (Mackenzie, 1954). In contrast, the handbook’s second (UNESCO, 1990) and third editions (UNESCO, 2013) make no mention of Sindhi-Braille, whether in Pakistan or India. Despite the receding of Sindhi-Braille in recent years from the popular imagination, the use of 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽 remains widespread and robust in contemporary Pakistan and India, respectively. In Pakistan, the Sindhi Language Authority has been working on adapting 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 to create a standalone 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 (Sindhi Language Authority, 2017b). At the time of writing this book, a 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 graph inventory with standardised graph-phone correspondences had been prepared (Hauze, 2016c; 2016d), although further refinements remain in the pipeline (Irfan, 2021). In India, 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽 provides the basis for 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽, and comprises graphs for most, if not all, Sindhi phones (Mackenzie, 1954, pp. 112–113). Although reliable information on the prevalence of 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 remains scarce, a small but invaluable collection of 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 texts is accessible online.
11.2 Graphematic foundations
In terms of graphetic makeup, individual graphs of the Braille script are based on a matrix of dots, known as a cell. Distinct graphs or ‘letters’ are created by embossing — that is, raising — different combinations of dots within the cell (Daniels, 1996c, p. 886). Currently, the most commonly used cell configuration is a 2 × 3 matrix, referred to as six-dot Braille. Within a six-dot Braille cell, there are sixty-four different combinations or patterns in which dots can be raised. In other words, inventories based on the six-dot Braille matrix can have a maximum of sixty-four basic graphs or rasms. Rasms may be combined to form complex graphs or multigraphs. Some Braille-based systems employ an eight-dot cell comprising a 2 × 4 matrix, which allows for an inventory of 256 distinct graphs (UNESCO, 2013, p. ix). However, six-dot Braille remains predominant worldwide. The dots in a cell are numbered and referenced in a standard manner, as shown in Figure 11.1.

Source: Wikimedia Commons (https://upload.wikimedia.org/wikipedia/commons/b/bb/Braille8dotCellNumbering.svg). Copyright 2010 by DePiep. Used under CC BY-SA 3.0.
As evident from Figure 11.1, if the bottom row of an eight-dot cell is suppressed or left unembossed, it effectively becomes a six-dot cell. Thus, systemic support for eight-dot Braille implies support for six-dot Braille. Such an approach is reflected in Unicode’s encoding of the script (Unicode, 2024b, section 21.1.1).
Currently, the vast majority of Braille-based writing systems worldwide have a sinistrodextral or left-to-right (LTR) directionality, regardless of the directionality of other homolingual writing systems. For instance, 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚑𝚎-𝙷𝚎𝚋𝚛 are both dextrosinistral or right-to-left (RTL), but 𝚊𝚛-𝙱𝚛𝚊𝚒 and 𝚑𝚎-𝙱𝚛𝚊𝚒 are both LTR (Mackenzie, 1954, pp. 112–113). By extension, although 𝚏𝚊-𝙰𝚛𝚊𝚋 shares its RTL directionality with 𝚊𝚛-𝙰𝚛𝚊𝚋, 𝚏𝚊-𝙱𝚛𝚊𝚒 aligns with 𝚊𝚛-𝙰𝚛𝚊𝚋 in following an LTR directionality (Lindemann, Alipour, & Fischer, 2011, p. 575). Braille-based writing systems may also have mutually similar rules governing the graphetic and graphematic occurrence of individual rasms and graphs. These rules may differ from analogous rules in homolingual inkprint systems. For instance, in the inkprint writing systems of 𝚊𝚛-𝙰𝚛𝚊𝚋 and 𝚞𝚛-𝙰𝚛𝚊𝚋, tashdid and sukun are subsegmental in nature, and written above the γ-consonant they co-occur with. However, in 𝚊𝚛-𝙱𝚛𝚊𝚒 and 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺, the equivalents of tashdid and sukun occupy their own graphosegmental space, and are written before — that is, to the left of — the impacted γ-consonant (Mackenzie, 1954, p. 134; Online Braille Learning, 2020b). Along similar lines, inkprint writing systems based on Indic scripts usually comprise a subsegmental virama, which may be written above, below or contiguously with the impacted γ-consonant. In contrast, Bharati Braille — or 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽 — provides for a graphosegmentally distinct virama written before the impacted γ-consonant. In this regard, Braille-based systems reveal noticeable threads of commonality and contrast among themselves, as well as with their homolingual counterparts.
Braille-based systems also exhibit patterns of similarity and distinctness in the graphosociolinguistic sphere. For instance, just as Hànyǔ Pīnyīn (𝚌𝚖𝚗-𝙻𝚊𝚝𝚗-𝚙𝚒𝚗𝚢𝚒𝚗) often dispenses with tone markers (§13.2.2), so too may Mandarin-Braille (𝚌𝚖𝚗-𝙱𝚛𝚊𝚒) omit tone markers, even though dedicated graphs for indicating tone are available in the 𝚌𝚖𝚗-𝙱𝚛𝚊𝚒 inventory (Aldridge, 2007). Similarly, the convention of omitting some or all γ-vowels in 𝚊𝚛-𝙰𝚛𝚊𝚋, 𝚑𝚎-𝙷𝚎𝚋𝚛 and 𝚞𝚛-𝙰𝚛𝚊𝚋 may spill over onto 𝚊𝚛-𝙱𝚛𝚊𝚒, 𝚑𝚎-𝙱𝚛𝚊𝚒 and 𝚞𝚛-𝙱𝚛𝚊𝚒 writing, thereby increasing their opacity. That said, the omission of graphs is not always arbitrary or discretionary. In several Braille-based writing systems, the practice of omitting certain graphs has been standardised and supplemented by a list of conventional abbreviated forms. Depending on the degree of abbreviation or shorthand, and the associated complexity in decoding it, the resultant orthography is known as a contraction or grade. For a given Braille-based writing system, Grade 1 or uncontracted Braille refers to the basic or most transparent encoding within that system, which typically makes full use of the graphematic solution space available. Grades 2 and 3 of Braille involve progressively increasing amounts of abbreviations and contractions. The aim of contracted Braille is to speed to production and perception — that is, encoding and decoding of text. In previous years, employing contracted Braille also had an economic motive in reducing the size and cost of printed works (Mackenzie, 1954, p. 15). Braille-based systems differ in how many grades they comprise. For instance, German-Braille (𝚍𝚎-𝙱𝚛𝚊𝚒) features three contraction grades, whereas systems based on Bharati Braille are typically written uncontracted (UNESCO, 2013, pp. 46, 55). Certain systems may feature a Grade 1.5 (or 1½) of intermediate complexity between Grades 1 and 2 (Mackenzie, 1954, p. 42). In certain Braille-based systems, one or more grades may have fallen out of everyday use (Punani & Rawal, 2000, pp. 182–185), such as Grade 1 in 𝚍𝚎-𝙱𝚛𝚊𝚒 (UNESCO, 2013, p. 46). It should be borne in mind that grades with the same number in different Braille-based systems are not necessarily comparable in their graphematic complexity.
On occasion, the graphs of a Braille-based writing system may exhibit a one-to-one correspondence with the graphs of its homolingual inkprint counterpart. This is seen in 𝚎𝚗-𝙱𝚛𝚊𝚒 and 𝚎𝚗-𝙻𝚊𝚝𝚗. Accordingly, Grade 1 𝚎𝚗-𝙱𝚛𝚊𝚒 may effectively be considered a transliteration of 𝚎𝚗-𝙻𝚊𝚝𝚗. The Grade 1 or uncontracted version of a Braille-based system may also share a graphematic typology with its homolingual inkprint counterpart, as evinced by Grade 1 𝚎𝚗-𝙱𝚛𝚊𝚒 and 𝚎𝚗-𝙻𝚊𝚝𝚗 both being alphabetic in nature. In South Asia, Braille-based systems bear similarities to, as well as noteworthy differences from, their homolingual inkprint counterparts. These similarities and differences are illustrated in the sections that follow using the example of Sindhi-Braille.
11.3 Sindhi-Braille in Pakistan
The Sindhi-Braille writing system as used in Pakistan (𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺) is derived from Urdu-Braille as used in the country (𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺). As a result, the two systems share several graphematic properties, including being written left-to-right (Online Braille Learning, 2020a). Where the systems differ is in certain graph-phone correspondences. Table 11.1 provides an overview of the graph inventory of 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 and their linguistic values, accompanied by their inventorial equivalents in 𝚜𝚍-𝙰𝚛𝚊𝚋.
Sources: Hauze (2016c; 2016d) and UNESCO (1990; 2013)
| b | ⠃ | ب | d̪ | ⠙ | د | f | ⠋ | ف | ə | ⠂ | ◌َ |
| ɓ | ⠘ | ٻ | d̪ʱ | ⠧ | ڌ | pʰ | ⠖ | ڦ | a | ⠜ | ◌ا |
| bʱ | ⠆ | ڀ | ɗ | ⠌ | ڏ | q k | ⠟ | ق | ɪ | ⠑ | ◌ِ |
| p | ⠏ | پ | ɖ ɖɾ | ⠬ | ڊ | k | ⠅ | ڪ | i | ⠑⠊ | ◌ِي |
| t̪ | ⠞ | ت | ɖʱ ɖʱɾ | ⠲ | ڍ | kʰ | ⠻ | ک | ʊ | ⠥ | ◌ُ |
| t̪ʰ | ⠳ | ٿ | z | ⠮ | ذ | ɡ | ⠛ | گ | u | ⠥⠺ | ◌ُو |
| ʈ ʈɾ | ⠪ | ٽ | ɾ | ⠗ | ر | ɠ | ⠽ | ڳ | e | ⠊ | ◌ي |
| ʈʰ | ⠕ | ٺ | ɽ | ⠻ | ڙ | ɡʱ | ⠛⠦ ⠛⠓ | ﮔﻬ | ɛ | ⠂⠊ | ◌َي |
| s | ⠹ | ث | z | ⠵ | ز | ŋ | ⠶ | ڱ | o | ⠺ | ◌و |
| d͡ʑ | ⠚ | ج | s | ⠎ | س | l | ⠇ | ل | ɔ | ⠂⠺ | ◌َو |
| ʄ | ⠰ ⠴ | ڄ | ɕ | ⠩ | ش | m | ⠍ | م | alif | ⠁ | ا |
| ɲ | ⠴ ⠰ | ڃ | s | ⠯ | ص | n ◌̃ | ⠝ | ن | hamza | ⠄ | ء ﺋ |
| d͡ʑʱ | ⠚⠦ ⠚⠓ | ﺟﻬ | z | ⠫ | ض | ɳ | ⠼ | ڻ | sukun | ⠒ | ◌ْ ◌ٛ |
| t͡ɕ | ⠉ | چ | t̪ | ⠾ | ط | ʋ | ⠺ | و | tashdid | ⠠ | ◌ّ |
| t͡ɕʰ | ⠡ | ڇ | z | ⠿ | ظ | ɦ | ⠓ | ھ | |||
| ɦ | ⠱ | ح | Ø | ⠷ | ع | j | ⠊ | ي | |||
| x | ⠭ | خ | ɣ | ⠣ | غ | ||||||
Much like their 𝚜𝚍-𝙰𝚛𝚊𝚋 counterparts, the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 alif |⠁| and hamza |⠄| function as so-called vowel-holder graphs, serving as graphematic anchors for a following γ-vowel. The distribution of |⠁ ⠄| is determined by graphematic environment. Table 11.2 shows how 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 γ-vowels combine with alif |⠁|, the γ-consonant |⠃| [b], and the invariant hamza |⠄|.
| ə | a | ɪ | i | ʊ | u | e | ɛ | o | ɔ | |
| اَ | آ | اِ | اِي | اُ | اُو | اي | اَي | او | اَو | |
| ⠁⠂ | ⠜ | ⠁⠑ | ⠁⠑⠊ | ⠁⠥ | ⠁⠥⠺ | ⠁⠊ | ⠁⠂⠊ | ⠁⠺ | ⠁⠂⠺ | |
| b | bə | ba | bɪ | bi | bʊ | bu | be | bɛ | bo | bɔ |
| ب | بَ | با | بِ | بِي | بُ | بُو | بي | بَي | بو | بَو |
| ⠃ | ⠃⠂ | ⠃⠁ | ⠃⠑ | ⠃⠑⠊ | ⠃⠥ | ⠃⠥⠺ | ⠃⠊ | ⠃⠂⠊ | ⠃⠕ | ⠃⠂⠺ |
| bə.ə | bə.a | bə.ɪ | bə.i | bə.ʊ | bə.u | bə.e | bə.ɛ | bə.o | bə.ɔ | |
| ﺑَﺌَ | بَئا | ﺑَﺌِ | بَئِي | ﺑَﺌُ | بَئُو | بَئي | بَئَي | بَئو | بَئَو | |
| ⠃⠂⠄⠂ | ⠃⠂⠄⠁ | ⠃⠂⠄⠑ | ⠃⠂⠄⠊ | ⠃⠂⠄⠥ | ⠃⠂⠄⠥⠺ | ⠃⠂⠊ | ⠃⠂⠄⠂⠊ | ⠃⠂⠕ | ⠃⠂⠄⠂⠺ |
Table 11.1 and Table 11.2 reveal that the inventory and composition of graphs in 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 closely mirrors that of 𝚜𝚍-𝙰𝚛𝚊𝚋. For instance, 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 |⠁| acts as a one-to-one equivalent of 𝚜𝚍-𝙰𝚛𝚊𝚋 alif |ا| in acting as a base for γ-vowels in word-initial position, but denoting [a] in word-medial and final position. Likewise, the use of 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 |⠜| mirrors that of 𝚜𝚍-𝙰𝚛𝚊𝚋 |آ| for denoting word-initial [a]. Furthermore, 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 denotes φ-consonant gemination with a distinct tashdid |⠠| in line with 𝚜𝚍-𝙰𝚛𝚊𝚋 practice, rather than by doubling the γ-consonant. It also comprises a distinct sukun |⠒| to denote the absence of a postconsonantal φ-vowel. Notably, 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 denotes the aspirated voiced stops [ɡʱ d͡ʑʱ] with digraphs, while denoting [ɖʱ d̪ʱ bʱ] with monographs. As a result, these 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 graphs are compositionally identical to their 𝚜𝚍-𝙰𝚛𝚊𝚋 counterparts.
Notwithstanding the above, further verification is needed to attest certain graph-phone correspondences. Of the sources consulted at the time of writing, one source maps the phones [ʄ ɲ] onto the graphs |⠰ ⠴| (Hauze, 2016c) while the other interchanges their allocations to |⠴ ⠰|, respectively (Hauze, 2016d). Confirmation is also required on the graphematic makeup of the graphs for [ɡʱ d͡ʑʱ], with one source indicating their 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 graphs as |⠛⠦ ⠚⠦| (Hauze, 2016c) and the other specifying |⠛⠓ ⠚⠓|, respectively (Hauze, 2016d). This discrepancy is directly analogous to the alternation between (left-to-right) |ﮔﻬ ﺟﻬ| and |ﮔﮭ ﺟﮭ| attested in 𝚜𝚍-𝙰𝚛𝚊𝚋 (§6.5.3), where the rasm |⠦| corresponds to 𝚜𝚍-𝙰𝚛𝚊𝚋 |ﻬ| in notionally denoting the aspiration suprasegmental [ʱ]. The answer to this question will determine the graphematic composition of the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 graphs for [ɡʱ d͡ʑʱ ɽʱ mʱ nʱ ɳʱ lʱ ʋʱ] (see Example (9)). Pending clarification on these points, all the graphs in question have been listed in Table 11.1.
The paucity of available 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 texts also means that certain graphematic and sociolinguistic observations need to be inferred from contemporary 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 use, with the assumption that they would apply largely unchanged to 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺. With this caveat in mind, 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝙿𝙺 appear to share notable graphematic and sociolinguistic properties with their inkprint Arabic-script-based writing systems. Graphematically, both pairs of systems allow for all γ-vowels to be overtly marked. Thus, the spoken utterance [kə] is represented in 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 by the sequence |⠅⠂|, where |⠅| represents [k] and |⠂| [ə]. Sociolinguistically, though, certain γ-vowels may be omitted in texts intended for proficient readers (UNESCO, 2013, p. 104), resulting in [kə] being transcribed simply as |⠅| [k]. This parallels the 𝚜𝚍-𝙰𝚛𝚊𝚋 manifestations of [kə], where the graphematically fully-specified |ڪَ| is often sociolinguistically superseded by the underspecified |ڪ|. The observations on the manifestation of γ-vowels also extend to sukun and tashdid.
Notwithstanding their similarities, 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝙿𝙺 differ from their inkprint counterparts in terms of graphetic makeup. In the Braille-based systems in question, all rasms occupy their own individual graphosegmental spaces and, hence, are of equal graphetic size. Put differently, 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 does not comprise subsegmental graphs of the kind observed in 𝚜𝚍-𝙰𝚛𝚊𝚋. Nor does 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 feature positional variants or allographs that are characteristic of Arabic-script-based writing systems (see Table 6.1). Another area of divergence between the Braille-based and Arabic-script-based systems under consideration is the graphetic linearity and temporal congruence of their graphs. Generally, graphs in 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙰𝚛𝚊𝚋-𝙿𝙺 writing occur one after the other corresponding to the sequential occurrence of their phonological counterparts. An exception to this temporal order is tashdid |⠠|, which, when written, appears before the affected γ-consonant (Mackenzie, 1954, p. 134).
Akin to 𝚎𝚗-𝙱𝚛𝚊𝚒 and other Braille-based systems worldwide, 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 has an established contracted variant or grade (Online Braille Learning, 2020d; UNESCO, 2013, pp. 103–104). Considering that 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 is still in the process of becoming established, a contracted grade of Sindhi-Braille in Pakistan is yet to emerge.
Many Braille-based inventories worldwide create numeral logograms by prefixing phonograms with an invariant ‘number marker’, often |⠼|. Punctuation graphs, too, follow similar patterns across major Braille-based writing systems (UNESCO, 1990; 2013). An overview of numeral and punctuation logograms as used in 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 (Online Braille Learning, 2020c) is shown in (29), with the assumption that they would apply unchanged to 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺.
(29)
| Numerals | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|
| ⠼⠁ | ⠼⠃ | ⠼⠉ | ⠼⠙ | ⠼⠑ | ⠼⠋ | ⠼⠛ | ⠼⠓ | ⠼⠊ | ⠼⠚ | |
| Punctuation | . | , | ? | ! | ; | : | – | ( ) | “ | ” |
| ⠲ | ⠂ | ⠦ | ⠖ | ⠆ | ⠒ | ⠤ | ⠶⠀⠶ | ⠦ | ⠴ |
Comparing the logograms in (29) with the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 phonograms in Table 11.1, it emerges that there is some room for confusion between the two. For instance, the numeral multigraph |⠼⠑| ‘5’ is graphetically identical to the phonographic sequence |⠼⠑| [ɳɪ]. While homography of this kind puts the onus on the reader to appropriately decode it in context, it is also comparable to the polyvalency of phonograms such as 𝚜𝚍-𝙰𝚛𝚊𝚋 |ن| (§6.5). There is also internal polyvalency among the logograms in (29), as in |⠦| being used as a question mark as well as an open quotation mark. This may be likened to the use of 𝚎𝚗-𝙻𝚊𝚝𝚗 |.| as a full stop, abbreviation marker and decimal separator.
Going by the precedent set by 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 (Online Braille Learning, 2020a), it is conceivable that the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 collation order would be identical or near-identical to that of 𝚜𝚍-𝙰𝚛𝚊𝚋.
11.4 Sindhi-Braille in India
In India, the Sindhi-Braille writing system (𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽) is based on Bharati Braille (𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽). Accordingly, 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 inherits its graphematic properties from Bharati Braille, including sinistrodextrality, linearity, uniformly-sized graphs and an overall dearth of allographs. In fact, these properties connect 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽 with 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺, while simultaneously distinguishing it from the graphe(ma)tically complex Indic-script-based writing systems (Sproat, 2010a, pp. 186–187).
Notwithstanding these differences, 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽 retains notable structural likenesses to Indic-script-based systems. Fundamental among them is the abugidic framework of 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽, in that a so-called γ-consonant maps onto a φ-[CV₀] sequence, with φ-[V₀] denoting the default or inherent φ-vowel (IIT Madras, 2020a; 2020b; 2020c; Mackenzie, 1954, p. 134). Thus, in the Hindi, Urdu, Marathi and Sindhi subvariants of Bharati Braille, the graph |⠅| has the phonological value [kə], with [ə] considered inherent to the graph. Table 11.3 provides an overview of the graph inventory and graphematic values of 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽, accompanied by equivalents in 𝚜𝚍-𝙳𝚎𝚟𝚊.
Sources: IIT Madras (2020a; 2020b; 2020c), Mackenzie (1954, pp. 112–113) and UNESCO (1990, pp. 39–40)
| k(ə) | ⠅ | क | t̪(ə) | ⠞ | त | ɕ(ə) | ⠩ | श | ə | ⠁ | अ |
| kʰ(ə) | ⠨ | ख | t̪ʰ(ə) | ⠹ | थ | ɕ(ə) | ⠯ | ष | a | ⠜ | ◌ा आ |
| ɡ(ə) | ⠛ | ग | d̪(ə) | ⠙ | द | s(ə) | ⠎ | स | i | ⠊ | ◌ि इ |
| ɡʱ(ə) | ⠣ | घ | d̪ʱ(ə) | ⠮ | ध | ɦ(ə) | ⠓ | ह | i | ⠔ | ◌ी ई |
| ŋ(ə) | ⠬ | ङ | n(ə) n̪(ə) | ⠝ | न | ɽ(ə) | ⠻ | ड़ | ʊ | ⠥ | ◌ु उ |
| t͡ɕ(ə) | ⠉ | च | p(ə) | ⠏ | प | ɽʱ(ə) | ⠐⠻ | ढ़ | u | ⠳ | ◌ू ऊ |
| t͡ɕʰ(ə) | ⠡ | छ | pʰ(ə) | ⠖ | फ | ɠ(ə) | ⠐⠛ | ॻ | e | ⠑ | ◌े ए |
| d͡ʑ(ə) | ⠚ | ज | b(ə) | ⠃ | ब | ʄ(ə) | ⠐⠚ | ॼ | ɛ | ⠌ | ◌ै ऐ |
| d͡ʑʱ(ə) | ⠴ | झ | bʱ(ə) | ⠘ | भ | ɗ(ə) | ⠐⠫ | ॾ | o | ⠕ | ◌ो ओ |
| ɲ(ə) | ⠒ | ञ | m(ə) | ⠍ | म | ɓ(ə) | ⠐⠃ | ॿ | ɔ | ⠪ | ◌ौ औ |
| ʈ(ə) ʈɾ(ə) | ⠾ | ट | j(ə) | ⠽ | य | x(ə) | ⠭ | ख़ | anusvara | ⠰ | ◌ं |
| ʈʰ(ə) | ⠺ | ठ | ɾ(ə) | ⠗ | र | ɣ(ə) | ⠐⠣ | ग़ | virama | ⠈ | ◌् |
| ɖ(ə) ɖɾ(ə) | ⠫ | ड | l(ə) | ⠇ | ल | z(ə) | ⠵ | ज़ | ɾɪ | ⠐⠗ | ◌ृ ऋ |
| ɖʱ(ə) ɖʱɾ(ə) | ⠿ | ढ | ʋ(ə) | ⠧ | व | f(ə) | ⠋ | फ़ | kɕ(ə) | ⠟ | क्ष |
| ɳ(ə) ɽ̃(ə) | ⠼ | ण | ɡj(ə) | ⠱ | ज्ञ | ||||||
Apart from the presence of an inherent φ-vowel in every γ-consonant, Table 11.3 reveals several other Indic-system elements in the graphematic structure of 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽. These include an anusvara that indicates the nasalisation suprasegmental |◌̃| of a φ-vowel, or the nasal component of a homorganic nasal-oral φ-consonant cluster. Thus, the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 anusvara corresponds directly to its 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝚂𝚒𝚗𝚍 counterparts, and less directly to 𝚜𝚍-𝙶𝚞𝚛𝚞 bindi and tippi. Notably, the relationship of the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 anusvara |⠰| to 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 |⠝| [n ◌̃] is near-equivalent to the relationship between the 𝚜𝚍-𝙳𝚎𝚟𝚊 anusvara |ं| and 𝚜𝚍-𝙰𝚛𝚊𝚋 |ن| [n ◌̃]. Also present in 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 is a virama, |⠈|, which, when juxtaposed with a γ-consonant, indicates the absence of the inherent [ə] (IIT Madras, 2020a; 2020b; 2020c; Sproat, 2010a, p. 186). The virama in 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 is written before the impacted γ-consonant, much like the tashdid in 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺. However, and as with other abugidas, the inherent φ-vowel in a γ-consonant may also be implicitly suppressed in certain graphematic environments — say, when the γ-consonant is followed by a γ-vowel.
Table 11.3 also reveals how the modifier |⠐| is juxtaposed with other graphs to create new, complex graphs. This makes |⠐| functionally analogous to the nuqta in 𝚜𝚍-𝙳𝚎𝚟𝚊, 𝚜𝚍-𝙶𝚞𝚛𝚞, 𝚜𝚍-𝚂𝚒𝚗𝚍 and 𝚜𝚍-𝙺𝚑𝚘𝚓. Graphetically, though, the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 nuqta |⠐| differs from its inkprint counterparts in not occupying its own segmental space. Moreover, the compositionality of graphs formed using the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 nuqta |⠐| may be distinct from the compositionality of phonological equivalents in other writing systems. For instance, |⠐| is prefixed to |⠻| [ɽ(ə)] to create the complex graph |⠐⠻| [ɽʱ(ə)], which is a process of graphetic augmentation not seen in any of the other writing systems previously evaluated. Along similar lines, the γ-plosives |⠛ ⠚ ⠫ ⠃| [ɡ(ə) d͡ʑ(ə) ɖ(ə) b(ə)] are prefixed with the nuqta to form the γ-implosives |⠐⠛ ⠐⠚ ⠐⠫ ⠐⠃| [ɠ(ə) ʄ(ə) ɗ(ə) ɓ(ə)] (Mackenzie, 1954, p. 113). This process does not have an exact parallel in other writing systems. Also compositionally unique is the linking of nuqta with |⠣| [ɡʱ(ə)] to form |⠐⠣| [ɣ(ə)] (IIT Madras, 2020a; UNESCO, 1990, pp. 39–40). The φ-[CV₀] sequences [x(ə) z(ə) f(ə)] may be represented by the standalone graphs |⠭ ⠵ ⠋|, respectively (IIT Madras, 2020a; UNESCO, 1990, pp. 39–40).134 Alternatively, and in line with 𝚜𝚍-𝙳𝚎𝚟𝚊 practice, [x(ə) z(ə) f(ə)] may be left graphematically undistinguished from [kʰ(ə) d͡ʑ(ə) pʰ(ə)] and transcribed with the graphs for the latter. A standalone graph for canonical [q(ə)] is not attested. The graph |⠟| [q] from 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 is used in 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 for [kɕ(ə)] instead.135
Where 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 diverge from their Braille-based counterparts in Pakistan as well as from other writing systems based on Indic scripts is in the representation of φ-vowels. Unlike any of the writing systems described so far in this book, 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 do not possess free and bound vowel allographs in complementary distribution. Instead, they employ a single invariant set of γ-vowels in all graphematic positions — postconsonantal or otherwise. Table 11.4 provides an overview of how 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽’s γ-vowels manifest in isolation and when following γ-consonants, with equivalents in 𝚜𝚍-𝙳𝚎𝚟𝚊 provided for comparison. The table also illustrates how two consecutive φ-vowels are shown in writing.
| ə | a | ɪ | i | ʊ | u | e | ɛ | o | ɔ | |
| अ | आ | इ | ई | उ | ऊ | ए | ऐ | ओ | औ | |
| ⠁ | ⠜ | ⠊ | ⠔ | ⠥ | ⠳ | ⠑ | ⠌ | ⠕ | ⠪ | |
| b | bə | ba | bɪ | bi | bʊ | bu | be | bɛ | bo | bɔ |
| ब्◌ ब् | ब | बा | बि | बी | बु | बू | बे | बै | बो | बौ |
| ⠈⠃ | ⠃ | ⠃⠜ | ⠃⠊ | ⠃⠔ | ⠃⠥ | ⠃⠳ | ⠃⠑ | ⠃⠌ | ⠃⠕ | ⠃⠪ |
| bə.ə | bə.a | bə.ɪ | bə.i | bə.ʊ | bə.u | bə.e | bə.ɛ | bə.o | bə.ɔ | |
| बअ | बआ | बइ | बई | बउ | बऊ | बए | बऐ | बओ | बऔ | |
| ⠃⠁⠁ | ⠃⠁⠜ | ⠃⠁⠊ | ⠃⠁⠔ | ⠃⠁⠥ | ⠃⠁⠳ | ⠃⠁⠑ | ⠃⠁⠌ | ⠃⠁⠕ | ⠃⠁⠪ |
Numerals and punctuation in 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 are near-identical to those in 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 (see Example (29)). Regarding contracted grades, the latest edition of the World Braille Usage handbook (UNESCO, 2013, p. 55) reports that contractions have been prepared for certain Braille-based writing systems in India, but are not widely used. Since the handbook makes no mention of Sindhi-Braille, it appears safe to assume that no contracted grades of 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 are in widespread use.
Although texts in 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 proved hard to come by when researching this chapter, Lachman Hardwani’s Tukaram ji Jivani ‘A Biography of Tukaram’ (Hardwani & Tole, 2007) represented a welcome exception.136 This work is based on the author’s homonymous 𝚜𝚍-𝙳𝚎𝚟𝚊 biography on the life of seventeenth-century Bhakti mystic and Marathi-language poet Tukaram (Hardwani, 2007), and is a notable instance of a substantial twenty-first century composition in 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽. In theory, the work may be considered a transliteration of the 𝚜𝚍-𝙳𝚎𝚟𝚊 original into 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽, effectively making them parallel texts that enable comparison. In practice, though, the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 text does not make full use of the graph inventory listed in Table 11.3. In fact, the graph subset employed appears to be that of Marathi-Braille (𝚖𝚛-𝙱𝚛𝚊𝚒), likely conditioned by linguistic context and author preference.
Since the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 text only makes use of the graphematic provisions applicable to 𝚖𝚛-𝙱𝚛𝚊𝚒, certain Sindhi-specific phonological features remain unrepresented. On occasion, this causes the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 text to diverge from its 𝚜𝚍-𝙳𝚎𝚟𝚊 parallel text (Hardwani, 2007), as shown in Example (30). For instance, the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 text does not graphematically distinguish φ-implosives from their φ-plosive counterparts, and uses the graphs |⠛ ⠚ ⠫ ⠃| for both ((30) a–d). Also undifferentiated are Sindhi [z(ə) ɽ(ə)] from [d͡ʑ(ə) ɖ(ə)], with both sets being written identically as |⠚ ⠫|, respectively ((30) e–f). This likely stems from the fact that, in Marathi phonology, [z ɽ] exist only as allophones of [d͡ʑ ɖ]. Where relevant, the illustrative examples in (30) are accompanied by theoretical 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 spellings based on Mackenzie (1954, pp. 112–113) to enable comparison. In contrast, the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 text clearly exhibits graphematic features that are well-established in 𝚖𝚛-𝙱𝚛𝚊𝚒, such as the anusvara |⠰| ((30) f–g) and the graphs |⠬ ⠒ ⠐⠗ ⠩| [ŋ(ə) ɲ(ə) ɾɪ ɕ(ə)] ((30) h–j). Rather conveniently, the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 text also contains a typographical error ((30) k) that neatly demonstrates 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽’s graphotactic rules on how to represent two consecutive φ-vowels.
(30)
| 𝚜𝚍-𝙱𝚛𝚊𝚒 (Hardwani & Tole, 2007) | 𝚜𝚍-𝙱𝚛𝚊𝚒 (Mackenzie, 1954, pp. 112–113) | 𝚜𝚍-𝙱𝚛𝚊𝚒 (Hardwani, 2007) | IPA | Gloss | |
|---|---|---|---|---|---|
| ⠘⠛⠧⠜⠝ | ⠘⠐⠛⠧⠜⠝ | भॻवान | [bʱəɠᵊʋanᵊ] | ‘god, lord (oblique)’ | |
| ⠁⠚⠥ | ⠁⠐⠚⠥ | अॼु | [əʄᶷ] | ‘today’ | |
| ⠫⠊⠝⠕ | ⠐⠫⠊⠝⠕ | ॾिनो | [ɗɪno] | ‘gave’ | |
| ⠃⠇⠥ | ⠐⠃⠇⠥ | ॿलु | [ɓəlᶷ] | ‘strength’ | |
| ⠚⠔⠇⠢ | ⠵⠔⠇⠢ | ज़िले | [zɪle] | ‘district (oblique)’ | |
| ⠅⠰⠙⠫ | ⠅⠰⠙⠻ | कंदड़ | [kən̪d̪əɽᵊ] | ‘doing’ | |
| ⠚⠰⠓⠊⠰⠚⠢ | जंहिंजे | [d͡ʑɛ̃ɦᶦ̃d͡ʑe] | ‘whose (correlative)’ | ||
| ⠘⠜⠬⠢ | भाङे | [bʱaŋe] | ‘part (oblique)’ | ||
| ⠧⠒⠢ | वञे | [ʋəɲe] | ‘goes (3SG)’ | ||
| ⠈⠩⠗⠢⠈⠯⠺⠀ |
श्रेष्ठ संस्कृती-पुरुषु | [ɕɾeɕʈʰᵊ sənskᶦɾɪt̪i pʊɾʊɕᶷ] | ‘man of ideal values’ | ||
| ⠉⠊⠚⠑ | ⠉⠁⠊⠚⠑ | चइजे | [t͡ɕəɪd͡ʑe] | ‘one may say’ | |
As was the case with 𝚜𝚍-𝚂𝚒𝚗𝚍 and 𝚜𝚍-𝙶𝚞𝚛𝚞, the difficulty in accessing written material has prevented a more thorough scrutiny of graphematic practices in 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽. Despite this limitation, the preliminary analysis of Sindhi-Braille systems provided in this chapter provides us with substantial food for thought on advancing and refining our understanding of several graphetic, typological, orthographic and sociolinguistic concepts. These outcomes reiterate the indispensability of including Braille-based writing systems in grapholinguistic endeavours.
11.5 Analysis
Graphematic typology
Since 𝚞𝚛-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙰𝚛𝚊𝚋 serve as templates for 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺, the graphematic commonalities between them are palpable. For instance, just as the former pair features of free and bound γ-vowels in complementary distribution, so too does the latter pair. To be precise, 𝚞𝚛-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙰𝚛𝚊𝚋’s usage of alif |ا| as a base for free γ-vowels is mirrored in 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺’s requirement for all free γ-vowels to be based on alif |⠁|. Likewise, bound γ-vowels in all these systems are formed by replacing alif with a γ-consonant or other suitable base. Indeed, if the questions underlying Figure 2.3 — of which postconsonantal φ-vowels can be graphematically represented, and how — were to be asked of 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺, they would emerge as plenar alphasyllabaries. The typological sameness of 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 with 𝚞𝚛-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙰𝚛𝚊𝚋 (§6.6.1) is consistent with their graphematic analogy.
Notwithstanding the typological correlation, there remains a stark difference in how postconsonantal γ-vowels are graphetically composed in 𝚞𝚛-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙰𝚛𝚊𝚋 on the one hand, and in 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 on the other. In the former pair, some of the distinctive elements in vowel graphs are subsegmental, such as |◌َ ◌ِ ◌ُ|, canonically [ə ɪ ʊ]. In the latter pair, and when fully graphovocalised, the distinctive elements in vowel graphs always occupy their own segmental space, separately from their base. Thus, in 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺, the distinctive elements denoting [ə ɪ ʊ] are |⠂ ⠑ ⠥|, respectively (Table 11.1 & Table 11.2). Although the difference in γ-vowel compositionality should not impact on the overall status of 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 as plenar alphasyllabaries, a more granular typological framework that takes into account matters of grapho(sub)segmentality may subcategorise them distinctly from 𝚞𝚛-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙰𝚛𝚊𝚋.
Crucially, 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽 and, by extension, 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 are modelled on the graphematic structure of Indic writing systems, particularly the abugidic principle of an inherent φ-vowel in every canonical γ-consonant. At the same time, 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 differ from prototypical Indic writing systems — as well as from 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 — in lacking free and bound γ-vowel allograph pairs. The invariant set of γ-vowels in 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 preclude it from being an alphasyllabary and, instead, make it an alphabet (Figure 2.3). In sum, 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 is an abugidic alphabet. Thus, despite being homolingual, homoscriptal and graphetically near-indistinguishable, 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 emerge as typologically very distinct. In this regard, their situation is analogous to that of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 in representing a case of intrasystemic typological difference.
When used in contracted form, both 𝚜𝚍-𝙱𝚛𝚊𝚒 systems may appear to have the characteristics of an abjad. However, as with 𝚜𝚍-𝙰𝚛𝚊𝚋, the discretionary sociolinguistic omission of certain features should not determine a writing system’s graphematic typology.
Graph inventory
Having been designed to be decoded primarily through the tactile route, the Braille script is distinct in its materiality (Meletis, 2020, p. 32 footnote 35). Yet, even if it were to be decoded visually, the fact that Braille’s inventory comprises graphs made up of combinations of dots in just six discrete positions throws up crucial graphetic questions. For starters, what is the nature of rasms in the Braille superset in general, and in the 𝚜𝚍-𝙱𝚛𝚊𝚒 subinventories in particular? Should the six-dot cell be considered the graphosegmental baseline? Or is there an argument for considering each of the six dot positions within a cell to be the smallest graphetic unit? If yes, does this mean that six-dot Braille essentially comprises just six rasms?
If one looks to the writing systems analysed in previous chapters for precedents, one finds that the position of a particular element relative to the graphetic baseline often determines its linguistic value, resulting in a contrast. Thus, in 𝚜𝚍-𝙳𝚎𝚟𝚊, the relative position of the dot-like element causes a contrast among |ड़ ङ डं|. Similarly, it is the number and arrangement of the dot-like element that mutually distinguishes 𝚜𝚍-𝙰𝚛𝚊𝚋 |ح خ ج ڄ ڃ چ| from one another. Against this background, a dot in 𝚜𝚍-𝙱𝚛𝚊𝚒 must be considered a subsegmental element of the six-dot cell, with different arrangements of dots over the six positions resulting in a distinct rasm.
As discussed in previous chapters, the open questions that remain on the criteria for graphemehood mean that attempting to identify graphemes in 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 at this stage would be premature. Yet, certain questions on the subject are worth raising. For instance, can graphs like 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺’s sukun |⠒| and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽’s virama |⠈| be considered to have linguistic value? Or is there an alternative analysis? Since this question applies to every writing system analysed thus far, the answer would have to be valid for all of them, too.
On the topic of graph composition, 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 exhibits lacunae that correspond to those in 𝚜𝚍-𝙰𝚛𝚊𝚋. Thus, while 𝚜𝚍-𝙰𝚛𝚊𝚋(-𝟷𝟾𝟻𝟹) |ڙ| [ɽ] has a distinct 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 equivalent in |⠻|, it is unclear whether its aspirate counterpart |ڙھ| should be written |⠻⠓| or |⠻⠦|. The answer to this question will depend on whether |ڙھ| is analysed as [ɽʱ] or [ɽɦ] and, subsequently, whether phonological aspiration should be represented by a distinct graphetic element (§6.5.3).
In terms of directionality, we see that 𝚜𝚍-𝙱𝚛𝚊𝚒 is independent of 𝚜𝚍-𝙰𝚛𝚊𝚋’s dextrosinistrality. Instead, 𝚜𝚍-𝙱𝚛𝚊𝚒’s left-to-right flow is influenced by practice in other Braille-based writing systems such as 𝚞𝚛-𝙱𝚛𝚊𝚒 and 𝚎𝚗-𝙱𝚛𝚊𝚒. Indeed, a similar phenomenon is observed in all of Sindhi’s writing systems, in that their directionality is determined by practice in other homoscriptal writing systems, and not necessarily in homolingual ones.
Graphematics and orthography
Just like Arabic, Devanagari and Khudawadi, Braille, too, is a script that has been used for Sindhi in more than one permutation or systemic variant. Moreover, as with 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 differ not just in their typology but also in their graph inventory. Hence, the question re-emerges of how this difference may be best expressed within the framework of the Modular Theory. Aside from being described as an inventorial and graphematic difference, is there an argument for considering 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 distinct orthographies?
When analysing 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 (§8.3.1), it was shown that a shorthand can only exist if an equivalent longhand exists. While 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 could not be considered a shorthand for 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍, the situation is different in the context of Braille-based systems. In the latter, preparing a Grade or contraction involves creating an abbreviated variant of a phonologically transparent system. Typologically, a Braille contraction entails a decrease in the system’s phonographic component and an increase in its logographic component. Moreover, the fact that creating a contraction involves constraining and codifying the number and nature of graphematic representations, there appears to be an argument for considering Grades within a particular Braille-based system to be orthographies of that system. Therefore, if codified Grades or contractions are introduced for either or both of 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽, a robust analytical and terminological framework would need to distinguish any superimposed contractions or ‘orthographies’ from underlying graphematic contrasts between the Pakistani and Indian systems.
Sociolinguistics
In addition to standardised and codified Grades or sets of contractions, unofficial or unstandardised contractions may be seen in several Braille-based writing system variants. Since contractions cause the system’s phonological opaqueness to increase, informal contractions involving the omission of certain phonograms is akin to the discretionary omission of subsegmental graphs in 𝚜𝚍-𝙰𝚛𝚊𝚋. To a lesser extent, unstandardised and phonographically opaque writing is also evocative of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 and 𝚜𝚍-𝙺𝚑𝚘𝚓 writing, which endured for centuries. Hence, regardless of whether a standardised shorthand is available, it appears that discretionary ‘abjadisation’ of a phonologically transparent system, or persisting with a phonologically opaque system, is not uncommon. Moreover, it is attested in a variety of sociolinguistic situations and among diverse user groups — from liturgical writing to mercantile recordkeeping, and from sighted users to members of the Blind community. In brief, discretionary abjadisation within a graphosphere of proficient reader-writers is not uncommon, and often proves popular and long-lasting thanks to the expedience and convenience it offers.
The prevalence of ‘deficient’ writing across a wide range of graphematic typologies and sociolinguistic situations also puts into perspective the preoccupation of nineteenth-century British officials with orthographic propriety. For these colonial-era figures, instituting a ‘full’ writing system for Sindhi stemmed from sociolinguistic conditioning that favoured phonologically transparent and biunique writing systems. The fact that opaque graphematic practices continue to persist despite prescriptive pressure to the contrary carries valuable lessons for grapholinguists and pedagogues alike.
The topic of pedagogy brings us to the question of whether systems like 𝚜𝚍-𝙱𝚛𝚊𝚒 should be labelled ‘auxiliary’. As outlined in Section 2.10.2, ‘auxiliary’ is a sociolinguistic label and not a graphematic one, and is susceptible to being applied in a subjective manner. Moreover, the term implies that Braille is a secondary writing system intended to get users up to speed with a primary one. Certain methods of encoding, such as English in graphical Morse Code, may justifiably be considered ‘auxiliary’, as almost nobody employs English in graphical Morse Code as a primary writing system. However, is it fair to make a similar claim in the context of Braille-based writing? As Daniels (1996b, p. 818) notes, users of Braille-based writing are often not literate in any other system. Given the recency and limited prevalence of 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽, one may assume that its users may be biliterate in 𝚞𝚛-𝙱𝚛𝚊𝚒-𝙿𝙺 and variants of 𝚖𝚞𝚕-𝙱𝚛𝚊𝚒-𝙸𝙽, respectively. Nevertheless, since all these systems are homoscriptal in Braille, Daniels’ observation stands vindicated. Hence, aside from being factually inaccurate, labelling Braille-based systems as ‘auxiliary’ may also come across as dismissive or disrespectful of its principal user group.
12 Roman
The Roman script has a long and rich history of being used to transcribe South Asian languages, dating back to the sixteenth century at least. In fact, some of the earliest books to be printed in South Asia using European-style printing presses comprised Konkani-language material transcribed in the Roman script (𝚔𝚘𝚔-𝙻𝚊𝚝𝚗) (SarDessai, 2000, pp. 15–17; Zwartjes, 2011, pp. 25–28, 53–58). Subsequent grammars of Sanskrit and Tamil authored by European Christian missionaries (Roth, 1988 [1660?]; Ziegenbalg, 1716) also made use of the Roman script, albeit as part of a transliteration or auxiliary writing system. In terms of graphematics, individual Roman-script-based systems tended to be internally consistent and predictable in their graph-phone correspondences and orthographic guidelines. However, cross-compatibility of graph-phone correspondences was not guaranteed, due to which readers effectively had to acquaint themselves with a distinct Roman-script-based writing system for every publication they read.
After the British East India Company gained its first foothold in South Asia by the mid-eighteenth century, some colonial administrators and European scholars turned their attention towards standardising the graphetic shapes of South Asian scripts, and the graph-phone correspondences of writing systems based on these scripts. Like the missionary-authored grammars before them, works of this kind were targeted at a European readership and, hence, often featured a Roman-script-based transliteration or auxiliary system as a guide. Prominent works of this kind from the early years of British colonial rule include Nathaniel Brassey Halhed’s (1778) Bengali grammar and Charles Wilkins’ commentary on the Bhagavad Gita (1785). The earliest attempt at designing a standardised Roman-script-based system specifically to transcribe South Asian languages was likely that of Welsh scholar William Jones. In a paper titled On the Orthography of Asiatick Words in Roman Letters (Jones W. , 1799; MacMahon, 1996, p. 833), Jones put forward a system based on the guiding principle of “consonants as in English, vowels as in Italian” (Gleason, 1996, p. 778). Jones’ system spawned much interest among European intellectuals on the idea of a so-called universal alphabet based on the Roman script (Burgess, 1895, p. 27; Volney, 1820). Systems proposed under this label included Lepsius’ Standard Alphabet (1855; 1863), used by Ernest Trumpp in his Sindhi-language works.
Notwithstanding scholarly interest in creating a standardised Roman-script-based writing system for South Asian languages, lay writers — including colonial administrators of the East India Company — were wont to transcribe South Asian words in the Roman script in an idiosyncratic ear-spelling loosely guided by 𝚎𝚗-𝙻𝚊𝚝𝚗 correspondences. Such practice came to be known as the ‘Sir Roger Dowler’ method, after an arbitrary eighteenth-century British transcription of the name of the last Nawab of Bengal, Siraj-ud-Daulah (Skrine, 1901, pp. 177, 205).
12.1 Early use
By the early nineteenth century, growing British interest in Sindh resulted in Sindhi names and words being transcribed according to the ‘Sir Roger Dowler’ method. Most conspicuous in this category was the 𝚎𝚗-𝙻𝚊𝚝𝚗 spelling |Scinde|, which reflected the British pronunciation /sɪnd/. Apart from being commonly used in early colonial writing, the spelling |Scinde| is also associated with a now-iconic and oft-misconstrued quote on the 1843 conquest of Sindh by British general Charles Napier (§3.3). According to a famous urban legend, Napier is supposed to have notified his superiors of his victory with a single-word despatch, Peccavi — Latin for “I have sinned”. Intended as a pun on the British pronunciation of “I have Scinde”, this mythical quote is traceable to a tongue-in-cheek article by a teenage girl (Doniger, 2014, pp. 559–562) published in the British satirical magazine Punch (no. 149 dt. 18th May 1844, p. 209). Figure 12.1 shows an extract of the article in question.

Source: Wikimedia Commons (https://commons.wikimedia.org/wiki/ File:18440518-Peccavi_Punch.jpg). Public domain. Used under CC-PD.
Along the lines of 𝚎𝚗-𝙻𝚊𝚝𝚗 |Scinde|, early instances of Sindhi-language words transcribed in the Roman script (𝚜𝚍-𝙻𝚊𝚝𝚗) also fell under the ‘Sir Roger Dowler’ category. Aptly illustrating such graphematic practices are the 𝚜𝚍-𝙻𝚊𝚝𝚗 entries in Eastwick’s Sindhi-English wordlists (1843a; 1843b). However, by the mid-nineteenth century, Jonesian-style 𝚜𝚍-𝙻𝚊𝚝𝚗 spellings became commonplace in European-authored scholarly works. For instance, the alphabet chart in Stack’s Sindhi grammar (1849a, pp. 3–8) features the names of the various graph inventories in question in Jonesian 𝚜𝚍-𝙻𝚊𝚝𝚗, with long γ-vowels and retroflex γ-consonants marked by diacritics. Lepsius’ Standard Alphabet (1855; 1863) represents a comprehensive Roman-script-based system based on Jonesian principles, which, when used to transcribe Sindhi-language words, qualifies as 𝚜𝚍-𝙻𝚊𝚝𝚗. Figure 12.2 features an extract from Trumpp (1858) showing Sindhi-language parallel text in 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙 and 𝚜𝚍-𝙻𝚊𝚝𝚗 in an early version of Lepsius’ Standard Alphabet.

Despite being graphematically comprehensive and theoretically capable of transcribing Sindhi in an accurate manner, 𝚜𝚍-𝙻𝚊𝚝𝚗 systems such as Lepsius’ were only ever used as auxiliary systems or transliterations, and never as standalone writing systems for Sindhi. It appears that, regardless of graphematic robustness, a Roman-script-based writing system for Sindhi would have been sociolinguistically out of place. This sentiment is captured by Stack (1849a) when explaining his reasons for rejecting Roman for use in his Sindhi grammar:
The Roman, too, I decided against. I never could understand the advantage of framing out of the Roman characters symbols to express sounds in Eastern tongues. Such sounds cannot be particularized without adding to the Roman letters so many marks and signs, as to render the learning of these quite as difficult as committing to memory a new character, […]
Stack’s quote is illustrative of a sociolinguistic phenomenon that can be argued to have persisted into modern times — the difficulty in accepting a European script as the primary script for certain South Asian languages. Despite being widely used as a graphematically transparent auxiliary writing system, 𝚜𝚍-𝙻𝚊𝚝𝚗 has never successfully emerged as a primary writing system for the language. It is the perceived sociolinguistic awkwardness of using 𝚜𝚍-𝙻𝚊𝚝𝚗 as a standalone writing system that makes it worthy of further investigation. Whereas the other Sindhi writing systems described thus far offer us numerous insights from a graphematic perspective, the value of𝚜𝚍-𝙻𝚊𝚝𝚗 lies primarily in its sociolinguistic lessons.
12.2 George Grierson’s system
The paradoxical use of 𝚜𝚍-𝙻𝚊𝚝𝚗 as a graphematically transparent but sociolinguistically questionable writing system for Sindhi is probably best exemplified in its use in the Linguistic Survey of India (Grierson, 1919). Like Lepsius’ Standard Alphabet, the Roman-script-based system employed in the LSI was conceived as a multilingual transcription method to be used for all the languages covered in the LSI. Its graph inventory and graph-phone correspondences reflected the recommendations of the 1895 Geneva Oriental Congress, themselves based on Lepsius’ Standard Alphabet (Burgess, 1895). In this book, the LSI’s Roman-script-based system will be assigned the language subtag 𝚖𝚞𝚕-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒, with its Sindhi-specific subvariant labelled 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒. Table 12.1 in Section 12.3 provides an overview of the graph inventory of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒.
Despite its comprehensiveness and ability to function as a standalone writing system for most of the languages covered, Grierson himself describes 𝚖𝚞𝚕-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 as a “transliteration” (Grierson, 1919, pp. ix–x). Therefore, in keeping with this book’s focus on sociolinguistically primary writing systems for Sindhi, the auxiliary system of 𝚖𝚞𝚕-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 will only be described briefly, to the extent relevant to subsequent chapters. Typologically, 𝚖𝚞𝚕-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 is an alphabet. In terms of graph inventory, it qualifies as bicameral in that every graph has two allographs — uppercase and lowercase — whose distribution is determined by graphotactic rules akin to those operating in𝚎𝚗-𝙻𝚊𝚝𝚗. However, 𝚖𝚞𝚕-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 differs from 𝚎𝚗-𝙻𝚊𝚝𝚗 in having a distinct set of graphetically diminutive allographs. To represent the reduced lax φ-vowels [ᵊ ᶦ ᶷ] and their nasalised counterparts [ᵊ̃ ᶦ̃ ᶷ̃], 𝚖𝚞𝚕-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 features the reduced γ-vowels |ᵃ ⁱ ᵘ| and |ᵃ̃ ⁱ̃ ᵘ̃|, respectively. Also used are |ᵉ ᵉ̃| as free variants of |ⁱ ⁱ̃| (Grierson, 1919, pp. 21–22). These diminutive allographs are seen in Figure 12.3, which features an extract of a text in 𝚖𝚞𝚕-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 along with an interlinear gloss in English.

Source: Grierson (1919, p. 102)
The iconicity inherent in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒’s use of diminutive graphs to indicate reduced allophones is graphematically and semiotically significant. It is also salient from a pedagogical perspective, and is taken up further in Chapter 13.
Also noteworthy in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 is the representation of the φ-implosives [ɠ ʄ ɗ ɓ] by doubling the graph for the corresponding φ-plosive — as |gg jj ḍḍ bb| respectively. Given the lack of geminated φ-consonants in Sindhi, Grierson (1919, p. 22) contends that the use of |gg jj ḍḍ bb| would not prove confusing. Moreover, the graph inventory of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 comprises equivalents for every graph in the 𝚜𝚍-𝙰𝚛𝚊𝚋 inventory, including ones that are homophonous in Sindhi. Their presence reiterates 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒’s status as a transliteration of 𝚜𝚍-𝙰𝚛𝚊𝚋 than as a standalone system.
12.3 ‘Romanized Sindhi’
Outside of scholarly and governmental publications, neither Grierson’s 𝚖𝚞𝚕-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒, nor its simplified cousin, the Hunterian system, came to be widely adopted in South Asia.137 Still, unstandardised graphematic practices loosely based on Griersonian-Hunterian graph-phone correspondences but devoid of all diacritics continued to prevail. Over the course of the twentieth century, independence from colonial rule and the establishment of sovereign nation-states in South Asia led to distinct languages and writing systems becoming official or dominant in each nation-state. As a result, the English language and the Roman script emerged as the only language and script commonly known throughout the region. Technological developments in the late twentieth and early twenty-first century led to Roman becoming ubiquitous on computers, electronic devices and the internet, further entrenching its prominence across South Asia.
In the context of Sindhi in post-Partition India and the script debate in the country (§5.3), Roman assumes a particularly significant role. Despite being absent from the debate for most of the twentieth century, 𝚜𝚍-𝙻𝚊𝚝𝚗 has been suggested as a viable alternative writing system for Sindhi in the twenty-first century. Led by members of the Sindhi community worldwide, the advocacy of 𝚜𝚍-𝙻𝚊𝚝𝚗 appears to have a pragmatic basis. Supporters suggest that the prevalence of Roman in South Asia and across the world, and its omnipresence on electronic devices, give 𝚜𝚍-𝙻𝚊𝚝𝚗 a significant edge over other writing systems of Sindhi:
The Roman script is presently the most widely used script on computers and on the internet all over the world. So those who use the Roman script for their languages have a great advantage over other people who do not use that script.
Building on the above, supporters of 𝚜𝚍-𝙻𝚊𝚝𝚗 point to growing levels of English-language literacy among Sindhi youth worldwide, along with their greater familiarity with electronic devices and the internet. On this basis, they contend that using 𝚜𝚍-𝙻𝚊𝚝𝚗 would help younger Sindhis circumvent the need to learn a specialised script to read and write their heritage language:
Learning the Arabic script (written from right to left) and learning to write the alphabets takes a lot of time which youngsters can’t give and nor are they interested. The roman format, which is transliteration in English [sic], makes the learning process easier without needing the children to learn a whole new writing system.
In the Indian context, supporters of 𝚜𝚍-𝙻𝚊𝚝𝚗 point to the system as an ideologically neutral solution to the script debate in the country:
Now if we analyse, we come to the conclusion that out of 100 [Sindhi] persons, some know the Arabic script, some Devnagiri [sic] script but practically all of us know the roman script. So why not make use of this reality?
Supporters of 𝚜𝚍-𝙻𝚊𝚝𝚗 have supplemented their advocacy with recommended graph inventories and graph-phone correspondences. Of these proposals, the most developed and prominent so far is the eponymously-named Romanized Sindhi system (Chandiramani, 2011; RomanizedSindhi.org, 2010a). Although most of the individuals behind Romanized Sindhi (𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜) are lay community activists, the group has, nevertheless, consulted with trained linguists and Sindhi-language teachers in devising the system (RomanizedSindhi.org, 2010b). The group’s core members are based in India, Singapore, the UK and the USA, and regularly hold presentations and training sessions around the world. The group’s website (RomanizedSindhi.org, 2010a) features introductory lessons in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 accompanied by audio. The website also features a sizable bilingual Sindhi-English dictionary, also with audio, with each Sindhi headword displayed in 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜. The group has also published a few e-books in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 (Sindhu Academy, 2015), including Sindhi lessons and classical poetry by well-known Sindhi poets. At the time of writing this book, the Sindhi Language Authority featured 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 on its website as an auxiliary system alongside 𝚜𝚍-𝙰𝚛𝚊𝚋 (Sindhi Language Authority, 2017a) While the SLA’s use of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 may not indicate official endorsement, it does seem like the most salient instance of the system being used outside of its circle of creators.
Graphematically, 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 shares several characteristics with homoscriptal systems worldwide. It is typologically an alphabet, and generally follows 𝚎𝚗-𝙻𝚊𝚝𝚗 rules regarding case-based allography and punctuation. A noteworthy feature of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 is its strict adherence to the ASCII character set, to ensure easy input and consistent reproduction across electronic devices.138 As a result, 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 attempts to unambiguously represent spoken Sindhi’s fifty-odd phonemes (§4.3) with the twenty-six graphs of the basic Roman script (p. 32), augmented only by those graphs available on a standard US English computer keyboard layout. This has led to 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 making extensive use of the tilde |~| and circumflex |^| as diacritics or graphetic augmentations. What is striking, though, is the placement of the augmentative elements after the base rasm, rather than above or below it. Table 12.1 provides an overview of the graph inventories and graph-phone correspondences of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜, sorted by the latter’s collation order.
| IPA | 𝚕𝚜𝚒 | 𝚛𝚜 | IPA | 𝚕𝚜𝚒 | 𝚛𝚜 | IPA | 𝚕𝚜𝚒 | 𝚛𝚜 | IPA | 𝚕𝚜𝚒 | 𝚛𝚜 |
|---|---|---|---|---|---|---|---|---|---|---|---|
b |
b | b | ɡʱ |
gh | gh | p |
p | p | ə ᵊ |
a ᵃ | a |
ɓ |
bb | b^ | ŋ |
ṅ | g~ | pʰ |
ph | ph | a |
ā | aa |
bʱ |
bh | bh | ɦ |
h ḥ | h | q k |
q | - | ɪ ᶦ |
i ᵉ | i |
t͡ɕ |
ch | ch | d͡ʑ |
j | j | ɾ |
r | r | ʊ ᶷ |
ī | ee |
t͡ɕ |
chh | chh | d͡ʑʱ |
jh | jh | ɽ |
ṛ | r^ | ʊ |
u ᵘ | u |
ɖ ɖɾ |
ḍ ḍr | d | ʄ |
jj | j^ | s |
s ṣ s̤ | s | u |
ū | oo |
d̪ |
d | d~ | ɲ |
ñ | j~ | ɕ |
sh | sh | e |
e | e |
d̪ʱ |
dh | dh~ | k |
k | k | ʈ ʈɾ |
ṭ ṭr | t | ɛ |
ai | ai |
ɖʱ ɖʱɾ |
ḍh ḍhr | dh | kʰ |
kh | kh | t̪ |
t t̤ | t~ | o |
o | o |
ɗ |
ḍḍ | d^ | x |
k͟h | khh | t̪ʰ |
th | th~ | ɔ |
au | au |
f |
f | f | l |
l | l | ʈʰ |
ṭh | th | ◌̃ |
◌̃ | ’n |
ɡ |
g | g | m |
m | m | ʋ |
w v | v | |||
Unlike 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊, 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 is largely free of inertial or relic graphs inherited from homoscriptal writing systems. Thus, graphs such as 𝚜𝚍-𝙰𝚛𝚊𝚋 |ث| or 𝚜𝚍-𝙳𝚎𝚟𝚊 |ऋ ृ ष|, which are not phonologically distinctive in modern Sindhi but are retained purely due to graphosociolinguistic pressure, do not have parallels per se in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜.
In terms of orthography, 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 features the occasional extrasystemic spelling, of which the most significant is the 𝚎𝚗-𝙻𝚊𝚝𝚗-influenced |Sindhi|. Whereas a strict, systemically consistent 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜i spelling of the name of the language is |Sindh~ee|, the ubiquity of the extrasystemic spelling |Sindhi| and its identificational significance has likely exerted sociolinguistic pressure to retain it. Other orthographic questions pending clarification in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 are those common to 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊, such as the presence and nature of φ-vowels.
Three members of the team behind Romanized Sindhi kindly agreed to be interviewed to provide details on their system, as well as their thoughts on issues surrounding Sindhi literisation. Their views are presented in Chapter 13 as part of an analysis of sociolinguistic perceptions of 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗 among Indian and diasporic Sindhis.
12.4 Analysis
Typologically, and like most Roman-script-based systems worldwide, both 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 emerge as plenar alphabets. On the one hand, they harmonise with the homolingual plenaries of 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 in explicitly denoting all φ-vowels occurring in postconsonantal position. On the other hand, 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 and𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 resemble 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 in lacking a graphetic and graphematic distinction between free and bound vowel allographs.
At the same time, the overall classification of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 as plenar alphabets should not be construed as all of their written units being graphosegmental in nature. As evident from this chapter, both inventories feature several graphosubsegmental elements, many of which border on having distinct linguistic values per se. Thus, in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒, the macron |◌̄| corresponds to the phonological suprasegmental of vowel length, subject to the disclaimers on vowel length as a contrastive feature in Sindhi phonology (§4.3.2). One may also describe the underdot |◌̣| as denoting retroflexion, which, however, is not a suprasegmental but a subsegmental bundle of phonologically distinctive features. In this regard, 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒’s |◌̄| and |◌̣| resemble in function the tone diacritics used in Hànyǔ Pīnyīn (𝚌𝚖𝚗-𝙻𝚊𝚝𝚗-𝚙𝚒𝚗𝚢𝚒𝚗; §13.2.2) and in Vietnamese-Roman (𝚟𝚒-𝙻𝚊𝚝𝚗; Osterkamp & Schreiber (2021, p. 174)) in representing a phonologically subsegmental feature. They also bear similarities with 𝚍𝚎-𝙻𝚊𝚝𝚗’s umlaut |◌̈| and the Japanese-Hiragana (𝚓𝚙-𝙷𝚒𝚛𝚊) dakuten |◌゙|, both bound graphs (Meletis, 2019, pp. 41–42). The umlaut is affixed to a free d𝚎-𝙻𝚊𝚝𝚗 graph denoting a back φ-vowel to create an augmented graph indicating the corresponding front φ-vowel. The dakuten is affixed to a kana — namely a φ-[CV] syllabogram — to indicate voicing of the underlying φ-[C]. In terms of linguistic values, the umlaut and dakuten denote the subsegmental phonological features of [+ front] and [+ voice], respectively. Further research is required to determine whether the linguistic values of the virama and tashdid in Sindhi’s other writing systems can also be justified as subsegmental in nature, based on which the graphs might consequently fall into the same category as 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒’s |◌̄| and |◌̣|.
In 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜, the graphetic elements |~ ^| are atypical of Roman-script ‘diacritics’ in not being graphosubsegmental. In this regard, these elements are comparable to the segmental 𝚜𝚍-𝙱𝚛𝚊𝚒 nuqta |⠐|. Phonologically, the𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 elements |~ ^| depart from 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒’s |◌̄| and |◌̣| in not possessing a neatly identifiable linguistic value. Alternatively, one may argue that |~ ^| have multiple linguistic values in this context, indicating everything from a dental place of articulation to an implosive manner of articulation. Determining whether the argument of ‘multiple linguistic values’ holds water and suffices for classifying |~ ^| as standalone graphs is a matter worthy of greater scrutiny.
Sociolinguistically, the rationale behind restricting 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 to ASCII-compliant symbols succinctly illustrates the power of modern technology in determining what script and graph subset should be used to write a particular language. Put differently, technology may make or break an entire writing system, thereby significantly influencing its design. The views of the Romanized Sindhi team on this issue, together with those of the wider Sindhi community, follow in the next chapter.
13 Arabic, Devanagari and Roman: Community perceptions
Although Partition in 1947 is commonly understood as having split the Sindhi speech community and graphosphere into its Pakistani and Indian branches, it also accelerated the rise of a worldwide Sindhi diaspora beyond these two countries (§3.4). The diasporic branch of the Sindhi community has generally lain low in matters of culture and language, with debate on these issues largely being restricted to Pakistan and India. In Pakistan, the Arabic script has prevailed as the undisputed script for writing Sindhi in most situations, manifesting in its contemporary avatar of 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝟷𝟾𝟻𝟹. Across the border in India, no script has emerged a clear winner in the context of graphising Sindhi. Immediately after Partition, both 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 had their share of supporters, because of which the Indian government officially approved and supported publications in both writing systems (§5.3). Since then, the prevalence of 𝚜𝚍-𝙰𝚛𝚊𝚋 has decreased noticeably in the country, but has not been offset by a corresponding increase in the adoption of 𝚜𝚍-𝙳𝚎𝚟𝚊. In the meantime, the increasing numbers of English-educated Sindhi youth in India and the diaspora, along with the advent of the internet, have triggered a rise in the informal use of Sindhi in the Roman script. Albeit limited, the presence of 𝚜𝚍-𝙻𝚊𝚝𝚗 has been significant enough to stoke and rekindle the debate on Sindhi’s writing systems (§12.3). That said, the debate has not been strong enough to permeate the politically-induced Indo-Pak cultural barrier and capture the attention of Pakistani Sindhis to any noticeable extent. Consequently, the Sindhi script debate in the twenty-first century remains largely restricted to regions outside Sindh, particularly India.
Against this background, this chapter presents the views of members of the Sindhi community in India and in the diaspora on the question of which script(s) to write their traditional language in. These views were obtained through open-ended in-depth interviews I personally conducted with community members, with the aim of “giving voice to the other” (Guest, MacQueen, & Namey, 2012, p. 13). Although the focus during the interviews was on obtaining interviewees’ opinions on using the Arabic, Devanagari and Roman scripts for Sindhi, I was conscious of needing to allow for information I might not have anticipated in my role of researcher (Guest, Namey, & Mitchell, 2013, p. 21). The open-ended nature of the questions helped safeguard against the inadvertent silencing of alternative views, and permitted them to be voiced and heard on an equal footing.
13.1 Study methodology
The interviews were guided by a qualitative approach, which is considered appropriate for “data that do not indicate ordinal values” (Nkwi, Nyamongo, & Ryan, 2001, p. 1). Put differently, a qualitative approach was especially suitable for data dealing with social patterns, perceptions, acceptance and opinions. A statistically-oriented quantitative research paradigm was considered suboptimal for shedding light on nonquantifiable parameters such as beliefs and opinions. Also validating the use of a qualitative approach was its inherent focus on “richness, depth, nuance, context, multi-dimensionality and complexity” (Mason, 2002, p. 1). Investigation of the context was imperative, as any grapholinguistic investigation focusing purely on graphematics and not on sociolinguistics would prove deficient. In other words, consideration of the “bigger social picture” (Edwards, 2009, p. 1) was key. Above all, the qualitative approach justified itself thanks to its emphasis on transcending mere descriptions and producing explanations or arguments (Mason, 2002, p. 7).
13.1.1 Interviewee profiles
The fundamental criteria for including an individual as a potential interviewee were twofold. First, the person needed to self-identify as a member of the Sindhi community. Second, they had to have lived for significant periods of time outside of Sindh, be it in India or in the worldwide diaspora. Since the focus was on linguistic and cultural affiliation, the citizenship(s) that they currently or previously held was immaterial. That said, these guiding principles were intended to be followed in spirit rather than to the letter. In addition, balances were also sought among the following interviewee cohorts:
- females and males;
- of ages below 45 years, between 45 and 65 years, and above 65 years;
- those currently living in India and outside of India;
- those who had spent their childhood in large cities and those in smaller towns, irrespective of their current location;
- those fluent in spoken Sindhi and those nonfluent in it; and
- those who could read 𝚜𝚍-𝙰𝚛𝚊𝚋 and those who could not.
In India, the initial target area was the Mumbai-Pune belt of western India where the majority of Indian Sindhis reside (§3.4). In Singapore and Australia, assistance was sought through the Singapore Sindhi Association and the Sindhi Association of Victoria, respectively.
Before commencing the fieldwork, approval for the research was obtained from the Human Research Ethics Committee (HREC) of the University of New England. Personal acquaintances who self-identified as members of the Indian Sindhi community were first approached. Commencing the research with familiar individuals allowed the interview questions and techniques to be refined, before proceeding to unacquainted people. Potential interviewees were initially contacted with a request to reply if willing to participate in the study. On receipt of their confirmation, interviewees were given a brief about the research. They were also informed that the interview would be audio-recorded, and that their data and privacy would be safeguarded in line with HREC guidelines. An appointment for a qualitative semistructured interview was then arranged at a suitable time, either in person or over video-conferencing software. Prior to the interview, explicit consent was once again obtained before proceeding. Suggestions for additional potential interviewees were sought from individuals already interviewed. These individuals were then contacted in the same manner.
A total of 50 people were interviewed, of whom 19 identified as female and 31 male. The voluntary nature of participation and limitations of time and resources meant that the desired balance between female and male interviewees could not be met. In terms of age, the youngest interviewee was 28, and the oldest 85. Based on their age, interviewees were categorised into three categories: youngest (ages 28–44), middle-aged (ages 45–64) and oldest (ages 65–85) generations. This three-generation classification was founded on a similar trifurcation adopted by Daswani and Parchani (1978) in their classic sociolinguistic study on Indian Sindhi. Of the people interviewed, 20 were of the youngest generation, 12 were middle-aged, and 18 were of the oldest generation. Among the oldest generation, 16 were born in pre-Partition Sindh. Figure 13.1 summarises the distribution of interviewees across age groups.

As mentioned earlier, the first fundamental criterion for interviewing a person was their self-identification as Sindhi. Of the 50 interviewees, 47 had parents who were both Sindhi. Two had only one Sindhi parent, but had sustained contact with the Sindhi side of their family. The remaining interviewee was a native Marathi speaker with a Sindhi spouse, but had learnt Sindhi well enough to become an amateur poet in the language.
The other fundamental criterion for interviewing a person was a substantial association with a region outside of Sindh. Of the total interviewed, sixteen were born in pre-Partition Sindh, and the remaining in the post-Partition era outside of Sindh. Of the sixteen Sindh-born interviewees, three were infants at the time of Partition, or had no recollection of schooling in Sindh. Twelve had at least some memories of acquiring elementary education in pre-Partition Sindh, while one interviewee had completed his entire schooling in Karachi before permanently migrating to India in the 1960s. Thirty-three interviewees were born and had received their entire school education outside of Sindh, the vast majority of them in various regions of independent India. Three had spent a few childhood years in Dubai, and one in Hong Kong. Two interviewees had spent some or all of their formative years in Malaysia.
I personally carried out all interviews between August 2014 and January 2015. Joint interviews were avoided where possible to prevent cross-contamination or mutual influencing of views, although this was not always possible. In all, forty-two people were interviewed one-on-one. The remaining eight people were interviewed in pairs, in four separate sessions. Three of these four pairs comprised family members, while the remaining two were colleagues. In joint interviews, every interview question was put separately to individuals, in order to ensure that each one received an opportunity to explicitly state their views. Interviews were conducted on location in India, Australia and Singapore, and over video-conferencing software (Skype). Thirty-three people were interviewed in India, ten in Australia, and four in Singapore. Four people residing in the USA and Canada were interviewed over Skype.
That said, interview location and current place of residence were not necessarily the same for several interviewees. Of the total interviewed, 30 were ordinarily resident in India and 20 in other countries, including Australia, Canada, Hong Kong, Singapore and the USA. Regardless, interviewees’ current place of residence did not necessarily indicate a childhood association with the place. Among the sixteen interviewees born in Sindh, their birthplaces ranged from large cities such as Karachi, Hyderabad and Shikarpur to smaller towns and villages in what are now the districts of Dadu, Hyderabad, Jamshoro and Khairpur. For most of them, though, their stay in Sindh was typically limited to the first few years of their life owing to Partition. As a result, 44 interviewees reported having spent most or all their childhood years in India. Of these, 25 had spent the majority of their childhood in large metropolises. These included 22 who had grown up in Bangalore, Delhi, Mumbai or Pune. In contrast, 19 interviewees had grown up in smaller Indian towns including Ulhasnagar, Gandhidham and Ajmer. Five had split their childhood between India and another country, and one had grown up entirely in Malaysia. In brief, it was common for interviewees in all generations to have complex geographical affiliations. As children, the oldest generation moved among several locations in India due to their refugee status. However, some of them eventually went on to temporarily live or permanently settle in a country other than India or Pakistan. The middle-aged generation, too, often moved cities and countries in early adulthood, but as economic migrants than as refugees. The youngest generation had been highly mobile since childhood. Indeed, several interviewees were at a loss when asked where they were from. The multiple geographical affiliations of interviewees succinctly highlight the transnationalism (Vertovec, 2009) of the Sindhi diaspora. Hence, the stated figures on geographical affiliations should only be taken as indicative.
In terms of overall education levels, at least 39 had a university degree or diploma. This affirms Khubchandani’s (1998, p. 8) observation on the Indian Sindhi community having achieved “near-universal literacy”, equally applicable to the worldwide Sindhi diaspora. The community’s high level of education also a aligns with its widely acknowledged economic success (Falzon, 2004; Markovits, 2000). The exception to this rule was the oldest interviewee, who was 85 years old at the time. He had dropped out of school in Sindh after Class 2 due to economic constraints, but had gone on to become a wealthy businessman. Most importantly, he was literate in both 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊. Those interviewees who did not specify their levels of education were all over the age of 70, and were either retired or working part-time. Figure 13.2 shows the relative levels of education among interviewees.
In terms of overall education levels, at least 39 had a university degree or diploma. This affirms Khubchandani’s (1998, p. 8) observation on the Indian Sindhi community having achieved “near-universal literacy”, equally applicable to the worldwide Sindhi diaspora. The community’s high level of education also a aligns with its widely acknowledged economic success (Falzon, 2004; Markovits, 2000). The exception to this rule was the oldest interviewee, who was 85 years old at the time. He had dropped out of school in Sindh after Class 2 due to economic constraints, but had gone on to become a wealthy businessman. Most importantly, he was literate in both 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊. Those interviewees who did not specify their levels of education were all over the age of 70, and were either retired or working part-time. Figure 13.2 shows the relative levels of education among interviewees.

Notwithstanding their high levels of education, only 19 of the 50 interviewees had received any education in the Sindhi language, either as a medium of instruction or a school subject. Of these interviewees, 17 were 65 years of age or older. This statistic is indicative of the decline in demand for Sindhi-language education in India and in the worldwide diaspora and, consequently, its lack of availability in schools. In other words, the only interviewees to have received any formal education in Sindhi were those of school-going age during the Partition era. Significantly, the two younger interviewees who had some Sindhi-medium education in India were in fact lecturers of Sindhi in universities in Mumbai and Pune, both with Master’s degrees in the language. The other 31 interviewees had received no formal or informal education in Sindhi.
In terms of self-reported language fluency, 28 of the 50 interviewees claimed to be able to thoroughly understand and speak Sindhi. Eighteen of them were of the oldest generation, nine of the middle-aged and one of the youngest. Twelve of these fluent speakers were involved in academic, literary or other Sindhi-language-related activities. For convenience, these interviewees are referred to as ‘scholars’ in this study. Nine of the scholars belonged of the oldest generation. Figure 13.3 shows the distribution of interviewees’ claimed Sindhi fluency on a scale of 1 to 5, where 1 represents bare minimum knowledge and 5 fluency.

In terms of reading abilities, 18 interviewees were able to read 𝚜𝚍-𝙰𝚛𝚊𝚋, of whom 17 were 65 years of age or older. For all of them, 𝚜𝚍-𝙰𝚛𝚊𝚋 had been a part of their formal education, either as the medium of instruction or as a language subject. All eighteen also had at least some experience of reading 𝚜𝚍-𝙳𝚎𝚟𝚊. Ten of the scholars were literate in both 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊, while the remaining two scholars were familiar only with the latter.
In terms of 𝚜𝚍-𝙳𝚎𝚟𝚊 abilities, ascertaining interviewee abilities was problematic. All but one interviewee claimed proficiency in 𝚑𝚒-𝙳𝚎𝚟𝚊, despite several admitting to being out of touch with it. However, 14 of them were not aware that Sindhi, too, was written in Devanagari. Seven were aware of the existence of 𝚜𝚍-𝙳𝚎𝚟𝚊, but had never read any. Of the 28 that had had exposure to 𝚜𝚍-𝙳𝚎𝚟𝚊, only four had received formal education in it, at least as a school subject. Seven interviewees who had not been formally educated in 𝚜𝚍-𝙳𝚎𝚟𝚊 claimed proficiency in it based on their extensive reading and writing in the system on a personal or informal level. Seventeen indicated that they had some reading experience in 𝚜𝚍-𝙳𝚎𝚟𝚊, in some cases extremely limited.
13.1.2 Interview structure
Interviews were conducted in a mix of English, Hindi and Sindhi, depending on interviewee ability and preference. Code-switching and code-mixing were inevitable and presumed, as this is common practice in urban multilingual milieus in India (Kothari, 2009, p. 33). Since the focus of the research was the content of interviewees’ statements and not the phonological or grammatical structure of their utterances, the language(s) of the interview did not impact the analysis.
Before commencing, the open-ended nature of the questions was explained to the interviewees and they were encouraged to speak at length. The open-ended nature of the interview allowed for inductive probing (Guest, MacQueen, & Namey, 2012, p. 13), namely seeking further clarification from the interviewees on their statements if required. It also allowed for the sequence of questions to be kept flexible and give the interview a better flow based on the individual’s response. Interviewees’ background and a self-evaluation of Sindhi fluency were first obtained. This was followed by information on their ability in and usage of 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊. Their opinions on the two writing systems in terms of suitability for the language were sought, along with any suggestions for resolving the script debate in India. Subsequently, their opinion on 𝚜𝚍-𝙻𝚊𝚝𝚗 was explicitly requested, along with its perceived advantages and disadvantages.
Interviewees were then shown short text passages in 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗, adapted from 𝚜𝚍-𝙰𝚛𝚊𝚋 primary school textbooks issued by the Pune-based Maharashtra State Bureau of Textbook Production and Curriculum Research. One text was retained in the original 𝚜𝚍-𝙰𝚛𝚊𝚋, the second transliterated into 𝚜𝚍-𝙳𝚎𝚟𝚊 based on Lekhwani’s (1996) conventions, and the third into 𝚜𝚍-𝙻𝚊𝚝𝚗 based on Grierson’s (1991) 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒. A list of equivalent graphs in 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 was also provided. The texts are listed in (31), together with IPA transcriptions and free translations. The translations were not shown to interviewees in order to prevent any semantic priming in their attempts to decode the texts.
(31)
- 𝚜𝚍-𝙰𝚛𝚊𝚋
مھاتما گانڌي
-
مھاتما گانڌيءَ کي راشٽرپتا ڪري مڃيو ويندو آهي. مھاتما گانڌيءَ جو جنم ۲ آڪٽوبر ۱۸۶۹ ۾ سؤراشٽر جي پوربندر ۾ ٿيو. سندس نالو موهنداس هو. پتا جو نالو ڪرمچند ۽ ماتا جو نالو پتلي ٻائي هو. سندس ماءُ ڏاڍي ڌارمڪ ويچارن جي هئي. ننڍي هوندي هو بُريءَ سنگت جو شڪار ٿيو. پر جيئن ئي پاڻ سنڀاليائين، پنھنجي پيءَ سامھون پڇتاءُ ظاهر ڪيائين. پوءِ اڳيان هلي هو آدرشي انسان بڻيو.
- (Maharashtra State Bureau of Textbook Production and Curriculum Research, 2008, p. 71)
məɦat̪(ᶦ)ma ɡan̪d̪ʱi
-
məɦat̪(ᶦ)ma ɡan̪d̪ʱiᵊ kʰe ɾaɕʈɾᵊpɪt̪a kəɾe məɲᶦjo ʋen̪d̪o aɦe. məɦat̪(ᶦ)ma ɡan̪d̪ʰiᵊ d͡ʑo d͡ʑənəmᶷ ɓĩ akʈobəɾᶷ əɾᶦɽəɦᵊ̃ sɔ ʊɳʱət̪əɾᵊ mẽ sɔɾaɕʈɾᵊ d͡ʑe poɾ(ᶦ)bən̪d̪əɾᵊ mẽ t̪ʰᶦjo. sən̪d̪ʊsᶦ nalo moɦən̪d̪asᶷ ɦo. pɪt̪a d͡ʑo nalo kəɾəmᵊt͡ɕən̪d̪ᶷ ɛ̃ mat̪a d͡ʑo nalo pʊt̪ᵊli ɓai ɦo. sən̪d̪əsᶦ maᶷ ɗaɖʱi d̪ʰaɾmɪkᶷ ʋit͡ɕaɾənᶦ d͡ʑi ɦʊi. nəɳɖʱ(ɾ)e ɦun̪d̪e ɦu bʊɾiᵊ səŋɡət̪ᵊ d͡ʑo ɕɪkaɾᶷ tʰᶦjo. pəɾᵊ d͡ʑiə̃ ĩ paɳᵊ səmbʱalᶦjaĩ, pɛ̃ɦᵋ̃d͡ʑe piᵊ samʱũ pət͡ɕʰᵊt̪aᶷ zaɦᶦɾᶷ kəjaĩ. poᶦ əɡ(ᶦ)jã ɦəli ɦu ad̪əɾ(ᶦ)ɕi ɪnsanᶷ bəɳᶦjo.
Mahatma Gandhi
- Mahatma Gandhi is considered the Father of our Nation. Mahatma Gandhi was born on 2 October 1869 in Porbandar, Saurashtra. His name was Mohandas. His father’s name was Karamchand and mother’s name was Putlibai. His mother was very religiously inclined. When young, he fell into bad company. On regaining control of himself, he expressed regret before his father. He then went on to become an ideal human being.
- 𝚜𝚍-𝙳𝚎𝚟𝚊
कसिरत
-
असां लाइ तंदुरुस्तु रहणु तमामु ज़रूरी आहे. शरीर खे तंदुरुस्तु रखण जा केतिरा ई तरीक़ा आहिनि. इन्हनि सभिनी में कसिरत तमामु सवलो उपाउ आहे. शरीर जे कंहिं बि उज़्वे हलाइण खे कसिरत चवंदा आहिनि.
हाकी, फ़ुटबालु, वालीबालु, क्रिकेट, कॿडी, डोड़ वग़ैरह रांदियूं कसिरत जा अलॻु अलॻु ज़रिया आहिनि. इन सां शरीरु मज़िबूतु थिए थो.
- (Maharashtra State Bureau of Textbook Production and Curriculum Research, 2007b, p. 57)
kəsᶦɾət̪ᵊ
-
əsã laᶦ t̪ən̪d̪ʊɾʊst̪ᶷ ɾəɦəɳᶷ t̪əmamᶷ zəɾuɾi aɦe. ɕəɾiɾᵊ kʰe t̪ən̪d̪ʊɾʊst̪ᶷ ɾəkʰəɳᵊ d͡ʑa ket̪ᶦɾa i t̪əɾika aɦɪnᶦ. ɪnʱənᶦ səbʱᶦni mẽ kəsᶦɾət̪ᵊ t̪əmamᶷ sɔlo ʊpaᶷ aɦe. ɕəɾiɾᵊ d͡ʑe kɛ̃ɦᵋ̃ bᶦ uzʋe kʰe ɦəlaɪɳᵊ kʰe kəsᶦɾət̪ᵊ t͡ɕəʋən̪d̪a aɦɪnᶦ.
ɦaki, fʊʈᵊbalᶷ, ʋalibalᶷ, kɾɪkeʈᵊ, ɖoɽᵊ ʋəɣɛɾəɦᵊ ɾan̪d̪ᶦjũ kəsᶦɾət̪ᵊ d͡ʑa ələɠᶷ ələɠᶷ zəɾɪja aɦinᶦ. ɪnɦənᶦ sã ɕəɾiɾᶷ məzᶦbut̪ᶷ t̪ʰᶦje t̪ʰo.
Exercise
-
Keeping healthy is very important for us. There are many ways of keeping one’s body healthy. Of them, exercise is the easiest option. Moving parts of one’s body may be called exercise.
Hockey, football, volleyball, cricket, kabaddi, running and similar sports are different means of exercise. They help keep one’s body fit.
- 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒
Qaumī Jhanḍo
-
Asā̃jo qaumī jhanḍo ṭirango āhe. Hinᵃ mẽ ṭe rangᵃ āhinⁱ. Mathā̃ kesⁱrī rangᵘ āhe. Vichᵃ mẽ achho rangᵘ āhe. Heṭhā̃ sāo rangᵘ āhe. Jhanḍe je vichᵃ mẽ ashokᵃ chakarᵘ āhe.
Asā̃khe pãhĩje jhanḍe lāi izatᵃ āhe. 15 āgasṭᵘ aĩ 26 janⁱvarī te iskūlanⁱ, kālejanⁱ aĩ sarⁱkārī āfīsanⁱ mẽ asī̃ ṭirango jhanḍo jhūlāīndā āhⁱyū̃. Sabhᵘ gaḍ̄ⁱjī rāshṭrīyᵃ gītᵘ gāīndā āhⁱyū̃.
- (Maharashtra State Bureau of Textbook Production and Curriculum Research, 2007a, p. 48)
qɔmi d͡ʑʱəɳɖo
-
əsãd͡ʑo qɔmi d͡ʑʱəɳɖo ʈɪɾəŋɡo aɦe. ɦɪnᵊ mẽ ʈ(ɾ)e ɽəŋɡᵊ aɦinᶦ. mət̪ʰã kesᶦɾi ɾəŋɡᶷ aɦe. ʋit͡ɕᵊ mẽ ət͡ɕʰo ɾəŋɡᶷ aɦe. ɦeʈʰã sao ɾəŋɡᶷ aɦe. d͡ʑʱəɳɖe d͡ʑe ʋit͡ɕᵊ mẽ əɕokᵊ t͡ɕəkəɾᶷ aɦe.
əsãkʰe pɛ̃ɦᵋ̃d͡ʑe d͡ʑʱəɳɖe d͡ʑe laᶦ ɪzətᵊ aɦe. pən̪d̪ɾəɦĩ aɡəsʈᶷ ɛ̃ t͡ɕʰəʋiɦĩ d͡ʑənᶦʋəɾi t̪e ɪskulənᶦ, kaled͡ʑənᶦ ɛ̃ səɾᶦkaɾi afisənᶦ mẽ əsĩ ʈɪɾəŋɡo d͡ʑʱəɳɖo d͡ʑʱulain̪d̪a aɦᶦjũ. səbʰᶷ ɡəɗᶦd͡ʑi ɾaɕʈɾijᵊ ɡit̪ᶷ ɠain̪d̪a aɦᶦjũ.
National Flag
-
Our national flag is the tricolour. It has three colours. At the top is saffron. In the middle is white. At the bottom is green. In the middle of the flag is the Ashoka Chakra.
We respect our national flag. On 15 August and 26 January, we fly the tricolour flag on schools, colleges and government offices. Together, we sing the national anthem.
Interviewees were asked to read aloud all the texts that they could read, and provide feedback on their reading experience of each. Graphematically-oriented questions on optimal graph-phone correspondences and on diacritics were also posed, albeit without technical terminology to the extent possible. Also posed were questions on any perceived link between script and religion, and on the extent to which they thought Roman could or should be used as a script for Sindhi. The aim of the reading task was to get interviewees to compare and contrast the three writing systems where possible and record, as authentically as possible, their own views on the matter. As it turned out, the reading task elicited a variety of opinions on the ease and difficulty of reading in the three systems. Although only 18 were literate in 𝚜𝚍-𝙰𝚛𝚊𝚋, all but one claimed proficiency in 𝚑𝚒-𝙳𝚎𝚟𝚊. On this basis, many were able to decode 𝚜𝚍-𝙳𝚎𝚟𝚊 due to the large overlap in graph-phone correspondences between the two systems (see Chapter 7). Moreover, all interviewees were implicitly conversant with the simplified Hunterian conventions used to transcribe South Asian names and words thanks to its widespread contemporary use on social media. Given that the Hunterian conventions are a simplification of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 (§12.3), interviewees were able to decode 𝚜𝚍-𝙻𝚊𝚝𝚗 to various extents. Texts in the Romanized Sindhi subvariant (𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜) were not used to avoid overweighting the focus on 𝚜𝚍-𝙻𝚊𝚝𝚗. In any event, the intention was to stimulate broad-based intersystemic comparisons among 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗 rather than intrasystemic comparisons between 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜.
All interviews were recorded using a Sony ICD-PX440 portable recorder. Following the completion of an interview, it was transcribed for further analysis. This included a broad IPA transcription of interviewees’ reading of the Sindhi-language texts.
13.1.3 Emerging themes
Initial interviews were transcribed and analysed shortly after completion so that preliminary patterns in the data could be identified and incorporated as required in subsequent interviews. This system of ongoing coding and analysis, or constant comparative analysis (Glaser & Strauss, 1967) enabled data to be provisionally categorised and themes to be continuously conceptualised. Following the completion of data collection, data were scrutinised as a whole in order to further refine the provisional categorisations. This process of content analysis, namely a “research technique for making replicable and valid inferences from texts […] to the contexts of their use” (Krippendorff, 2004, p. 18), involved two levels of analysis. The manifest level entailed describing what was actually said by the interviewees, while the interpretative level focused on what was meant or implied. This enabled underlying inferences in the utterances to be brought to the surface (Ndhlovu, 2011).
As part of content analysis, the data were subjected to thematic analysis. This involved sifting patterns from the data while bearing the specific research questions in mind and categorising the patterns under fundamental themes called codes. The codes were identified on the basis of how well they captured the qualitative richness of the phenomenon under consideration (Boyatzis, 1998) and were subject to constant revision. A two-stage classification then followed, where codes were consolidated into Organising themes and Global themes. This approach contained elements of both deductive thematic analysis, in that the codes revolved around the aforementioned specific research question, as well as strains of inductive thematic analysis, in that the codes were not preconceived but sought from the data themselves (Braun & Clarke, 2006, pp. 83-84; Fereday & Muir-Cochrane, 2006, p. 91). In many cases, the codes did not show any direct link to the questions asked. The key criterion for classification as a code was that the information in the data needed to be related to the topic of script and language, but not necessarily to the interview questions. The usefulness of this approach was vindicated by the fact that the interviewees often volunteered additional relevant information, over and above what the interview question addressed. The ultimate aim of the analysis was to identify patterns of script use and opinions, and on this basis, provide recommendations on the way forward (Guest, Namey, & Mitchell, 2013, p. 13).
Overall, the themes were classified into two Global themes, each with two Organising themes. The themes are first expounded in detail, followed by the various subaspects of each theme. Several interview excerpts are included for illustrative purposes in the description of the themes, to give the reader the greatest possible first-hand feel of what was actually said by interviewees. The meanings and further interpretation of these utterances follow in the Analysis sections provided after each Global theme. The nomenclature used for the Global and Organising themes derives in part from Meletis’ (2020) concept of a writing system’s ‘fits’.
| Global theme | Organising theme | Basic theme |
|---|---|---|
| Linguistic fit | Familiarity | Acquaintance and use |
| Graphematic detail | ||
| Decodability | Phonological decoding | |
| Lexical decoding | ||
| Sociocultural fit | Semiotic suitability | Indexicality |
| Linguistic purity | ||
| Pragmatic suitability | Availability of content | |
| Motivation |
Of the above, the entire theme of decodability is devoted to data on interviewees’ reading of the Sindhi-language texts (see (31)). Also included are numerous examples of nonstandard interviewee pronunciation of certain words from the sample texts. That said, it is crucial to note that the reading task was unstructured in nature and intended only to gauge interviewees’ overall feel and reaction to 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗. The reading task was not designed for a quantitative analysis of pronunciation patterns. Besides, several interviewees, especially those with limited spoken Sindhi skills, stopped reading one or more of the texts midway due to the cognitive load involved. Two interviewees of the oldest generation were unable to read any of the texts due to age-related eyesight issues. All these lacunae make a statistical or quantitative approach to the subject matter unsuitable. Hence, the number of interviewees exhibiting a particular pronunciation has not been cited. Rather, this theme should be considered for the insights it offers into pronunciation patterns, especially among nonfluent Sindhi New Variety speakers. In this sense, the data presented and discussed under this theme are intended to act as a launch pad for further, more structured research on the subject.
In the description and analysis that follows, excerpts from interviews have been inserted where relevant to further illustrate the points under discussion and the direct connection between interviewees’ words and the interpretation of the data (Fereday & Muir-Cochrane, 2006, p. 81). It should be noted that interviewees’ statements were often incomplete, involved code-switching and code-mixing, featured multiple stops and starts, and often left out information implied in the context. For this reason, interview excerpts should be understood as capturing the gist of interviewees’ utterances, rather than as a literal reproduction of their utterances. This practice is also consistent with the study’s focus on the content of interviewees’ statements, rather than their form. Nevertheless, every effort has been made to remain as authentic as possible when quoting interviewees.
Interview excerpts are followed by a reference, comprising the interviewee’s serial number and a letter denoting their gender. For instance, any excerpts from the interview with the twenty-fourth individual, who happened to identify as female, are followed by the reference ‘(24F)’. Excerpts translated into English from the original Hindi or Sindhi have been marked ‘(translated)’. Source-language versions of excerpts have not been provided due to space constraints. Explanatory text within excerpts has been enclosed in braces { } instead of the conventional square brackets [ ] to avoid confusion with the convention used to denote phonetic transcriptions in the IPA
13.1.4 Procedural considerations and scope
It was crucial that the title and nature of the study did not give the interviewees the impression that the researcher’s aim was to promote any one Sindhi writing system. In other words, the study needed to be insulated against supposed experimenter bias. This was done by formulating open-ended questions by using words such as why and how, especially those dealing with interviewees’ opinions. Closed questions were used when ascertaining facts from interviewees’ language history, such as their exposure and familiarity to the Sindhi language in various scripts. Since such questions did not concern interviewees’ opinions, framing them in a closed manner was considered safe from a neutrality perspective.
On a related note, it was also critical that the researcher did not succumb to the curse of knowledge (Camerer, Loewenstein, & Weber, 1989), namely the inability of a person who knows more about a particular subject to view the subject from the perspective of those who know less about it. This would have been counterproductive, since the very aim of the study was to find out what the interviewees thought. Therefore, every attempt was made to ensure that the questions were relevant to the interviewees, related to their lived experiences and did not involve technical or nebulous jargon. Consequently, complex terminology was rendered in plain language, in line with common usage among the interviewees. For instance, the Roman script was referred to as ‘English letters’, and diacritics as ‘extra symbols’.
On the subject of terminology, the word ‘attitudes’ has been avoided to the extent possible in the analysis of the results when discussing interviewees’ reported feelings and behaviours. This has been done since the definition of attitude varies from individual to individual, and indeed author to author.139 Moreover, attitudes can be difficult to reliably measure, simply because they are difficult to observe and evaluate. Therefore, the less loaded term opinions has been preferred for the subject matter of the study — namely interviewees’ self-reported thoughts on the use of the various Sindhi writing systems in question, inevitably garnished with varying quantities of emotion.
Terminology aside, the fact remains that in an ideal scenario, interviewees should have reported their honest thoughts free of any external influences (Sunderland, 2010, p. 24). In particular, interviewees’ opinions should ideally not have been tainted by the knowledge that they were being observed by the researcher. Interviewees should also not have felt any implicit self-imposed pressure to conform to what they might have incorrectly assumed to be the researcher’s aim, that is, to promote Roman. In other words, interviewee reactivity to the research (Heppner, Wampold, & Kivlighan, 2007) should have been nil. However, interviewee reactivity could not have practically been avoided in this study, since gathering interviewees’ informed consent was an ethical prerequisite (§13.1.1). The very process of interviewees reading the Information Sheet and signing the Consent Form would have made them conscious that they would be observed. Hence, attempts were made to compensate for this by avoiding linguistic and ideological priming as far as possible, and designing interview questions to be open, as described earlier.
Regarding implicit pressure to conform to the researcher’s perceived intentions, some interviewees might have used so-called satisficing techniques (Simon, 1956) to some extent or the other. That is, interviewees might have provided answers which according to them would satisfy the researcher, and suffice for purposes of the research. It is, therefore, unrealistic to expect any sort of survey or interview data, whether quantitative or qualitative, to serve as unambiguous indicators of people’s true opinions. Indeed, some interviewees admitted that they had never thought about reading or writing Sindhi in any detail prior to the interview. Moreover, since the idea of using 𝚜𝚍-𝙻𝚊𝚝𝚗 was novel to most interviewees, their responses on the issue may reflect only their initial thoughts rather than fleshed-out opinions on the idea. These uncertainties were likely why I was gently cautioned by an interviewee (#38M), a Sindhi grammarian and lexicographer, that “this business of gathering people’s opinions is rather risky”. Nevertheless, while relying on people’s opinions may well be risky, sociolinguists often not have much choice in the matter. In this regard, Fishman (1991) has concisely summarised the indispensability of qualitative self-reported data when gauging opinions on and attitudes towards language:
If attitudes […] do become of overriding interest or importance, there is usually no practical alternative to […] collecting self-report data about them via ‘scales’ or ‘questionnaires’.
In any case, even if it is somehow possible to narrow down and identify people’s true opinions and behaviours, this would not guarantee that these people would eventually adopt a solution that is supposedly suitable under the circumstances. This is simply because they are human, and therefore, emotional beings. A cold, objective solution to the script issue that does not take people’s emotional idiosyncrasies into account would likely ultimately fail. This is why people’s opinions, albeit risky, have value. This idea has been succinctly expressed by Edwards (2011):
[E]ven if reported attitudes do not always correspond to actual behaviour – even if, in some situations, they rarely do so – we ought not to assume that they are without value. Sometimes what people say is just as interesting and revealing as what they do. Discrepancies may provide some perspective on the intertwining of the individual with the social, rather than presenting disturbing or perplexing anomalies.
(Edwards, Challenges in the social life of language, 2011, p. 41)
When it comes to gathering people’s opinions on written language, Cahill (2011) advocates giving community opinion utmost importance when deciding on an orthography. Cahill’s maxim could well be extended to decisions on script, in that what matters most is what the community feels about it. Meletis (2020, p. 187) echoes this sentiment in noting that sociocultural factors often make or break a writing system’s acceptance, regardless of its other ‘fits’.
Somewhat paradoxically, the importance of community opinion does not mean that all members of the relevant community would necessarily be in favour of it. I have already mentioned being forewarned by an interviewee against overreliance on people’s opinions has already been mentioned. In addition, I was advised by another interviewee, a Sindhi-language lexicographer and translator (#25M), that people “would have to do what the government tells them to do”. If taken to mean that people’s opinions are effectively insignificant, this statement stands in complete contrast to the spirit of Cahill’s statement above. Yet, the very same interviewees making such statements would have likely wanted their own opinions to be given due weight, affirming, ipso facto, that community opinion does matter.
13.2 Perceived linguistic fits
The Global theme of linguistic fit described in this section deals with matters of language learning and teaching, and categorises interviewees’ statements under the Organising themes of familiarity and decodability. The former covers interviewees’ statements on the supposed prevalence of the scripts in question in India and around the world, on their own literacy abilities, and on the necessity of certain graphematic features in the three writing systems in question. The latter Organising theme deals with interviewees’ opinions on the perceived transparency of the graph-phone correspondences as used in the Sindhi-language texts shown to them. Also evaluated are implicit issues that interviewees did not overtly identify but nevertheless made evident in their statements and reactions.
13.2.1 Organising and basic themes
Familiarity | Acquaintance and use
Given the multiscriptal history of the Sindhi community, it was unsurprising that interviewees exhibited a range of spoken and written proficiencies in a variety of languages and writing systems. This diversity was reflected in their levels of familiarity with written forms of Sindhi.
Sindhi-Arabic (𝚜𝚍-𝙰𝚛𝚊𝚋)
Of the 50 interviewees, 18 were literate in 𝚜𝚍-𝙰𝚛𝚊𝚋. Seventeen of them belonged to the oldest generation. Of the 18 𝚜𝚍-𝙰𝚛𝚊𝚋 literates, eight were laypersons and ten were scholars. Laypersons indicated that they preferred to read Sindhi in the Arabic script, given a choice.
I’m comfortable with reading Sindhi in both Arabic and Devanagari. But for me, Sindhi in Arabic is the real thing. (32M)
Lay interviewees’ preference for 𝚜𝚍-𝙰𝚛𝚊𝚋 was shaped not just by personal preference or ideology, but also by low exposure to 𝚜𝚍-𝙳𝚎𝚟𝚊.
I may have seen Sindhi in Devanagari somewhere. I think it was a Sukhmani Sahib {a Sindhi religious text} or something. (41M)
In fact, the dearth of everyday reading material was not restricted to 𝚜𝚍-𝙳𝚎𝚟𝚊, but extended to 𝚜𝚍-𝙰𝚛𝚊𝚋 as well. This was a common complaint among interviewees.
I manage to get a copy of the Hindvasi {a 𝚜𝚍-𝙰𝚛𝚊𝚋 weekly} only occasionally. I don’t get it where I live […] I manage to get about two or three Sindhi books a year. (21F; translated)
I can’t read Arabic-script Sindhi because there are no books published in it nowadays. (30M)
The perceived paucity of publishing in 𝚜𝚍-𝙰𝚛𝚊𝚋 was confirmed by a scholar, who attributed it to the dwindling reader base for the writing system.
Over 80 percent of Sindhi books being printed in India today are in Devanagari. Not more than 20, or even 10 percent, are in the Arabic script. The Arabic script is limited only to the older generation. (38M; translated)
The phenomenon of 𝚜𝚍-𝙰𝚛𝚊𝚋 proficiency being restricted to the oldest generation was confirmed by younger interviewees who were nonliterate in 𝚜𝚍-𝙰𝚛𝚊𝚋 but who had lived with their grandparents.
My grandparents used to subscribe to a Sindhi newsletter in the Arabic script, which used to arrive home. So I know how it looks. But I never understood it, obviously. (08F)
This fact was also highlighted by the three members of the Romanized Sindhi team (RST) who agreed to be interviewed. As mentioned in Section 12.3, the RST is behind one of the most organised community efforts at promoting Sindhi in Roman, under the subvariant 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜. The decline in community proficiency in 𝚜𝚍-𝙰𝚛𝚊𝚋 was highlighted as one of the driving forces behind the RST’s venture.
If a Sindhi newspaper in the Arabic script comes home, the eldest person reads it and then keeps it aside. There may be three generations living under the same roof, but neither of the younger ones can read it. And when the elderly person passes away, the paper will go into the garbage. (39M)
Along the same lines, the RST members also highlighted the difficulty in creating content in 𝚜𝚍-𝙰𝚛𝚊𝚋, due to it being restricted to the older generation.
People who can read Sindhi in Arabic, they can’t make an e-book because they don’t know how to use computers. (40F)
The crux of the issue was that the oldest generation literate in 𝚜𝚍-𝙰𝚛𝚊𝚋 was not computer-literate, while the youngest generation that was computer-literate was not literate in 𝚜𝚍-𝙰𝚛𝚊𝚋. This was compounded by the fact that members of the youngest generation did not seem to feel a need to learn 𝚜𝚍-𝙰𝚛𝚊𝚋.
Not that I’m keen on learning to write Arabic Sindhi — no way! It’s a totally different thing {laughs}. That’s something, if you’ve got to learn, you’ve got to learn at that {early} age. (49M)
The whole idea of learning the Arabic script is daunting […] that script just looks visually scary. (11M)
The oldest generation did not dispute the difficulty in learning 𝚜𝚍-𝙰𝚛𝚊𝚋, despite their personal fondness of it.
The Arabic script is difficult for an ordinary student to learn. It takes time. (19M)
Nonetheless, all lay interviewees literate in 𝚜𝚍-𝙰𝚛𝚊𝚋 indicated that maintenance of the language was more important to them than maintenance of the writing system. In brief, they were open to the idea of using another script to read and write Sindhi if doing so would aid in the dissemination of the language.
I know, whenever there is a change, people oppose these things vehemently […] but if Sindhi youngsters can learn their cultural language through a familiar script, the language will be more popular, and will give it better chances of survival. (46M)
However, there were differences on what this alternative script for Sindhi should be. Of the 18 interviewees literate in 𝚜𝚍-𝙰𝚛𝚊𝚋, five thought using Devanagari was the way forward, whereas eight, including the three RST members, supported Roman. Two favoured persisting with Perso-Arabic. The remaining three were uncommitted, opining that issues such as the standardisation of graph inventories and spellings in existing writing systems were more important than picking one particular script for writing Sindhi. These opinions will be taken up subsequently.
Sindhi-Devanagari (𝚜𝚍-𝙳𝚎𝚟𝚊)
The ubiquity of the Devanagari script in interviewees’ lives was a common theme. Indeed, all but one were literate in a Devanagari-based writing system, mostly 𝚑𝚒-𝙳𝚎𝚟𝚊. Apart from two scholars, all interviewees also agreed on the pervasiveness of Devanagari-based writing systems in India. Yet, exposure to 𝚜𝚍-𝙳𝚎𝚟𝚊 was far from common. Fourteen interviewees were unaware of its very existence. All but one of them were from the youngest generation, with the exception being a middle-aged fluent speaker who had grown up in Malaysia. Seven interviewees had heard of 𝚜𝚍-𝙳𝚎𝚟𝚊, but had never witnessed a text in it. Of these seven, two expressed confidence in their ability to read it, based on their fluency in reading 𝚑𝚒-𝙳𝚎𝚟𝚊 and speaking Sindhi.
I’ve not learnt Sindhi in Devanagari formally. But […] if you know how to speak Sindhi, and if you know how to read Hindi in Devanagari, the job’s done. There’s no magic in reading Devanagari-script Sindhi. (31F)
Twenty-eight interviewees had had at least some exposure to 𝚜𝚍-𝙳𝚎𝚟𝚊, including the 18 who were literate in 𝚜𝚍-𝙰𝚛𝚊𝚋. However, interviewees in this group ranged from university lecturers and writers in 𝚜𝚍-𝙳𝚎𝚟𝚊 to those who had had only a one-off brush with it.
In the 1960s, my relatives used to go to a Sindhi-medium school in Bombay called Kamla High School. I just read their Devanagari-script Sindhi books out of curiosity, but nothing at length. (29M)
Nevertheless, there was no pattern between the extent of exposure to 𝚜𝚍-𝙳𝚎𝚟𝚊 and support for it. In fact, opinions varied widely on the extent to which 𝚜𝚍-𝙳𝚎𝚟𝚊 should be used. Ten interviewees explicitly cited 𝚜𝚍-𝙳𝚎𝚟𝚊 as suitable as a supplement to or replacement for 𝚜𝚍-𝙰𝚛𝚊𝚋. The essence of such comments was that many people across India would be literate in a Devanagari-script writing system, making it a suitable script for Sindhi, too. However, a fundamental assumption made by eight of them was that acquaintance with a Devanagari-based system, typically 𝚑𝚒-𝙳𝚎𝚟𝚊, equated to proficiency in it. In other words, they expected that those who could read 𝚑𝚒-𝙳𝚎𝚟𝚊 could read it well.
In India, people are already learning Hindi. It’s a compulsory subject in schools. So, they are well acquainted with the Hindi script. So, I think Devanagari would work for them for reading and writing Sindhi. (36F)
Children would have studied Hindi, so the Hindi script would be easier for them to read and write Sindhi in. (33F; translated)
Five interviewees of the middle-aged and oldest generations mentioned that enthusiasm for preserving the Sindhi language was greater in smaller towns in northern and western India, where the language was still actively spoken. Since the populations of these areas tended to be more conversant with a Devanagari-based writing system, interviewees justified promoting 𝚜𝚍-𝙳𝚎𝚟𝚊 on this basis.
If Sindhi is to be revived and preserved in India, it will only be in the pockets where it is being spoken today. In smaller towns — Pimpri, Ulhasnagar, Jaipur, and along the Kutch border. So, if we want to preserve it, we have to preserve it there. And for them, the familiar script is Devanagari. The Gujarati script is also practically Devanagari. (36F)
The insinuation was that only those dominant in a non-English South Asian language and proficient in reading a Devanagari-based system would bother reading or writing Sindhi; those community members living in urban areas and who were English-dominant would not care about the Sindhi language anyway.
The people who know the Roman alphabet well are not the ones who are enthusiastic about the Sindhi language. (42M)
Two interviewees in favour of 𝚜𝚍-𝙳𝚎𝚟𝚊 also unwittingly put forward the red herring that Devanagari was better for Sindhi because Hindi is the “national language” of India.140
There’s a likelihood that Sindhis in India would lean towards the Hindi script because they know, at the end of the day, the national language of India is Hindi. (09M)
Such statements illustrated the difficulty felt by certain interviewees in conceptually distinguishing between the spoken and written forms of language, likely exacerbated by the phenomenon of most major Indian languages being written in a distinct script. This theme will be explored further in Section 13.3.1. Nevertheless, the supposed national nature of the Devanagari script was a reason behind a couple of interviewees judging 𝚜𝚍-𝙳𝚎𝚟𝚊 as the path of least resistance.
You will not meet any resistance if you go with what is deemed as the national script. (42M)
Two more interviewees alluded to 𝚜𝚍-𝙳𝚎𝚟𝚊 being the path of least resistance, albeit from a slightly different perspective. To these interviewees, using 𝚜𝚍-𝙳𝚎𝚟𝚊 seemed less of a gamble. Although they had never read 𝚜𝚍-𝙳𝚎𝚟𝚊, they had had prior experience with 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚖𝚛-𝙳𝚎𝚟𝚊 at school. Based on their experience, they felt subjectively reassured that 𝚜𝚍-𝙳𝚎𝚟𝚊 would have a similar set of graph-phone correspondences and graphematic transparency. In contrast, their experience with 𝚎𝚗-𝙻𝚊𝚝𝚗 and its opaqueness made them sceptical of a putative 𝚜𝚍-𝙻𝚊𝚝𝚗 doing justice to representing Sindhi’s phonology.
How would you spell some of these Sindhi words in Roman? Someone spells it a certain way because they think that’s how it should be spelt. And another person reads it in a different way. (08F)
There’d be different people pronouncing the symbols differently, and there’d just be more variations in the language, as a result […] Luckily, now, Devanagari is quite encompassing. (01M)
The interviewees who were uncommitted towards using 𝚜𝚍-𝙳𝚎𝚟𝚊, or had doubts about its success, were also sceptical of Devanagari’s pan-Indian status in geographic and socioeconomic terms. They felt that regions outside the north and west of the country, and wealthy English speakers in large cities, would have poor knowledge of 𝚑𝚒-𝙳𝚎𝚟𝚊, and consequently, of the Devanagari script.
When I used to teach Sindhi to non-Sindhis, quite a few students would have trouble understanding even Devanagari. (38M; translated)
Hindi is not compulsory after Class 10 […] So, people are not giving any importance to Hindi. They are saying, “We only need to pass, so the bare minimum is enough.” So that’s why people are losing interest in Hindi in India, especially in cosmopolitan cities. (47M)
For most interviewees who had not heard of 𝚜𝚍-𝙳𝚎𝚟𝚊, the prospect seemed inconsequential.
I don’t know what the use case would be for someone to be writing Sindhi in the Devanagari script. Because you might as well speak it out, and write it in a universal script which everyone already understands. (03M)
For most interviewees, this “universal script” was Roman. However, acceptance of Roman’s supposed universality did not necessarily translate into support for using it for the Sindhi language.
Sindhi-Roman (𝚜𝚍-𝙻𝚊𝚝𝚗)
Conversance with Roman within the Sindhi community was the most salient theme in the data. All but four interviewees indicated having read at least some content in 𝚜𝚍-𝙻𝚊𝚝𝚗, typically in the form of text messages (SMS) or snippets on social media. However, for most interviewees, these texts or snippets were the only exposure to 𝚜𝚍-𝙻𝚊𝚝𝚗 they had received. Moreover, these pieces of writing were usually of extremely short length, and typically comprised jokes or greetings.
My nephew sometimes sends me some jokes in Sindhi, written in Roman. (48F)
The short messages in 𝚜𝚍-𝙻𝚊𝚝𝚗 that interviewees were familiar with were typically written using ad hoc graph-phone correspondences loosely inspired by the Hunterian variant of 𝚎𝚗-𝙻𝚊𝚝𝚗. However, the unpredictability of graph-phone correspondences in such writing and the resultant opacity made it difficult to decipher, even for fluent speakers of Sindhi. The saving grace was the typically short length of such 𝚜𝚍-𝙻𝚊𝚝𝚗 texts.
You have these little Sindhi jokes or forwards on social media. It takes me time to understand. But because it’s just a small paragraph — 2 lines, 3 lines — it’s fine. I manage. (14F)
The finer aspects of the 𝚜𝚍-𝙻𝚊𝚝𝚗 writing that interviewees were exposed to is examined later in this section, under the basic theme ‘Familiarity | Graphematic detail’.
Regardless of exposure, interviewee opinion on 𝚜𝚍-𝙻𝚊𝚝𝚗 was not unanimous, as was the case with 𝚜𝚍-𝙳𝚎𝚟𝚊. Opinion was divided among those in favour of, against and uncommitted towards the idea of 𝚜𝚍-𝙻𝚊𝚝𝚗. All but two interviewees agreed that Roman was well-known among the community in India and in the diaspora. Of these, 24 interviewees explicitly indicated that 𝚜𝚍-𝙻𝚊𝚝𝚗 would be a good idea. This included one interviewee who had never seen any 𝚜𝚍-𝙻𝚊𝚝𝚗 text prior to the interview.
With Sindhi in Roman, the advantage would be everyone would be more comfortable with that. Everyone can understand that, every Sindhi person. (22M)
This sentiment was similar to the basic argument underlying the pro-𝚜𝚍-𝙳𝚎𝚟𝚊 views, namely that Devanagari was suitable for Sindhi, at least in India, because the script was already widely known in the country. However, supporters of 𝚜𝚍-𝙻𝚊𝚝𝚗 bolstered their claim further by alluding to Roman’s prevalence worldwide. Of the 20 interviewees based outside India, 12 unequivocally backed 𝚜𝚍-𝙻𝚊𝚝𝚗.
The advantages of using Roman for Sindhi are obvious. Just the number of people you could reach out to. It’s very well known. (06M)
After coming to Australia, you tend to lose touch with written Hindi […] I feel the long-term benefits would be if you actually use Roman letters to write Sindhi. Because then it’s gonna be easier to spread the Sindhi language globally than just in India. (07M)
Two interviewees from the diaspora who had young children felt that 𝚜𝚍-𝙻𝚊𝚝𝚗 would help give their children introductory familiarity with their heritage language. This, they thought, might stimulate their children to pick up the language further.
The advantage of Sindhi in Roman is that children will get more exposure to the language. And they might ultimately try to understand what that text is. (50F)
This view was echoed by a scholar, also based in the diaspora.
If you give the learner a language in a script that he’s already familiar with, the accessibility to that language becomes a lot easier. The learner saves time and effort. Then there’s the psychological benefit. More than anything else, the psychology works wonders. There’s no initial battle that the learner has to win. (46M)
Ten interviewees mentioned having studied a Western European language in addition to English. Two of them noted that, as learners, they found it convenient that these languages were written in Roman, which they were familiar with through 𝚎𝚗-𝙻𝚊𝚝𝚗. On this basis, they supported the idea of 𝚜𝚍-𝙻𝚊𝚝𝚗.
When I started learning German, I realised one thing — that it is the alphabet which is helping. Suppose German was written in a particular script other than Roman. First, I’d have to learn the script […] How many scripts can you learn? (41M)
That said, these interviewees made no mention of the mutually incompatible graph-phone correspondences and orthographies of these European languages, and how they overcame these initial hurdles.
Two scholars who had dealt extensively with 𝚜𝚍-𝙳𝚎𝚟𝚊 categorically endorsed the idea of 𝚜𝚍-𝙻𝚊𝚝𝚗. Their justification hinged on the wide use of 𝚎𝚗-𝙻𝚊𝚝𝚗 by the youngest generation of Sindhis in India and overseas, and the ensuing familiarity with the Roman script.
I think it’s an excellent idea to adopt the Roman script for Sindhi […] Because English is the universal language now. (24F)
The previous generation will prefer the Arabic script for Sindhi. And then Devanagari. But the upcoming generation will certainly use Roman. And they will find it better. (20F)
A specific aspect of the supposed ubiquity of the Roman script was highlighted by the members of the Romanized Sindhi team. One of the major reasons for the RST’s advocacy for Roman is the script’s near-universal availability as an input method on computers and mobile devices (§12.3). The RST’s members, who were literate in both 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊, felt that the widespread support for the Roman script on computing devices gave it a clear advantage in modern times over the other two scripts in the fray.
The Roman script is international, all over the world. Every computer has it. (44M)
Those who know the Sindhi script — that Arabic script — and Devanagari, they are not computer-savvy […] We’re moving towards a digital world. So, we have to give the younger generation something which is easily available on computers. (40F)
Nonetheless, the pervasiveness of Roman on computing devices was only cited as an advantage by the RST members. No other interviewee cited support on computing devices as a reason to adopt Roman for Sindhi, perhaps because they thought of Sindhi predominantly as a spoken language. This topic will be dealt with further under the theme ‘Pragmatic suitability | Motivation’.
However, not all who agreed on the prevalence of Roman thought that the script should be used for Sindhi. Nineteen interviewees were in favour of renewed ways of teaching 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊. The reasons for their disinclination towards the idea of 𝚜𝚍-𝙻𝚊𝚝𝚗 was largely based on personal preference. They suggested that Roman be relegated to diasporic Sindhis.
In India, it is better that they teach children Sindhi in the Arabic script. If they cannot, then in Devanagari. But abroad, where children have no choice, they can teach them Sindhi in Roman to keep the language alive. (34F)
Of the interviewees instinctively disinclined towards 𝚜𝚍-𝙻𝚊𝚝𝚗, five conceded that it might actually be a pragmatic option. They surmised that writing Sindhi in Roman might be useful in initially luring learners to the language, who might otherwise be put off by the prospect of an unknown script.
The advantages of it being in Roman is, of course, you will get the masses […] You’d be able to get a lot more candidates to take a first step towards reading and writing Sindhi […] but Devanagari or the original Arabic script would be ideal. (09M)
Such interviewees, who saw Roman as a useful carrot for attracting learners but not as a full-fledged script for the language, typically had a mental image of Roman as a stop-gap measure or a temporary fix to the script issue. This aspect will be discussed further under the Global theme of sociocultural fits (§13.3).
The two interviewees who expressed doubts on Roman’s pervasiveness within the Sindhi community also highlighted the importance of users’ subjective comfort with a particular script and how it might shape their acceptance of Sindhi written in that script.
You have the option for English-speaking parents to teach their kid using the Roman script. But that again is a minority in India […] there’s a large section who are Hindi-speaking, and perhaps read and write and are more comfortable in the Hindi script. (10M)
Seven interviewees did not favour any particular script outright. They felt other issues were more pressing, such as spelling standardisation in 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 and the creation of engaging Sindhi-language content. These themes will be taken up under the Organising themes of ‘Decodability’ (this section) and ‘Pragmatic suitability’ (§13.3.1).
Familiarity | Graphematic detail
Compared to the rasms of the basic Roman inventory, the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text shown to interviewees comprised numerous graphs augmented with subsegmental elements or diacritics. Eighteen interviewees felt that diacritics were a useful inclusion in the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text and aided the decoding process. This view was particularly noticeable among those who had prior exposure to a Roman-script-based writing system whose inventory comprised rasms augmented with diacritics.
It’s a wonderful idea […] The French learn French using the Roman script with their accent marks. Similarly, you can do Sindhi with the Roman script with accent marks. (14F)
A couple of interviewees had had experience with the International Alphabet for Sanskrit Transliteration (IAST), used to transcribe Sanskrit in the Roman script (Royal Asiatic Society, 1896). The IAST’s graph inventory and graph-phone correspondences essentially comprise a subset of the multilingual Roman-script system used in the Linguistic Survey of India (𝚖𝚞𝚕-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒; §12.2). As 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒, too, comprises a subset of 𝚖𝚞𝚕-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒, it shares a large degree of overlap with the IAST. As a result, interviewees found the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 text shown to them visually familiar.
This is the same way it’s done for Sanskrit, too […] when you read the Bhagavad Gita and its shlokas {verses}, this is the way they indicate how it should be pronounced. (18F)
Scholars interviewed generally approved of graphetic augmentation to the extent that it served a justifiable linguistic function.
Roman script with diacritics the best. In Devanagari-script Sindhi, too, we use underlines to indicate implosives. (20F)
For implosives, you’ll have to use diacritics […] If you want to romanise Sindhi, then you need to do so keeping in mind the structure of the language — and not the convenience of people or machines (38M; translated)
On the other hand, 21 interviewees — not including the RST members — opined that adding diacritics to 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 increased learning and reading complexity. Such interviewees emphasised the need for the function of diacritics to be explicitly taught. For some interviewees, it appeared that the 𝚎𝚗-𝙻𝚊𝚝𝚗 graph inventory served as a canonical template that they were reluctant to deviate from.
In English, too, you won’t find these symbols […] It needs to be taught, what these marks would sound like. (17M)
Consequently, having to learn the linguistic values of diacritics was seen as increasing the initial learning curve. This partially negated the advantages of accessibility and ease as claimed by supporters of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜.
If I’m reading this word in Roman-script Sindhi, I need to know what this symbol sounds like. I need to know it so well that it instinctively comes to me. So, I’m trying to learn phonetic notation and then read this. You’re adding an extra step for me. It’s not as easily accessible as it may seem. (12F)
Overall, visual simplicity of the graph inventory was considered somewhat more salient than its phonological precision. In this regard, augmenting the basic Roman inventory with diacritics was interpreted as adding to its graphetic intricacy.
These symbols lead to complications — the line and the dot and all that. In fact, this is like going back to the original Arabic script. It’s as difficult as doing it in the original. (09M)
Even those interviewees who felt that diacritics were useful sometimes highlighted the initial impression of increased complexity that diacritics conveyed. On this basis, they opined that having a 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 inventory that differs from the 𝚎𝚗-𝙻𝚊𝚝𝚗 or basic Roman inventory might be disagreeable to beginners.
Having extra symbols in Roman is the perfect way, actually. But I don’t know how children, how the Sindhi youth of today will take to it. I would say, to not confuse them, keep it plain, without additional symbols. (31F)
Along these lines, it was felt that only languages with robust governmental or societal backing could afford to have a complex writing system. In their opinion, the Sindhi language did not enjoy this luxury anywhere outside Sindh, even in India.
German, for instance, is a language of a country. People had to learn it […] Hence, they could put the umlaut on some letters and say “Learn this. This is what it means.” In India, you can’t push this down people’s throat saying “You have to learn Sindhi”. So, it has to be made as simple as possible […] It’ll come at the cost of the language getting a little corrupted. (05M)
The ideal of visual simplicity also shaped the RST members’ thoughts on what a suitable 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 graph inventory should look like. The linearity of a 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 graph inventory free of diacritics was considered a significant advantage over the several bound graphs used in 𝚜𝚍-𝙳𝚎𝚟𝚊. They felt that using diacritics to augment the basic Roman inventory was akin to using bound graphs in 𝚜𝚍-𝙳𝚎𝚟𝚊, thereby replicating the graphematic complexity of the latter. For the RST interviewees, using or proposing diacritics in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 betrayed a latent conceptual influence of 𝚜𝚍-𝙳𝚎𝚟𝚊.
Putting diacritics over or under the letter is not an inherent part of the Roman script. That means we are still thinking in terms of Devanagari, if we write Sindhi in Roman with diacritics below and above letters. (39M)
That said, the RST evidently did feel the need to augment the basic Roman inventory to create as biunique a set of graph-phone correspondences as possible for representing Sindhi phonology. The crucial distinction is that the RST’s proposed 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 augmentations occupy their own graphosegmental space and appear after the affected graph. Moreover, since all graphosegmental ‘diacritics’ in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 are taken from the ASCII set (Table 12.1), they can all be entered using the widely-used US English keyboard layout. Other technological restrictions also dictated the choice of diacritics in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜.
We did not use the colon sign in our Roman Sindhi alphabet, because Microsoft’s operating system could not accept filenames with a colon. So we only used signs that were acceptable to the computer. (44M)
Thus, in addition to perceived visual complexity, the supposed difficulty in inputting bound graphs or subsegmental diacritics using a US English keyboard layout was another reason the RST eschewed them in their graph inventory.
To input special signs, you have to make special software. How many people around the world will go and buy the software, and begin to use and learn Sindhi in Roman? We wanted to make do with the symbols that are already available on the computer, without creating any more software and without confusing anyone. (44M)
Such opinion reinforced the RST’s argument of ubiquity and ease of input on computers being a major advantage of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜. Including diacritics was evidently seen as encumbering this ease of input, and nullifying the advantage. Regardless, apart from the RST members, the supposed difficulty in typing Roman-script diacritics on computers and electronic devices was explicitly raised only by one other interviewee.
Apart from the RST members, some other interviewees also found diacritics disagreeable. Yet, they admitted the need to augment the basic Roman alphabet to adequately represent Sindhi phonology, while also struggling to articulate their opinion as nonlinguists.
Showing [
ʈʰ] in the Roman script is very difficult. Because |th| could also be read as [t̪ʰ]. (13F)In Roman, showing the difference between [
ʈ ʈʰ ɖ ɖʰ ɳ] and [t̪ t̪ʰ d̪ d̪ʰ n] is difficult. That is something to think about […] Indicating [ɓ ɠ] is very difficult. (47M)
Remarkably, reticence to diacritics was only in the context of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜. In 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊, most subsegmental and bound graphs were seen as an integral part of the inventory and writing system. Furthermore, such elements were regarded as key to those systems’ perceived phonological accuracy. A scholar referred to the convention of omitting bound γ-vowels in 𝚜𝚍-𝙰𝚛𝚊𝚋, which he thoughts caused reading difficulties for primary school children. He narrated his unsuccessful attempt to have all 𝚜𝚍-𝙰𝚛𝚊𝚋 γ-vowels overtly denoted in Indian 𝚜𝚍-𝙰𝚛𝚊𝚋 textbooks.
Without vowel diacritics, Arabic-script Sindhi is effectively disabled. I told the so-called scholars in charge of preparing textbooks, “Please include vowel diacritics in textbooks. Children need them.” But those professors said, “No! There’s no tradition of using vowel diacritics in Arabic-script Sindhi”. (25M; translated)
Another scholar raised the issue of allography prevailing in the context of 𝚜𝚍-𝙰𝚛𝚊𝚋 γ-vowels in textbooks (§6.5.3). According to him, representing the φ-vowels [i u] as |اوُ ايِ| was more authentic in 𝚜𝚍-𝙰𝚛𝚊𝚋 than |اُو اِي|, and that the latter convention was influenced by 𝚊𝚛-𝙰𝚛𝚊𝚋 practices. In his opinion, distinct preferences for these allographs in Pakistan and India was accentuating the divergence between 𝚜𝚍-𝙰𝚛𝚊𝚋 orthography in the two graphospheres.
In India, even today, we don’t write the diacritics for [
i u] over alif. But in Pakistan, they’ve started doing it. Because of Arabic influence. (38M; translated)
The underlying theme in both scholars’ statements was that γ-vowels in 𝚜𝚍-𝙰𝚛𝚊𝚋 were an inalienable and, indeed, indispensable part of the writing system. Likewise, an interviewee, who dismissed diacritics in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 as confusing, lauded the supposed unambiguity of bound vowel allographs in 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙳𝚎𝚟𝚊, commonly referred to as matra.141
We need the matra in Devanagari […] The matra are easier for me to read than these symbols in Roman. (13F)
Thus, it was evident that lay interviewees had different mental yardsticks for diacritics in various writing systems, depending on how much exposure they had had to them and, consequently, internalised them.
Underlying reticence to diacritics meant that interviewees unwittingly ignored several graphetic elements the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text absent from the basic Roman inventory. Despite ignoring diacritics, those with high levels of oral Sindhi proficiency were able to read the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text with reasonable accuracy, by mentally filling in graphematic gaps.
All these symbols, they didn’t make any difference to me. I didn’t pay any attention to them. (15M; translated)
I know how to speak Sindhi […] so I didn’t really pay attention to the extra symbols in Roman […] These symbols are fine for those who have no idea of Sindhi, who are complete beginners. (21F; translated)
Thus, interviewees fluent in spoken Sindhi seemed to read the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text by lexical or whole-word recognition. They found it difficult to conceptualise reading by phonologically decoding individual letters. On this basis, they rationalised that fluency in spoken Sindhi was necessary to read the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 text accurately.
If the youngsters know how to speak Sindhi, then the language can be transliterated into Roman. If they don’t know spoken Sindhi itself, then Sindhi in Roman will be difficult to pronounce. (30M)
This Roman-script Sindhi will take time. The youngest generation don’t know the words and the language. So they’ll find it difficult. I know the language, so I’ll be able to read it. (33F; translated)
Regardless, it was not the case that interviewees with limited spoken Sindhi read the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text by phonologically decoding individual graphs or graph sequences. Of the seven interviewees who rated their Sindhi knowledge as poor (1 out of 5; see Figure 13.3), only two claimed to have read graph-by-graph, paying attention to the diacritics along the way.
With all those little things added, with little more practice, it would be really helpful. (04M)
I don’t think this learning curve is very steep, with this kind of lettering. (23F)
The other five interviewees professing limited knowledge of Sindhi claimed to have read by lexical recognition, despite the inherent contradiction in their statement.
I more or less ignored the extra marks. It was previous knowledge of what I thought the word should sound like. (28M)
Even so, reading by lexical recognition was effectively the only option available to some of the interviewees nonfluent in spoken Sindhi. Even if they attempted to read by phonological decoding, insufficient time to familiarise themselves with the graph-phone correspondences of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 meant that they had to eventually fall back on their rudimentary spoken Sindhi knowledge to recognise words in the text.
I struggled with a couple of the extra marks and dots around the script. But with continuous use, you could possibly get used to that. (06M)
In general, when unable to match a written 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 or 𝚜𝚍-𝙳𝚎𝚟𝚊 word with an entry from their mental lexicon, nonfluent readers attempted an ad hoc pronunciation for it. Such arbitrary attempts sometimes resulted in the Sindhi-language word being pronounced as a graphematically similar word from a homoscriptal writing system, typically 𝚑𝚒-𝙳𝚎𝚟𝚊 or 𝚎𝚗-𝙻𝚊𝚝𝚗. At times, interviewees simply skipped problematic words altogether in their reading.
The aspect of readers needing to familiarise themselves with new graphematic conventions was touched upon by one scholar. In the context of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜, he believed that retaining graphs and conventions generally familiar to lay readers needed to be taken into account. On this basis, he recommended retaining digraphs such as |ch| and |sh| in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜, despite their apparent suboptimality.
In Roman-script Sindhi, we could create a new symbol for [
ɕ] either by adding a dot to the letter |s|, or by adding an |h| after it. Of these, I think |sh| is more common […] Similarly, if you spell [t͡ɕ] as |c|, we linguists will understand it, but common people will have trouble. They’ll read it as [k] or [s]. Because they’re used to writing words like [t͡ɕat͡ɕa], meaning ‘uncle’, with a |ch|. (38M; translated)
Another scholar, although agnostic in terms of graphematic conventions, stressed the importance of standardisation regardless of writing system.
As long as symbols and spellings are standardised and they are uniform, it shouldn’t cause confusion. Confusion comes when you spell one thing in different ways. And then you fight over it — which is right and which is wrong. (19M)
Overall, the aspect of familiar graphs and graphematic conventions to enable inexperienced readers to better ease in was a common theme across scholarly as well as lay opinion. Such a process would inevitably entail closely scrutinising the graphematic features of every candidate writing system to identify areas of difficulty in decoding. However, since 𝚜𝚍-𝙰𝚛𝚊𝚋 literacy was restricted to a minority of interviewees, the Organising theme on Decodability is restricted to findings on 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒.
Decodability | Phonological decoding
𝚜𝚍-𝙳𝚎𝚟𝚊 | Reduced lax γ-vowels
Notwithstanding idiosyncratic variation, interviewees who read the 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 texts exhibited certain observable patterns of nonstandard pronunciations. One such pattern was the decoding of unstressed lax γ-vowels, particularly evident in the youngest generation’s pronunciations. Most interviewees in this cohort comprised notional speakers of the Sindhi New Variety, albeit with poor to average competence. When reading the 𝚜𝚍-𝙳𝚎𝚟𝚊 text, the youngest generation routinely failed to articulate word-final [ᵊ]. This pattern aligned with the fact that [ə] — including its reduced allophone [ᵊ] — are not overtly indicated in 𝚜𝚍-𝙳𝚎𝚟𝚊 owing to its status as the default φ-vowel (Table 7.4).
In contrast to the representation of [ə] and [ᵊ], 𝚜𝚍-𝙳𝚎𝚟𝚊 overtly denotes the lax φ-vowels [ɪ ʊ] as |ि ु| or |इ उ|, respectively. However, the same graphs are used to denote the reduced φ-vowel allographs [ᶦ ᶷ]. For Sindhi Old Variety speaker-readers, the graphematic indistinctiveness of full [ɪ ʊ] and reduced [ᶦ ᶷ] does not usually pose a problem, since their phonological values are predictable from their word-internal position (Table 7.5). However, reduced lax φ-vowel allographs are often absent or noncontrastive in the New Variety phonology (§4.3.2). To compensate for this gap, interviewees were informed in advance that 𝚜𝚍-𝙳𝚎𝚟𝚊 |ि ु| and |इ उ| were to be pronounced as reduced [ᶦ ᶷ] in unstressed positions, especially at the end of a word. Still, the marginal nature of reduced [ᶦ ᶷ] in New Variety Sindhi, coupled with the youngest generation’s lack of exposure to 𝚜𝚍-𝙳𝚎𝚟𝚊 writing, meant that this cohort decoded most instances of |ि ु| or |इ उ| in the 𝚜𝚍-𝙳𝚎𝚟𝚊 text as full [ɪ ʊ]. In word-final position, |ि ु| or |इ उ| were typically rendered as tense [i u], reflecting the influence of 𝚑𝚒-𝙳𝚎𝚟𝚊 graphematics (§7.5.3). Often, such realisations resulted in an articulation that was effectively a nonword in spoken Sindhi. A summary of common nonstandard pronunciations by interviewees is shown in Table 13.2.
| 𝚜𝚍-𝙳𝚎𝚟𝚊 spelling | Nonstandard spelling | Standard Sindhi pronunciation | Gloss | |
|---|---|---|---|---|
| Old Variety | New Variety | |||
Medial [ᶦ] as [ɪ]<]/th>
| ||||
| केतिरा | ket̪ɪɾa |
ket̪ᶦɾa |
ket̪ɾa |
‘how many’ |
| सभिनी | səbʱɪni |
səbʱᶦni |
səbʱni |
‘all’ |
| कसिरत | kəsɪɾət̪ |
kəsᶦɾət̪ᵊ |
kəsɾət̪ |
‘exercise’ |
Final [ᶦ] as [ɪ] |
||||
| बि | bi |
bᶦ |
b(ᶦ) |
‘also’ |
Final [ᶷ] as [u] |
||||
| तंदुरुस्तु | t̪ən̪d̪ʊɾʊst̪u |
t̪ən̪d̪ʊɾʊst̪ᶷ |
t̪ən̪d̪ʊɾʊst̪ |
‘fit, healthy’ |
| रहणु | ɾəɦɳu ~ ɾɛɦɳu |
ɾəɦəɳᶷ |
ɾəɦəɳ |
‘to be’ |
| तमामु | t̪əmamu |
t̪əmamᶷ |
t̪əmam |
‘very’ |
Of the words in the 𝚜𝚍-𝙳𝚎𝚟𝚊 text with final |ि| or |इ|, the word |आहिनि| [aɦɪnᶦ] ‘are’ usually escaped being pronounced with final [i]. The ubiquity and frequency of this word in the spoken language was likely the conditioning factor at play.
If the reader was nonfluent in spoken Sindhi, they tended to consider words of the kind in Table 13.2 as unfamiliar words, and move on. However, if the interviewee was reasonably fluent in spoken Sindhi, their inability to map their ‘overpronounced’ decoding of a 𝚜𝚍-𝙳𝚎𝚟𝚊 word with a corresponding phonological entry in their mental lexicon often resulted in visible displeasure with the 𝚜𝚍-𝙳𝚎𝚟𝚊 text.
𝚜𝚍-𝙳𝚎𝚟𝚊 | Pronunciation of rasmically cognate graphs
As is the case in 𝚑𝚒-𝙳𝚎𝚟𝚊, 𝚜𝚍-𝙳𝚎𝚟𝚊’s inventory uses complex graphs created by graphetically augmenting existing rasms (§7.5.1). One such frequently-occurring graph in 𝚜𝚍-𝙳𝚎𝚟𝚊 is |ज़| [z(ə)], graphetically derived from |ज| [d͡ʑ(ə)]. However, the visual similarity of these graphs led interviewees to sometimes decode |ज़| as [d͡ʑ(ə)]. Select words susceptible to such decoding are shown in Table 13.3.
| 𝚜𝚍-𝙳𝚎𝚟𝚊 spelling | Nonstandard pronunciation | Standard Sindhi pronunciation | Gloss | |
|---|---|---|---|---|
| Old variety | New variety | |||
| ज़रूरी | d͡ʑəɾuɾi |
zəɾuɾi |
zəɾuɾi |
‘necessary’ |
| उज़्वे | ʊd͡ʑʋe |
uzʋe |
uzʋe |
‘limb (oblique)’ |
| मज़िबूतु | məd͡ʑbut̪ |
məzᶦbut̪ᶷ |
məzbut̪ |
‘strong’ |
With reference to Table13.3, [zəɾuɾi] and [məzbut̪] also exist in the lexicon of contemporary Hindi, in which they are often realised as the nonstandard affricated pronunciations [d͡ʑəɾuɾi] and [məd͡ʑbut̪]. The affricated pronunciations in the context of Sindhi might, therefore, be attributed to Hindi interference. However, [uzʋe] has no common parallel in Hindi lexicon. Hence, the affricated pronunciation of this word can only be attributed to |ज़| [z(ə)] being interpreted as |ज| [d͡ʑ(ə)] based on visual similarity. Indeed, of all words in the text containing |ज़| [z(ə)], [uzʋe] was the one most frequently rendered with [d͡ʑ(ə)].
𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 | Lax and tense γ-vowels
Compared to the 𝚜𝚍-𝙳𝚎𝚟𝚊 text, interviewees rendered the reduced φ-vowels [ᵊ ᶦ ᶷ] more predictably and accurately when reading the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text. Before commencing the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text, interviewees were advised that the superscript γ-vowels |ᵃ ⁱ ᵘ| were “lightly pronounced” versions of their full-sized equivalents |a i u|. Considering the elusive nature of reduced [ᵊ ᶦ ᶷ] in New Variety Sindhi, their representation in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒’s as the graphematically iconic |ᵃ ⁱ ᵘ| appeared to benefit beginner readers, especially those nonfluent in spoken Sindhi.
With interviewees who were scholars, the presence of subscript |ᵃ ⁱ ᵘ| often stimulated discussions on whether reduced [ᵊ ᶦ ᶷ] should be explicitly written in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜, especially considering their marginal phonological status in New Variety Sindhi. One scholar in favour of explicitly representing reduced [ᵊ ᶦ ᶷ] drew attention to their grammatical function (§4.4).
There’s been a lot of debate on this. If you don’t show reduced vowels at the end of a word, how will you know the difference between plural and singular forms? Oblique and non-oblique forms? How will gender be decided? How will the computer give you an appropriate output when parsing data? (38M; translated)
In contrast, another scholar felt that it was necessary for any Sindhi writing system to adapt to changing pronunciations and not reflect antiquated standards.
In thirteenth-century Marathi, you’d say and write [
d̪eʋa t̪ũt͡ɕɪ ɡəɳeɕʊ].142 Today’s Marathi has lost those final short vowels. And Marathi spelling in Devanagari has been adapted accordingly. (25M; translated)
Statements by the three RST members indicated that the RST was yet to arrive at unambiguous agreement on whether and how to graphematically denote reduced φ-vowels. One member cited how younger readers of their proposed 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 system sometimes failed discern when the γ-vowels |i u| were to be pronounced as reduced [ᶦ ᶷ], especially when word-final. The member illustrated his point with the Sindhi word [əmbᶷ] ‘mango’, rendered in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 as |a’nbu|. He acknowledged that resolution of the matter was pending.
Technically speaking, we should add the letter |u| at the end of certain words. But there was an objection from my colleague. He asked ordinary children to read the word |a’nbu|, and told them that the letter |u| stands for a very short [
ʊ]. But instead of [əmbᶷ], everyone said [əmbuːːː]. So, my colleague said that it’s confusing to write |u| and |i| when they’re pronounced extra short. Write them without any vowel at the end […] But we have to sort out this issue. (44M)
Another RST member preferred explicitly writing word-final |i u|, but conceded that learners may overpronounce them. She cited the inaccurate decoding of final γ-vowels in the Sindhi words [d̪ɪlᶦ] ‘heart’ and [pʊʈᶷ] ‘son’, written in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 as |d~ili| and |putu|.
In Romanized Sindhi, we write |d~ili| but pronounce it as [
d̪ɪlᶦ]. Learners might understand it as [d̪ɪliːːː]. Similarly, they pronounce |putu| as [pʊʈuːːː], since there’s a |u| at the end. I remind them that it’s a soft [ᶷ], and not [uːːː]. (40F)
The topic of graphematic distinctness also arose in the context of distinguishing lax and tense φ-vowels in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒. In 𝚜𝚍-𝙳𝚎𝚟𝚊, lax γ-vowels, both free and bound, are graphetically distinct from their tense counterparts. In 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒, however, lax |a i u| are set apart from tense |ā ī ū| only by the macron element or diacritic. The resulting graphetic subtlety sometimes led to readers misinterpreting γ-vowels, especially in infrequently occurring Sindhi words. Table 13.4 lists a selection of such instances.
| 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 spelling | Nonstandard pronunciation | Standard Sindhi pronunciation (Old & New Varieties) | Gloss |
|---|---|---|---|
| jhūlāīndā | d͡ʑʱulɛn̪d̪a |
d͡ʑʱula.in̪d̪a |
‘(we) fly’ |
| gāīndā | ɡɛn̪d̪a |
ɡa.in̪d̪a |
‘(we) sing’ |
| rāṣhṭrīyᵃ | ɾəɕt̪ɾij |
ɾaɕʈɾijə |
‘national’ |
As alluded to under the theme of ‘Graphematic detail’, the pronunciation of |jhūlāīndā| and |gāīndā| as [d͡ʑʱulɛn̪d̪a] and [ɡɛn̪d̪a] appear to originate in readers’ reticence towards diacritics. Thus, the reader mentally ignores the macrons over |ā| and |ī|, and mistakenly decodes the graph sequence |ai| as the digraph for [ɛ] (Table 12.1). Likewise, ignoring the macron over |ā| in |rāṣhṭrīyᵃ| would result in the graph being interpreted as lax [ə].
The issue of graphematic distinctness, or lack thereof, in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 also came up in the context of γ-consonants.
𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 | Retroflex versus dental γ-consonants
The topic of subdued visual distinctiveness between graph sets in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 also applied to retroflex and dental γ-consonants. In 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒, retroflex γ-stops are distinguished from their dental equivalents only by an underdot diacritic (Table 12.1). As a result, readers of the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text often decoded retroflex γ-stops as dental, and vice versa. Table 13.5 lists a selection of such instances.
| 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 spelling | Nonstandard pronunciation | Standard Sindhi pronunciation (Old & New Varieties) | Gloss |
|---|---|---|---|
| jhanḍo | d͡ʑʱən̪d̪o |
d͡ʑʱəɳɖo |
‘flag’ |
| ṭirango | t̪ɪɾəŋɡo |
ʈɪɾəŋɡo |
‘tricolour’ |
| ṭe | t̪e |
ʈe ~ ʈɾe |
‘three’ |
With reference to 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 |ṭirango| [ʈɪɾəŋɡo] ‘tricolour’ in Table 13.5, its semantic and etymological equivalent in the Hindi language is [t̪ɪɾəŋɡa]. In terms of pronunciations, the Sindhi and Hindi words are identical apart from the initial φ-consonant and the final φ-vowel. It is plausible that the diminutive nature of the underdot diacritic on |ṭ| [ʈ], together with readers’ relatively greater exposure to the Hindi word, resulted in interference. This may explain the realisation [t̪ɪɾəŋɡo] with initial dental [t̪], which is a nonword in both Sindhi and Hindi.
While the case of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 |jhanḍo| [d͡ʑʱəɳɖo] ‘flag’ being interpreted as [d͡ʑʱən̪d̪o] also features the replacement of retroflex φ-consonants with dental ones, it remains intriguing. Here, too, Sindhi [d͡ʑʱəɳɖo] is semantically and phonologically very similar to its Hindi counterpart [d͡ʑʱəɳɖa], differing only in the final φ-vowel. Hence, it is problematic to attribute readers substituting retroflex [ɳɖ] with dental [n̪d̪] entirely to Hindi influence. The pronunciation of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 |ṭe| [ʈe] ‘three’ as [t̪e] appears completely independent of Hindi interference, since the phonological composition of Sindhi [ʈe] bears little resemblance to its Hindi equivalent [t̪in]. Hence, readers’ decoding of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 |ṭ ḍ ṇ| as dental [t̪ d̪ n̪] can only be ascribed to the graphetic indistinctiveness of the retroflex γ-consonants |ṭ ḍ ṇ| from their dental counterparts |t d n|. Moreover, it was nonfluent interviewees who exhibited the above nonstandard pronunciations, ostensibly due to their Sindhi proficiency being inadequate to compensate for perceived graphematic ambiguities.
Miscellaneous observations
The 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 texts contained one instance each of a so-called φ-diphthong. In the 𝚜𝚍-𝙳𝚎𝚟𝚊 text, the word |वग़ैरह| [ʋəɣɛɾəɦᵊ] ‘et cetera, and the like’ was sometimes rendered by older readers as [ʋəɡeɾa], with [ɛ] manifesting as [e]. Likewise, the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 word |qaumī| [kɔmi] often surfaced as [komi] in the speech of older readers. These findings corroborate Bughio’s (2001) observation of [e o] being characteristic of Old Variety Sindhi (§4.3.2).
Also of note was the almost universal realisation of 𝚜𝚍-𝙳𝚎𝚟𝚊 |क़ ग़| [q(ə) ɣ(ə)] as [k(ə) ɡ(ə)], respectively, thereby affirming the merger of the former with the latter in Indian Sindhi (§4.3.2). In contrast, 𝚜𝚍-𝙳𝚎𝚟𝚊 |ड़| [ɽ(ə)] proved problematic for some readers. Two of them, one from the oldest and the other from the middle-aged generation, felt that the word |डोड़| [ɖoɽᵊ] ‘running’ should be written |डोर|. Their suggestion was based on their own pronunciation [ɖoɾᵊ], reflecting the merger of [ɽ] and [ɾ] in their Sindhi idiolect (§4.3.1).
This spelling indicates the pronunciation [
ɖoɽᵊ], but it should be [ɖoɾᵊ], according to my knowledge of Sindhi. (31F).
Likewise, a reader identified the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 spelling |ṭe| [ʈe] as disagreeable. According to him, the word should have been spelt |ṭre|, which better reflected his own pronunciation [ʈɾe] with initial [ʈɾ] (§4.3.1).
This shouldn’t be [
ʈe]. It’s [ʈɾe]. (17M)
A notable phenomenon was that of nonfluent readers sometimes repeating a word in its colloquial pronunciation once they matched it with an entry in their mental lexicon. This was most evident with the word |आहे| [aɦe] ‘is’, which readers with limited Sindhi skills often re-read with the colloquial pronunciation [a(j)e]. This was indicative of the literary pronunciation [aɦe] likely being absent from the reader’s mental lexicon.
Decodability | Lexical decoding
False friends
In the 𝚜𝚍-𝙳𝚎𝚟𝚊 text, a few words bore great resemblance to certain Hindi words, although remaining graphematically and semantically distinct from the latter. Consequently, interviewees, especially those nonfluent in Sindhi, were misled into decoding such 𝚜𝚍-𝙳𝚎𝚟𝚊 words as their Hindi doppelgangers. Table 13.6 provides examples of such instances from the 𝚜𝚍-𝙳𝚎𝚟𝚊 text.
| 𝚜𝚍-𝙳𝚎𝚟𝚊 spelling | Non-standard pronunciation (Hindi-ised) | Standard Sindhi pronunciation | Sindhi gloss | 𝚑𝚒-𝙳𝚎𝚟𝚊 spelling | Hindi gloss | |
|---|---|---|---|---|---|---|
| Old Variety | New Variety | |||||
| इन्हनि | ɪnɦi ~ ɪnɦĩ |
ɪnɦənᶦ |
ɪnɦən |
‘these (oblique)’ | इन्हीं | ‘these very’ |
| कंहिं | kəɦĩ |
kɛ̃ɦᵋ̃ |
kɛ̃ɦ |
‘any (oblique)’ | कहीं | ‘anywhere’ |
| उपाउ | ʊpaj |
ʊpaᶷ |
ʊpa |
‘solution’ | उपाय | ‘solution’ |
A similar phenomenon was observed in the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text. Sindhi-language words that bore graphematic likenesses to their cognates in 𝚎𝚗-𝙻𝚊𝚝𝚗, or in informal Hindi-in-Roman (𝚑𝚒-𝙻𝚊𝚝𝚗), were pronounced with English or Hindi pronunciations rather than Sindhi ones. Table 13.7 provides an overview.
| 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 spelling | Nonstandard pronunciation (Hindi-ised ~ Anglicised) | Standard pronunciation (Sindhi Old Variety) | Gloss |
|---|---|---|---|
| chakarᵘ | t͡ɕəkɾə |
t͡ɕəkəɾᶷ |
‘wheel’ |
| izatᵃ | ɪzzət̪ |
ɪzət̪ᵊ |
‘respect’ |
| āgasṭᵘ | əɡəst̪ ⁓ ɔɡəsʈ |
aɡəsʈᶷ |
‘August’ |
| janⁱvarī | d͡ʑənʋəɾi ⁓ d͡ʑænjʊ(ə)ɾi |
d͡ʑənᶦʋəɾi |
‘January’ |
In Table 13.7, the pronunciations [t͡ɕəkɾə], [ɪzzət̪], [əɡəst̪] and [d͡ʑənʋəɾi] are those of the Hindi cognates of the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 words in question. That said, attributing the pronunciation of |izatᵃ| as [ɪzzət̪] solely to Hindi interference proves tricky. As discussed under the topic of φ-consonant gemination in Sindhi (§4.3.1) [ɪzzət̪] has been cited by certain scholars as a phonologically justifiable Sindhi pronunciation. What is noteworthy, though, is that the pronunciation [ɪzzət̪], with geminate [z], emerged from the spelling |izatᵃ|, with singleton |z|. Also, [ɪzzət̪] and [əɡəst̪] were more evident in the speech of readers nonfluent in Sindhi but at least reasonably fluent in Hindi. This finding, together with readers’ tendency to ignore diacritics, may point to readers’ subconscious tendency to ignore graphematic cues — such as doubled graphs or diacritics — and to prefer whole-word decoding. This hypothesis would explain why readers unintentionally retrieved phonologically similar Hindi pronunciations from their mental lexicons. The pronunciation of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 |janⁱvarī| as [d͡ʑənʋəɾi] was inconsequential, since the Sindhi and Hindi pronunciations of the word are near-identical.
Some readers who were nonfluent in Sindhi but fluent in English read 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 |āgasṭᵘ| and |janⁱvarī| as [ɔɡəsʈ] and [d͡ʑænjʊ(ə)ɾi], respectively, which reflected the Indian English pronunciations of ‘August’ and ‘January’, respectively. One may surmise that the lexical recognition of these English loanwords prompted readers to directly retrieve the corresponding Indian English pronunciations from their mental lexicons. Indeed, for the youngest generation, the Hindi or English-influenced pronunciations of the words in question may well be the standard ‘Sindhi’ pronunciations in their mental lexicons. Consequently, no New Variety pronunciations have been listed in Table 13.7.
The phenomenon of retaining the source pronunciations of loanwords as the standard Sindhi pronunciation was reflected in a scholar’s objection to the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 spelling |āgasṭᵘ|. In his opinion, the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 spelling should have been more indicative of the Indian English pronunciation [ɔɡəsʈ] rather than the assimilated or Old Variety Sindhi pronunciation [aɡəsʈᶷ].
There are few spellings that are odd, like |āgasṭᵘ| […] It’s pronounced [
ɔɡəsʈ], no? The sound [ɔ] is not conveyed by the line above the letter |a|. (19M)
Although only a few scholars explicitly raised the topic of how to spell English loanwords in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒, it was implicitly alluded to in lay interviewees’ pronunciations of loanwords in the 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 texts.
Loanwords
The subject of how to spell English loanwords in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 came up constantly, albeit subtly, when interviewees read the 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 texts. The 𝚜𝚍-𝙳𝚎𝚟𝚊 text contained four English loanwords, ‘hockey’, ‘football’, ‘volleyball’ and ‘cricket’, transcribed |हाकी|, |फ़ुटबालु|, |वालीबालु| and |क्रिकेट|, respectively. All interviewees fluent in English read out these words with their (Indian) English pronunciations, although many of them paused or had false starts when initially encountering these words. It is possible that the 𝚜𝚍-𝙳𝚎𝚟𝚊 spellings in question, which reflected the assimilated or Old Variety Sindhi pronunciations [ɦaki], [fʊʈᵊbalᶷ], [ʋalibalᶷ] and [kɾɪkeʈᵊ], were a mismatch with the readers’ own — anglicised — pronunciations of these words. Only two readers exhibited the Old Variety pronunciations of the four words in question, all of whom were fluent in Sindhi but nonfluent in English.
The 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text, too, contained several English loanwords, of which |August| and |January| have already been discussed. Other English loanwords present in the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 text were ‘school’, ‘college’ and ‘office’. However, in the text, all of them manifested in their oblique or declined Sindhi forms, with the suffix [ənᶦ] appended (Table 4.8). Details of the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 spellings in question are shown in Table 13.8.
| 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 spelling | Anglicised pronunciation | Standard pronunciation (Sindhi Old Variety) | Gloss |
|---|---|---|---|
| iskūlanⁱ | skulən |
ɪskulənᶦ |
‘schools (oblique)’ |
| kālejanⁱ | kɔlɨd͡ʑən |
kaled͡ʑənᶦ |
‘colleges (oblique)’ |
| āfīsanⁱ | ɔfɪsən |
afisənᶦ |
‘offices (oblique)’ |
Regardless of spoken Sindhi competence, readers found the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 spellings in Table 13.8 to be highly unintuitive due to the novelty of the graphematic form. Most readers required prompts to help them proceed, following which those fluent in English typically read aloud the root words with their Indian English pronunciations. The observed difficulty in decoding the spellings in Table 13.8 tacitly thrust into the spotlight the dilemma of how to spell English-origin lexical roots with Sindhi-specific grammatical inflections in 𝚜𝚍-𝙻𝚊𝚝𝚗, irrespective of subvariant or orthographic module. It was also reminiscent of graphematic inertia in 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 among homoscriptal loanwords in those writing systems (§6.5.4, §7.5.3).
The question of how to spell English-origin loanwords in the Romanized Sindhi system (𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜) was explicitly raised with the three RST interviewees. One member stated their intention to respell English loanwords to conform to the 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 graph inventory and graphematic rules, while also reasonably reflecting their contemporary Sindhi pronunciations. This meant transcribing φ-consonant-final loanwords accordingly, without compulsively appending a final γ-consonant. Thus, English ‘school’ would be spelt |skool| in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜, to reflect the New Variety Sindhi pronunciation [skul]. Such a stance precluded the γ-vowel-final spelling |skoolu|, reflecting the Old Variety Sindhi pronunciation [skulᶷ].
We’re writing it as |skool| […] not |skoolu|. It’s not [
ɦiᶷ mʊ̃ɦɪ̃d͡ʑo skulʊ́ aɦe] ‘This is my school’. (40F)
The issue of how to best spell homoscriptal loanwords in 𝚜𝚍-𝙳𝚎𝚟𝚊 was broached by one scholar. He alluded to the debate on the 𝚜𝚍-𝙳𝚎𝚟𝚊 spellings of Sanskrit-origin loanwords written in 𝚜𝚊-𝙳𝚎𝚟𝚊 with final lax |ि ु| but pronounced in contemporary Sindhi with final tense [i u]. To illustrate his point, he referred to the 𝚜𝚊-𝙳𝚎𝚟𝚊 word |कवि| ‘poet’, which has entered the lexicons of Hindi and Sindhi as a loanword. In both languages, the loanword is pronounced [kəʋi], with a final tense [i]. However, written 𝚑𝚒-𝙳𝚎𝚟𝚊 retains the source spelling |कवि|, with final |ि|. As described in Section 7.5.3, all instances of final |ि| in 𝚑𝚒-𝙳𝚎𝚟𝚊 are decoded as tense [i]. Consequently, the spelling |कवि| in 𝚑𝚒-𝙳𝚎𝚟𝚊 unambiguously reflects the pronunciation [kəʋi]. In contrast, |कवि| in 𝚜𝚍-𝙳𝚎𝚟𝚊 indicates the pronunciation *[kəʋᶦ], which is a nonword in Sindhi. When asked about respelling the word in 𝚜𝚍-𝙳𝚎𝚟𝚊 as |कवी| to better reflect the Sindhi pronunciation [kəʋi], the interviewee favoured retaining the source spelling |कवि|, arguing that it harmonised with the prevalent 𝚑𝚒-𝙳𝚎𝚟𝚊 spelling.
In Devanagari, we normally write the word [
kəʋi] with a short |ि| at the end. But a colleague of mine says, “No. When writing this word in Devanagari-script Sindhi, you spell it with long |ी| at the end”. Now the problem is this: if a Sindhi child writes [kəʋi] with long |ी|, he’ll spoil his Hindi spelling. (26M; translated)
To sum up, the theme of Hindi interference, whether graphematic-phonological or lexical, was prominent across interviewee cohorts. Also salient was the question of how to spell homoscriptal loanwords. Whereas most lay interviewees did not have strong opinions on loanword spellings, there was considerable diversity in scholarly opinion.
13.2.2 Analysis
The themes on the perceived linguistic fits of 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗 covered their perceived prevalence and ease of reading. Of these, 𝚜𝚍-𝙰𝚛𝚊𝚋 was generally considered to be restricted to the oldest generation, and difficult to learn for nonreaders. In contrast, both 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗 were considered widely known, with the former in India and the latter globally.
With regard to 𝚜𝚍-𝙰𝚛𝚊𝚋, lay interviewees literate in it did not explicitly or implicitly refer to the finer points of its perceived transparency. The only references in this regard were by scholars, primarily on 𝚜𝚍-𝙰𝚛𝚊𝚋 being “disabled” by the common omission of lax vowel diacritics, and on the influence of 𝚊𝚛-𝙰𝚛𝚊𝚋 on Pakistani 𝚜𝚍-𝙰𝚛𝚊𝚋. As described in Section 6.5.4, the omission of subsegmental γ-vowels or variation in their graphematic placement do not significantly affect fluent readers of 𝚜𝚍-𝙰𝚛𝚊𝚋. In fact, the 𝚜𝚍-𝙰𝚛𝚊𝚋 text shown to interviewees was largely free of subsegmental graphs, but proficient readers were able to decode the text without noticeable trouble. In this context, Rabin (1977, p. 155) observes that finer graphematic and orthographic discrepancies in a writing system primarily affect not proficient readers but “marginal and largely inarticulate groups”. Such groups include children and adult learners with a poor grasp of the spoken language. He also notes that:
[t]he educated reader tends to feel that these people should make the same effort that he made himself in order to learn to read fluently, rather than causing him difficulties by changing his ingrained reading habits. Some even resent the very idea that others should have things made easier than they had themselves.
Contrary to Rabin’s observation, however, the 𝚜𝚍-𝙰𝚛𝚊𝚋-literate interviewees generally did not insinuate that the writing system or its conventions were inviolable, stemming from the time and effort they had invested in learning it as children. Put differently, the oldest generation literate in 𝚜𝚍-𝙰𝚛𝚊𝚋 did not display any effort justification (Aronson & Mills, 1959). Rather, they were in favour of using the best possible means to ensure that spoken Sindhi was maintained in the community. However, consensus was lacking on which writing system was best suited for this purpose.
Supporters of 𝚜𝚍-𝙳𝚎𝚟𝚊, both literate and nonliterate in 𝚜𝚍-𝙰𝚛𝚊𝚋, generally justified their stance on two main grounds. First, they claimed that most school children in India were taught Hindi, including its written form of 𝚑𝚒-𝙳𝚎𝚟𝚊, until Class 10. Hence, most Indian Sindhi children would be familiar with the Devanagari script. The underlying assumption here was that school children who were taught English and Hindi would necessarily be proficient in the spoken and written forms of these languages. That is, literacy acquisition seemed to be viewed in binary terms, with someone either literate or not literate in a given writing system. A nuanced take on degrees of proficiency was generally absent. Consequently, 𝚜𝚍-𝙳𝚎𝚟𝚊 supporters did not seem to consider that people who were taught 𝚑𝚒-𝙳𝚎𝚟𝚊 as school children may have been merely alphabeticised (Zeisler, 2006, p. 177), and not proficient in it. Using her personal experience with learning the Thaana script to write the Divehi language (𝚍𝚟-𝚃𝚑𝚊𝚊), Gnanadesikan (2021) highlights the elusive distinction between being alphabeticised and being proficient in a script and its associated writing system:
My personal experience shows that an adult can learn the Thaana script [to read the Divehi language] with a day’s concentrated effort but that fluency […] takes years.
The second argument in favour of 𝚜𝚍-𝙳𝚎𝚟𝚊 hinged on the greater transparency of 𝚑𝚒-𝙳𝚎𝚟𝚊 compared to 𝚎𝚗-𝙻𝚊𝚝𝚗, on which basis supporters felt that 𝚜𝚍-𝙳𝚎𝚟𝚊 would, likewise, be more transparent than a putative 𝚜𝚍-𝙻𝚊𝚝𝚗. This argument betrayed the perception of the Roman script by itself being necessarily opaque, and not the 𝚎𝚗-𝙻𝚊𝚝𝚗 writing system. Exposure to 𝚜𝚍-𝙻𝚊𝚝𝚗 texts on social media and messaging apps that exhibited a high degree of graphematic variability and unpredictably seemed to reinforce the impression of Roman being ‘unphonetic’. Similarly, the Devanagari script per se, rather than 𝚑𝚒-𝙳𝚎𝚟𝚊, was described as ‘phonetic’, on which basis it was justified as more suitable to write Sindhi in. To some extent, 𝚜𝚍-𝙳𝚎𝚟𝚊 supporters exhibited an element of ambiguity aversion (Fox & Tversky, 1995). Given their experience with unpredictable 𝚎𝚗-𝙻𝚊𝚝𝚗 spellings, the idea of 𝚜𝚍-𝙻𝚊𝚝𝚗 seemed to arouse a fear of the unknown. Their experience with the comparatively more transparent 𝚑𝚒-𝙳𝚎𝚟𝚊 seemed to colour their impression of 𝚜𝚍-𝙳𝚎𝚟𝚊 as being phonologically predictable.
The main argument in favour of 𝚜𝚍-𝙻𝚊𝚝𝚗 was its global prevalence. For the RST members, this argument included the Roman script’s availability on most computers and mobile devices worldwide. However, consensus was lacking among interviewees on what the graphematic properties of a conceptual 𝚜𝚍-𝙻𝚊𝚝𝚗 should be like. Some felt diacritics in 𝚜𝚍-𝙻𝚊𝚝𝚗 were useful in indicating phonological nuances, while others dismissed diacritics as unfamiliar and burdensome. Overall, the subjective impression of simplicity was highly regarded as an initial lure, while a visually complex writing system was seen as putting learners off.
Part of the observed aversion to diacritics could stem from a spillover effect, where the diacritic-free nature of 𝚎𝚗-𝙻𝚊𝚝𝚗 influences perception of other Roman-script-based systems. Such a spillover effect has been attested by Karan (2006, p. 119), who states that “Anglophone linguists and people in countries which had been colonized by the British often displayed more reticence to using diacritics”. Nida (1957, p. 130) corroborates Karan’s statement in noting that education officials in former French and Portuguese colonies in Africa had no such reservations concerning diacritics, thanks to the extensive presence of diacritical graphs in the 𝚏𝚛-𝙻𝚊𝚝𝚗 and 𝚙𝚝-𝙻𝚊𝚝𝚗 inventories. Be that as it may, facts are irrelevant when feelings are strong (O’Kane, 2014) that no diacritics is better. In fact, being anti-diacritic, or at the very least, considering them to be optional is not uncommon worldwide. For instance, the Hànyǔ Pīnyīn inventory for Mandarin (𝚌𝚖𝚗-𝙻𝚊𝚝𝚗-𝚙𝚒𝚗y𝚒𝚗) provides for tone markers in the form of graphosubsegmental elements or diacritics on graphosegmental γ-vowels. Yet, government agencies of the People’s Republic of China usually omit tone markers from official documents. According to Wiedenhof (2005, p. 398), “due to the relatively complex graphics of the tone symbols […] [e]ven Chinese passports, despite their obvious identificational function and the high frequency of identical personal names, do not specify Pīnyīn tones”.
The RST members advanced the additional argument that diacritics in 𝚜𝚍-𝙻𝚊𝚝𝚗 were cumbersome to input on computing devices. In an ideal scenario, technology should not dictate to users, and language communities should be free to choose a script, specify a graph inventory and decide on graph-phone correspondences that they feel represent appropriate linguistic, processing and sociocultural fits for their language. However, the reality in minority-language contexts is that technology does often influence decisions on script and graph inventory. This is especially evident with regard to symbols not yet encoded in Unicode. In fact, members of Unicode’s Technical Committee have written that “[i]t should be considered a long-term disservice to users to saddle users with an orthography that does not work on today’s computers” (Anderson, McGowan, Whistler, & Priest, 2023). This position is understandable when one considers that the process of adding new characters to Unicode can take years. Illustrating this point in the context of this book, most commonly-used graphs in the Devanagari repertoire were encoded as Unicode characters in 1991. Yet, the 𝚜𝚍-𝙳𝚎𝚟𝚊 γ-implosives |ॻ ॼ ॾ ॿ| for Sindhi implosives were added only in 2006 (Unicode, 2006, p. 312). In this regard, Karan (2006, p. 234) is — unfortunately — right in opining that “computer technology can be a deciding factor in orthography [and script] implementation”.
Despite popular reticence to diacritics, the fact remains that some form of graphematic augmentation would be necessary to enable a biunique, or at least transparent, 𝚜𝚍-𝙻𝚊𝚝𝚗 writing system. Such augmentation may be graphetic (diacritics) or graphematic (di-, tri- and multigraphs), or a combination of the two. Of these, diacritics in a 𝚜𝚍-𝙻𝚊𝚝𝚗 system may face resistance in graphospheres where the dominant Roman-script writing system is 𝚎𝚗-𝙻𝚊𝚝𝚗. By that argument, a 𝚜𝚍-𝙻𝚊𝚝𝚗 system featuring digraphs should be theoretically palatable to users in an 𝚎𝚗-𝙻𝚊𝚝𝚗-dominated graphosphere, since 𝚎𝚗-𝙻𝚊𝚝𝚗 employs several digraphs. That said, digraphs may not be accepted as a blanket replacement for diacritics, as illustrated by the dilemma on how to graphematically indicate the distinction between retroflex and dental φ-consonants in any 𝚜𝚍-𝙻𝚊𝚝𝚗 system. Since English phonology lacks a retroflex-dental distinction, there exists no precedent in 𝚎𝚗-𝙻𝚊𝚝𝚗 in this regard. In fact, a phonemic distinction between retroflex and dental (or alveolar) stops exists in only 11 percent of the world’s languages, most of which are in South Asia and Australia (Arsenault, 2012). Of these, many are unwritten or use non-Roman scripts. From the limited Roman-script precedents available, Table 13.9 provides a snapshot of how retroflex φ-consonants are graphematically distinguished from dental or alveolar ones.
/t/ |
/t̪ ⁓ t/ |
/ɖ/ |
/d̪ ⁓ d/ |
/ɳ/ |
/n̪ ⁓ n/ |
|
|---|---|---|---|---|---|---|
| Javanese (𝚓𝚟-𝙻𝚊𝚝𝚗) | th | t | dh | d | - | - |
| Somali (𝚜𝚘-𝙻𝚊𝚝𝚗) | - | - | dh | d | - | - |
| Ewe (𝚎𝚎-𝙻𝚊𝚝𝚗) | - | - | ɖ | d | - | - |
| Australianist (𝚊𝚞𝚜-𝙻𝚊𝚝𝚗) | rt | th, t | rd | dh, d | rn | nh, n |
| Australianist (Western Desert) | ṯ | t | ḏ | d | ṉ | n |
| Konkani (𝚔𝚘𝚔-𝙻𝚊𝚝𝚗) | tt | t | dd | dd | nn | n |
| IAST & LSI (𝚖𝚞𝚕-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒) | ṭ | t | ḍ | d | ṇ | n |
Table 13.9 reveals that digraphic conventions for retroflex φ-consonants include prefixing the graph for the corresponding dental or alveolar φ-stop with |r| (𝚊𝚞𝚜-𝙻𝚊𝚝𝚗), suffixing it with |h| (𝚓𝚟-𝙻𝚊𝚝𝚗) or doubling the graph in question 𝟷𝚔𝚘𝚔-𝙻𝚊𝚝𝚗). However, none of these conventions appear to be commonly used in 𝚜𝚍-𝙻𝚊𝚝𝚗, even after taking into account its inherent variation. Moreover, digraphs ending in |h| are often used in unstandardised 𝚜𝚍-𝙻𝚊𝚝𝚗 to denote aspirated stops. Hence, proposing digraphs to graphematically distinguish retroflex and dental φ-stops in 𝚜𝚍-𝙻𝚊𝚝𝚗 users, and require targeted learning.
Besides creating digraphs and augmenting existing rasms, Table 13.9 suggests a third option: introducing a new rasm altogether, as seen in 𝚎𝚎-𝙻𝚊𝚝𝚗 |ɖ|. However, new rasms would also prove unfamiliar to readers and, consequently, increase the learning curve. Sebba refers to this phenomenon as an “increased load on the single letter” (2007, p. 22). This sentiment is echoed by Venezky, in stating that “it may be more difficult to learn to discriminate a totally new symbol from an existing repertoire than it is to learn that a sequence of two existing symbols has a special significance” (1970, p. 260).
Hence, it appears that the issue of inventorial augmentation results in a Catch-22 situation. If digraphs, diacritics or new rasms are (over)used, the resultant inventory may become visually daunting and aesthetically displeasing. On the other hand, if such innovations are restricted or not used at all, the ensuing graph inventory and graph-phone correspondences might be phonologically opaque and increase readers’ cognitive load. Such a system would also pose an additional hurdle for learners nonfluent in the spoken language.
That said, several fluent Sindhi speakers did report reading the 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 texts through the lexical route (Cook & Bassetti, 2005). That is, they reported decoding entire words from context, based on their knowledge of the spoken language (Mattingly, 1992). In the process, they mostly ignored diacritics and other phonological cues in the writing system. On this basis, such readers tended to report that spoken Sindhi fluency was necessary to effectively decode an unfamiliar writing system, such as 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒. As a corollary, diacritics in 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 were deemed superfluous, since fluent readers would anyway decode through the lexical route. At best, diacritics and finer phonological cues in the writing system were thought useful only for beginner readers, whose knowledge of spoken Sindhi was so weak as to leave them with no choice but to read through the phonological route.143 This belief reflects Venezky’s (1970) observation of the different purposes served by a writing system for beginner and advanced readers. Venezky notes that “for the beginner, the orthography [i.e., writing system] is needed as an indicator for the sounds of words (inter alia), but for the advanced reader, meanings, not sounds, are needed” (p. 260).
In brief, 𝚜𝚍-𝙻𝚊𝚝𝚗 in general, and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 in particular, was generally considered to be useful primarily for learners nonfluent in spoken Sindhi. However, for such nonfluent learners, Sindhi would effectively qualify as a second language (Guérin, 2008; Seifart, 2006). Any proposed 𝚜𝚍-𝙻𝚊𝚝𝚗 orthography, therefore, should ideally be designed for a target group of L2 learners, and not for fluent speakers. Such efforts would also need to take into account how much pedagogical instruction the average Sindhi-language learner would likely receive in practice. Although reading has been demonstrated to be a highly useful second-language-learning tool (Schneider, 2011, p. 195), opportunities for structured reading instruction in Sindhi in India and the diaspora are few. This follows from the low demand for formal schooling in the language among Indian and diasporic Sindhis (§4.5.2). Consequently, acquiring and using 𝚜𝚍-𝙻𝚊𝚝𝚗 — as well as 𝚜𝚍-𝙳𝚎𝚟𝚊 — would be driven largely from personal motivation and community efforts.
If the spread of 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗 is likely to result from informal incentivisation than from formal educational requirements, a suitable writing system for Sindhi in such a scenario should ideally be easily acquirable (Cook & Bassetti, 2005; Lüpke, 2011; Karan, 2006). In this regard, Bird opines that designing a writing system, including an orthography, should take into account:
how steep a learning curve the speakers will tolerate, and on the available pedagogical resources, […] In some settings, the average person may have very limited opportunities for study. New readers may not persevere with a deep orthography long enough, […] So the reward of being able to read may not come early enough to justify the effort. A shallow orthography may be preferable here, […]
Applying Bird’s observation to the context of 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗, a shallow or transparent writing system would permit beginner readers to decode graphematic units fairly accurately (Frost & Katz, 1992). While it is true phonological decoding pronunciation does not imply comprehension of meaning, it is also true that the psychological “reward of being able to read” described by Bird above might act as motivation for learners to persist with their efforts.
The phenomenon of L2 learners benefiting from a transparent writing system has also been noted by Smalley (1964, p. 55) in his classic paper on orthography design. He notes that native speakers of a language may not require phonological nuances to be explicitly represented in the writing system. However, “foreigners” or L2 learners of the language would greatly benefit from such graphematic assistance. More importantly, Smalley stresses the requirement for a lesser-learnt language to have a transparent writing system, stating pointedly that:
[t]he reason we can get along with five vowel symbols in English for our horribly complex vowel system is that we can force children to stay in school long enough to teach them.
One may argue that standardisation — including orthographisation — is not paramount in the initial stages of graphematic development, and that idiosyncratic variation in spelling should be tolerable. However, the ability to decode inconsistent spellings presupposes a reasonable command over the spoken language, and consequently, an ability to read through the lexical route. In the context of Sindhi in India and the diaspora, only the oldest generation fulfils this criterion. At the same time, this generation sees no need to read in 𝚜𝚍-𝙳𝚎𝚟𝚊 or 𝚜𝚍-𝙻𝚊𝚝𝚗, since most of them are literate in 𝚜𝚍-𝙰𝚛𝚊𝚋. On the other hand, the implied target group for 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗 is the youngest generation of Indian and diasporic Sindhis. This generation often has limited to poor abilities in spoken Sindhi and, therefore, is unable to reliably decipher variant spellings in 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗. It follows from the above that a target group with limited skills in spoken Sindhi would benefit the most from a transparent writing system that permits easy decoding through the phonological route. As seen in the context of 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊 or even historical 𝚜𝚍-𝚂𝚒𝚗𝚍, graphematic and spelling variation may not pose a significant processing hurdle to fluent speakers and experienced readers, but they do for nonfluent speakers and beginner readers. This is a hindrance that lesser-learnt languages, like Sindhi in India and in the worldwide diaspora, can ill afford.
At this juncture, one may put forward the counterargument that attempting to learn a new writing system would inevitably entail a learning curve, even when the system is for one’s “native” language (Bunčić, 2016a, p. 18). Along these lines, Desai (2002, p. 185) states that “learning a language is natural to some extent, [but] learning a script [i.e., a writing system] is essentially an artificial and planned activity”. While this line of reasoning cannot be faulted, it is also desirable that the learning curve for acquiring a new writing system should be kept as flat as possible, especially if it is not part of formal education.
If the guiding principle is to reduce the learning curve in 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗, graph-phone correspondences and spellings should reflect, to the extent possible, practices and conventions that potential learners would already be familiar with. Against this background, one may recommend that the graphematic or canonical models (Sebba, 2007, p. 59; Smalley, 1964, p. 65) for 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗 be 𝚑𝚒-𝙳𝚎𝚟𝚊 and 𝚎𝚗-𝙻𝚊𝚝𝚗, respectively. This line of thinking is reflected in the RST’s adherence where possible to 𝚎𝚗-𝙻𝚊𝚝𝚗 graph-phone correspondences in designing their 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜 system. However, throwing a sizable spanner in the works is the subtle generational shift in Sindhi phonology, or evolution in chronolect. Considering that the creators of pedagogical material in 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗 tend to be Old Variety Sindhi speakers, they tend to model their writing on their own spoken chronolect. The resulting graphematic forms may disagree with New Variety speakers’ idiolects, and lead to them mispronouncing or misinterpreting words. The RST’s experience with children interpreting what was intended to be reduced lax [ᶦ ᶷ] as tense [i u] succinctly illustrates the pedagogical implications that the chronolectal divide can have. In turn, this increases the need for targeted didactic instruction and practice. However, implementing such targeted interventions is impeded by the fact that Sindhi is not a language that students or parents in India and in the diaspora are willing to devote considerable time and money towards. As a result, any writing system for the language that requires effort to acquire will prove suboptimal.
On the question of phonological decoding, interviewees’ attempts at reading the various Sindhi-language texts, especially 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒, reveal that the chief reasons for inauthentic phonological decoding were visual graphematic underdifferentiation, inconspicuousness and likeness (Siegel, 2010). In 𝚜𝚍-𝙳𝚎𝚟𝚊, the underdifferentiation of reduced [ᶦ ᶷ] and full [ɪ ʊ] in writing led to readers, especially those nonfluent in Sindhi, pronouncing the former pair as the latter. In word-final position, lax [ᶦ ᶷ] were pronounced as tense [i u] due to 𝚑𝚒-𝙳𝚎𝚟𝚊 influence. Related to graphematic underdifferentiation was that of subtle or obscure graphetic distinction between graphs, due to which 𝚜𝚍-𝙳𝚎𝚟𝚊 |ज़| [z(ə)] was often decoded as |ज| [d͡ʑ(ə)]. Although the 𝚜𝚍-𝙳𝚎𝚟𝚊 text did not contain any instances of |ङ| [ŋ(ə)], it could be speculated that this phonogram might be confused with |ड| [ɖ(ə)] or |ड़| [ɽ(ə)] based on visual similarity. Also, readers for whom |ड़| [ɽ(ə)] varied freely with |र| [ɾ(ə)] found certain spellings unrepresentative of their own idiolectal pronunciations. In 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒, reduced [ᵊ ᶦ ᶷ] were graphematically distinguished from full [ə ɪ ʊ] by using superscript graphs for the former, which aided decoding. However, the fact that lax [ə ɪ ʊ] and tense [a i u], as well as dental [t̪ d̪ n̪] and retroflex [ʈ ɖ ɳ], were graphematically distinguished from each other by visually inconspicuous diacritics often led to readers confounding one for the other. On occasion, ignoring diacritics led to the inauthentic interpretation of graph sequences as digraphs, such as |āī| [a.i] being decoded as |ai| [ɛ].
Also impacting decoding performance was crosslinguistic interference or linguistic transfer (Odlin, 2003). In some instances, readers inadvertently applied the graphematic rules of 𝚑𝚒-𝙳𝚎𝚟𝚊 to 𝚜𝚍-𝙳𝚎𝚟𝚊, or 𝚎𝚗-𝙻𝚊𝚝𝚗 to 𝚜𝚍-𝙻𝚊𝚝𝚗 (Cook & Bassetti, 2005; Jarvis & Pavlenko, 2008). The unintentional application of graphematic rules from a homoscriptal writing system is a common occurrence, and is well-known in Second Language Acquisition (SLA) studies. From a graphematic perspective, a relevant and useful concept is that of the native script effect, defined by Gnanadesikan (2021) as:
the relationship and interaction between such a first script or scripts (S₁) and a script or scripts learned later (S₂) is similar to the relationship and interaction between a first language or languages (L₁) and language(s) learned later in life (L₂).
Despite focusing on scripts, the concept of native script effect proves useful in explaining the phenomena under discussion. Since a writing system has been defined as the combination of a language and script, it follows that the combination of, say, an L1 and S1 may be described as a WS1. Thus, a WS1 may be defined as a conceptual native writing system, comprising at least a graph inventory along with their linguistic values in that system. If present, an orthographic module may also be included. A theoretical native writing system effect appears to offer a neat explanation to the phenomenon of graphematic interference. For instance, people with English as their L1 and the Roman script as their S1 would have 𝚎𝚗-𝙻𝚊𝚝𝚗 as their WS1. When such people learn French as an L2 and, with it, 𝚏𝚛-𝙻𝚊𝚝𝚗 as their WS2, they may decode their WS2 by unintentionally applying the rules of their WS1 (Woore, 2013). Various other studies attest this phenomenon (Bassetti, Escudero, & Hayes-Barb, 2015; Cook & Bassetti, 2005; James, Schofield, Garrett, & Griffiths, 1993; Jarvis & Pavlenko, 2008; San Francisco, Mo, Carlo, & Snow, 2006). Unsurprisingly, the interference caused by the native graphematic effect is more evident in beginners’ attempts at decoding the WS2 than in advanced users’ attempts. This is affirmed by Hedgcock and Ferris when they state that:
[L2 readers] tend to use some L1 processing when they try to read the L2, although the tendency influences beginning L2 reading more than advanced L2 reading.
Applying these concepts to interviewees’ reading performance, the WS1 for most interviewees was either 𝚑𝚒-𝙳𝚎𝚟𝚊 or 𝚎𝚗-𝙻𝚊𝚝𝚗. Accordingly, the inadvertent retrieval of Hindi or English pronunciations or lexical items when decoding the 𝚜𝚍-𝙳𝚎𝚟𝚊 or 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 texts could be attributed to a hypothetical native writing system effect. The native script effect outweighing the high levels of transparency inherent in 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 may also explain why graphematic transparency per se proved inadequate in guiding readers towards appropriate decodings.
If future research proves the hypothesis of a native writing system effect to be tenable, it has implications for teaching literacy in lesser-studied languages and writing systems, for which learner motivation may be ephemeral. Given that 𝚜𝚍-𝙳𝚎𝚟𝚊 continues to have areas of graphematic ambiguity and a generally accepted 𝚜𝚍-𝙻𝚊𝚝𝚗 system is still to emerge, supporters of these writing systems may want to consider how graphematic transparency per se interacts with the native writing system effect. As alluded to by Interviewee #38M, if Sindhi [t͡ɕ] were to be indicated in 𝚜𝚍-𝙻𝚊𝚝𝚗 using the Roman-script graph |c|, learners with 𝚎𝚗-𝙻𝚊𝚝𝚗 as their WS1 may decode |c| as [s] or [k] due to the effect of their WS1. Such interference may result in 𝚜𝚍-𝙻𝚊𝚝𝚗 being perceived as having a steep learning curve, even when its graph-phone correspondences are transparently and consistently applied. Moreover, the larger the divergence between the graph-phone correspondences in the WS1 and WS2, the greater the mental effort required by the learner. This may impact on learner motivation, which, as mentioned earlier, is detrimental in the context of lesser-learnt languages. Hence, writing systems for lesser-learnt languages have the unenvious task of being transparent on the one hand, but also familiar to the learner on the other (Schneider, 2016, p. 24). Understandably, walking this conceptual tightrope is often fraught, if not impossible. Adding to the mix is the question of how to spell loanwords from homoscriptal languages, particularly when declined according to the target language’s grammar.
13.2.3 Summary
Interviewees in the study had varying views on the perceived prevalence of the Arabic, Devanagari and Roman scripts in question. However, widespread prevalence of a script did not necessarily translate into interviewees favouring that script for Sindhi. In addition, support for using a particular script to write Sindhi did not mean that interviewees were able to satisfactorily decode a Sindhi text written in that script. Moreover, influence from other writing systems the interviewee was literate in was evident in their decoding of Sindhi texts.
Although exploratory and preliminary in nature, the observations so far indicate certain evident patterns, particularly concerning the linguistic fits of 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒. These findings form a useful launch pad for further fine-grained research on what kinds of graphs and graph-phone conventions may offer the best balance between transparency and familiarity, especially for learners nonfluent in spoken Sindhi. More importantly, the findings indicate how a writing system that comprises a good linguistic fit in theory may not always result in a good processing fit in practice (Meletis, 2020), due to the native writing system effect. In this regard, those interested in Sindhi-language pedagogy and literacy instruction would do well to bear in mind Pike’s statement, that:
the science of forming an orthography [i.e., writing system] should by no means be considered limited to the science of linguistics; rather it must be emphasized again and again that the social sciences and psychology must play their part, else an orthography may result which will be vehemently repudiated by the people.
The perceived sociocultural fits of 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚜𝚍-𝙻𝚊𝚝𝚗 are described and analysed in the following section.
13.3 Perceived sociocultural fits
The Global theme of sociocultural fit touches upon interviewees’ statements on the impressionistic cultural symbolism of the Arabic, Devanagari and Roman scripts, and the perceived practicality of using each of them for the Sindhi language. These statements are further classified based on the Organising themes of semiotic and pragmatic suitability — namely the mental image interviewees had of the Arabic, Devanagari and Roman scripts, and the need and usefulness of writing Sindhi in each of them.
13.3.1 Organising and basic themes
Semiotic suitability | Indexicality
For all interviewees, Sindhi when written in the Arabic, Devanagari and Roman scripts was emblematic (Agha, 2007) of certain notions. Although interviewees were not always able to explicitly identify the semiotic values they attributed to each of the three scripts, their underlying mental associations were usually betrayed by and clearly discernible from their statements.
Geocultural values
Reference to the Arabic script as the “Sindhi script” was common. This term was particularly evident in the statements of the nine lay interviewees literate in it.
Whatever Sindhi I’ve read is in the Sindhi script. (35F; translated)
Despite promoting a Roman-script-based writing system for Sindhi, the RST members were also not averse to terming Arabic the “Sindhi script”.
In 1853, what the Sindhi script was at that time, today Romanized Sindhi is in that position. (40F)
The term “Sindhi script” was also commonly used by lay interviewees nonliterate in 𝚜𝚍-𝙰𝚛𝚊𝚋 but nominally supportive of it, due to exposure to it in their formative years. Such lay interviewees were typically unaware of the graphosociolinguistic history of the Sindhi language.
It’s not difficult to transliterate the Sindhi script into Devanagari. (31F)
If you teach it in the original Sindhi script, or Devanagari, you might attract fewer people […] but they will exit that training being taught proper Sindhi. (09M)
Notwithstanding the conceptual distinction between writing system and script, the indexical value of Arabic as the “Sindhi script” was common among interviewees who had at least some exposure to 𝚜𝚍-𝙰𝚛𝚊𝚋 and were not ideologically opposed to it. The phenomenon of 𝚜𝚍-𝙰𝚛𝚊𝚋 being emblematic of the Sindhi language is discussed in detail later in this section.
Conversely, interviewees who were scholars, and consequently aware of the various writing systems historically used for Sindhi, used the terms “Arabic script” or “Persian script”.
I don’t use Devanagari because I don’t need to. Whatever I’ve written, I’ve written in Arabic. (43M; translated)
In the schools of the Sadhu Vaswani Mission {a Pune-based Sindhi spiritual organisation} […] they are changing over to Devanagari script because they can’t find teachers who know the Persian script. (36F)
In contrast, the Devanagari script carried the indexical value of “Indian script” or “national script”, particularly for those in favour of it.
Definitely, one hundred percent, the script for Sindhi should be Devanagari. Because it’s an Indian script. Sanskrit is in it, Marathi is in it, so Sindhi should be in it. (15M; translated)
Interviewees who backed 𝚜𝚍-𝙻𝚊𝚝𝚗 ascribed to the Roman script the indexical value of “world script” or “global script”. This was especially common among interviewees residing in the Sindhi diaspora.
Outside India, romanised Sindhi is the right way to go. It’s relevant, it’s worldwide. (45M)
There’s nothing like writing Sindhi in a script which is very well understood around the world. (49M)
In sum, the most common semiotic associations of the Arabic, Devanagari and Roman scripts were ‘Sindhi’, ‘Indian’ and ‘global’, respectively.
Religiocultural values
As mentioned earlier in this section, scholars understood that 𝚜𝚍-𝙰𝚛𝚊𝚋 was just one of Sindhi’s several historical writing systems. However, for a couple of interviewees in this cohort, the Arabic script had an association with Muslim or Islamic culture.
When we let go of our own script and adopt the script of another — the Arabic script — it means we’re adopting their culture as well […] This is like a religious conversion. (25M; translated)
The Arabic script is associated with Muslim culture. And Sindhi was written in the Arabic script because we were mainly dominated by Muslim culture. (46M)
Similar views were expressed by two younger interviewees nonliterate in 𝚜𝚍-𝙰𝚛𝚊𝚋. One declared that her inability to read 𝚜𝚍-𝙰𝚛𝚊𝚋 contributed to its semiotic value in her eyes.
I would think that Sindhi in the Arabic script is a Muslim kind of language, Arabic. It looks the same to me […]. You may say that the Sindhi language is different and the Arabic language is different and Urdu is different. But, to me, they’re all the same. (13F)
The other interviewee believed that the relative prevalence of the Arabic, Devanagari and Roman scripts in India made a difference to their perceived image.
These two, Roman and Devanagari, are commonly used in India. But this one, the Arabic script is not, so it would be considered a Muslim or Arab thing. Devanagari would be considered as something local. And Roman would be something global. (17M)
One of the two interviewees raised in Malaysia noted that Malay, too, was previously written using the Arabic script, popularly known as Jawi. On this basis, she indicated a conceptual dissociation between the Arabic script and the language or content it was used to write.
I know Sindhi writing also looks like Arabic. But it could be the Quran, it could be our Sukhmani Sahib […] It could be Jawi, too. (14F)
Of the 18 interviewees literate in 𝚜𝚍-𝙰𝚛𝚊𝚋, five favoured 𝚜𝚍-𝙳𝚎𝚟𝚊 on ideological grounds. Some of them expressed their views as ‘bringing back Devanagari’. Their justifications typically hinged on Devanagari being the indigenous script of Sindhi before it was allegedly displaced by invaders, namely “Muslims” and the British.
People say, before Muslims came to India, 500 years ago, what was the Sindhi language written in? It was written in Devanagari. (36F)
Earlier, Sindhi was only written in Devanagari. There was no Arabic script. When we know that the British came and changed it to Arabic, why can’t we go back to Devanagari again? (47M)
Allegations of the British purportedly sidelining of 𝚜𝚍-𝙳𝚎𝚟𝚊 and instituting 𝚜𝚍-𝙰𝚛𝚊𝚋 was justified by citing the British policy of divide et impera ‘divide and conquer’.
Before 1843, the script used for Sindhi was Devanagari. That’s on record […] But at the same time, there were supporters of the Arabic script. And in 1843, the British conquered Sindh. So the British, as per their policy of Divide and Rule […] introduced the Arabic script for Sindhi. (26M; translated)
For two of the interviewees who believed that the British had deliberately done away with Devanagari-script Sindhi, the Arabic script did not necessarily index Muslimness. However, the Arabic script did not qualify as the indigenous script of Sindhi either. Rather, it was Devanagari that indexed indigeneity.
A couple of Devanagari supporters bolstered their claim by alluding to the seals of the Indus Valley Civilisation (§3.1, §5.1) Regardless of these seals not yet being conclusively deciphered, the two interviewees asserted that the seals represented an earlier form of Devanagari.
One thing is clear, that the original script of the Sindhi language is related to the Indus Valley script […] When history says that Devanagari is our script, then why shouldn’t we write in that script. (25M; translated)
At the same time, supporters of Devanagari who saw Arabic as a “Muslim” or “foreign” script, did not necessarily consider Devanagari to be a “Hindu” script. Rather, their emphasis was on the supposed indigeneity of Devanagari to the Sindhi language in particular. Along similar lines, none of the 50 interviewees made any association of the Roman script with Christianity. At most, four interviewees alluded to the “Western” nature of Roman.
I won’t view it as Christian. Western? Yes. But Christian? No. (11M)
Compared to the Arabic and Devanagari scripts, Roman was almost entirely devoid of religious associations. In fact, its presence in India as well as in Western countries caused it to be occasionally characterised as “neutral”.
I think Roman is the most neutral. ’Cos we’re so used to seeing it everywhere. (04M)
Notably, 𝚜𝚍-𝙻𝚊𝚝𝚗 had the support of two interviewees who revealed they had been members of the right-wing Hindu nationalist group Rashtriya Swayamsevak Sangh (RSS; ‘National Volunteers’ Association’), one of whom was openly anti-Muslim and anti-British in his outlook. This further affirmed that Roman was largely seen as religiously nonaligned.
The question of writing Sindhi in Roman is about language. Where does religion come into the picture? (33F; translated)
In summary, the Arabic script had the semiotic value of “Muslim” in the eyes of a few interviewees, both literate and nonliterate in Perso-Arabic. Devanagari, on the other hand, was seen by its supporters as the “native” Sindhi script, but not as a “Hindu” script. Likewise, no interviewee associated the Roman script with Christianity, although it did signify “Western” for a few.
Legitimacy
Of the 26 interviewees who did not categorically support 𝚜𝚍-𝙻𝚊𝚝𝚗, 24 alluded to the stop-gap image the writing system had in their minds. Even if otherwise convenient, 𝚜𝚍-𝙻𝚊𝚝𝚗 was seen as a makeshift candidate, and not a formal system.
The advantage of writing Sindhi in Roman is, you can communicate with people, via text or via email in your own language […] but it’s not really preserving the language as such […] in its original form. (02M)
Interviewees frequently expressed their perception of 𝚜𝚍-𝙻𝚊𝚝𝚗 being inappropriate in abstract and subjective terms, such as lack of “flavour”.
I think the English or Hindi script would not be advisable, because the flavour would be lost. (29M)
Whereas a few interviewees’ dislike of 𝚜𝚍-𝙻𝚊𝚝𝚗 stemmed from doubts on its phonological accuracy, others conceded that a phonologically robust 𝚜𝚍-𝙻𝚊𝚝𝚗 system could be theoretically designed, Nonetheless, they remained averse to the idea of 𝚜𝚍-𝙻𝚊𝚝𝚗 on instinctive grounds.
A Sindhi child may read Sindhi in Roman properly. But still, it won’t seem like Sindhi. It doesn’t have flavour. It won’t make an impression on the child. (26M; translated)
In the eyes of such interviewees 𝚜𝚍-𝙻𝚊𝚝𝚗 seemed to lack the intangible propriety and respectability epitomised by 𝚜𝚍-𝙰𝚛𝚊𝚋 and, for some, 𝚜𝚍-𝙳𝚎𝚟𝚊. Others admitted that no system could be completely transparent. Curiously, many still favoured the “original” writing system of Sindhi, namely 𝚜𝚍-𝙰𝚛𝚊𝚋, despite being nonliterate in it and being completely unaware of its phonological transparency.
Phonetics is something you’ll never get a hundred percent of […] but the feel of the language essentially flows much better in the script in which it’s in originally. (05M)
The fact that interviewees had only seen 𝚜𝚍-𝙻𝚊𝚝𝚗 used as a quick-fix solution to represent Sindhi in writing on the internet and messaging apps gave 𝚜𝚍-𝙻𝚊𝚝𝚗 — including the Roman script — the indexical value of “inauthentic”.
If there was ever an attempt to popularise the Roman script for Sindhi, it would still be used only in a very casual manner. I don’t know why! Maybe because it loses a level of authenticity, since it’s not in the original script. (12F)
In general, the convenience of a hypothetical 𝚜𝚍-𝙻𝚊𝚝𝚗 was widely acknowledged. Regardless, 𝚜𝚍-𝙻𝚊𝚝𝚗’s perceived lack of phoneticity, coupled with exposure to it only in informal contexts, meant that it had an image of informality and inauthenticity to almost half the interviewees in this study. To them, the prior mental associations of the Sindhi language with the Arabic script and, to a lesser extent, Devanagari, gave 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 legitimacy. These rigid mental associations between language and script are discussed further under the basic theme of ‘Linguistic purity’.
Semiotic suitability | Linguistic purity
Associations of language and script
Several lay interviewees were unable to clearly distinguish the Devanagari script from the Hindi language, and the Roman script from the English language. To them, the idea of writing Sindhi in Devanagari or Roman was effectively writing Sindhi in “Hindi” or “English”, respectively.
When I look at this — Sindhi written in Devanagari — my brain is looking for Hindi. (28M)
I’m connecting this here — Sindhi in Roman — to English […] So, when I read it, the pronunciations are how it would be pronounced in English. (12F)
Aside from affirming the presence of a native graphematic effect, interviewees’ rigid mental associations of a particular script with a particular language sometimes hindered their ability to clearly articulate their views. As a result, some of their statements were conceptually muddled and hard to comprehend.
Not everybody is very familiar with English […] we think everybody knows English, but there will be people who won’t know it well. And for them to convert English to Sindhi will be difficult […] English works for people like us, but what about Hindi speakers? (31F)
The difficulty in conceptually separating language and script was indicative of the rigid associations between the two in the Indian context, where a particular script is often considered integral to a particular language. This mindset was particularly evident among the eight lay interviewees supportive of retaining and reviving 𝚜𝚍-𝙰𝚛𝚊𝚋.
Sindhi has got its own script. So, it should be the same script — the original Sindhi script — that should be used and brought back amongst the younger generation. (29M)
The eight lay interviewees supportive of 𝚜𝚍-𝙳𝚎𝚟𝚊 also exhibited a similar mindset of language-script association, albeit with a slight difference. They justified their using 𝚜𝚍-𝙳𝚎𝚟𝚊 on the basis that Sindhi was an “Indian” language and Devanagari an “Indian” script.
At least we can say that Devanagari is ours, an Indian script, right? (15M; translated)
We’re Sindhi. If we don’t know the Arabic script, then we should at least know Devanagari. We’re Indians. (21F; translated)
Scholars among the interviewees were clear that there was no intrinsic link between language and script.
Whether transcribed in the IPA, or in Devanagari, on in the Arabic script — these are simply external manifestations of a language. They’re not the language itself. (46M)
Such awareness was lacking among to lay interviewees, who were, for the most part, unable to disengage an established language-script pair in their minds. Consequently, this mindset contributed to the perceived inauthenticity of 𝚜𝚍-𝙻𝚊𝚝𝚗.
This Roman-script Sindhi will always be used as an alternative. It’ll never become Sindhi […] everybody knows this is not Sindhi. It’s not like this will be accepted one day as official […] But it’s a crutch, it’s a tool for me to be able to learn Sindhi. (11M)
The rigid associations of script with language meant that the prospect of dissociating the two was often met with resistance.
Resistance to induced changes
Eleven interviewees — eight of them 𝚜𝚍-𝙰𝚛𝚊𝚋 supporters — implied that natural evolution of the language and script were acceptable, but artificially introduced changes were not. Three interviewees explicitly described any targeted script change as “bastardisation”.
If you’re gonna use another script, like Roman, then that element of English will somehow jump in […] you’re trying to bastardise the language […] it’s a tough one. Because you’re trying to save the language. But at the same time, you’re trying to change the language. (07M)
Who in their right mind would want to, for want of a better word, let me just say bastardise their language? When I went to French classes, we learnt it properly. When I went to German class, I learnt it properly. Why are we changing the rules for Sindhi? (27F)
Of the eight 𝚜𝚍-𝙰𝚛𝚊𝚋 supporters resistant to induced changes, only one was literate in it. The 17 other interviewees literate in 𝚜𝚍-𝙰𝚛𝚊𝚋 were more open to changes in the written manifestation of Sindhi, as long as such changes contributed to the language’s maintenance. Openness to change also sometimes resulted in well-meaning but potentially contentious suggestions. To simplify literacy acquisition, two interviewees literate in 𝚜𝚍-𝙰𝚛𝚊𝚋 proposed eliminating graphs for the φ-implosives from all of Sindhi’s writing systems.
I would take away those sounds, like [
ɓə]. In Sindhi, [ɓə] means ‘two’. But even if you say [bə], the meaning is still clear. And it simplifies writing. (42M)The simpler, the better. You can sacrifice sounds. You cannot sacrifice learners of the language. What’s the priority? What’s important is not that sounds remain. What’s important is that speakers remain. (43M; translated)
Most scholars were open to graphematic modifications in 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊, but only to the extent that they were linguistically justified.
When transliterating Sindhi from the Arabic script to Devanagari or Roman, I won’t distinguish the various letters for [
z]. Because the sounds of those letters have merged with each other […] But if I won’t write vowel signs at the end of words, then the entire grammatical structure falls apart. (38M)
To scholars, eliminating graphs, whether segmental or subsegmental, was acceptable only if their associated linguistic values in spoken Sindhi had naturally disappeared or become indistinct over the course of time. Thus, for most interviewees, be they scholars or laypersons, organic phonological and graphematic evolution was tolerable, but contrived tweaking was not. That said, while scholars’ opposition to forced changes had a linguistic basis, laypersons’ opposition to changes largely stemmed from the symbolic value associated with existing conventions.
Symbolicity
Thirteen interviewees, including the three RST members, were aware that 𝚜𝚍-𝙰𝚛𝚊𝚋 was decreed official by the British in 1853. Significantly, twelve of these interviewees were scholars, and eleven were literate in 𝚜𝚍-𝙰𝚛𝚊𝚋. Knowledge of the fact that 𝚜𝚍-𝙰𝚛𝚊𝚋 had been officially propagated by the British, coupled with literacy in multiple writing systems, had endowed these interviewees with meta
The theory that Sindhi only works in the Arabic script is utter nonsense. (44M)
Apart from these thirteen interviewees, most believed that 𝚜𝚍-𝙰𝚛𝚊𝚋 had been the only writing system historically in vogue for Sindhi. For interviewees nonliterate in 𝚜𝚍-𝙰𝚛𝚊𝚋 but supportive of it, the idea of 𝚜𝚍-𝙰𝚛𝚊𝚋’s supposed primordiality led them to feel that the Sindhi language would be truly preserved only when written in the Arabic script. For such interviewees, the maintenance of originality and tradition was more important than ease of learning.
You should know your language in its original form. It is better. (34F)
I would prefer to go to the original brand of the Sindhi script and language than opt for duplicates like studying it in another script — even in Devanagari, for that matter. (29M)
For supporters of 𝚜𝚍-𝙰𝚛𝚊𝚋, its subjectively superior value was evident in their use of terms such as “authenticity”.
If I knew the Arabic script, I’d obviously like to read Sindhi in that script and not in Devanagari. It’s more authentic, and a little more respectful. (03M)
Graphetically, the Arabic script was the only one whose aesthetic qualities were commented on.
Just looking at this writing, it does look really beautiful, aesthetically. Definitely better than English {laughs}! (01M)
I don’t understand anything in this Arabic-style writing. But aesthetically, it looks beautiful. There is some beauty in the curves and the dots. (05M)
Notably, all those who commented on the visual elegance of the Arabic script were nonliterate in any Arabic-script-based writing system. In contrast, none of the interviewees literate in 𝚜𝚍-𝙰𝚛𝚊𝚋 discussed its calligraphic appearance. Indeed, no interviewee commented on the aesthetics of the scripts they were familiar with.
Two interviewees considered the Arabic script so inextricable from the Sindhi language that they felt the script should remain unchanged even if the language were to die out. To such interviewees, the maintenance of perceived authenticity was more critical than perceived practicality, since they had reconciled themselves with never needing to use the Sindhi language in any form.
If you want to keep the language alive, keep it alive in both forms — spoken, and written in Arabic. That’ll be truer to the spirit of the language […] than for somebody to learn it in the Roman script. With Roman, you’ve learnt a bastardised version of Sindhi. And when it’ll pass on to the next generation, it’ll be an even worse off version {laughs}. (11M)
To interviewees supportive of maintaining 𝚜𝚍-𝙰𝚛𝚊𝚋, especially younger ones, its illegibility to them was immaterial. Rather, it was the script’s emblematicity in the context of the Sindhi language in particular, and Sindhi culture in general, that gave it importance.
This script, Arabic, shouldn’t be abolished completely. Because, as it is, Sindhis don’t have too much of a history or culture or great representation in India. So, that script is something that is clearly Sindhi. (08F)
In summary, interviewees supportive of 𝚜𝚍-𝙰𝚛𝚊𝚋 exhibited a notional separation in their minds between symbolicity and utility. None were desirous of actually becoming literate in 𝚜𝚍-𝙰𝚛𝚊𝚋. Rather, they only wanted to maintain the grapholinguistic status quo, and retain the Arabic script as a Sindhi linguistic and cultural icon. As far as becoming literate in 𝚜𝚍-𝙰𝚛𝚊𝚋 or improving their proficiency in spoken Sindhi were concerned, these were matters of utility. As it turned out, written and spoken Sindhi ranked low in utilitarian terms.
Pragmatic suitability | Availability of content
Irrespective of support for a particular script, the bigger question of written content in the Sindhi language, regardless of script, was categorically brought up by ten interviewees of various ages. Despite increasing levels of 𝚜𝚍-𝙳𝚎𝚟𝚊 publishing in India, interviewees agreed that the majority of Sindhi literature still remained available only in 𝚜𝚍-𝙰𝚛𝚊𝚋. The consequent dearth of material in 𝚜𝚍-𝙳𝚎𝚟𝚊 was alluded to by the RST members as one of its drawbacks.
Devanagari does not have all the literature. All the original literature is still in Arabic. Now the question is, how do we rewrite that in Devanagari. But Devanagari is also limited in terms of awareness. Should we put all our resources into a script for which there is limited awareness among the population? (39M)
In contrast, other interviewees emphasised the creation of new content in Sindhi over transliteration of older content. Two older interviewees fluent in spoken Sindhi noted that the paucity of quality written material was an issue that had plagued the language for a while now. They surmised that adopting a new script would not automatically generate interesting Sindhi-language content.
Not many people write in Sindhi nowadays. The same things are being reprinted over and over. New content is limited, because there’s not many readers for it. (19M)
There has to be interesting literature! The content is important […] I don’t want highly intellectual stuff. But at least something to relate to? I’m tired of coming across the same kind of stuff. (31F)
Overall, eight interviewees explicitly mentioned that Sindhi-language content mattered to them more than the form it appeared in. One interviewee, a scholar, drew attention to the fact that the Urdu language in India was in a grapholinguistic situation similar to that of Sindhi. Like Sindhi, Urdu too has traditionally been written in the Arabic script (𝚞𝚛-𝙰𝚛𝚊𝚋). However, younger Urdu speakers in India are often nonliterate in 𝚞𝚛-𝙰𝚛𝚊𝚋. For this reason, Urdu literature in India is increasingly published in Devanagari (Ahmad, Urdu in Devanagari: Shifting orthographic practices and Muslim identity in Delhi, 2011). In this context, the scholar emphasised that 𝚞𝚛-𝙳𝚎𝚟𝚊 books were popular not because of their script, but their content. On this basis, he opined that those desirous of popularising 𝚜𝚍-𝙻𝚊𝚝𝚗 needed to generate and publish interesting content.
You’ll find that Mirza Ghalib’s poetry is sold more in Devanagari-script Urdu than in Arabic-script Urdu […] So, if you want to introduce Roman for Sindhi, go publish similar books and put them on the market. (38M; translated)
In this sense, the supposed sociolinguistic drawbacks of 𝚜𝚍-𝙳𝚎𝚟𝚊 were also applicable to 𝚜𝚍-𝙻𝚊𝚝𝚗. Four interviewees raised the point that proposing 𝚜𝚍-𝙻𝚊𝚝𝚗 was futile unless considering Sindhi-language content became available in it. More importantly, the content had to be interesting; publishing a 𝚜𝚍-𝙻𝚊𝚝𝚗 text was pointless if the subject matter was dull.
This Sindhi social worker I’d met — he’d written a book or something in Sindhi using Roman script […] I just thought it was, uh, interesting, but I can’t even remember what it was. Which is why I didn’t even bother reading it […] It was not something that I would want to read! (12F)
Conversely, interviewees felt that if the content was evidently engaging it would engender a desire to explore further.
If I know that it’s interesting, I’d read it. Like, many times, I’ve read about the Sindhi deity Jhulelal — what he did, what his name means — but in English. But if there’s something similar of interest to me, written in Sindhi in Roman, I’d read it. (13F)
The paucity of literature in 𝚜𝚍-𝙻𝚊𝚝𝚗 was also acknowledged by the RST members.
The entire literature that we have, we have to start converting it into Roman script. So, we need a big team of enthusiastic writers, producers, translators, who will start transcribing the existing Sindhi literature into Roman script. (39M)
In addition to the eight interviewees who prioritised quality content in Sindhi over its written form, three others emphasised the importance of communication over its packaging. In this regard, they felt the Sindhi language was just one of several options available to them.
Sindhi or any other language — if it’s of interest to me, I read it. (27F)
The basic function of a language is communication. So, if your communication reaches others, how does it matter which language it’s in? (24F)
In short, it was common for interviewees to insinuate that the message was more important than the medium. For these interviewees, the Sindhi language — whether written or oral — was somewhat dispensable as long as they were able to communicate with the intended party. Such a mindset likely influenced interviewees’ motivation in learning to read, write and speak Sindhi.
Pragmatic suitability | Motivation
Community inertia
As mentioned in Section 13.2.1, five interviewees of the middle-aged and oldest generations stated that enthusiasm for the Sindhi language, and consequently for reading and writing it, was greater in smaller towns in India. According to them, urbanised Sindhis’ interest in speaking and transmitting the language, let alone reading and writing it, appeared low.
Revitalising Sindhi is a losing battle, in real terms. Of course, depending on the person, they may make the right noises. But there’s no seriousness. (42M)
It was insinuated that enthusiasm for the language in Indian metropolises was largely restricted to the intelligentsia. Regardless, petty differences among the literati on script issues had resulted in stalemates and, consequently, inaction. The topic of infighting, coupled with reluctance to take a stand on the script issue, was brought up by nine scholars. They alluded to a chronic tendency among the Indian Sindhi intelligentsia to pass the buck, rather than take active steps towards popularising the writing language, be it 𝚜𝚍-𝙰𝚛𝚊𝚋 or 𝚜𝚍-𝙳𝚎𝚟𝚊.
These intellectuals have no logical explanation, and they put the blame onto someone else. “It’s his opinion. They are deciding things. Nothing’s in our hands.” They point fingers at each other. (24F)
The gist of such statements implied an overall unwillingness among the cognoscenti to ruffle feathers, barring a few notable exceptions. Several of them happened to be 𝚜𝚍-𝙰𝚛𝚊𝚋 supporters, and were left-leaning on the ideological spectrum.
Those agitating in favour of the Arabic script were mostly writers and litterateurs […] they were called ‘progressive writers’. They were of a communist bent. (25M; translated)
Unfortunately, most Sindhi intellectuals who openly took a stand on the script issue in post-Partition in India were deceased at the time of writing this book. Prominent names among this outspoken cohort included Kirat Babani (1922–2015; §5.3) and Popati Hiranandani (1924–2005) (Kothari, 2009, p. 163). Hiranandani, one of the few women in an otherwise male-dominated post-Partition Indian Sindhi literary world, was known for her assertiveness, which was unexpected of women at the time (Shivdasani, 2010). Hiranandani’s candid personality was endorsed by an interviewee in narrating an incident involving her and 𝚜𝚍-𝙳𝚎𝚟𝚊 supporter Jairamdas Daulatram (§5.3). The incident underscored the open, sometimes aggressive stances taken on the script issue in the past.
Popati Hiranandani had threatened to gun down Dada Jairamdas Daulatram for supporting Devanagari — we’d become so militant. Now both sides have calmed down. But the script issue remains unresolved, even after so many years. (26M; translated)
In present times, open stance-taking on the script issue has generally disappeared from the Indian Sindhi literary world. Instead, people were more inclined to pass the buck and maintain a tenuous peace, as alluded to earlier. Interestingly, older interviewees who were fluent Sindhi speakers also displayed a buck-passing tendency on occasion. Four such interviewees claimed that it was the younger generation that was not interested in learning Sindhi, implying that their own generation was not to blame for not transmitting the language effectively.
Sindhi children should be attracted to the language. But nowadays they’re not. I always tell my son, “Speak in Sindhi”. (35F; translated)
Only two interviewees attributed any responsibility to their own generation.
The older generation were also responsible for destroying the language {laughs} […] For example, my son-in-law doesn’t speak Sindhi, because his parents didn’t speak it to him. (31F)
Eleven interviewees were critical of the Sindhi community in general, stating that they were not doing enough to maintain their language.
Sindhis are not making any effort to save their language and culture. Because they’re too busy making money! (34F; translated)
In a sense, statements blaming an anonymous third party were indicative of the aforementioned tendency to make the right noises. However, of the interviewees critical of the Sindhi community’s lack of linguistic pride, only one of them, a 𝚜𝚍-𝙳𝚎𝚟𝚊 supporter, was emphatic about teaching the language in written form to youngsters. Even those who were nominally supportive of 𝚜𝚍-𝙰𝚛𝚊𝚋 indicated that they were happy as long as the younger generation were able to speak the language.
Forget that Arabic script. What’s important is that parents and children should at least speak Sindhi at home! (35F; translated)
Statements like these were suggestive of interviewees perceiving the written form of language — at least of Indian languages — as being dispensable.
Predominance of orality
Overall, there was broad consensus on literacy acquisition being the hardest part of learning a language. Having to learn a specialised script for the language was, therefore, an added burden. An interviewee who grew up in Bangalore narrated his travails with having to compulsorily learn the regional language, Kannada, as a school subject until Class 8. Despite being comfortable with spoken Kannada, he struggled with the written form of the language (𝚔𝚗-𝙺𝚗𝚍𝚊).
I told my Kannada teacher in Class 8, “My only fear is writing Kannada.” […] Surprisingly, I got 50 percent and passed that subject. I was happy just to finish Class 8, and not have to write in Kannada anymore {laughs}! […] Writing was a challenge. (49M)
In general, interviewees emphasised the importance of being able to comprehend and speak a language, rather than read and write it. They were often reluctant to put in special efforts to learn the written form of a language if there was no evident tangible benefit of doing so. Thus, even if nominally in favour of using a particular script for Sindhi, all but one of the interviewees were happy for the language to be maintained orally.
Interaction between Sindhis can take place orally in Sindhi. Truly, if you look at it, the ‘purity’ of the script and ‘purity’ of the language is more academic than practical. (41M)
How does it matter which script you’re teaching Sindhi in? […] the idea is that conversational Sindhi shouldn’t die out. (10M)
Interviewees of the oldest and middle-aged generations fluent in spoken Sindhi often asserted that reading and writing was an after-effect of being able to speak the language. The written form of the language was only seen as having a subsidiary role to play, if at all, in language learning.
This thing called language, you learn it by listening […] Even if you want to learn it from the written medium, or if you want to read it, you need to know something of the spoken language first. (31F; translated)
Even simultaneous learning of the spoken and written forms of language was not generally envisaged.
You have to ensure that learners learn to speak somewhere first. Then, you give them exposure to reading. Only then will it make sense. (17M)
In fact, the oldest generation was content with youngsters simply being orate in the language.
Let them read English, let them read Hindi. But they should at least speak Sindhi. (21F; translated)
The emphasis on oracy also manifested in the form of fluent speakers regretting the inability of the younger generation to correctly articulate Sindhi’s characteristic φ-implosives. No such regret was expressed about youngsters not being able to read and write 𝚜𝚍-𝙰𝚛𝚊𝚋.
Our children study in English-medium schools, so they’re unable to pronounce Sindhi words correctly […] We try and teach them to say [
ɓəkᶦɾi] {‘she-goat’}, with a [ɓ], but they can’t say it. They should, but they don’t pay attention. (21F; translated)Some youth, they say “Forget it. Why put in so much effort. It doesn’t make any difference whether I say [
ɗũɡʱi] {‘copra’} or [ɖũɡʱi]. As long as people understand what I want to say.” (34F)
As far as the question of 𝚜𝚍-𝙻𝚊𝚝𝚗 was concerned, it was felt that such a system would be restricted to beginners who wished to gain a working knowledge of spoken Sindhi.
Keep the originality by maintaining the language in the Arabic script. Roman-script Sindhi is for people who have no exposure, no idea whatsoever, of the language. (50F)
Apart from the RST members, none of the interviewees felt that 𝚜𝚍-𝙻𝚊𝚝𝚗 would be adopted to a significant degree by those fluent in spoken Sindhi.
People who can speak and understand Sindhi, I doubt they will put any effort into writing Sindhi in the Roman script. (03M)
Two fluent speakers characterised language as a ‘transaction’. Considering that spoken Sindhi in India and the diaspora was used only in restricted domains, the interviewees characterised the idea of writing in Sindhi — in particular, writing it in Roman — as putting the cart before the horse.
There’s no need for me to write in Sindhi. Because there’s no transaction. What do I write? To whom? (42M)
In any case, inability to speak Sindhi was not seen as having significant social repercussions. Consequently, being unable to read and write Sindhi, regardless of script, was far from being a hindrance.
We don’t use Sindhi much in the written form. So it really doesn’t matter. (18F)
In fact, many in the younger generation not fluent in Sindhi had barely given any thought to reading and writing the language.
I haven’t even thought about it, actually […] it’s an accepted thing that you’re never going to be able to read or write Sindhi. At the most, you can understand it. And try and speak it. (05M)
Interviewees brought up the fact that the Sindhi language was not used in official domains, which would have necessitated competence in the written form of the language. They also spoke of the availability of cheap international phone plans and video-calling software, which enabled them to interact verbally with friends and relatives rather than have to write to them. In this context, several interviewees young and old, saw the issue of literacy in Sindhi, which was already unimportant to them, as even less important.
Why will people who can speak Sindhi learn to write it? They already speak the language. Why would they want to read and write it? And now everyone’s got a mobile phone. There’s no need to write letters either. (36F)
It’s not the day and age of writing letters. Fewer and fewer people are doing that. People just pick up the phone and call each other. So, there’s no need to read and write Sindhi. (02M)
For these interviewees, it was not just cutting-edge technology involving mobile phones, communication apps and high-speed broadband that were rendering Sindhi in the written form of language increasingly dispensable. Even older, simpler innovations such as the compact disc were noted as enabling access to Sindhi literature by circumventing the need for a script entirely.
Let’s say you’re going for a long drive […] you put in a CD — an audiobook of Sindhi stories — into your car stereo. And you can listen to the stories. There’s no script involved! So where’s the need to fight over a script? (19M)
Along these lines, it was felt that popularising or maintaining a language did not depend on it being available in a written form.
If you want to propagate Sindhi stories or Sindhi mythology […] it can be done in audio format or video format. People don’t have to read it. (12F)
One Sindhi scholar identified a seemingly contradictory behaviour in contemporary India towards the written form of language. He noted that people in India were generally desirous of reading English and consulting dictionaries, in order to improve their command over the language. Yet, they did not exhibit the same behaviour when it came to ameliorating their knowledge of Indian languages.
Indians don’t have the habit of referring to dictionaries. They’ll look up dictionaries in English, but not in their own language. That culture doesn’t exist. (38M; translated)
In short, the written form of language was seen as something that enabled asynchronous communication in the language, if desired. It was seen as a nice-to-have, but not as something essential. In general, interviewees considered writing to be a formal activity that was dispensable in the context of knowing a language.
13.3.2 Analysis
The themes presented and explained in the preceding section reveal a mentality that appears paradoxical at first glance. Sindhi written in the Arabic script had considerable social status, to the extent that certain lay interviewees were in favour of 𝚜𝚍-𝙰𝚛𝚊𝚋 being maintained as Sindhi’s primary or sole writing system. The only serious contender to 𝚜𝚍-𝙰𝚛𝚊𝚋 was 𝚜𝚍-𝙳𝚎𝚟𝚊. Overall, 𝚜𝚍-𝙻𝚊𝚝𝚗 was felt to be an improvisation ill-suited for ‘correctly’ representing Sindhi. In general, language-script associations were rigid; the idea of using a hitherto untested script to write a language in a formal manner was unpalatable to many.
In any event, reading and writing Sindhi was not a matter of great concern for lay interviewees. Although written Sindhi, especially 𝚜𝚍-𝙰𝚛𝚊𝚋, had status, it was not something that interviewees were particularly desirous of learning. Rather, they were mainly interested, if at all, in learning and keeping the spoken language alive. In such an endeavour, the written form was not seen as having a major role to play. Hence, interviewees were generally resigned to letting the use of 𝚜𝚍-𝙰𝚛𝚊𝚋 fade away, while paying lip service to it. In this sense, supporters of 𝚜𝚍-𝙰𝚛𝚊𝚋 preferred to see it die a natural and dignified death than be euthanised. Along the same lines, supporters of 𝚜𝚍-𝙳𝚎𝚟𝚊 were essentially those who liked the idea of Sindhi being written in a seemingly ‘Indian’ script, but who were not necessarily going to actively read and write in it. Finally, 𝚜𝚍-𝙻𝚊𝚝𝚗 was seen by its supporters as a convenient aid for learning and teaching spoken Sindhi, despite — or because of — it being considered a quick-and-dirty workaround for technological limitations.
The themes presented also point to the prevalence of somewhat rigid language-script associations in interviewees’ minds, reflecting a general feeling in South Asia that a distinct language needs to be written in a distinct script in order to have social status (Masica, 1991, p. 144; Salomon, 2007, p. 111). Such a mindset can be ultimately traced to the introduction of printing during the British colonial era, which resulted in the consolidation of region-specific script forms (Masica, 1996). Indeed, the graphosociolinguistic history of Sindhi described in previous chapters clearly attests to the significant role of print technology and type design in entrenching the graphetic shapes of various inventories. Thus, the advent of printing caused specific scripts and typographical forms to become inextricably linked with the languages they were used for. This, in turn, led to the mindset displayed by numerous interviewees that a distinct script was required for a language to be considered distinct and have status.
The rigid mental association between language and script may be explained to some extent by the heuristic of goal dilution (Zhang, Fishbach, & Kruglanski, 2007). This is a fallacy that causes people to feel that “[s]omething that does only one thing is better at that thing than something that does that thing and something else” (Sutherland, 2011). In the present context, a lay interviewee may have felt that a script representing only language X does a better job than a script representing language X as well as language Y. Along these lines, certain interviewees may have mentally associated Devanagari with Hindi, Marathi and Sanskrit, and associated Roman with several languages worldwide, especially European ones. The Arabic script, on the other hand, was likely not associated with any other prominent South Asian language, save Urdu. On this basis, lay interviewees supportive of 𝚜𝚍-𝙰𝚛𝚊𝚋 may have felt that the Arabic script is better suited to write Sindhi as it seemed exclusive to Sindhi — at any rate, more exclusive than Devanagari or Roman. Such a hypothesis may explain why the Arabic script was described as the “original Sindhi script”. In brief, a script that appeared to be master of one was preferable to one that seemed like a jack of all trades. These subjective impressions of the Arabic script were, in many cases, aided by nonliteracy in 𝚜𝚍-𝙰𝚛𝚊𝚋, and ignorance of the fact that the Arabic script is used for a variety of languages worldwide.
The symbolic value attached to 𝚜𝚍-𝙰𝚛𝚊𝚋 may also be illustrative of an endowment effect with regard to it (Kahneman, Knetsch, & Thaler, 1990). That is, some interviewees may have ascribed more value to 𝚜𝚍-𝙰𝚛𝚊𝚋 simply because it was ‘theirs’. Even if lacking in practical communicative value for these individuals, 𝚜𝚍-𝙰𝚛𝚊𝚋 remained part of their community’s and language’s story. The fact that most supporters of 𝚜𝚍-𝙰𝚛𝚊𝚋 were nonliterate in it and unable to factually verify their instinctive impressions of it likely reinforced the endowment effect they felt.
Returning to the subject of rigid language-script associations, a theory that may offer some explanation for it is the package-deal fallacy (Sternberg, 2011). This fallacy involves an assumption that things that are commonly associated with each other must always be kept together; else, there will be disorder. Logically, the fallacy implies that X and Y usually go together, therefore X cannot be dissociated from Y. For certain interviewees in the present study, especially linguistically untrained ones, the maintenance of existing language-script associations seemed to induce a semblance of orderliness. For them, writing a language in a different script would have uncertain consequences, and would be acceptable only as a temporary or informal measure. This proceeds from the phenomenon of ambiguity aversion mentioned earlier (§13.2.2). The existence of the package-deal fallacy in interviewees’ minds may explain why replacing the Arabic script with another was described as ‘bastardising’ Sindhi. The underlying sentiment was that fossilisation of written Sindhi as the purebred 𝚜𝚍-𝙰𝚛𝚊𝚋 was preferable to its survival as the mongrel 𝚜𝚍-𝙻𝚊𝚝𝚗.
The package-deal fallacy may also help expound why 𝚜𝚍-𝙳𝚎𝚟𝚊 had a fair share of support among interviewees. Since most major South Asian languages are typically written in Indic or “Indian” scripts, some interviewees may have felt that an “Indian” language like Sindhi is best expressed in a script indigenous to the region. Hence, irrespective of their own proficiency in Sindhi, such persons may have deemed Devanagari a suitable candidate for Sindhi on the basis of its South Asian origins. For them, Roman would not do a satisfactory job of representing Sindhi phonology, since it was perceived as originally designed for writing English and other European languages. Indeed, Roman was seen to form a package deal with languages such English, German and French, whose associations with the Roman script are longstanding and established. To clarify, Roman was not considered a cultural misfit per se in the South Asian sociolinguistic context. Rather, its European or Western credentials made it inappropriate for use as the formal or quasi-official script for a South Asian language like Sindhi. While there was little objection to using Roman as a supplementary or auxiliary script for Sindhi, such a 𝚜𝚍-𝙻𝚊𝚝𝚗 system would always index informality and casualness. These implicit constraints on script use for South Asian languages are aptly illustrated by the extensive derision that English-dominant Indian political leaders have to face whenever they are caught with notes of their Indian-language speeches transcribed in Roman (Mohanty, 2013; Pillalamarri, 2015).
Interviewees supportive of 𝚜𝚍-𝙳𝚎𝚟𝚊 on the basis of Devanagari’s supposed indigeneity asserted that 𝚜𝚍-𝙳𝚎𝚟𝚊 was the only pre-1843 writing system for Sindhi. Given the alphasyllabic-abugidic nature of 𝚜𝚍-𝙳𝚎𝚟𝚊, 𝚜𝚍-𝚂𝚒𝚗𝚍 and 𝚜𝚍-𝙶𝚞𝚛𝚞, together with their graphetic commonalities, it is understandable that certain laypersons may think of them simply as noncontrastive graphetic variants of each other. Furthermore, by the mid-twentieth century, Devanagari-based writing systems had become dominant and officially sanctioned across much of northern South Asia, displacing local Indic-script-based writing systems (Masica, 1991, p. 144). The ascendance and dominance of Devanagari-based systems may have obliterated from popular memory the fact that several different, albeit mutually related, inventories had previously been in vogue for several languages, including Sindhi. Arguments in favour of 𝚜𝚍-𝙳𝚎𝚟𝚊’s historicity were, hence, based mostly on their truthiness (Colbert, 2005), in that it felt right despite not being authentic or verifiable.
To strengthen their point, both 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 supporters also appealed to tradition. Those supportive of 𝚜𝚍-𝙰𝚛𝚊𝚋 insinuated that “the Arabic script is the best way to write Sindhi because that’s how we’ve always written it”. Similarly, those who thought of Devanagari as Sindhi’s indigenous script typically argued along the lines of “Devanagari is the best way to write Sindhi because that’s how we used to write it, before the British came along and imposed the Arabic script”. Notably, traditionalist supporters of 𝚜𝚍-𝙳𝚎𝚟𝚊 were all literate in 𝚜𝚍-𝙰𝚛𝚊𝚋, while also keen on ensuring that the Sindhi language was maintained. On the other hand, traditionalist supporters of 𝚜𝚍-𝙰𝚛𝚊𝚋 were mostly nonliterate in it, and wanted to preserve it for posterity rather than for practical reasons. Such interviewees were not concerned with what was in the text, but with what spoke to the eye (Coulmas, 2013, p. 32).
In order to contextualise and better understand interviewees’ opinions on the various scripts in question, the indexical associations or semiotic values (Bunčić, Lippert, & Rabus, 2016) need to be explored. As stated by Bunčić (2016h, p. 234), “every script is more than just a tool to capture speech, it also carries indexical meanings”. These meanings can further be classified into categories based on their nature, as well as their polarity. For instance, the perception of the Arabic script as “Sindhi” may have insinuated that Devanagari was less Sindhi, but by no means did it suggest that Devanagari was not Sindhi. Similarly, the perception of Devanagari as “Indian” indicated that the Arabic script was less Indian, but not necessarily not Indian. Such values must, therefore, be understood in degrees of intensity rather than in binary oppositions.
In contrast, the idea that the Arabic script indexed “Muslimness” implied that the other two scripts were not Muslim. Similarly, the implication that Devanagari was the primordial Sindhi script automatically excluded the other scripts from this label. Thus, these values are privative in nature and may, therefore, be assigned a particular polarity. Table 13.10 provides a consolidated overview of the semiotic values indexed by each script, together with polarities where applicable. Values with a question mark against them are tentative.
| Arabic | Devanagari | Roman | |
|---|---|---|---|
| Geocultural values | [Sindhi] | [Indian] | [global] |
| Religiocultural values | [+Muslim] [−indigenous] [−Western] |
[−Muslim] [+indigenous] [−Western] |
[−Muslim] [−indigenous] [+Western] |
| Legitimacy | [+authentic] [+formal] [?phonetic] [−convenient] |
[?authentic] [+formal] [+phonetic] [?convenient] |
[−authentic] [−formal] [−phonetic] [−convenient] |
Although potentially contradictory at first glance, the term “Sindhi” in Table 13.10 should be understood as distinct from “indigenous”. The notion of Sindhiness emerged when lay interviewees attributed values to scripts, without any reference to or knowledge of the historical interplay of Sindhi’s writing systems. In contrast, the notion of indigeneity almost always surfaced when interviewees explicitly referred to the history of Sindhi’s writing systems.
Notwithstanding the above, Bunčić (2016i, p. 325) notes that semiotic values “are not inherent to a script.” Rather, a script acquires these values from its use in a particular context (Bender, 2008). For instance, if a script is used to write a language predominantly in an informal context, then that script acquires the indexical meaning of informality (Bunčić, 2016c, p. 62). This observation neatly encapsulates the historical image of the Landa inventories in the pre-British and British era, and the contemporary image of Roman. The Landa inventories acquired the image of “traders’ script”, “shortcut script” and “secret script” precisely because they were used by said user groups in said contexts. Similar is the present-day situation of Roman, where the widespread use of the script to write Sindhi on social media and on messaging apps in an unstandardised and ad-hoc manner has given it an image of “informal script”, at least in the context of Sindhi. This image has inadvertently led to the de-legitimisation of Roman as a formal solution for writing Sindhi. While Roman was considered useful as a tool to aid learning spoken Sindhi, it was not considered a potential full-fledged script for the language usable in formal domains such as writing literature.
At this juncture, one may ask why 𝚜𝚍-𝙳𝚎𝚟𝚊 is not adopted more widely on social media and in messaging apps if 𝚜𝚍-𝙻𝚊𝚝𝚗 was not considered formal. The question appears legitimate especially when one considers the legitimacy and status of 𝚑𝚒-𝙳𝚎𝚟𝚊, 𝚜𝚊-𝙳𝚎𝚟𝚊 and 𝚖𝚛-𝙳𝚎𝚟𝚊 in contemporary India, as well as the widespread technological support available for typing and displaying Devanagari on computing devices nowadays. Part of the answer to this question lies in the fact that a full-fledged writing system for Sindhi may actually be overkill in the present context. That is, the formal image or subjectively superior phonological accuracy of a Devanagari-based system is somewhat immaterial, since the people most likely to write Sindhi for everyday purposes may not require a high degree of phonological accuracy. The idea underlying such practice may be termed the principle of good enough, from a similar concept found in software and technology design (see Capps, 2009; Wilson, 2009). This principle suggests that people would adopt a writing system that is good enough for their requirements (Rosowsky, 2010), even if phonologically superior systems are known to them and are technologically supported. In other words, if people find that using unstandardised 𝚜𝚍-𝙻𝚊𝚝𝚗 — or, for that matter, unstandardised 𝚑𝚒-𝙻𝚊𝚝𝚗 — on social media and messaging apps got the message across, they would continue to use it, and likely even prefer it over a phonologically comprehensive but intricate 𝚜𝚍-𝙳𝚎𝚟𝚊 and 𝚑𝚒-𝙳𝚎𝚟𝚊. Similarly, a makeshift 𝚜𝚍-𝙻𝚊𝚝𝚗 would likely be preferred to a comprehensive Roman-script-based writing system such as 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒. Even if users were familiar with 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 and were able to type and read it on computers and mobile devices, the graphematic intricacy of 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 appears excessive for mundane everyday communication. This situation is reminiscent of Sindhi Vania traders historically preferring to carry out mercantile communication and maintain their books in a so-called deficient Sindhi-Landa writing system. To the Vanias of the pre-British and British era, the ‘deficient’ Sindhi-Landa system got the message across and was, therefore, good enough. Phonological accuracy and graphematic propriety, therefore, were superfluous matters, which explains the Vanias rejection of the phonologically and graphematically ‘complete’ 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 (§5.2.3, §8.2). Nearly a century and a half since 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 was proposed, not much seems to have changed in attitudes towards written language among the Sindhi community. When it comes to everyday writing, lay Sindhis do not appear to be seeking a linguistically or phonologically optimal solution. Rather, the preference is for something that is satisfactory, and achieves maximum communication with minimum effort. Admittedly, fluid or hybridised graphematic practices in modern times often exist in an uneasy tension with grapholinguistic prescriptivism, in that status is only accorded to writing practices that are standardised. As observed by Schneider (2016, p. 24), hybridised writing practices serve the needs of the users, but are often not legitimised by the users themselves.
The apparent semiotic values of the Arabic, Devanagari and Roman scripts listed in Table 13.10 also allude to the persistence of digraphia in the context of written Sindhi — specifically, use-oriented digraphia. Historically, the high-variety or H writing systems of Sindhi were 𝚜𝚍-𝙰𝚛𝚊𝚋, 𝚜𝚍-𝙶𝚞𝚛𝚞 and 𝚜𝚍-𝙺𝚑𝚘𝚓, with 𝚜𝚍-𝙳𝚎𝚟𝚊 also acquiring H status from the mid-nineteenth century. In contrast, unstandardised Sindhi-Landa was a low-variety or L writing system. In present times, 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 continue to act as H writing systems. The L position of unstandardised Sindhi-Landa, however, is now occupied by unstandardised 𝚜𝚍-𝙻𝚊𝚝𝚗. This further explains why interviewees considered 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 to have status, but not 𝚜𝚍-𝙻𝚊𝚝𝚗. The first two qualified as H writing systems, but not the third. Crucially, the H nature of 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 mandated that any formal or H-variety Sindhi-language text be written in 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊, ideally in an ornate literary style. Thus, the high bar set for H variety writing may end up deterring people from learning and using it extensively (Khubchandani, 1984). The prevailing digraphia in written Sindhi and the elevated status of H variety writing in the language may explain the paradoxical phenomenon observed among interviewees. Despite closely the H-status 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊 with the Sindhi language, people were happy to hold them in tokenistic reverence, especially 𝚜𝚍-𝙰𝚛𝚊𝚋. There was no desire to learn or actively use them in everyday settings. On the other hand, 𝚜𝚍-𝙻𝚊𝚝𝚗 was used informally on a daily basis, but, due to its perceived L status, was not seen as appropriate for literary or formal purposes.
The perceived choice and sociocultural fit of a writing system, therefore, appear to be determined by situational use. This aligns with the fact that, in South Asia, the choice of spoken language, too, is often situationally determined (Kulkarni-Joshi, 2015). According to Khubchandani (1984, p. 175), the contextual or domain-based selection of linguistic repertoires in the Indian situation is characterised by “flexibility and manipulation in adjusting to situational needs”, and is not incompatible with one’s affiliation with a mother tongue. Ndhlovu (2013) has described this practice of drawing on various linguistic resources in one’s repertoire depending on circumstance as “language nesting”. Despite Ndhlovu’s model being focused on spoken language use, it lends itself well to written language use as well. The phenomenon on drawing on appropriate linguistic resources in appropriate situations was reflected in interviewees’ statements and insinuations that language — spoken as well as written — was most often just a medium of communication. Outside of culturally salient or loaded situations, the medium was less important than the message. At the same time, such a stance was in no way antithetical to interviewees considering Sindhi to be their mother tongue.
In any event, the question of which script to write Sindhi in was a moot point for interviewees who had been put off by the regurgitated content circulating in existing Sindhi-language publications. Indeed, the issue of high-quality content forms part of a vicious circle that has affected Sindhi-language writing, publication and readership in India for some time now. The decreasing number of people literate in 𝚜𝚍-𝙰𝚛𝚊𝚋, and the failure of 𝚜𝚍-𝙳𝚎𝚟𝚊 to gain community traction, has resulted in a dearth of motivated writers in both systems, thereby resulting in insipid content. In turn, uninteresting content causes the number of readers in both systems to decline further. This conundrum results in a chicken-and-egg situation of what to address first — the problem of boring content in both 𝚜𝚍-𝙰𝚛𝚊𝚋 and 𝚜𝚍-𝙳𝚎𝚟𝚊, or the issue of community literacy in these systems?
The question of script was also a moot point in that learning to read and write Sindhi was, generally speaking, not a desideratum for any of the interviewees nonliterate in the language. In terms of language learning, it appears reasonable to state that learning to understand and speak a language is hard enough for a layperson. Working adults would typically be unwilling to put in extra effort into learning how to read and write a language unless there was some tangible benefit to doing so. This mindset aligns with the Sindhi community’s historically pragmatic approach to education and literacy. For instance, Amil Sindhis typically acquired literacy in 𝚏𝚊-𝙰𝚛𝚊𝚋 in pre-British-era Sindh, but switched to 𝚜𝚍-𝙰𝚛𝚊𝚋 in the British era. What drove the Amil community’s choices were the tangible economic benefits of becoming literate in these writing systems in their respective eras. In modern times, 𝚜𝚍-𝙰𝚛𝚊𝚋 has been displaced by 𝚎𝚗-𝙻𝚊𝚝𝚗 as the optimal vehicle of economic progress. Indeed, this observation holds good across much of modern South Asia. The perceived socioeconomic benefits of being proficient in 𝚎𝚗-𝙻𝚊𝚝𝚗 is what drives individuals to consult 𝚎𝚗-𝙻𝚊𝚝𝚗 dictionaries. However, as noted by Interviewee #38M (p. 389), such habits do not necessarily apply to the written forms of South Asian languages. Hence, one would acquire a high level of written proficiency in a language bereft of evident social or economic benefits only out of sheer personal interest, or if the learning curve was flat. Seen as a cost-benefit analysis, the motivational intensity (Brehm & Self, 1989; Kukla, 1972) to learn a language — particularly its written form — would be proportional to the difficulty involved in doing so, up to a tipping point where the individual decides that the costs involved outweigh the rewards. From the perspective of interviewees, the energy one would invest in learning 𝚜𝚍-𝙰𝚛𝚊𝚋 would be very high, while the need for success was very low. This resulted in low motivational intensity for this endeavour. In general, there seemed to be an internalisation of the fact that the Sindhi language had been relegated to the spoken domain. Consequently, motivation to acquire Sindhi in written form remained.
As a result of low motivation levels, certain interviewees may have felt it convenient to attribute responsibility for the situation to other parties, often anonymous. The observed passing-the-buck tendency involves an attribution error, where a seemingly negative outcome — here, the fading away of Sindhi in written form — is attributed to the character or personality of the other party. In contrast, any personal inaction or apathy is attributed to situational constraints. Thus, members of the older generation may feel that young Sindhis do not know their traditional language due to a lackadaisical attitude. Yet, they may resist any insinuation that the older generation somehow failed to transmit the language to the younger generation, and attribute the failure of transmission to circumstances. Likewise, a member of the younger generation may consider themself a victim of the situation, and consider their parents and grandparents responsible for not transmitting their traditional language on (Iyengar, 2013). Thus, there appear to be elements of an actor-observer bias (Jones & Nisbett, 1972) when it comes to taking and attributing responsibility for the situation of spoken and written Sindhi in present-day India.
At any rate, the attribution of responsibility for inaction on resolving the Sindhi script date in post-Partition India seems inconsequential when viewed against historical attitudes towards written language among the Sindhi community. Starting from the predominance of orality in early Sindhi folklore, to the eschewing of the graphematically ‘complete’ 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, it appears that written Sindhi has been considered less important than the spoken form, and utilised only to the extent necessary. This is also the sentiment expressed by several interviewees in that Sindhi in the spoken form was more important to them than in the written form. Moreover, such views are also consistent with views from the Sindhi diaspora reported in other studies (Khemlani David, 2001, p. 232). The preference for communicating in the oral mode was also seen in interviewees’ ready adoption of new technologies such as mobile phones and video-calling software to communicate orally with friends and family in Sindhi and in other languages. This stood in stark contrast to the low level of motivation to read and write in 𝚜𝚍-𝙳𝚎𝚟𝚊 or 𝚜𝚍-𝙻𝚊𝚝𝚗, despite the Devanagari and Roman scripts being known to nearly all interviewees. In a sense, the observed behaviours vindicate Garvin’s prediction half a century ago that:
[n]otions which from a European perspective seem perfectly obvious and/or necessary may be rejected out of hand […] some of the nationalities in the former colonies [of European powers] might not necessarily go through a process of literacy and language standardization [in their own languages], but might pass directly into a ‘Macluhanesque’ period where oral mass communication in the local traditional style would be made possible by the electronic media.
If the story of written Sindhi is anything to go by, it does seem that, even in modern times, the ability to read and write formally in a particular language continues to be subconsciously perceived as a secondary or dispensable skill. Yet, spoken ability in languages remains valued, and acquired rather seamlessly when needed. Such an approach stands in some contrast to reported instances of language minorities wanting to maintain or promote literacy in the written form of their traditional language purely for emotional or identitarian purposes (Martin-Jones & Jones, 2000). Indeed, the interviewees in this study saw the act of literacy acquisition as driven by inherent need than by emotion. In this context, Daswani (2005, p. 20) states that literacy in a written language is typically desired only when “one [is] stimulated by one’s vocation and the demands it makes upon the individual’s competence in literacy”. This is echoed by Schneider (2016, p. 23) when she notes the importance of opportunities to actually exercise any literacy skills acquired. In the South Asian context, Ferguson (1996, p. 87) notes that “[l]iteracy is widely regarded as primarily an aspect of formal schooling rather than a resource for everyday living”. These observations are affirmed by the story of written Sindhi, both historically and in present times. For the Sindhi community, everyday oracy in their traditional language has been and continues to be valued more than cosmetic literacy in it. While written Sindhi has been appreciated and even admired, it has not always been sought after as a practical skill, unless there has been some demonstrable quotidian need for it.
13.3.3 Summary
Most interviewees, across all generations, were familiar with a Roman-script-based writing system, be it standardised 𝚎𝚗-𝙻𝚊𝚝𝚗 or unstandardised 𝚑𝚒-𝙻𝚊𝚝𝚗 and 𝚜𝚍-𝙻𝚊𝚝𝚗. However, implicit notions of propriety conditioned by contextual and domain-based digraphia meant that 𝚜𝚍-𝙻𝚊𝚝𝚗 was considered an L writing system. Consequently, 𝚜𝚍-𝙻𝚊𝚝𝚗 was seen as unsuitable for H-variety formal writing. In contrast, 𝚜𝚍-𝙰𝚛𝚊𝚋, despite being an H variety system, was hardly known among the youngest generation. Still, a few of them saw it as emblematic of the Sindhi language in the written form. Since literacy in Sindhi, regardless of script, was not particularly sought after, there prevailed in some quarters the notion of allowing the fading cultural icon that was 𝚜𝚍-𝙰𝚛𝚊𝚋 to be antiquated with dignity. This was considered preferable to replacing it with a seemingly L variety system such as 𝚜𝚍-𝙻𝚊𝚝𝚗 and, in the process, creating a bastardised version of written Sindhi.
PART THREE | Writing Systems of Sindhi: Implications for theory
14 Graphematics and orthography
As outlined in Chapter 1, one of the aims of this book was to analyse Sindhi’s numerous writing systems that belong to various typological categories using a common theoretical approach and terminology. To paraphrase Meletis (2020, p. 391), the aim was to use a holistic approach to describing Sindhi’s writing systems in order to enable atomistic approaches towards the subject matter in future. With this aim in mind, Part Three of this book consolidates the findings from Part Two, contextualises the graphematic and sociolinguistic lessons they offer, and identifies promising avenues for future research.
14.1 Graphematic typology and the grapheme
14.1.1 Writing system typology
The Analysis sections of Chapters 5 to 12 have revealed that Sindhi’s writing systems over the centuries have belonged to a variety of typological categories, ranging from the abjadic 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 to the plenar-alphabetic 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒. What’s more, such typological diversity is also observed intrasystemically — namely in writing systems comprising the same language-script pair. For instance, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 is an abjad, whereas 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 is an abugidic alphasyllabary. Likewise, 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 appears to be a plenar alphasyllabary, while 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 is an abugidic alphabet. These findings attest to the multi-layered structure of writing systems, and reveal how their structure is impacted not just by which language and script are being combined, but also by how they are combined. It also emerges that, at present, there is no suitable or widely accepted notation for indicating writing systems that comprise the same language-script pair but belong to different typological categories. In their current format, IETF-style language tags do not provide for a subtag denoting the graphematic typology of the writing system.
In terms of graphetic compositionality, the case of 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 and 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 has emphasised the need to distinguish between graphematic and graphetic secondariness. Graphs such as 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙿𝙺 |⠂ ⠑ ⠥| [ə ɪ ʊ] and the 𝚜𝚍-𝙱𝚛𝚊𝚒-𝙸𝙽 anusvara |⠰| are graphematically bound in that they can only occur together with a free graph. Graphetically, however, they are not subsegmental. In fact, they are of the same size as the free graphs they co-occur with. This finding emphasises the need to develop and use specific terminology in this regard, with the aim of avoiding potentially ambiguous descriptors like ‘secondary’ or ‘subsidiary’ to the extent possible.
14.1.2 The elusive grapheme
The Analysis sections of Chapters 5 to 12 also reveal that the current state of grapholinguistic theory remains inadequate for conclusively determining the graphemes in the various writing systems under investigation. Although Meletis’ (2020) criteria of minimality, linguistic value and contrast (§2.5) offer a robust theoretical springboard, the findings from Part Two attest to the work that remains to be done in refining these criteria.
On the question of minimality, there remain several areas susceptible to paradigmatic inconsistency and arbitrariness in evaluation. For instance, the Analysis of 𝚜𝚍-𝙳𝚎𝚟𝚊 shows how |ब| [b(ə)] may be interpreted as a graphetic combination of |ब्◌| [b] and |ा| [a], whereas |क| [k(ə)] would likely be considered rasmically distinct from |क्◌| [k]. Such examples also highlight the potential tension between graphe(ma)tic minimality and phenomenological primacy. For instance, in 𝚜𝚍-𝙳𝚎𝚟𝚊, the graphetically simpler |प| represents the phonetically more complex value [pə], while the graphetically more complex |प्| has the phonetically simpler value [p]. At the same time, [p] is also denoted by |प्◌|, which is graphetically the simplest of the three. As evident, the correlation between graphe(ma)tic and phonological minimality is nonlinear. Regardless of graphe(ma)tic minimality, an end user of 𝚜𝚍-𝙳𝚎𝚟𝚊 would likely consider |प| as the conceptually basic form, and |प्◌| and |प्| as derived forms. This is the view reflected in traditional and pedagogical interpretations of Devanagari-based writing systems, as well as in recent technological-grapholinguistic approaches such as those adopted by Unicode. Furthermore, considering |प| to be the conceptually basic form, and |प्◌| and |प्| to be derived ones might also be justifiable. A parallel in the phonological realm is choosing between fully released [p] or unreleased [p̚] as the conceptually ‘basic’ entity and, consequently, as representative the underlying phoneme. Despite [p̚] being arguably curtailed in a phonetic sense compared to [p], it is typically the latter that is considered ‘basic’ and used to denote the underlying phoneme — namely /p/. Put differently, [p̚] is considered a ‘derived’ form of /p/ whose occurrence is predictable based on phonological environment. Similarly, one may argue that the occurrence of |प्◌| [p] and |प| [pə] are usually predictable in 𝚜𝚍-𝙳𝚎𝚟𝚊 and other Devanagari-based writing systems based on graphematic environment. Nevertheless, and as mentioned in Section 7.7.2, the presence of paradigmatically deviant forms in 𝚜𝚍-𝙳𝚎𝚟𝚊 such as |क्◌| [k], as well as of so-called ligatures, raise questions on what exactly is meant by minimality, and how the criterion should be applied in determining 𝚜𝚍-𝙳𝚎𝚟𝚊’s graphemes. Similar are the findings from the other Analysis sections in Part Two, in the process precluding definitive answers on the grapheme inventories of Sindhi’s various writing systems.
Along similar lines, the criterion of linguistic value can be reliably applied in determining graphemes only when there is consensus on what constitutes ‘linguistic value’. The answer to this question has implications for several of the writing systems in question. For instance, if the subsegmental phonological feature of implosivity counts as a ‘linguistic value’, the underline element in 𝚜𝚍-𝙳𝚎𝚟𝚊 |ॾ| may qualify as a grapheme in itself. Of particular interest is the question of whether the absence of a postconsonantal φ-vowel — namely [Ø] — meets the definition of ‘linguistic value’. The answer to this question would decide the grapheme status of virama and sukun across Sindhi’s writing systems.
Regarding the criterion of graphematic contrast or distinctiveness, the case of the unstandardised Landa forms demonstrates that the question of distinctiveness is fundamental not just at the level of individual graphs or graphetic elements, but to scripts as a whole. This is elaborated on in the following subsection.
14.1.3 Ontogenesis of script
As evinced in Part Two, opinions were — and remain — varied on whether the graphetically distinct but unstandardised Landa inventories constituted standalone scripts at the underlying level, or were simply superficial calligraphic variants of one another. Illustrating the fraught nature of this question is Figure 14.1, which features the handwritten graph for [p(ə)] in thirteen Landa inventories.

p(ə)]Source: Stack (1849a, p. 7)
The Analysis in Part Two reveals that dilemmas of this nature in colonial-era Sindh were typically resolved by deliberate top-down intervention, often motivated by administrative or evangelical aims. In general, though, a graph inventory acquired the status of ‘script’ when it formed part of a writing system that fulfilled certain broad criteria. These criteria are outlined in (32):
(32)
- graphetic distinctiveness from comparable inventories,
- graphematic comprehensiveness in representing phon(eme)s with distinct graphs, and
- consistency in graph-phone correspondences.
Accordingly, of the thirteen Landa inventories highlighted in Figure 14.1, only two went on to meet these criteria and, consequently, acquire the status of ‘script’ — Khudawadi and Khojki. The rest were, and generally still are, simply considered graphetic variants of Khudawadi. This view has influenced the encoding of the various Landa forms in Unicode, as captured in Pandey’s (2011a) statement below:
Numerous Landa-based scripts were used in Sindh. […] The majority of these scripts are insufficiently developed to be encoded independently in [Unicode]. The exceptions to this are Khudawadi and Khojki. Therefore, if there is a need to represent these smaller Landa-based Sindhi scripts, the proposed encoding for Khudawadi should be used.
The above finding suggests that quasi-planned intervention has played a key role in the ontogenesis of a script in the generally understood sense. This appears true not just in the Sindhi context, but in the wider South Asian context as well. Indeed, the observed phenomenon is not unlike a particular speech variety being picked by an official or authoritative body as the standard variety and consequently decreeing it a ‘language’. However, the similarities seem to end there. In spoken language, phonological inventories and their associated rules develop organically in a bottom-up manner. Native or fluent speakers of a speech variety are implicitly aware of and adhere to its phonological rules, with linguists taking on the task of explicitly identifying such rules. As outlined in Section 2.9, if a present-day language authority were to intervene in a top-down manner and attempt to promulgate an ostensible orthoepy (see footnote 23), it would likely be ridiculed, resisted or simply ignored. In contrast, top-down intervention in graphematic matters such as the standardisation of graph inventories, graph-phone correspondences and spelling rules are generally seen as positive and desirable — regardless of whether such rules are actually followed.
Taken together, the findings from the analysis of Sindhi’s writing systems suggest that scripts — and, potentially, graphemes — come into existence when an institution or individual with influence hails them into being. In the context of Sindhi writing, influential entities of this kind range from the British administration in colonial-era Sindh to Laljibhai Devraj. Of course, as the findings in Part Two also reveal, the purported influence of these institutions and individuals is often fleeting, probably best exemplified by the fate of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿. Despite the administrative and financial backing of the colonial government, not to mention meeting all the criteria outlined in (32), 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 ended up being a damp squib. Although the obsolescence of 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 does not impinge on the status of Khudawadi as a script, it does carry valuable lessons for theory on the subject of orthography and its supposed authority.
14.2 Foundations of orthography
14.2.1 Orthography and authority
With reference to the Modular Theory of Writing Systems (MT; see Section 2.4), the notion of a graphematic solution space proves useful in explaining the constrained variation attested in the spellings of Sindhi words across writing systems. In contrast, no existing theory seems capable of satisfactorily explaining certain orthographic phenomena observed in Sindhi’s various writing systems.
Inherent in most academic conceptualisations of orthography is the purported authority it carries in its graphosphere of operation. In the sociolinguistic, pedagogical and, now, grapholinguistic literature, scholarship has tended to assume that orthography-prescribing bodies — to the extent they exist — necessarily have prescriptive power over their graphospheres and the people within those graphospheres. For instance, Meletis states that “[a]n orthography obliges the writer to obey the prescriptive rules that a community of writers has – more or less bindingly” (Meletis, 2020, p. 155). By extension, the orthographic rules followed by one “community of writers” may not be followed by the other. A salient example in the English graphosphere is that of different written norms in the UK and the US. However, there may also be orthographic rules — and bodies that make them — that are not obeyed by a critical mass of writers, effectively rendering them leaders without followers. In the context of English, Oxford spelling (𝚎𝚗-𝙻𝚊𝚝𝚗-𝙶𝙱-𝚘𝚡𝚎𝚗𝚍𝚒𝚌𝚝; see Section 2.3) may qualify as an orthography that is not widely followed. In contrast, the history of written Sindhi reveals not one but multiple instances of prescribed orthographies going largely ignored, which has implications for our understanding of orthography and of the very need for one. Indeed, binding orthographies are a relatively recent phenomenon in the history of glottography (Gnanadesikan, 2009) and, even in the twenty-first century, are by no means universal or commonplace (Garton, Dale, Roy, & Basumatary, 2022).
The case of written Sindhi also demonstrates that the authority — or lack thereof — of a particular orthography is relatively independent of its linguistic robustness. In fact, the descriptions and evaluations in Part Two of this book reveal the grapholinguistic history of Sindhi to be a veritable graveyard of consistent or well-designed orthographies that failed to gain community acceptance. Prominent in this list are 𝚜𝚍-𝙰𝚛𝚊𝚋-𝚡-𝚝𝚛𝚞𝚖𝚙𝚙, 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 and perhaps 𝚜𝚍-𝙳𝚎𝚟𝚊-𝚡-𝚒𝚒𝚜, although it may be premature to rule on the last one. The sociolinguistic inconspicuousness of these Sindhi orthographies stands and the relatively muted reaction to them over the years stands in stark contrast to orthography reforms in European languages and the sociolinguistic stir they tend to create (Johnson, 2005; Sebba, 2007). Indeed, even a revived minority language like Cornish, with less than a thousand fluent speakers at the time of writing, has seen significant community debate over its orthographies (Bowler, 2020). The sociolinguistic prominence of the Cornish orthography debate is reflected in the fact that there exist four separate IETF subtags for various proposed orthographies in Cornish-Roman (𝚔𝚠-𝙻𝚊𝚝𝚗). In contrast, there exist no official IETF subtags for orthographies or variants in any of Sindhi’s writing systems.
The case of written Sindhi also highlights a new dimension of analysis with regard to the popular observance of an orthography. So far, scholarly critiques of orthography — particularly in the context of European languages and writing systems — have tended to focus on what may be termed orthographic posturing. This refers to writers adopting or rejecting a particular orthography as a proxy for, or index of, their own sociopolitical ideology (Bunčić, Lippert, & Rabus, 2016; Johnson, 2005). However, such an understanding presumes that every writer follows some orthography. What the grapholinguistic history of Sindhi demonstrates is the phenomenon of orthographic apathy, wherein a user may follow no particular orthography. That is, users may implicitly dispense with an orthographic module altogether in their writing, proceeding instead with a bare graphematic module that shows considerable variation, albeit within the bounds of the graphematic solution space. This is aptly illustrated by the continued use of unstandardised 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝚝𝚛𝚊𝚍 until Partition, and, in present times, by the persistent use of unstandardised 𝚜𝚍-𝙻𝚊𝚝𝚗 on instant messaging apps and social media. This is despite the existence of standardised 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿, 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚕𝚜𝚒 as well as the ASCII-only 𝚜𝚍-𝙻𝚊𝚝𝚗-𝚡-𝚛𝚜.
The dispensation of the orthographic module described above challenges the largely unquestioned assumption in the scholarly literature on an orthography necessarily having prescriptive power. The case of written Sindhi has shown that its grapholinguistic stakeholders are, in general, comfortable with the existence of orthographic variation and, indeed, multiple writing systems. Whereas formal institutions like the SLA in Pakistan and IIS in India, as well as individual lexicographers and grammarians, may seek to standardise orthographies based on scholarly or ideological foundations, they tend to be a minority across the Sindhi graphosphere. This stands in some contrast to the situation observed in European graphospheres, whose history reveals an urge to standardise orthographies to be the societal norm. In turn, such an urge may reflect the sociolinguistic importance ascribed to orthographies in Europe.
At the same time, it also emerges that the number of scripts in vogue in Europe has tended to be limited, especially over the last five hundred years or so. In contrast, the diversity of scripts used in the Sindhi graphosphere, and in South Asia in general, has been and continues to be substantial (Figure 5.3). Whether the importance of an orthography in a particular graphosphere is related to the relative number of scripts in that graphosphere is taken is taken up in the next section.
14.2.2 Orthography and script density
The sheer variety of scripts and writing system types seen in the Sindhi graphosphere, coupled with the relatively low levels of sociolinguistic pressure to orthographise and standardise, prompt the question of there being a potential correlation between the two. This question assumes greater salience when compared to the grapholinguistic situation in Europe — one that reveals low levels of script variety and high levels of sociolinguistic pressure to orthographise. In this regard, Martin Dürst (personal communication, June 10, 2022) notes that, in Europe, the written form of a language is expected to have a few distinct graphs or ‘accented letters’ as a marker of outward grapholinguistic identity. In South Asia, and especially in present-day India, a language is expected to have its own script as a marker of outward grapholinguistic identity. In short, it is common for stakeholders around the world to expect the written form of a language to be perceptibly distinct in some aspect from the written forms of surrounding languages.
What distinguishes the European graphosphere from the South Asian one is the module typically harnessed to create the desired surface distinction — orthography in Europe versus script in South Asia. The choice of module appears to be inversely proportional to the relative diversity or density of scripts in use in the region in question. In Europe, where script choice over the last five hundred years has generally been restricted to Roman and Cyrillic (and, in theory, Greek), the orthographic module is the only option to engineer the desired surface distinction. Consequently, one may hypothesise that the orthographic module’s responsibility to act as an external differentiator has catapulted it into the sociolinguistic limelight in the European graphosphere. In contrast, languages in South Asia have been spoilt for choice in terms of script. Consequently, it is the script module that bears primary responsibility for observable differentiation in the region, because of which the orthographic module is often relegated to the sidelines. In a nutshell, the phenomenon observed is one of more script, less orthography, and vice versa.
Against this background, the historic and contemporary apathy towards orthography in the Sindhi graphosphere seems consistent with the South Asian context in general. That said, a comprehensive sociolinguistic treatment of awareness of and attitudes towards matters of orthography in South Asian writing systems will require a much broader analysis, and is beyond the scope of this book. Nevertheless, the issue does point towards common threads in sociolinguistic attitudes towards writing and writing systems across South Asia. These threads are taken up further in the concluding chapter of the book.
15 Sociolinguistics
The analysis of script and language use in the Sindhi community over the ages reveals certain distinct trends and patterns, with different user groups employing different scripts for different purposes. Certain sources, especially colonial-era British and European sources, have attributed this variation to religious stratification (§5.2). However, Part Two of this book has demonstrated that, while religious affiliation did influence the choice of script by particular user groups, it would be an oversimplification to state that religious affiliation dictated the choice of script. In fact, closer investigation reveals a great deal of diversity in script use among various Sindhi socioreligious and occupational groups, with there being not just religion-based variation, but also occupation-based and gender-based variation. The applicability of these conclusions in the wider South Asian context and their relevance for grapholinguistic theory is detailed in this chapter.144
At the outset, though, it must be mentioned that discussions on script ‘choice’ and multiscriptality evidently concern only literate sections of the Sindhi community. Writing continued to be the realm of only a small section of the population of Sindh well into the twentieth century. As of 1901, the literacy rate in Sindh was reported to be 9.3 percent for Hindus, and 0.74 percent for Muslims (Aitken, 1907, p. 180).145 The historically low literacy rates in Sindh are not unusual in the South Asian context. Ferguson (1996, p. 86) estimates that literacy rates in the Subcontinent remained at less than two percent prior to the nineteenth century. That said, sections of the Sindhi community did historically possess high literacy rates, as evinced by Markovits’ (2008) characterisation of Amil Sindhis in the late nineteenth century:
The Amils themselves […] represented but a tiny fraction of the Hindu population of Sindh […]. The Khudabadi Amils of Hyderabad were probably the most highly educated non-Brahmin group in the whole subcontinent. Already by the 1880s, the male literacy rate in the group was close to 100 per cent and the female literacy rate quite high also; the rate of English literacy was also exceptionally high.
Furthermore, and as will be described in Section 15.2, the competence of some Hindu-Sikh Sindhi women in 𝚙𝚊-𝙶𝚞𝚛𝚞 and 𝚜𝚍-𝙶𝚞𝚛𝚞 may be described as ‘partial’. Whether nuances such as an exceptionally high literacy rate or partial literacy among subsections of a speech community are relevant for theorising phenomena of bi- and multiscriptality needs to be determined on a case-by-case basis.
15.1 The Sindhi language and script ‘choice’
Part Two of this book reveals that there has always been a great deal of diversity in script use within the Sindhi community. In part, this diversity can be attributed to the lack of centralised mass education in South Asia before the British era. Only liturgical and administrative languages, and the scripts used for them, formed part of the limited education imparted in pre-British times. As outlined in Chapter 5, competence in a particular script was typically acquired in the context of literacy in a liturgical or administrative language, such as Arabic, Sanskrit or Persian. Therefore, in general, people learnt to read and write — if at all — depending on their religio-occupational needs, rather than on purported ideologies and prejudices. As a result, affiliation with a particular social group, be it based on religion, sect, occupation or gender, influenced the kind of education one received and, consequently, determined one’s script competences. In other words, people learnt scripts that were required to read the religious scriptures of their community, or to take up the traditional occupations of their social group. In the context of the Sindhi community, Muslim Sindhis might have learnt the Arabic script in the context of acquiring 𝚊𝚛-𝙰𝚛𝚊𝚋 competency for reading Islamic liturgical texts. In addition, Muslim Sindhis of the Nizari Ismaili community might have also learnt Khojki, for ginanic as well as for commercial ends. Among Hindu-Sikh Sindhis, Vania men involved in trade would learn the local Landa script variant from older male family members to maintain commercial accounts, while Amil men in the administration learnt to read and write the Arabic script as part of 𝚏𝚊-𝙰𝚛𝚊𝚋 competency. Vania and Amil women, on the other hand, sometimes learnt to read Gurmukhi to read Sikh scriptures. In this manner, religio-occupational needs and gender group indirectly influenced user competence in a particular script and, consequently, engendered a skill-based preference for that script. This sort of implicit and subconscious script ‘choice’ represents what Gnanadesikan (2021) has termed the native script effect.
It also emerges that, despite being the everyday language of most of Sindh’s inhabitants, Sindhi was not formally taught before the British era. Therefore, in the instances that Sindhi was read and written at the time, it was logical that people would use the script that they were literate or most comfortable in. This might have given rise to the unqualified assumption among early European scholars that religious affiliation, and even prejudice, led certain Sindhis to choose a particular script and reject others. The use of particular scripts by different user groups may be better understood as a tendency emerging organically from competence in a particular script, rather than as an active ideological choice. This pattern is also reflected in recent community proposals for using the Roman script to write Sindhi. The call appears to be founded largely on utilitarian intentions — namely that knowledge of Roman is currently ubiquitous within the community and, hence, would facilitate written communication in the Sindhi language — and not on any ideological affinity with the Roman script.
In short, the expositions in Part Two affirm that different subgroups within the Sindhi community acquired literacy in certain scripts for perceived economic or cultural payoff, in line with Coulmas’ (2003, p. 226) observations on the aims behind the acquisition of literacy. The findings, thus, refute the monolithic proposition of historical script choice within the Sindhi community being an outcome of ideology and sectarian prejudice. Accordingly, the historical acquisition of scripts in the Sindhi community did not necessarily conform to stereotypical semiotic or indexical associations based on religion. In other words, the common contemporary South Asian stereotypes of religion–script pairs, including Muslim–Arabic, Hindu–Devanagari and Sikh–Gurmukhi (Jain, 2007, p. 59) were not strictly adhered to within the Sindhi community in a historical context. For instance, Ismaili Sindhis employed the Brahmic-origin Khojki script for liturgical and commercial purposes alike, to the extent that the script is now emblematic of the community. Likewise, Amil Sindhis acquired proficiency in the Arabic script, first in the context of 𝚏𝚊-𝙰𝚛𝚊𝚋 and, later, in 𝚜𝚍-𝙰𝚛𝚊𝚋, in order to gain employment in administration. In fact, three of the four Hindu-Sikh members of Barrow Ellis’ script committee (§5.2) were Amils. Along similar lines, Vania Sindhis rejected education in what the colonial government termed ‘Hindu Sindhi’ — namely 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 — as they did not see economic payoff in acquiring such education (Aitken, 1907, p. 479). Amil and Vania women who managed to acquire literacy usually did so in the Gurmukhi script conventionally identified with Sikhism.
In this regard, historical script acquisition and use in the Sindhi community contrasts with the historical religion-based script divisions seen in other South Asian language communities, in particular the Hindi-Urdu-speaking communities of north-central India. Whereas the Hindi-Urdu example has become synonymous with a religion-based script divide (Ahmad, 2008; Brandt, 2016; King C. , 1994; King R. D., 2001), some may unwittingly assume that a similar divide applies to all South Asian language communities. However, this hypothesis is not borne out in the context of Sindhi. At most, there may be hints of the Arabic script having acquired the semiotic value of [+ Muslim] among certain Indian Sindhis of late (Table 13.10), especially among people not literate in 𝚜𝚍-𝙰𝚛𝚊𝚋. Overall, though, religion has played a negligible role in conditioning script preference and competence among Sindhis, regardless of era. The decisive factor behind script ‘choice’ has been the purpose and context of writing.
15.2 Sindhi and the Biscriptality paradigm
The Biscriptality framework currently cites Sindhi as an example of scriptal pluricentricity, the justification being that the language today manifests as 𝚜𝚍-𝙰𝚛𝚊𝚋 in Pakistan but as 𝚜𝚍-𝙳𝚎𝚟𝚊 in India (Bunčić, 2016c, p. 59; 2016g, p. 188). Evidently, there is more to the story here.
As revealed in Part Two, the present-day situation is one in which the Arabic script is the undisputed script for writing Sindhi in Pakistan, in almost all domains of use. In contrast, the Indian situation is somewhat more complex. Immediately after Partition, both Arabic and Devanagari were used to write Sindhi, making the language biscriptal within India at the time. Since then, use of Arabic has declined, but its place has not been fully taken by Devanagari. Therefore, while Sindhi in India in present times is written to a limited extent in Devanagari, it also qualifies as a largely oral or, more appropriately, neovernacularised language (Iyengar & Parchani, 2021; Annamalai, 2014). These observations serve to refine the claim that Sindhi today is a scriptally pluricentric language across the two geopolitical centres of Pakistan and India. However, and as explained in Section 15.1, script use during the pre-British and British eras was centred on occupational or gender-based groups. Thus, while multiscriptality in the context of the Sindhi language has continued to remain largely user-oriented, the user groups acting as ‘script centres’ have changed over the years.
Notwithstanding persistent user-oriented multiscriptality in Sindhi, the findings in Part Two also reveal use-oriented multiscriptality, particularly in the past. That is, in addition to orientation along the sociolinguistic axes of occupation and gender, Sindhi literacy practices in pre-British and early British times also show a distinct bifurcation in terms of the purpose or function of writing. For religious or administrative writing, the scripts and associated writing systems employed were so-called fully developed ones such as 𝚜𝚍-𝙰𝚛𝚊𝚋 and, to a lesser extent, 𝚜𝚍-𝙺𝚑𝚘𝚓. On the other hand, for commercial or other ephemeral writing, the scripts and writing systems in use were so-called defective ones, best exemplified by the unstandardised Landa variants. In other words, the scripts in use and the graphematic completeness of their associated writing systems depended on their vocational relevance (Khubchandani, 1977, p. 34). There was a neat division of labour among the writing systems in question, typically resulting in mutual exclusivity or domain complementarity (Timm, 1981). Building on Ferguson’s (1959) classic definition of diglossia, the historical scripts used for formal writing qualify as high-status or H scripts. In contrast, those used for informal or ephemeral writing qualify as low-status or L script forms. On this basis, it can be argued that writing in Sindhi during the eras in question also exhibits characteristics of digraphia.
The use of Gurmukhi by Hindu-Sikh Sindhi women presents an especially intriguing case of digraphia. Similar historical cases in East Asia are alluded to by Bunčić (2016d; 2016f) and Unseth (2005, p. 37), where a particular language was written and read in one script by men, but in another by women. Consequently, the script used by women — notionally the L stratum in premodern, strongly patriarchal societies — was, by association, deemed the L variety. Bunčić (2016c) terms this gender-based digraphia. This characterisation reflects to some extent the situation of Sindhi women in pre-British and early British times. Although they did not usually receive a formal education, they did in some cases acquire competence in 𝚙𝚊-𝙶𝚞𝚛𝚞 and 𝚜𝚍-𝙶𝚞𝚛𝚞 from older stay-at-home women in order to read Sikh scriptures. However, the Sindhi case contrasts with those described by Bunčić and Unseth in that women — the supposed L stratum of Sindhi society at the time — primarily used Gurmukhi in religious contexts, which would presumably render it an H script. Put differently, 𝚙𝚊-𝙶𝚞𝚛𝚞 and 𝚜𝚍-𝙶𝚞𝚛𝚞 may represent a noteworthy case of digraphia where an L group accesses written language through an H script. Regardless of whether this interpretation is affirmed or rebutted by further research, the fact remains that the case of 𝚙𝚊-𝙶𝚞𝚛𝚞 and 𝚜𝚍-𝙶𝚞𝚛𝚞 as used by Sindhi women makes valuable contributions to our knowledge of historical gender-based digraphia, and to the biscriptality paradigm as a whole.
Also noteworthy is that Sindhi women’s proficiency in 𝚙𝚊-𝙶𝚞𝚛𝚞 and 𝚜𝚍-𝙶𝚞𝚛𝚞 was usually restricted to reading, and that they did not necessarily write using Gurmukhi to a great extent. This corroborates Masica’s (1996, p. 776) observation of “ritual reading, particularly by women, of devotional texts” in various South Asian societies. In the absence of suitable English-language terms for the phenomenon at hand, it appears expedient to adopt the German-language terms lesefähig ‘capable of reading’ and schreibfähig ‘capable of writing’. Thus, the Sindhi women in question may be described as lesefähig in 𝚙𝚊-𝙶𝚞𝚛𝚞 and 𝚜𝚍-𝙶𝚞𝚛𝚞, but not always schreibfähig in those systems. This observation further distinguishes the historic gender-based digraphia among Sindhi women from similar cases described by Bunčić and Unseth. This dimension of literacy and competence may be worth considering in sociolinguistic analyses of script use, especially where the notion of ‘use’ needs to be further qualified.
Finally, also deserving mention is the institutionalisation and furtherance of Sindhi multiscriptality by the British colonial government and Christian missionaries in the region, such as Trumpp. Both groups generally subscribed to the idea of separate scripts and, consequently, writing systems for Sindhi targeted at Muslim and Hindu users. Nevertheless, it is necessary to draw a distinction between the advocacy of multiscriptality by the government and by missionaries. As already mentioned, scholars have surmised that the colonial government’s motives may have been informed by the imperial policy of Divide and Conquer. In contrast, missionaries were primarily driven by the aim of making Christian scriptures as widely readable as possible among the Sindhi-speaking population. Considering the different script competences prevalent among different groups in Sindhi society, it was expedient for missionaries to not just translate but transliterate their work accordingly. As a result, translations of Christian scriptures into Sindhi emerged in various scripts in order to potentially cover various groups — in 𝚜𝚍-𝙰𝚛𝚊𝚋 to cover Muslims and Persian-educated Amils, in 𝚜𝚍-𝚂𝚒𝚗𝚍-𝚡-𝟷𝟾𝟼𝟿 to cover Vania men, in 𝚜𝚍-𝙶𝚞𝚛𝚞 to cover stay-at-home Amil and Vania women, and even in 𝚜𝚍-𝙳𝚎𝚟𝚊, presumably to cover literate Sindhi speakers who did not fall into the above societal categories. It appears, therefore, that the colonial government and the missionaries, despite having ostensibly different aims, ended up doing the same thing — promoting distinct scripts for different groups of Sindhi speakers.
In any event, the semiotic associations and the overall distribution of scripts described here only concern inkprint scripts. Were 𝚜𝚍-𝙱𝚛𝚊𝚒 to be included in the mix, the tenuous nature of indiscriminately associating script with religious or social categories is laid bare. The perspective that 𝚜𝚍-𝙱𝚛𝚊𝚒 adds to sociolinguistic understandings of Sindhi multiscriptality demonstrates yet again why Braille-based writing systems need to be included more often in grapholinguistic evaluations, on par with inkprint writing systems.
In all, it appears uncontroversial to state that multiscriptality is and has been the normal state of affairs in the Sindhi graphosphere. To paraphrase Ellis (2006), multiscriptality may be considered the unmarked case when it comes to writing Sindhi.
15.3 The sociolinguistic status of writing
As mentioned in Chapter 5, Sindhi had a rich culture of orature, including numerous musical and poetic compositions. Not all of them went on to appear in written form, with those that did generally being of a religious or spiritual nature. The primacy of the oral medium in pre-British Sindh and the instrumental approach towards the written medium are indicative of the traditional South Asian outlook towards writing in general. This outlook has been characterised as “paradoxical” (Masica, 1996). Writing has a three-thousand-year-old history in the Subcontinent, and the region has seen the evolution of dozens of scripts and writing systems (Salomon, 1996a). In fact, the region likely has the highest script density in the world (Masica, 1996). Yet, oral transmission and performance has traditionally been the primary means of teaching and learning in South Asian societies (Aklujkar, 2008; Annamalai, 2008; Fuller, 2001; Kachru, 2008; Lopez, 1995; Masica, 1996; Ostler, 2016; Plofker, 2009; Rocher, 1994). In this sense, premodern South Asia has been portrayed as a culture that “hypervalue[d] orality” (Pollock, 2006, p. 4). Salomon, who has written extensively on the topic, notes that:
[w]riting played a significantly different cultural role in traditional South Asia (i.e. the Indian subcontinent) than in many parts of the ancient world […] Oral traditions were usually more revered than written ones in India, and sacred texts such as the Vedas or the Buddhist Canon were originally preserved by memory rather than in written form, which was felt to be less reliable.
Salomon (2007, p. 80) also hypothesises that writing having “secondary cultural value” could be a reason why so many different scripts developed in various parts of the Subcontinent. In other words, regional script forms arose in abundance since writing was considered secondary and scribes, therefore, were not always scrupulous in composing or reproducing written texts. In the context of this study, Salomon’s observation is aptly illustrated by the emergence of the numerous regional varieties of Landa.
Along similar lines, Masica (1991, pp. 137, 144) notes that the historically secondary nature of writing in South Asia has led to it being primarily used for informal commercial record-keeping, rather than for literary works as was the case in East Asia, Arabia and Europe. This observation is echoed by Bright (1990b), who notes that writing has been known in the Subcontinent for millennia, but has been used more for informal mercantile purposes rather than for literature. In this regard, Salomon (2007, p. 80) adds that writing practices in premodern South Asia varied according to purpose. Writing for informal purposes was usually in deficient scripts or inconsistent orthographies. In contrast, writing for formal purposes used rigorous and relatively standardised scripts and orthographies. These observations dovetail neatly with the use-oriented or domain-based multiscriptality attested in the context of Sindhi (§15.2).
The presence of domain-based complementary distribution of scripts and writing systems may distinguish South Asian writing practices from those in other parts of the world. For instance, Bright (1990b, p. 146) contrasts the historically secondary nature of the written medium in much of South Asia with the “cult of the book” prevalent in Europe and the West. To some extent, this may explain why the British rulers of Sindh were preoccupied with instituting a standardised script and orthography for graphising the language. The notion of standardising scripts and orthographies has been criticised for its monolingual and homogenising underpinnings by certain authors, in particular Khubchandani (1984). Nevertheless, it is also true, as stated by Bright (1990b, p. 146) that “nowadays, it is writing, not speech, which most educated people regard as basic, and indeed as a necessity”. With the spread of mass education, the notion of a language having a standard script, writing system and orthography has become entrenched worldwide (Bunčić, 2016b, p. 16). In fact, it is the entrenchment of this notion that has led to the post-Partition infighting over the so-called official script for Sindhi in India. That said, it does appear that historical and contemporary script use and writing practices in the Sindhi community are consistent with traditional South Asian writing practices in general.
At the same time, Euro-Western influence during the British and post-Independence eras has caused South Asian languages to become increasingly standardised and codified in writing, along with several speech forms being graphised for the first time. Yet, vestiges of traditional practices persist, leading to modern-day hybrid practices that may diverge from practices common in other parts of the world. The salient characteristics of modern South Asian literacy practices have been summarised by Masica thus:
Large portions of the population of South Asia […] have, as it were, leapt directly from a preliterate to a postliterate stage without passing through a literate stage in between — that is, they have gone from a culture rich in oral literature and performance to a culture of films, videotapes, and audiocassettes. […] although the reading public is very large in absolute terms, it is the film, audiocassette, and television, rather than the book, that are becoming the premier vehicles of mass cultural consumption today.
Masica’s observations align with the conclusions in Section 13.3.3 in that formal literacy in Sindhi — in any of its scripts and writing systems — was and is not highly sought after. At the same time, audio-visual Sindhi-language content has been on the rise on video-sharing websites and online platforms, representing the next stage in the evolution of “films, videotapes, and audiocassettes” Masica talks of. The supposed predilection for the oral mode among South Asian communities in general is also consistent with the Sindhi community’s apparent nonchalance towards issues of graphematic standardisation and orthographies in their language’s writing systems. In general, the outlook seems to be “Why do I need to write to someone in Sindhi if I can speak to them directly in the language?” Indeed, it is the community’s relative comfort with grapholinguistic variability and plurality that forms the very raison d’être of this book. After all, had the Sindhis been finicky, dogmatic or chauvinistic in matters of writing their traditional language, there would have been no need for a book like this.